You Only Look Once:Unified, Real-Time Object Detection论文笔记
来源:互联网 发布:gpu与matlab混合编程 编辑:程序博客网 时间:2024/05/16 17:23
You Only Look Once:Unified, Real-Time Object Detection论文笔记
项目主页: http://pjreddie.com/darknet/yolo/
论文:You Only Look Once:Unified, Real-Time Object Detection
参考网址:http://blog.csdn.net/dp_bupt/article/details/49176115
http://blog.csdn.net/cv_family_z/article/details/46803421
本文旨在实现图像中的物体检测,和之前的R-CNN不同的是,它利用一个单一的CNN,完成了在整个图像上bounding box和类别概率的预测。这既使得它可以实现end-to-end的优化,同时也提高了框架的速度。
基于R-CNN的框架,都是先利用region proposal来生成bunding-box,然后利用CNN在box中提取提取特征,再利用分类器进行分类。而且为了优化bounding-box的位置,后续加入了线性单元,用于调整box坐标,从而提高分类准确率。
YOLO结构模型如下:

单一的CNN同时完成多个bounding-box的位置及其类别概率的预测。而且训练是基于整个图像,这样就能利用内容信息,从而降低背景误差。在此基础上,通过设定合适的概率预测阈值,就可以得到探测到的高概率物体。如上图最右端所示,即为最终识别结果。
系统流程如下图所示,输入图像划分为S*S个grid(网格)。如果一个物体的中心落在某个grid内,则对应的grid负责检测该物体。
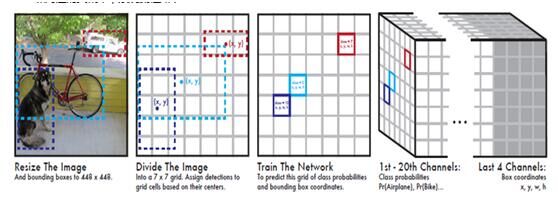
每个grid cell预测B 个bounding box和其对应的confidence scores(置信度得分)。这些confidence scores反映了box含有物体的置信度大小与box是否含有物体的概率大小。最后,作者定义置信度为![]() 。如果这个grid cell中不含有物体,则置信度为0。否则作者希望置信度得分等于预测出的box和ground truth box的IOU(交集除以并集)。
。如果这个grid cell中不含有物体,则置信度为0。否则作者希望置信度得分等于预测出的box和ground truth box的IOU(交集除以并集)。
每个bounding box包含5个预测值:x,y,w,h和confidence。(x,y)表示相对于grid cell边界的box中心点坐标。w和h表示相对于整张图片的box宽高。最后,confidence表示预测出的box与任一ground truth box的IOU。
每个grid cell也预测C种物体的条件概率,Pr(Classi|Object)。这个概率依托于grid cell中是否含有物体概率。不管boxes B有多少个,作者只为每个grid cell预测物体种类。

根据公式(1)可以得到每个bounding box的置信度得分。这些得分表示class出现在box中的概率,同时也表示这些预测的box适合物体的程度。
YOLO系统是一个回归问题,它把图片划分为grid cell,同时预测bounding box,confidence以及class概率。这些预测被表示为S*S*(B*5 + C)个tensor(张量)
作者是在PASCAL VOC上进行YOLO网络的评估,他们采用的参数为S=7,B=2。PASCAL VOC有20类标注的classes,所以C=20。最终网络输出为7X7X30=1470个tensor(张量)。
YOLO系统使用CNN实现并在VOC上测试,初始卷积层从图像中提取特征,全连接层预测概率和坐标。网络框架与GoogleNet类似,拥有24个卷积层和2个全连接层,网络如下图所示,最终的输出是对7X7个网格的预测,每个网格预测20类的概率和坐标。
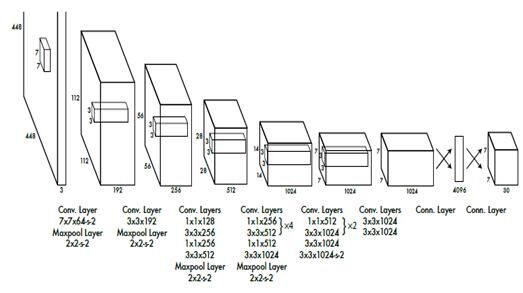
网络训练部分,作者使用ImageNet进行初始训练,使用上图中的前20层加一个maxpooling层及两个全连接层进行训练,1星期训练得到top-5error为88%。
接着,作者在上述网络后面添加了4个卷积网络层和2个全连接层,用于目标检测。这6层刚开始都是随机权值,由于检测需要更为精细的信息,作者将网络输入由224*224调整至448*448,后面这6层就是用于处理回归问题的。
网络的最后一层预测class概率和bounding box,在最后一层使用逻辑激活函数,其他层使用leaky ReLU:
![]()
网络输出使用平方和误差,并引入尺度因子λ 对类概率和bounding box的误差进行加权,同时为了反映出偏离在大的bounding box中的影响比较小,paper使用bounding box宽高的平方根,最终的损失函数是:

为了避免过拟合,作者使用了dropout和数据增加。
49个grid cell,每个包含20个概率预测值,一共就有980个预测值,但只有少数网格有物体存在,这样严重的稀疏可能会导致最终所有的概率都为0,导致训练过程发散。
针对这一问题,在每个grid cell引入额外变量,用于表示在此网格存在物体的概率。这样在某一位置的物体的类别概率就可以计算出来,即:

公式里的物体存在概率在每个grid处都更新,而条件概率只在那些含有物体的grid处才更新,这样就能避免概率为0的问题。
YOLO的限制: 由于YOLO具有极强的空间限制,它限制了模型在邻近物体上的预测,如果两个物体出现在同一个grid cell中,模型只能预测一个物体,所以在小物体检测上会出问题。另外模型对训练数据中不包含的物体或具有异常长宽比的物体扩展不是太好。loss函数对大小bounding box采取相同的error也是个问题。
实验结果: 在voc2012上的实验结果对比如下,YOLO在不基于R-CNN的方法中mAP最高,但比state-of-art低。

YOLO的速度提升比较明显,在voc2007上的实验结果对比如下:

- [深度学习论文笔记][Object Detection] You Only Look Once: Unified, Real-Time Object Detection
- 《You Only Look Once:Unified,Real-Time Object Detection》笔记
- 论文笔记(3)You Only Look Once:Unified, Real-Time Object Detection
- You Only Look Once:Unified, Real-Time Object Detection论文笔记
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- 论文笔记|You Only Look Once: Unified, Real-Time Object Detection
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- 论文笔记 You Only Look Once: Unified, Real-Time Object Detection
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- 论文笔记 You Only Look Once: Unified, Real-Time Object Detection
- Object Detection -- 论文YOLO(You Only Look Once: Unified, Real-Time Object Detection)解读
- You Only Look Once: Unified, Real-Time Object Detection
- You Only Look Once: Unified, Real-Time Object Detection
- You Only Look Once(YOLO):Unified, Real-Time Object Detection
- You Only Look Once: Unified, Real-Time Object Detection(2)
- AutoCloseable & Closable
- 为升级后的Linux内核打包(适用于ubuntu)
- 通信框架AKKA介绍
- 计算机专业毕业设计指导
- Harris角点检测基本理论
- You Only Look Once:Unified, Real-Time Object Detection论文笔记
- Using Xcode OpenGL ES Frame Capture
- linkinFrame--web应用举例--准备工作
- Activity启动模式详解
- [DevExpress]TreeListLookUpEdit带checkbox之经典运用
- ASCII 码表
- java程序实现短信发送(可调用免费短信接口)
- Android中用OpenGL ES Tracer分析绘制过程
- 相机的存储路径


