Windows平台shellcode开发入门(二)
来源:互联网 发布:apache php nginx 编辑:程序博客网 时间:2024/06/03 17:34
在本系列第一部分中,我们学习了Shellcode的定义及其工作原理。为能够正确地编写 Windows 平台的 Shellcode ,作者将会在本文中讲述所需要的信息:进程环境块 、PE 文件格式及 X86 汇编。
一、进程环境块(PEB)
在Windows操作系统中,PEB是一个位于所有进程内存中固定位置的结构体。此结构体包含关于进程的有用信息,如可执行文件加载到内存的位置,模块列表(DLL),指示进程是否被调试的标志,还有许多其他的信息。
重要的是理解操作系统如何调用这个结构体。这个结构在不同Windows操作系统版本上并不是固定的,所以它可能随着新的Windows发行版发生改变,但一些通用信息会保持不变。
正如第1部分中讨论的,DLL(由于ASLR机制)可以加载到不同的内存位置,因此我们不能在shellcode中使用固定的内存地址。不过,我们可以使用PEB这个结构,位于固定的内存位置,从而查找DLL加载到内存中的地址。
如果熟悉C/C++编程语言,你会很容易理解这个结构体包含哪些信息及其布局。微软官方文档显示如下字段:
如你所见,一些称作“保留(Reserved)”字段没有相应的描述,而其他一些字段具有相应的文档描述。
对于不熟悉C/C++的同学们,你需要理解以下概念:BYTE表示1个字节。PVOID表示1个指针(或1个内存地址)-因此,在0×86系统上(32位系统)占用4个字节。 PPEB_LDR_DATA是1个指针,指向自定义结构体PEB_LDR_DATAPEB_LDR_DATA。其中第1个字段保留2个字节(Reserved1[2]是一个包含2个BYTE的数组)。BeingDebugged标志是1个字节,紧随着另一个字节(Reserved2)。Reserved3[2]是包含2个指针(2*4字节=8字节)的数组,而Ldr是一个指针-4个字节。
PEB_LDR_DATA包含如下信息:
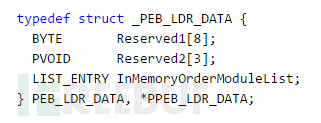
像以前一样,我们可以在偏移20字节后访问 InMemoryOrderModuleList字段(十六进制表示为0×14:8字节的Reserved1+3*4字节的Reserved2)。该字段可以指出已加载DLL的相关信息。
接下来事情变得有点复杂。我们可以通过LDR_DATA_TABLE_ENTRY结构体来获取已加载DLL的信息。微软官方文档并没有公开整个结构,但我们 可以从这里找到更多信息。
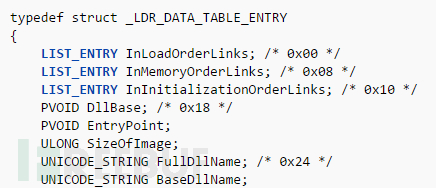
LIST_ENTRY结构是一个简单的双向链表,包含指向下一个元素(Flink)的指针和指向上一个元素的指针(Blink),其中每个指针占用4个字节:

InMemoryOrderModuleList字段是一个指针,指向LDR_DATA_TABLE_ENTRY 结构体上的LIST_ENTRY字段。但是它不是指向LDR_DATA_TABLE_ENTRY 起始位置的指针,而是指向这个结构的InMemoryOrderLinks字段。Flink和Blink指向LIST_ENTRY结构体的指针。
让我们一步一步的梳理:
1.读取PEB结构2.跳转到0xC偏移处读取Ldr指针3.跳转到0x14偏移处读取 InMemoryOrderModuleList字段现在,我们来到了加载至内存首个模块的InMemoryOrderLinks元素。这个模块是可执行文件(例如calc.exe)。我们想要遍历所有已加载的DLL文件。InMemoryOrderLinks是一个LIST_ENTRY结构体,前面4个字节是Flink指针,而后面4个字节是Blink指针,通过前面的4个字节可以帮助我们遍历到第2个已加载模块。只需再次执行这个过程,我们便可以访问到第3个已加载模块的信息。
InMemoryOrderModuleList链表按照如下次序显示所有已加载模块:
1. calc.exe (可执行文件)2. ntdll.dll3. kernel32.dll 正如在第1部分中讨论的,我们需要访问kernel32.dll ,以便调用类似GetProcAddress 和 LoadLibrary函数,帮助我们再调用其他Windows API函数。
为达到此目的,我们需要从当前的LDR_DATA_TABLE_ENTRY结构体上读取Dllbase字段(DLL加载到内存中的位置)。DLLBase位于此结构的0×18偏移处。但是考虑到InMemoryOrderLinks字段又位于LDR_DATA_TABLE_ENTRY 结构体0×8偏移处,因此为获取获取DllBase,现在我们只需要偏移0×10个字节。下面是查找kernel32.dll内存地址所需步骤的概述:

虽然绘画不是那么出色,但希望你可以明白其中的工作原理。你只需了解使用“Flink”指针就可以遍历所有已加载模块。别让这张图给吓着了,接下来你将会看到,我们完全可以在8行左右的代码内实现这个遍历操作。
二、PE文件格式
可移植的可执行文件(PE)是Windows系统上可执行文件和动态链接库所使用的文件格式。此格式描述这些文件所包含的内容:头(header)及包含所有代码和数据的节(Section,又称区段、区块等)。网上有许多介绍PE文件格式的文件爱你,但我们在这里只介绍编写shellcode所必需的信息:头(header),节(section)和导出表。
PE文件的简单示意图:
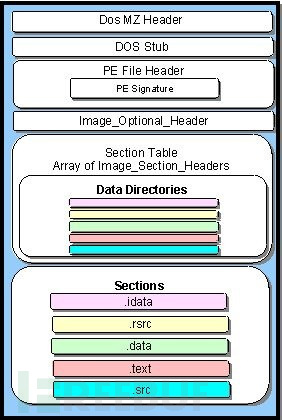
正如你在这图片中所看到的,PE文件包含:
DOS头DOS存根(stub)PE头节表节(代码和数据节)使用hex editor工具打开PE文件,可以给我们带来更详尽的内容:
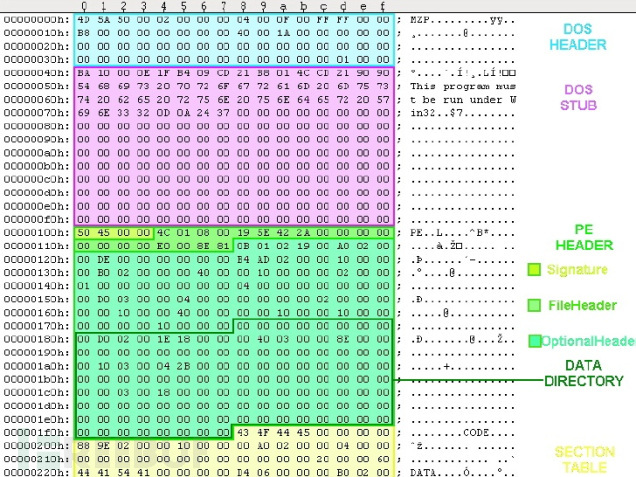
PE格式是相当复杂的,但我们只需了解如何解析PE头部来获取导出函数。让我们先从DOS头开始,DOS头可以表示成如下结构:
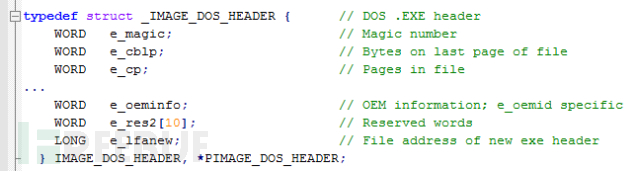
你可以在C/C++编译器的“WinNT.h”头部文件中找到完整的结构定义以及所需的其他结构。所有的PE文件(EXE或DLL)都是从这个结构开始。因此,如果在内存中找到某个模块,我们也会在那个内存地址上找到这个结构体。你可以通过前两个字节“MZ”来识别,这两个字节是e_magic 字段,表示DOS头的“签名”。
我们只需要了解该结构的 e_lfanew 字段。这个字段位于0x3C偏移处,它指出了PE头所的位置。PE头是包含了如下信息的结构体:
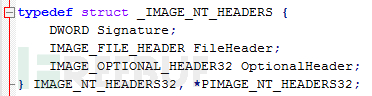
它包含PE签名(如果使用编辑器打开一个PE文件,你可以看到“PE”字符串)。FileHeader是一个结构体,包含诸如节(代码和数据)数目、机器类型(X86,X64,ARM),以及“特征(characteristics)”等信息,可以用来判断文件是可执行文件文件(.exe)还是动态链接库(.dll)。
对于我们而言,OptionalHeader(可选头)是一个包含更多有用信息的结构体:
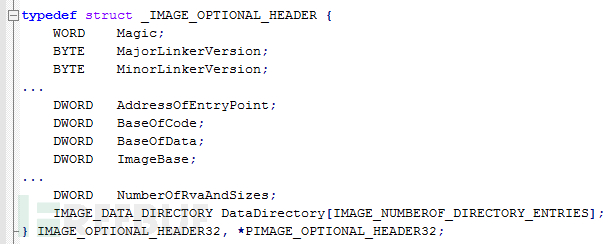
它包含以下信息:
AddressOfEntryPoint:exe/dll 开始执行代码的地址,即入口点地址。ImageBase:DLL加载到内存中的地址,即映像基址。DataDirectory-导入或导出函数等信息。我们只对最后一个字段感兴趣, DataDirectory,因为需要获得导出函数。DLL的工作原理:它包含各种函数的定义,然后再将这些函数导出。所以其他应用程序只需将这个DLL加载到内存,然后查找导出函数并进行调用。例如,“MessageBox”是一个“user32.dll”的导出函数(实际上,这个函数有两个版本:ASCII和Unicode)。
此结构的 DataDirectory字段是由 IMAGE_DATA_DIRECTORY 元素组成的数组。 IMAGE_DATA_DIRECTORY结构的定义如下:
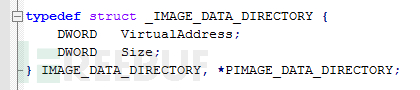
IMAGE_DATA_DIRECTORY结构(16字节)位于OptionalHeader(可选头)结构体的最后。对于我们而言,只需要了解第1个数据目录是“导出目录”。
为了访问导出目录,我们只需跟随这个结构的 VirtualAddress(相对虚拟地址)字段,它指向导出目录的开始位置。 DWORD是占用4个字节的数据类型,而 WORD仅占用2个字节。如果你计算截止到DataDirectory数组所有元素占用空间的大小,你会发现从PE头的起始位置到 DataDirectory数组的起始位置一共是120字节(0×78)。所以我们可以在0×78偏移处找到输出目录的相对虚拟地址(VirtualAddress字段)。
导出目录的结构如下:
我们将会使用这个结构的如下字段:
AddressOfFunctions:指向一个DWORD类型的数组,每个数组元素指向一个函数地址。AddressOfNames:指向一个DWORD类型的数组,每个数组元素指向一个函数名称的字符串。AddressOfNameOrdinals:指向一个WORD类型的数组,每个数组元素表示相应函数的排列序号(16位整数)。接下以包含3个函数的DLL文件作为示例:
AddressOfFunctions = 0x11223344 -> [0x11111111, 0x22222222, 0x33333333]:0x11223344指向一个数组,该数组包含函数的地址:0x11111111,0x22222222和0x33333333。AddressOfNames = 0x12345678 -> [0xaaaaaaaa -> “func0”, 0xbbbbbbbb -> “func1”, 0xcccccccc -> “func2”] :0x12345678是指向一个数组,其中数组元素指向函数名称字符串:例如0xaaaaaaaa指向字符串“func1”,即导出函数的名称。AddressOfNameOrdinals = 0xabcdef —> [0x00, 0x01, 0x02] :0xabcdef是一个指向整数(16位)数组,数组元素表示相应函数在AddressOfFunctions数组上的偏移值。为利用函数名称获取函数地址,我们需要通过解析 AddressOfNames数组来检查名称。第1个函数(func0)的序号是0,第2个函数(func1)的序号是1,而第3个函数(func2)的序号是2。因此,如果我们需要查找函数func2的地址,我们只需访问 AddressOfFunctions数组的第2个元素(从0开始编号)。
总之,就像这样:
函数地址=AddressOfFunctions[ 序号(函数名称) ]
别被吓到了,接下来你会看到,我们完全可以使用15-20行的汇编代码来搞定所有事情。
三、汇编语言
正如你在文本中看到的,我们完全可以使用C/C++高级语言来编写shellcode。 但若想要正确地了解Shellcode是什么,Shellcode如何工作,以及如何修改Shellcode,你需要理解和编写汇编代码。
本章节仅提供汇编语言的一些基本知识。要想深入理解汇编语言,请不要依赖本章节,你可以阅读一下诸如此类的好文章。本文的介绍并不是很完整,仅覆盖一些常见操作,从而让大家具备编写简单shellcode的能力。
为避免因不同汇编语言差异而导致的复杂性,以下编写的示例都是使用Microsoft Visual C++ Express版编译器上的内部汇编语言编译器。当然,你也可以使用像MASM, NASM 或YASM之类的汇编语言编译器。
首先让我们从开“变量”开始。处理器使用不同的寄存器(当变量考虑)来存储临时数据。每个寄存器都具有各自的用途,但是这里我们将其统一视为“全局变量”。更详细的介绍,你可以阅读这篇文章。
通用寄存器:EAX,EBX,ECX,EDX,ESI和EDI。每个寄存器都可以存储4字节的数据。同时,它们最后2个字节也可以单独称作AX,BX,CX,DX,SI和DI。最后1个字节可以AL,BL,CL,DL的名称来访问。
比方说程序从0×12345678地址开始执行。其中有一个特定寄存器保存当前执行指令的地址,称作EIP(指令指针)。执行完一条指令之后,这个寄存器会自动更改为下一条指令的地址。现在已经拥有“变量”,让我们看看可以利用它们做些什么。为完成一些有用的操作,我们需要使用多个指令。
指令:
mov 目的,源:把数据从源操作数拷贝到目的操作数。add 目的,源:把源操作数加到目的操作数,或目的操作数=目的操作数+源操作数。sub 目的,源:目的操作数减去源操作数,或目的操作数=目的操作数-源操作数。inc 目的:目的操作数的取值加1dec目的:目的操作数的取值自减1示例:
; Comments can be specified by starting with a ;mov EAX, 5 ; Put value 5 in the EAXadd EAX, 2 ; Add 2 to EAX, EAX will be 7inc EAX ; EAX will be 8mov EBX, 2 ; Store value 2 in EBXsub EAX, EBX ; EAX will be 6你可以像下图一样在Visual C++平台上测试这个程序。
我们可以点击左侧的灰色线框来放置断点,Visual C++调试器将会在断点处暂停程序的执行。当你启动这个程序时,它会在指定的断点处停止运行。此时,你会在开发环境的底部看到“Watch1”窗口。你可以在这个窗口上添加寄存器名称,从而查看它们的取值。所以,添加EAX、EBX等寄存器名称,然后观察它们的取值。

你可以按下F11来单步执行指令,然后在watch窗口上观察寄存器的取值是如何变化的。或者你也可以只把鼠标放在寄存器名称的上方来查看它的取值。请注意这些只是基本的调试操作,要获得更高级的调试功能,你可以使用像Immunity Debugger之类的调试器,但是为简单起见,你使用Visual C++自带的调试器即可。
程序的控制流会经过一些决策序列,即通过比较两个数值来采取不同的行为。首先,你需要学会使用标签(label)。标签只是为了标记代码的不同位置。你可以使用“跳转至(jumps)”来访问不同的代码位置。
有用的指令:
jump 地址/标签。无条件地跳转到某个标签或内存地址cmp 目的,源:通过目的操作数减去源操作数来比较目的操作数和源操作数(不改变操作数的值)。“结果”也不会被保存下来,只需记住如果源操作数等于目的操作数,计算机将会设置“Zero Flag”标志位。这个标志位会被接下来的条件转移指令所使用。jz 地址/标签:如果已设置了“Zero Flag”标志位(jz=如果为零就跳转),跳转到指定标签或地址。因此如果之前“cmp”指令所比较的参数是相等的,“Zero Flag”便会被设置,然后代码跳转到指定地址或标签。如果不等,什么事情都不会发生,程序将接着运行下一条指令。jnz 地址/标签:与jz刚好相反(jnz=如果不为零就跳转),如果“Zero Flag”未被设置,代码将会跳转到指定地址。也就是所说,前面的“cmp”指令所比较的参数是不相等的。汇编语言还有许多其他的跳转指令,但这些对入门而言已经足够。作为示例,你可以尝试以下代码:

现在,让我们把话题转到汇编语言的重点内容:栈。栈是一种内存中的数据结构,你可以在其中存储数据。你可以将其视为一块内存空间,然后像堆叠盘子一样存放数据,一个数据放在另一个数据的上面,而你只可以从顶部取数据。
关于栈,有两条非常有用的指令:
push 数据:把数据压入栈中pop 寄存器:从栈顶取出数据,然后存储在指定的寄存器 同时,有两个寄存器“指向”栈:
ESP寄存器(栈指针):指向栈顶EBP寄存器(基指针,或帧指针):指向栈底在与栈打交道时,会发生一些重要的事情。比如ESP,表示栈顶,取值为0×11223344。如果我们通过“push 0xaaaaaaaa”指令把4字节的数据压入栈中,0xaaaaaaaa数据会存入栈的顶部,而ESP取值会减少4个字节。所以,我们可以说栈是往低地址空间增长的。在push指令之后,ESP的取值将会变为0×11223340。
如果我们从栈上获取数据,情况便会颠倒过来:数据从栈上移除(实际上,由于编译优化的原因,数据仍存储那里,未被清除),ESP取值会增加4个字节。
看似困难,其实不然。例如:

思考一下栈上的数学运算,假定我们在栈上压入0×20字节的数据(通过8条push指令,0×20=32),我们可以只修改ESP值来轻易地清理栈上的空间:addESP, 0×20。这比8条pop指令更为简单有效。现在我们学习调用函数。有两种常见的函数调用方式:stdcall和cdecl。WindowsAPI使用stdcall调用约定(方式),我们仅讨论这种函数调用方式。不过,它们是类似的,你可以从这里找到更多的信息。让我们以下面的函数作为示例:
int function(int x, int y){ return x + y;}若要调用function(0×11,0×22),我们需要了解以下内容:
1.从右往左把参数压入栈中。2.使用“call function”指令来调用函数3.call指令会自动地把下一条指令的地址压入栈中(ESP的取值也会减小)4.函数返回后,EAX寄存器会保存函数执行的结果。
在该函数执行完成之后,EAX寄存器的值为0×33(0×11+0×22=0×33)。
所以,这些是汇编的基础知识。不过,我们也会在shellcode中使用其他的指令,类似:
xor 目的,源:二进制操作,但是我们只会像“xor eax, eax”这样使用该指令。这条命令会把eax寄存器赋值为0。lea 目的,源(取有效地址):主要功能是把源操作数指定的内存地址存入目的操作数。lodsd:把ESI寄存器指定地址的数据存入EAX寄存器。xchg 目的,源-交换操作数的值:源操作数将会取得目的操作数的值,而目的操作数也会取得源操作数的值。汇编语言是一门难度颇大的语言,但如果你循序渐进的学习,要掌握它也并非难事。
四、总结
即使还没有编写任何的shellcode,但我们已经学习了编写shellcode所需要的全部知识,具备了编写基本shellcode的能力。我们了解到什么是PEB及其如何帮助编写shellcode,PE文件的组成,甚至还编写了几行简单的汇编代码。在下一部分,我们将会实际地编写一个shellcode,同时也会利用本文和第1部分学习的内容来实现有用的功能。接下来,我们将会把这里所学的知识付诸实践。
- Windows平台shellcode开发入门(二)
- Windows平台shellcode开发入门(一)
- Windows平台shellcode开发入门(三)
- 黑客攻防入门(二)shellcode构造
- windows下shellcode编写入门
- windows下shellcode编写入门
- JNI初探二(windows平台开发)
- Windows Phone8 开发入门(二)
- 【Facebook的UI开发框架React入门之二】开发环境搭建(iOS平台)-goodmao
- Hibernate入门篇(二)——开发平台以及环境搭建
- Eclipse平台入门之二:开发环境与实例
- 100个windows平台C++开发错误之二十
- Advances in Windows Shellcode
- windows下shellcode检测工具
- 所有windows可用shellcode
- 通用shellcode的编写、调用 实验缓冲区溢出攻击(非远程)调用shellcode实例(二)
- Android开发入门(二)
- Servlet开发入门(二)
- No mapping found for HTTP request with URI问题
- Jpeg的文件信息
- asp.net 前台绑定后台变量方法总结
- SQL Server 存储过程
- HEVC sad计算函数
- Windows平台shellcode开发入门(二)
- linux下删除乱码文件名的方法
- grunt-contrib-requirejs插件合并压缩requirejs管理的Angularjs应用
- 排序、检索 2016.2.5
- 高德地图坐标转换
- C++经典面试算法题
- Windows平台shellcode开发入门(三)
- While reindexing loaded db appear: Java HotSpot(TM) 64-Bit Server VM warning: Attempt to allocate st
- android并发请求处理


