下面这个网址收集了python操作excel文件的主要模块的记录。
http://www.python-excel.org/
The Packages
There are python packages available to work with Excel files that will run on any Python platform and that do not require either Windows or Excel to be used. They are fast, reliable and open source:
openpyxl
The recommended package for reading and writing Excel 2010 files (ie: .xlsx)
Download | Documentation | Bitbucket
xlsxwriter
An alternative package for writing data, formatting information and, in particular, charts in the Excel 2010 format (ie: .xlsx)
Download | Documentation | GitHub
xlrd
This package is for reading data and formatting information from older Excel files (ie: .xls)
Download | Documentation | GitHub
xlwt
This package is for writing data and formatting information to older Excel files (ie: .xls)
Download | Documentation | Examples | GitHub
xlutils
This package collects utilities that require both xlrd and xlwt, including the ability to copy and modify or filter existing excel files.
NB: In general, these use cases are now covered by openpyxl!
Download | Documentation | GitHub
calf兄在自己的博文里对这个几个模块的使用优缺点有如下博文进行总结。
http://www.gocalf.com/blog/python-read-write-excel.html
junjie兄在如下博文里对xlrd,xlwt的使用进行了总结
http://www.jb51.net/article/60510.htm
python读excel——xlrd
这个过程有几个比较麻烦的问题,比如读取日期、读合并单元格内容。下面先看看基本的操作:
首先读一个excel文件,有两个sheet,测试用第二个sheet,sheet2内容如下:

python 对 excel基本的操作如下:
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
importxlrd
importxlwt
fromdatetime importdate,datetime
defread_excel():
workbook=xlrd.open_workbook(r'F:\demo.xlsx')
printworkbook.sheet_names()
sheet2_name=workbook.sheet_names()[1]
sheet2=workbook.sheet_by_index(1)
sheet2=workbook.sheet_by_name('sheet2')
printsheet2.name,sheet2.nrows,sheet2.ncols
rows=sheet2.row_values(3)
cols=sheet2.col_values(2)
printrows
printcols
printsheet2.cell(1,0).value.encode('utf-8')
printsheet2.cell_value(1,0).encode('utf-8')
printsheet2.row(1)[0].value.encode('utf-8')
printsheet2.cell(1,0).ctype
if__name__ =='__main__':
read_excel()
运行结果如下:
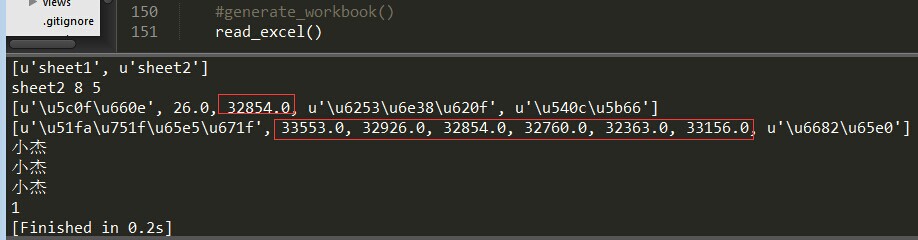
那么问题来了,上面的运行结果中红框框中的字段明明是出生日期,可显示的确实浮点数。好的,来解决第一个问题:
1、python读取excel中单元格内容为日期的方式
python读取excel中单元格的内容返回的有5种类型,即上面例子中的ctype:
?
1
ctype : 0empty,1string, 2number, 3date, 4boolean, 5error
即date的ctype=3,这时需要使用xlrd的xldate_as_tuple来处理为date格式,先判断表格的ctype=3时xldate才能开始操作。现在命令行看下:
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
>>> sheet2.cell(2,2).ctype
>>> sheet2.cell(2,1).ctype
>>> sheet2.cell(2,0).ctype
>>> sheet2.cell(2,4).ctype
>>> sheet2.cell(2,2).value
33656.0
>>> xlrd.xldate_as_tuple(sheet2.cell_value(2,2),workbook.datemode)
(1992,2,22,0,0,0)
>>> date_value =xlrd.xldate_as_tuple(sheet2.cell_value(2,2),workbook.datemode)
>>> date_value
(1992,2,22,0,0,0)
>>> date(*date_value[:3])
datetime.date(1992,2,22)
>>> date(*date_value[:3]).strftime('%Y/%m/%d')
'1992/02/22'
即可以做下简单处理,判断ctype是否等于3,如果等于3,则用时间格式处理:
?
1
2
3
if(sheet.cell(row,col).ctype ==3):
date_value=xlrd.xldate_as_tuple(sheet.cell_value(rows,3),book.datemode)
date_tmp=date(*date_value[:3]).strftime('%Y/%m/%d')
那么问题又来了,上面 sheet2.cell(2,4).ctype 返回的值是0,说明这个单元格的值是空值,明明是合并的单元格内容"好朋友",这个是我觉得这个包功能不完善的地方,如果是合并的单元格那么应该合并的单元格的内容一样,但是它只是合并的第一个单元格的有值,其它的为空。
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
>>> sheet2.col_values(4)
[u'\u5173\u7cfb', u'\u597d\u670b\u53cb', '', u'\u540c\u5b66', '', '', u'\u4e00\u4e2a\u4eba', '']
>>>fori inrange(sheet2.nrows):
printsheet2.col_values(4)[i]
关系
好朋友
同学
一个人
>>> sheet2.row_values(7)
[u'\u65e0\u540d',20.0, u'\u6682\u65e0', '', '']
>>>fori inrange(sheet2.ncols):
printsheet2.row_values(7)[i]
无名
20.0
暂无
>>>
2、读取合并单元格的内容
这个是真没技巧,只能获取合并单元格的第一个cell的行列索引,才能读到值,读错了就是空值。
即合并行单元格读取行的第一个索引,合并列单元格读取列的第一个索引,如上述,读取行合并单元格"好朋友"和读取列合并单元格"暂无"只能如下方式:
?
1
2
3
4
5
6
7
>>>printsheet2.col_values(4)[1]
好朋友
>>>printsheet2.row_values(7)[2]
暂无
>>> sheet2.merged_cells
[]
疑问又来了,合并单元格可能出现空值,但是表格本身的普通单元格也可能是空值,要怎么获取单元格所谓的"第一个行或列的索引"呢?
这就要先知道哪些是单元格是被合并的!
3、获取合并的单元格
读取文件的时候需要将formatting_info参数设置为True,默认是False,所以上面获取合并的单元格数组为空,
?
1
2
3
4
>>> workbook =xlrd.open_workbook(r'F:\demo.xlsx',formatting_info=True)
>>> sheet2 =workbook.sheet_by_name('sheet2')
>>> sheet2.merged_cells
[(7,8,2,5), (1,3,4,5), (3,6,4,5)]
merged_cells返回的这四个参数的含义是:(row,row_range,col,col_range),其中[row,row_range)包括row,不包括row_range,col也是一样,即(1, 3, 4, 5)的含义是:第1到2行(不包括3)合并,(7, 8, 2, 5)的含义是:第2到4列合并。
利用这个,可以分别获取合并的三个单元格的内容:
?
1
2
3
4
5
6
>>>printsheet2.cell_value(1,4)
好朋友
>>>printsheet2.cell_value(3,4)
同学
>>>printsheet2.cell_value(7,2)
暂无
发现规律了没?是的,获取merge_cells返回的row和col低位的索引即可! 于是可以这样一劳永逸:
?
1
2
3
4
5
6
7
8
9
10
11
12
13
>>> merge =[]
>>>for(rlow,rhigh,clow,chigh) insheet2.merged_cells:
merge.append([rlow,clow])
>>> merge
[[7,2], [1,4], [3,4]]
>>>forindex inmerge:
printsheet2.cell_value(index[0],index[1])
暂无
好朋友
同学
>>>
python写excel——xlwt
写excel的难点可能不在构造一个workbook的本身,而是填充的数据,不过这不在范围内。在写excel的操作中也有棘手的问题,比如写入合并的单元格就是比较麻烦的,另外写入还有不同的样式。这些要看源码才能研究的透。
我"构思"了如下面的sheet1,即要用xlwt实现的东西:
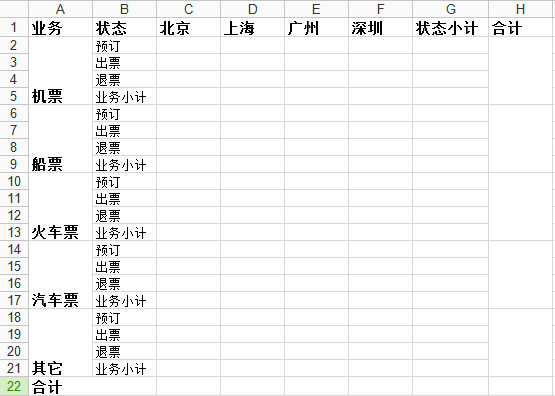
基本上看起来还算复杂,而且看起来"很正规",完全是个人杜撰。
代码如下:
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
defset_style(name,height,bold=False):
style=xlwt.XFStyle()
font=xlwt.Font()
font.name=name
font.bold=bold
font.color_index=4
font.height=height
style.font=font
returnstyle
defwrite_excel():
f=xlwt.Workbook()
sheet1=f.add_sheet(u'sheet1',cell_overwrite_ok=True)
row0=[u'业务',u'状态',u'北京',u'上海',u'广州',u'深圳',u'状态小计',u'合计']
column0=[u'机票',u'船票',u'火车票',u'汽车票',u'其它']
status=[u'预订',u'出票',u'退票',u'业务小计']
fori inrange(0,len(row0)):
sheet1.write(0,i,row0[i],set_style('Times New Roman',220,True))
i, j =1,0
whilei < 4*len(column0)andj < len(column0):
sheet1.write_merge(i,i+3,0,0,column0[j],set_style('Arial',220,True))
sheet1.write_merge(i,i+3,7,7)
i+=4
j+=1
sheet1.write_merge(21,21,0,1,u'合计',set_style('Times New Roman',220,True))
i=0
whilei < 4*len(column0):
forj inrange(0,len(status)):
sheet1.write(j+i+1,1,status[j])
i+=4
f.save('demo1.xlsx')
if__name__ =='__main__':
write_excel()
需要稍作解释的就是write_merge方法:
write_merge(x, x + m, y, w + n, string, sytle)
x表示行,y表示列,m表示跨行个数,n表示跨列个数,string表示要写入的单元格内容,style表示单元格样式。其中,x,y,w,h,都是以0开始计算的。
这个和xlrd中的读合并单元格的不太一样。
如上述:sheet1.write_merge(21,21,0,1,u'合计',set_style('Times New Roman',220,True))
即在22行合并第1,2列,合并后的单元格内容为"合计",并设置了style。
如果需要创建多个sheet,则只要f.add_sheet即可。
如在上述write_excel函数里f.save('demo1.xlsx') 这句之前再创建一个sheet2,效果如下:
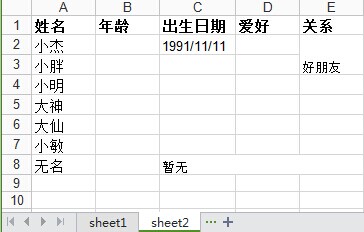
代码也是真真的easy的了:
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
sheet2=f.add_sheet(u'sheet2',cell_overwrite_ok=True)
row0=[u'姓名',u'年龄',u'出生日期',u'爱好',u'关系']
column0=[u'小杰',u'小胖',u'小明',u'大神',u'大仙',u'小敏',u'无名']
fori inrange(0,len(row0)):
sheet2.write(0,i,row0[i],set_style('Times New Roman',220,True))
fori inrange(0,len(column0)):
sheet2.write(i+1,0,column0[i],set_style('Times New Roman',220))
sheet2.write(1,2,'1991/11/11')
sheet2.write_merge(7,7,2,4,u'暂无')
sheet2.write_merge(1,2,4,4,u'好朋友')
f.save('demo1.xlsx')
三 如何修改已经存在的excel ,实际用openpyxl可以做到
Python中一般使用xlrd(excel read)来读取Excel文件,使用xlwt(excel write)来生成Excel文件(可以控制Excel中单元格的格式),需要注意的是,用xlrd读 取excel是不能对其进行操作的:xlrd.open_workbook()方法返回xlrd.Book类型,是只读的,不能对其进行操作。而 xlwt.Workbook()返回的xlwt.Workbook类型的save(filepath)方法可以保存excel文件。
因此对于读取和生成Excel文件都非常容易处理,但是对于已经存在的Excel文件进行修改就比较麻烦了。不过,还有一个xlutils(依赖于xlrd和xlwt)提供复制excel文件内容和修改文件的功能。其实际也只是在xlrd.Book和xlwt.Workbook之间建立了一个管道而已,如下图:
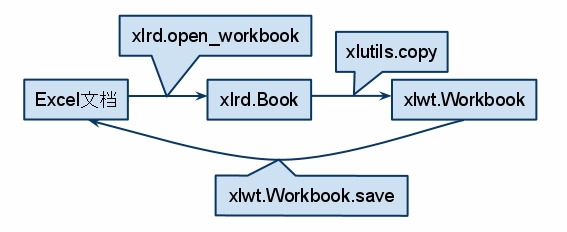
xlutils.copy模块的copy()方法实现了这个功能,示例代码如下:
from xlrd import open_workbook
from xlutils.copy import copy
rb = open_workbook('m:\\1.xls')
#通过sheet_by_index()获取的sheet没有write()方法
rs = rb.sheet_by_index(0)
wb = copy(rb)
#通过get_sheet()获取的sheet有write()方法
ws = wb.get_sheet(0)
ws.write(0, 0, 'changed!')
wb.save('m:\\1.xls')
0 0


