面试题201-225
来源:互联网 发布:一橙网络资费 编辑:程序博客网 时间:2024/04/27 15:14
201.为什么选择ConcurrentHashMap,简述锁分段技术。
ConcurrentHashMap的内部结构
ConcurrentHashMap为了提高本身的并发能力,在内部采用了一个叫做Segment的结构,一个Segment其实就是一个类Hash Table的结构,Segment内部维护了一个链表数组,我们用下面这一幅图来看下ConcurrentHashMap的内部结构:
效率低下的HashTable容器
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
锁分段技术
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
java5中新增了ConcurrentMap接口和它的一个实现类ConcurrentHashMap。ConcurrentHashMap提供了和Hashtable以及SynchronizedMap中所不同的锁机制。Hashtable中采用的锁机制是一次锁住整个hash表,从而同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。ConcurrentHashMap默认将hash表分为16个桶,诸如get,put,remove等常用操作只锁当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
上面说到的16个线程指的是写线程,而读操作大部分时候都不需要用到锁。只有在size等操作时才需要锁住整个hash表。
在迭代方面,ConcurrentHashMap使用了一种不同的迭代方式。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变。
202.系统优化从哪些方面入手?
数据库方面
1. 选用合适的数据库框架(针对当前项目)
2. 合理的数据库表结构设计
3. 减少数据库交互 使用缓存
4. 查询语句优化 ,只查询有需要字段 减少多余字段查询 .优化查询逻辑 减少不必要表关联
5. 使用索引 与分库 分表等手段提高查询效率
程序方面
1. 理清业务逻辑 减少重复逻辑
2. 避免循环查询数据库
3. 正确使用API中提供方法(API使用不正确 有时候会很消耗资源)
4. 良好的编码习惯 (这个比较宽泛很多要求 网上都有)
页面方面
1. 页面元素布局,注意JS加载顺序 (这个影响都不大)
2. 合理使用ajax加载数据
3. 页面支持使用缓存阿等等
203.MySQL索引原理
###索引的数据结构
前面讲了生活中索引的例子,索引的基本原理,数据库的复杂性,又讲了操作系统的相关知识,目的就是让大家了解,任何一种数据结构都不是凭空产生的,一定会有它的背景和使用场景,我们现在总结一下,我们需要这种数据结构能够做些什么,其实很简单,那就是:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生。
###详解b+树
如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
###b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
204.为什么tcp可以保持顺序性
TCP协议使用TCP头部的seq num + ack机制可以保证顺序性。
205.TCP与UDP的区别?
TCP :传输控制协议
特点:面向连接的可靠传输协议
4种可靠机制
确认
重传 超时 错误
排序
滑动窗口 流控
(三次握手,四次断开)
UDP :用户数据报文协议
特点:非面向连接不可靠传输协议
udp是不可靠的传输协议,就像漂流瓶,石沉大海。
206.Java中关于OOM的场景及解决方法
1、OOM for Heap=>例如:java.lang.OutOfMemoryError: Java heap space分 析
此OOM是由于JVM中heap的最大值不满足需要,将设置heap的最大值调高即可,参数样例为:-Xmx2G
解决方法
调高heap的最大值,即-Xmx的值调大。
2、OOM for Perm=>例如:java.lang.OutOfMemoryError: Java perm space
分 析
此OOM是由于JVM中perm的最大值不满足需要,将设置perm的最大值调高即可,参数样例为:-XX:MaxPermSize=512M
解决方法
调高heap的最大值,即-XX:MaxPermSize的值调大。
另外,注意一点,Perm一般是在JVM启动时加载类进来,如果是JVM运行较长一段时间而不是刚启动后溢出的话,很有可能是由于运行时有类被动态加载进来,此时建议用CMS策略中的类卸载配置。
如:-XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled
3、OOM for GC=>例如:java.lang.OutOfMemoryError: GC overhead limit exceeded
分 析
此OOM是由于JVM在GC时,对象过多,导致内存溢出,建议调整GC的策略,在一定比例下开始GC而不要使用默认的策略,或者将新代和老代设置合适的大小,需要进行微调存活率。
解决方法
改变GC策略,在老代80%时就是开始GC,并且将-XX:SurvivorRatio(-XX:SurvivorRatio=8)(Eden与Survivor的占用比例。例如8表示,一个survivor区占用 1/8 的Eden内存,即1/10的新生代内存,为什么不是1/9?
因为我们的新生代有2个survivor,即S0和S1。所以survivor总共是占用新生代内存的 2/10,Eden与新生代的占比则为 8/10)和-XX:NewRatio(-XX:NewRatio=4)(新生代和年老代的堆内存占用比例, 例如2表示新生代占年老代的1/2,占整个堆内存的1/3)设置的更合理。
4、OOM for native thread created=>如:java.lang.OutOfMemoryError: unable to create new native thread
分 析
参考如下:
(MaxProcessMemory - JVMMemory - ReservedOsMemory) / (ThreadStackSize) = Number of threads
MaxProcessMemory 指的是一个进程的最大内存
JVMMemory JVM内存
ReservedOsMemory 保留的操作系统内存
ThreadStackSize 线程栈的大小
如果JVM内存调的过大或者可利用率小于20%,可以建议将heap及perm的最大值下调,并将线程栈调小,即-Xss调小,如:-Xss128k
解决方法
在JVM内存不能调小的前提下,将-Xss设置较小,如:-Xss:128k
5、OOM for allocate huge array=>例如:Exception in thread "main": java.lang.OutOfMemoryError: Requested array size exceeds VM limit
分 析
此类信息表明应用程序(或者被应用程序调用的APIs)试图分配一个大于堆大小的数组。例如,如果应用程序new一个数组对象,大小为512M,但是最大堆大小为256M,因此OutOfMemoryError会抛出,因为数组的大小超过虚拟机的限制。
解决方法
(1)、首先检查heap的-Xmx是不是设置的过小
(2)、如果heap的-Xmx已经足够大,那么请检查应用程序是不是存在bug,例如:应用程序可能在计算数组的大小时,存在算法错误,导致数组的size很大,从而导致巨大的数组被分配。
6、 OOM for small swap=>例如:Exception in thread "main": java.lang.OutOfMemoryError: request <size> bytes for <reason>. Out of swap space?
分 析
抛出这类错误,是由于从native堆中分配内存失败,并且堆内存可能接近耗尽。这类错误可能跟应用程序没有关系,例如下面两种原因也会导致错误的发生:
(1)操作系统配置了较小的交换区
(2)系统的另外一个进程正在消耗所有的内存
解决方法
(1)、检查os的swap是不是没有设置或者设置的过小
(2)、检查是否有其他进程在消耗大量的内存,从而导致当前的JVM内存不够分配。
注意:虽然有时<reason>部分显示导致OOM的原因,但大多数情况下,<reason>显示的是提示分配失败的源模块的名称,所以有必要查看日志文件,如crash时的hs文件。
jvm启动时加入参数:-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=D:\heapdump 然后通过jvisualvm工具分析数据
关于memcache,前段时间尝试自己用memcache来写了一个队列,平台windows。最终效果非常不理想,在循环的get或set时,memcache会显得非常缓慢,并且最终的命中率一点都不高。在windows平台上的redis会由于pull的不支持造成在高并发时经常redis server gone away的情况。在*inux平台上,redis表现了非常棒的性能和稳定性,目前公司线上产品在使用redis后,已经非常稳定,所以redis绝对是值得使用的神器。
根据情况选择不同的引擎或数据库软件,MYISAM,INNODB等引擎要在不同的情况下使用,MYSIAM适用于查询多,插入少;INNODB适用于写入多,查询少和事务支持。noSQL也是非常值得尝试的产品,PHP对mongdb的支持还行,操作也挺方便的。
M/S在高并发下存在延迟问题,临时解决方案是可以用缓存。
好了,以上就是近期总结的一些经验。
208.jstack、jmap的使用
HTTP无状态:无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。从另一方面讲,打开一个服务器上的网页和你之前打开这个服务器上的网页之间没有任何联系
如果你要实现一个购物车,需要借助于Cookie或Session或服务器端API(如NSAPI and ISAPI)记录这些信息,请求服务器结算页面时同时将这些信息提交到服务器
当你登录到一个网站时,你的登录状态也是由Cookie或Session来“记忆”的,因为服务器并不知道你是否登录
优点:服务器不用为每个客户端连接分配内存来记忆大量状态,也不用在客户端失去连接时去清理内存,以更高效地去处理WEB业务
缺点:客户端的每次请求都需要携带相应参数,服务器需要处理这些参数
1、HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接,更不能代表HTTP使用的是UDP协议(无连接)
2、从HTTP/1.1起,默认都开启了Keep-Alive,保持连接特性,简单地说,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
3、Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间
1、增加了一个角色,要有一个专门负责收集客人需求的人。NIO里对应的就是Selector。
2、由阻塞服务方式改为非阻塞服务了,客人吃着的时候服务员不用一直侯在客人旁边了。传统的IO操作,比如read(),当没有数据可读的时候,线程一直阻塞被占用,直到数据到来。NIO中没有数据可读时,read()会立即返回0,线程不会阻塞。
NIO中,客户端创建一个连接后,先要将连接注册到Selector,相当于客人进入餐厅后,告诉前台你要用餐,前台会告诉你你的桌号是几号,然后你就可能到那张桌子坐下了,SelectionKey就是桌号。当某一桌需要服务时,前台就记录哪一桌需要什么服务,比如1号桌要点菜,2号桌要结帐,服务员从前台取一条记录,根据记录提供服务,完了再来取下一条。这样服务的时间就被最有效的利用起来了。
InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是比起MyISAM存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
ynchronized?
承实体类(concrete class)?
体类,但前提是实体类必须有明确的构造函数。
public class ThreadTest {static Thread t1 = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("t1");}});static Thread t2 = new Thread(new Runnable() {@Overridepublic void run() {try {// 引用t1线程,等待t1线程执行完t1.join();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("t2");}});static Thread t3 = new Thread(new Runnable() {@Overridepublic void run() {try {// 引用t2线程,等待t2线程执行完t2.join();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("t3");}});public static void main(String[] args) throws Exception {t3.start();t2.start();t1.start();}}参考线程的相关面试题:http://blog.csdn.net/a137268431/article/details/50765716
写一个sql, 查询出 访问 1 个页面 2个页面 3 个页面 4 个页面 5个页面 及大于5个页面 的用户数 各是多少?
SELECT visit_page le5,COUNT(*) FROM visit obj WHERE obj.visit_page<=5 GROUP BY visit_pageUNIONSELECT "gre5",COUNT(*) gre5 FROM visit obj2 WHERE obj2.visit_page>5
220.数据库设计时,字段可以选择默认值或者null,为何选择默认值
sychronized是java中最基本同步互斥的手段,可以修饰代码块,方法,类.
在修饰代码块的时候需要一个reference对象作为锁的对象.
在修饰方法的时候默认是当前对象作为锁的对象.
在修饰类时候默认是当前类的Class对象作为锁的对象.
synchronized会在进入同步块的前后分别形成monitorenter和monitorexit字节码指令.在执行monitorenter指令时会尝试获取对象的锁,如果此没对象没有被锁,或者此对象已经被当前线程锁住,那么锁的计数器加一,每当monitorexit被锁的对象的计数器减一.直到为0就释放该对象的锁.由此synchronized是可重入的,不会出现自己把自己锁死.
二.什么ReentrantLock
以对象的方式来操作对象锁.相对于sychronized需要在finally中去释放锁
三.synchronized和ReentrantLock的区别
除了synchronized的功能,多了三个高级功能.
等待可中断,公平锁,绑定多个Condition.
1.等待可中断
在持有锁的线程长时间不释放锁的时候,等待的线程可以选择放弃等待. tryLock(long timeout, TimeUnit unit)
2.公平锁
按照申请锁的顺序来一次获得锁称为公平锁.synchronized的是非公平锁,ReentrantLock可以通过构造函数实现公平锁. new RenentrantLock(boolean fair)
3.绑定多个Condition
通过多次newCondition可以获得多个Condition对象,可以简单的实现比较复杂的线程同步的功能.通过await(),signal();
1)在TCP/IP协议栈中的位置
HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上,这个时候,就成了我们常说的HTTPS。如下图所示:
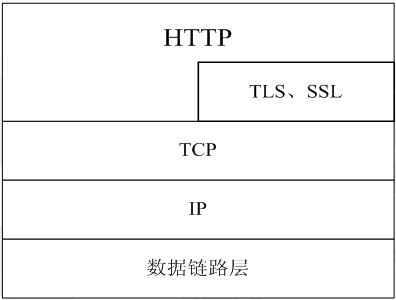
默认HTTP的端口号为80,HTTPS的端口号为443。
2)HTTP的请求响应模型
HTTP协议永远都是客户端发起请求,服务器回送响应。见下图:
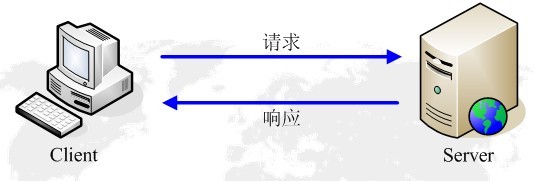
这样就限制了使用HTTP协议,无法实现在客户端没有发起请求的时候,服务器将消息推送给客户端。
HTTP协议是一个无状态的协议,同一个客户端的这次请求和上次请求是没有对应关系。
3)工作流程
一次HTTP操作称为一个事务,其工作过程可分为四步:
1)首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
2)建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
3)服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
4)客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要用鼠标点击,等待信息显示就可以了。
224.sql练习
1)一道SQL语句面试题,关于group by
表内容:
2005-05-09 胜
2005-05-09 胜
2005-05-09 负
2005-05-09 负
2005-05-10 胜
2005-05-10 负
2005-05-10 负
如果要生成下列结果, 该如何写sql语句?
胜 负
2005-05-09 2 2
2005-05-10 1 2
建表语句:
CREATE TABLE `test_match` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`dateStr` varchar(128) DEFAULT NULL,
`flag` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
insert into `test_match`(`id`,`dateStr`,`flag`) values (1,'2005-05-09','胜'),(2,'2005-05-09','胜'),(3,'2005-05-09','负'),(4,'2005-05-09','负'),(5,'2005-05-10','胜'),(6,'2005-05-10','负'),(7,'2005-05-10','负');
答案:
SELECT obj.`dateStr` '日期',SUM(CASE WHEN obj.`flag`='胜' THEN 1 ELSE 0 END) '胜',SUM(CASE WHEN obj.`flag`='负' THEN 1 ELSE 0 END) '负' FROM test_match obj GROUP BY dateStr
2)请教一个面试中遇到的SQL语句的查询问题表中有A B C三列,用SQL语句实现:当A列大于B列时选择A列否则选择B列,当B列大于C列时选择B列否则选择C列。
select (case when a>b then a else b end ),
(case when b>c then b esle c end)
from table_name
参考sql练习:http://blog.csdn.net/a137268431/article/details/50771379
225.lvs与keepalived的作用?nginx起到的作用
LVS是实现负载均衡作用的,即将客户端的需求采用特定的负载均衡算法分发到后端的Web应用服务器上,Keepalived是用来实现高可用的,即保证主LVS宕机后,从LVS可以在很短时间顶上,从而保证了系统或网站的稳定性。
nginx主要用于动静分离的操作
- 面试题201-225
- 面试题....
- 面试题
- 面试题
- 面试题
- 面试题
- 面试题
- 面试题
- 面试题
- 面试题
- 面试题
- 面试题
- 面试题
- 面试题
- 面试题
- 面试题
- 面试题
- 面试题
- SElinux
- 为何Math.abs(Integer.MIN_VALUE) = Integer.MIN_VALUE
- Rom
- jquery,toggle修改元素的显示和隐藏
- HDU 3709 Balanced Number(数位dp)
- 面试题201-225
- Python学习笔记(1)
- 文档显示部件,文档编辑部件获取标签的值
- docker安装-官网实例中文(centos7)
- Textview关键字高亮
- JAVA开发网站可以使用什么框架?
- ajax post json数据字符被转义
- 阅读Android源码的一些姿势
- Android样式之drawable


