理解文章《Notes on Convolutinal Neural Networks》
来源:互联网 发布:dbc网络用语 编辑:程序博客网 时间:2024/05/16 06:03
http://ufldl.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B
本文属于学习文章,非商业用途。
====================================================================
开始的第一个练习是:稀疏自编码器
- 第一部分就是神经网络的简单概述

输入的是:训练样本集 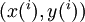 ;输出的是:
;输出的是: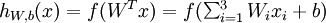 。
。
其中f为激活函数,常用的两个激活函数:
sigmoid函数----------->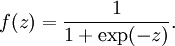
双曲正切函数(tanh)------------>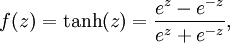
但是一直有个问题就是激活函数作用?
激活函数的选择是构建神经网络过程中的重要环节,下面简要介绍常用的激活函数。
(1) 线性函数 ( Liner Function )

(2) 斜面函数 ( Ramp Function )

(3) 阈值函数 ( Threshold Function )


图2 . 阈值函数图像
以上3个激活函数都是线性函数,下面介绍两个常用的非线性激活函数。
(4) S形函数 ( Sigmoid Function )

该函数的导函数:

(5) 双极S形函数

该函数的导函数:

S形函数与双极S形函数的图像如下:

图3. S形函数与双极S形函数图像
双极S形函数与S形函数主要区别在于函数的值域,双极S形函数值域是(-1,1),而S形函数值域是(0,1)。
由于S形函数与双极S形函数都是可导的(导函数是连续函数),因此适合用在BP神经网络中。(BP算法要求激活函数可导)
激活函数(activation function)是用来加入非线性因素的,因为线性模型的表达能力不够。以下,同种颜色为同类数据。某些数据是线性可分的,意思是,可以用一条直线将数据分开。比如下图:
这时候你需要通过一定的机器学习的方法,比如感知机算法(perceptron learning algorithm) 找到一个合适的线性方程。
但是有些数据不是线性可分的。比如如下数据:

第二组数据你就没有办法画出一条直线来将数据区分开。
这时候有两个办法,第一个办法,是做线性变换(linear transformation),比如讲x,y变成x^2,y^2,这样可以画出圆形。如图所示:
如果将坐标轴从x,y变为以x^2,y^2为标准,你会发现数据经过变换后是线性可分的了。大致示意图如下:


另外一种方法是引入非线性函数。我们来看异或问题(xor problem)。以下是xor真值表

这个真值表不是线性可分的,所以不能使用线性模型,如图所示

我们可以设计一种神经网络,通过激活函数来使得这组数据线性可分。
激活函数我们选择阀值函数(threshold function),也就是大于某个值输出1(被激活了),小于等于则输出0(没有激活)。这个函数是非线性函数。
神经网络示意图如下:

其中直线上的数字为权重。圆圈中的数字为阀值。第二层,如果输入大于1.5则输出1,否则0;第三层,如果输入大于0.5,则输出1,否则0.
我们来一步步算。
第一层到第二层(阀值1.5)

第二层到第三层(阀值0.5)

可以看到第三层输出就是我们所要的xor的答案。
经过变换后的数据是线性可分的(n维,比如本例中可以用平面),如图所示:

总而言之,激活函数可以引入非线性因素,解决线性模型所不能解决的问题。
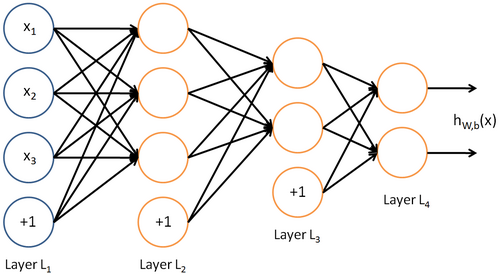
然后就是网络模型:
所谓神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。例如,下图就是一个简单的神经网络:
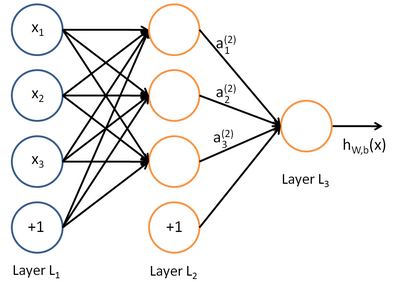
我们使用圆圈来表示神经网络的输入,标上“ ”的圆圈被称为偏置节点,也就是截距项。神经网络最左边的一层叫做输入层,最右的一层叫做输出层(本例中,输出层只有一个节点)。中间所有节点组成的一层叫做隐藏层,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及一个输出单元。
”的圆圈被称为偏置节点,也就是截距项。神经网络最左边的一层叫做输入层,最右的一层叫做输出层(本例中,输出层只有一个节点)。中间所有节点组成的一层叫做隐藏层,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及一个输出单元。
神经网络也可以有多个输出单元。下面的神经网络有两层隐藏层: 及
及 ,输出层
,输出层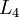 有两个输出单元。
有两个输出单元。
- 第二部分就是反向传导算法
假设我们有一个固定样本集 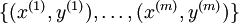 ,它包含
,它包含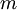 个样例。我们可以用批量梯度下降法来求解神经网络。具体来讲,对于单个样例
个样例。我们可以用批量梯度下降法来求解神经网络。具体来讲,对于单个样例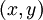 ,其代价函数为:
,其代价函数为:
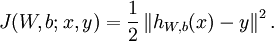
这是一个(二分之一的)方差代价函数。给定一个包含 个样例的数据集,我们可以定义整体代价函数为:
![\begin{align}J(W,b)&= \left[ \frac{1}{m} \sum_{i=1}^m J(W,b;x^{(i)},y^{(i)}) \right] + \frac{\lambda}{2} \sum_{l=1}^{n_l-1} \; \sum_{i=1}^{s_l} \; \sum_{j=1}^{s_{l+1}} \left( W^{(l)}_{ji} \right)^2 \\&= \left[ \frac{1}{m} \sum_{i=1}^m \left( \frac{1}{2} \left\| h_{W,b}(x^{(i)}) - y^{(i)} \right\|^2 \right) \right] + \frac{\lambda}{2} \sum_{l=1}^{n_l-1} \; \sum_{i=1}^{s_l} \; \sum_{j=1}^{s_{l+1}} \left( W^{(l)}_{ji} \right)^2\end{align}](http://ufldl.stanford.edu/wiki/images/math/4/5/3/4539f5f00edca977011089b902670513.png)
以上公式中的第一项 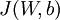 是一个均方差项。第二项是一个规则化项(也叫权重衰减项),其目的是减小权重的幅度,防止过度拟合。
是一个均方差项。第二项是一个规则化项(也叫权重衰减项),其目的是减小权重的幅度,防止过度拟合。
[注:通常权重衰减的计算并不使用偏置项 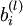 ,比如我们在 的定义中就没有使用。一般来说,将偏置项包含在权重衰减项中只会对最终的神经网络产生很小的影响。如果你在斯坦福选修过CS229(机器学习)课程,或者在YouTube上看过课程视频,你会发现这个权重衰减实际上是课上提到的贝叶斯规则化方法的变种。在贝叶斯规则化方法中,我们将高斯先验概率引入到参数中计算MAP(极大后验)估计(而不是极大似然估计)。]
,比如我们在 的定义中就没有使用。一般来说,将偏置项包含在权重衰减项中只会对最终的神经网络产生很小的影响。如果你在斯坦福选修过CS229(机器学习)课程,或者在YouTube上看过课程视频,你会发现这个权重衰减实际上是课上提到的贝叶斯规则化方法的变种。在贝叶斯规则化方法中,我们将高斯先验概率引入到参数中计算MAP(极大后验)估计(而不是极大似然估计)。]
权重衰减参数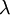 用于控制公式中两项的相对重要性。在此重申一下这两个复杂函数的含义:
用于控制公式中两项的相对重要性。在此重申一下这两个复杂函数的含义: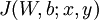 是针对单个样例计算得到的方差代价函数; 是整体样本代价函数,它包含权重衰减项。
是针对单个样例计算得到的方差代价函数; 是整体样本代价函数,它包含权重衰减项。
以上的代价函数经常被用于分类和回归问题。在分类问题中,我们用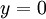 或
或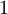 ,来代表两种类型的标签(回想一下,这是因为 sigmoid激活函数的值域为
,来代表两种类型的标签(回想一下,这是因为 sigmoid激活函数的值域为![\textstyle [0,1]](http://ufldl.stanford.edu/wiki/images/math/8/4/2/84235d31ac83fe764546463aba7acc0e.png) ;如果我们使用双曲正切型激活函数,那么应该选用
;如果我们使用双曲正切型激活函数,那么应该选用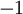 和 作为标签)。对于回归问题,我们首先要变换输出值域(译者注:也就是
和 作为标签)。对于回归问题,我们首先要变换输出值域(译者注:也就是 ),以保证其范围为 (同样地,如果我们使用双曲正切型激活函数,要使输出值域为
),以保证其范围为 (同样地,如果我们使用双曲正切型激活函数,要使输出值域为![\textstyle [-1,1]](http://ufldl.stanford.edu/wiki/images/math/8/5/a/85a1c5a07f21a9eebbfb1dca380f8d38.png) )。
)。
我们的目标是针对参数 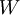 和
和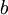 来求其函数 的最小值。为了求解神经网络,我们需要将每一个参数
来求其函数 的最小值。为了求解神经网络,我们需要将每一个参数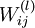 和 初始化为一个很小的、接近零的随机值(比如说,使用正态分布
和 初始化为一个很小的、接近零的随机值(比如说,使用正态分布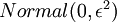 生成的随机值,其中
生成的随机值,其中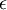 设置为
设置为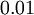 ),之后对目标函数使用诸如批量梯度下降法的最优化算法。因为 是一个非凸函数,梯度下降法很可能会收敛到局部最优解;但是在实际应用中,梯度下降法通常能得到令人满意的结果。最后,需要再次强调的是,要将参数进行随机初始化,而不是全部置为
),之后对目标函数使用诸如批量梯度下降法的最优化算法。因为 是一个非凸函数,梯度下降法很可能会收敛到局部最优解;但是在实际应用中,梯度下降法通常能得到令人满意的结果。最后,需要再次强调的是,要将参数进行随机初始化,而不是全部置为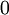 。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,对于所有
。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,对于所有 ,
,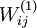 都会取相同的值,那么对于任何输入
都会取相同的值,那么对于任何输入 都会有:
都会有: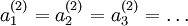 )。随机初始化的目的是使对称失效。
)。随机初始化的目的是使对称失效。
梯度下降法中每一次迭代都按照如下公式对参数 和 进行更新:
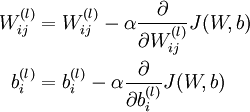 (个人理解就是每次按照梯度减少的方向变化多少,然后再更新参数)
(个人理解就是每次按照梯度减少的方向变化多少,然后再更新参数)
其中 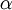 是学习速率。其中关键步骤是计算偏导数。我们现在来讲一下反向传播算法,它是计算偏导数的一种有效方法。
是学习速率。其中关键步骤是计算偏导数。我们现在来讲一下反向传播算法,它是计算偏导数的一种有效方法。
我们首先来讲一下如何使用反向传播算法来计算 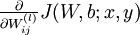 和
和 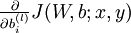 ,这两项是单个样例 的代价函数 的偏导数。一旦我们求出该偏导数,就可以推导出整体代价函数 的偏导数:
,这两项是单个样例 的代价函数 的偏导数。一旦我们求出该偏导数,就可以推导出整体代价函数 的偏导数:
![\begin{align}\frac{\partial}{\partial W_{ij}^{(l)}} J(W,b) &=\left[ \frac{1}{m} \sum_{i=1}^m \frac{\partial}{\partial W_{ij}^{(l)}} J(W,b; x^{(i)}, y^{(i)}) \right] + \lambda W_{ij}^{(l)} \\\frac{\partial}{\partial b_{i}^{(l)}} J(W,b) &=\frac{1}{m}\sum_{i=1}^m \frac{\partial}{\partial b_{i}^{(l)}} J(W,b; x^{(i)}, y^{(i)})\end{align}](http://ufldl.stanford.edu/wiki/images/math/9/3/3/93367cceb154c392aa7f3e0f5684a495.png)
以上两行公式稍有不同,第一行比第二行多出一项,是因为权重衰减是作用于 而不是。
反向传播算法的思路如下:给定一个样例 ,我们首先进行“前向传导”运算,计算出网络中所有的激活值,包括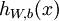 的输出值。之后,针对第
的输出值。之后,针对第 层的每一个节点,我们计算出其“残差”
层的每一个节点,我们计算出其“残差”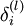 ,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为
,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为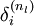 (第
(第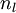 层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第
层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第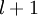 层节点)残差的加权平均值计算,这些节点以
层节点)残差的加权平均值计算,这些节点以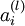 作为输入。下面将给出反向传导算法的细节:
作为输入。下面将给出反向传导算法的细节:
- 进行前馈传导计算,利用前向传导公式,得到
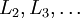 直到输出层
直到输出层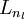 的激活值。
的激活值。 - 对于第 层(输出层)的每个输出单元,我们根据以下公式计算残差:
- 对
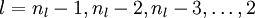 的各个层,第 层的第 个节点的残差计算方法如下:
的各个层,第 层的第 个节点的残差计算方法如下: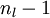 与的关系替换为与的关系,就可以得到:
与的关系替换为与的关系,就可以得到: - 计算我们需要的偏导数,计算方法如下:
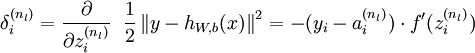
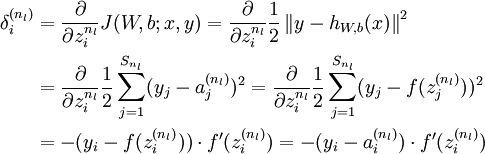
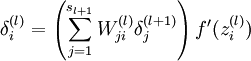
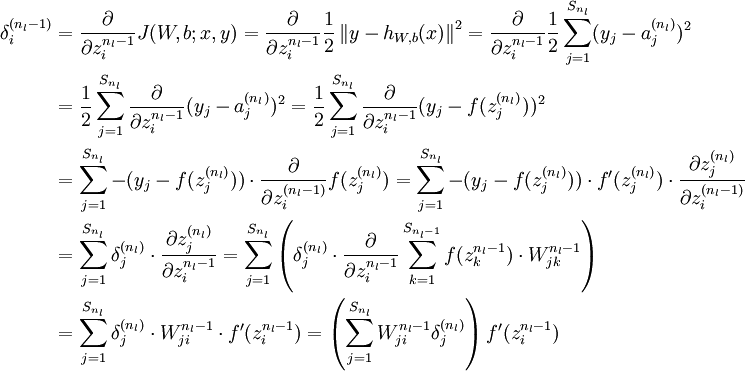
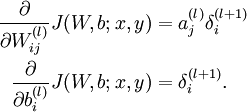
(残差的具体推导如下:)
最后,我们用矩阵-向量表示法重写以上算法。我们使用“ ” 表示向量乘积运算符(在Matlab或Octave里用“.*”表示,也称作阿达马乘积)。若
” 表示向量乘积运算符(在Matlab或Octave里用“.*”表示,也称作阿达马乘积)。若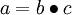 ,则
,则 。在上一个教程中我们扩展了
。在上一个教程中我们扩展了 的定义,使其包含向量运算,这里我们也对偏导数
的定义,使其包含向量运算,这里我们也对偏导数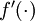 也做了同样的处理(于是又有
也做了同样的处理(于是又有![\textstyle f'([z_1, z_2, z_3]) = [f'(z_1), f'(z_2), f'(z_3)]](http://ufldl.stanford.edu/wiki/images/math/c/7/5/c7515c53b59e670ceee277e06c1229cb.png) )。
)。

那么,反向传播算法可表示为以下几个步骤:
- 进行前馈传导计算,利用前向传导公式,得到直到输出层 的激活值。
- 对输出层(第 层),计算:
- 对于 的各层,计算:
- 计算最终需要的偏导数值:
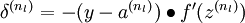
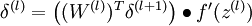
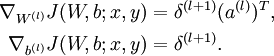
实现中应注意:在以上的第2步和第3步中,我们需要为每一个 值计算其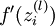 。假设
。假设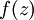 是sigmoid函数,并且我们已经在前向传导运算中得到了。那么,使用我们早先推导出的
是sigmoid函数,并且我们已经在前向传导运算中得到了。那么,使用我们早先推导出的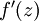 表达式,就可以计算得到
表达式,就可以计算得到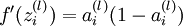 。
。
最后,我们将对梯度下降算法做个全面总结。在下面的伪代码中,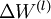 是一个与矩阵
是一个与矩阵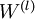 维度相同的矩阵,
维度相同的矩阵,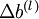 是一个与
是一个与 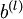 维度相同的向量。注意这里“”是一个矩阵,而不是“
维度相同的向量。注意这里“”是一个矩阵,而不是“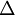 与 相乘”。下面,我们实现批量梯度下降法中的一次迭代:
与 相乘”。下面,我们实现批量梯度下降法中的一次迭代:
- 对于所有 ,令
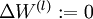 ,
,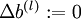 (设置为全零矩阵或全零向量)
(设置为全零矩阵或全零向量) - 对于
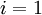 到,
到,- 使用反向传播算法计算
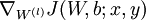 和
和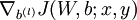 。
。 - 计算
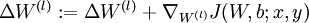 。
。 - 计算
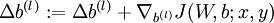 。
。
- 使用反向传播算法计算
- 更新权重参数:
![\begin{align}W^{(l)} &= W^{(l)} - \alpha \left[ \left(\frac{1}{m} \Delta W^{(l)} \right) + \lambda W^{(l)}\right] \\b^{(l)} &= b^{(l)} - \alpha \left[\frac{1}{m} \Delta b^{(l)}\right]\end{align}](http://ufldl.stanford.edu/wiki/images/math/0/f/7/0f7430e97ec4df1bfc56357d1485405f.png)
现在,我们可以重复梯度下降法的迭代步骤来减小代价函数 的值,进而求解我们的神经网络。
- 第三部分就是梯度检验与高级优化,这部分主要介绍算法中注意的东西
反向传播算法很难调试得到正确结果,尤其是当实现程序存在很多难于发现的bug时。举例来说,索引的缺位错误(off-by-one error)会导致只有部分层的权重得到训练,再比如忘记计算偏置项。这些错误会使你得到一个看似十分合理的结果(但实际上比正确代码的结果要差)。因此,但从计算结果上来看,我们很难发现代码中有什么东西遗漏了。本节中,我们将介绍一种对求导结果进行数值检验的方法,该方法可以验证求导代码是否正确。另外,使用本节所述求导检验方法,可以帮助你提升写正确代码的信心。
缺位错误(Off-by-one error)举例说明:比如 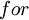 循环中循环次,正确应该是
循环中循环次,正确应该是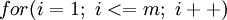 ,但有时程序员疏忽,会写成
,但有时程序员疏忽,会写成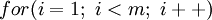 ,这就是缺位错误。
,这就是缺位错误。
假设我们想要最小化以  为自变量的目标函数
为自变量的目标函数 。假设
。假设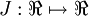 ,则
,则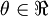 。在一维的情况下,一次迭代的梯度下降公式是
。在一维的情况下,一次迭代的梯度下降公式是
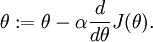
再假设我们已经用代码实现了计算 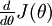 的函数
的函数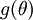 ,接着我们使用
,接着我们使用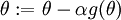 来实现梯度下降算法。那么我们如何检验
来实现梯度下降算法。那么我们如何检验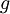 的实现是否正确呢?
的实现是否正确呢?
回忆导数的数学定义:
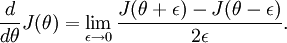
那么对于任意 值,我们都可以对等式左边的导数用:
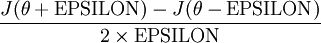
来近似。
实际应用中,我们常将 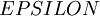 设为一个很小的常量,比如在
设为一个很小的常量,比如在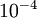 数量级(虽然 的取值范围可以很大,但是我们不会将它设得太小,比如
数量级(虽然 的取值范围可以很大,但是我们不会将它设得太小,比如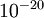 ,因为那将导致数值舍入误差。)
,因为那将导致数值舍入误差。)
给定一个被认为能计算 的函数,我们可以用下面的数值检验公式
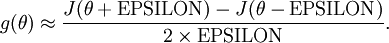
计算两端是否一样来检验函数是否正确。
上式两端值的接近程度取决于 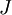 的具体形式。但是在假定
的具体形式。但是在假定 的情况下,你通常会发现上式左右两端至少有4位有效数字是一样的(通常会更多)。
的情况下,你通常会发现上式左右两端至少有4位有效数字是一样的(通常会更多)。
现在,考虑 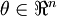 是一个向量而非一个实数(那么就有
是一个向量而非一个实数(那么就有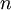 个参数要学习得到),并且
个参数要学习得到),并且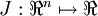 。在神经网络的例子里我们使用,可以想象为把参数
。在神经网络的例子里我们使用,可以想象为把参数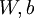 组合扩展成一个长向量。现在我们将求导检验方法推广到一般化,即 是一个向量的情况。
组合扩展成一个长向量。现在我们将求导检验方法推广到一般化,即 是一个向量的情况。
假设我们有一个用于计算 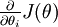 的函数
的函数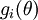 ;我们想要检验
;我们想要检验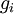 是否输出正确的求导结果。我们定义
是否输出正确的求导结果。我们定义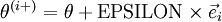 ,其中
,其中
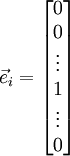
是第 个基向量(维度和 相同,在第 行是“”而其他行是“”)。所以,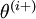 和 几乎相同,除了第 行元素增加了。类似地,
和 几乎相同,除了第 行元素增加了。类似地,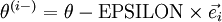 得到的第 行减小了。然后我们可以对每个 检查下式是否成立,进而验证 的正确性:
得到的第 行减小了。然后我们可以对每个 检查下式是否成立,进而验证 的正确性:
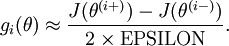
当用反射传播算法求解神经网络时,正确算法实现会得到:
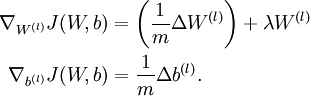
以上结果与反向传播算法中的最后一段伪代码一致,都是计算梯度下降。为了验证梯度下降代码的正确性,使用上述数值检验方法计算 的导数,然后验证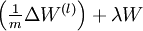 与
与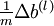 是否能够给出正确的求导结果。
是否能够给出正确的求导结果。
迄今为止,我们的讨论都集中在使用梯度下降法来最小化。如果你已经实现了一个计算 和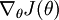 的函数,那么其实还有更精妙的算法来最小化。举例来说,可以想象这样一个算法:它使用梯度下降,并能够自动调整学习速率,以得到合适的步长值,最终使 能够快速收敛到一个局部最优解。还有更妙的算法:比如可以寻找一个Hessian矩阵的近似,得到最佳步长值,使用该步长值能够更快地收敛到局部最优(和牛顿法类似)。此类算法的详细讨论已超出了这份讲义的范围,但是L-BFGS算法我们以后会有论述(另一个例子是共轭梯度算法)。你将在编程练习里使用这些算法中的一个。使用这些高级优化算法时,你需要提供关键的函数:即对于任一个,需要你计算出 和。之后,这些优化算法会自动调整学习速率/步长值 的大小(并计算Hessian近似矩阵等等)来自动寻找 最小化时 的值。诸如L-BFGS和共轭梯度算法通常比梯度下降法快很多。
的函数,那么其实还有更精妙的算法来最小化。举例来说,可以想象这样一个算法:它使用梯度下降,并能够自动调整学习速率,以得到合适的步长值,最终使 能够快速收敛到一个局部最优解。还有更妙的算法:比如可以寻找一个Hessian矩阵的近似,得到最佳步长值,使用该步长值能够更快地收敛到局部最优(和牛顿法类似)。此类算法的详细讨论已超出了这份讲义的范围,但是L-BFGS算法我们以后会有论述(另一个例子是共轭梯度算法)。你将在编程练习里使用这些算法中的一个。使用这些高级优化算法时,你需要提供关键的函数:即对于任一个,需要你计算出 和。之后,这些优化算法会自动调整学习速率/步长值 的大小(并计算Hessian近似矩阵等等)来自动寻找 最小化时 的值。诸如L-BFGS和共轭梯度算法通常比梯度下降法快很多。
- 第四部分就是自编码算法与稀疏性
在有监督学习中,训练样本是有类别标签的。现在假设我们只有一个没有带类别标签的训练样本集合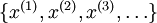 ,其中
,其中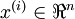 。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如
。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如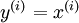 。下图是一个自编码神经网络的示例。
。下图是一个自编码神经网络的示例。
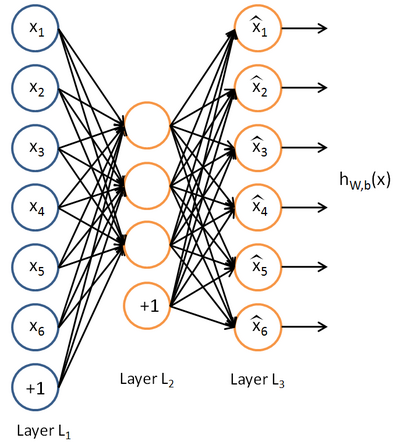
自编码神经网络尝试学习一个 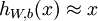 的函数。换句话说,它尝试逼近一个恒等函数,从而使得输出
的函数。换句话说,它尝试逼近一个恒等函数,从而使得输出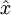 接近于输入 。恒等函数虽然看上去不太有学习的意义,但是当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 是一张
接近于输入 。恒等函数虽然看上去不太有学习的意义,但是当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 是一张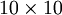 图像(共100个像素)的像素灰度值,于是
图像(共100个像素)的像素灰度值,于是 ,其隐藏层 中有50个隐藏神经元。注意,输出也是100维的
,其隐藏层 中有50个隐藏神经元。注意,输出也是100维的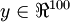 。由于只有50个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从50维的隐藏神经元激活度向量
。由于只有50个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从50维的隐藏神经元激活度向量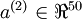 中重构出100维的像素灰度值输入 。如果网络的输入数据是完全随机的,比如每一个输入
中重构出100维的像素灰度值输入 。如果网络的输入数据是完全随机的,比如每一个输入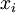 都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自编码神经网络通常可以学习出一个跟主元分析(PCA)结果非常相似的输入数据的低维表示。
都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自编码神经网络通常可以学习出一个跟主元分析(PCA)结果非常相似的输入数据的低维表示。
我们刚才的论述是基于隐藏神经元数量较小的假设。但是即使隐藏神经元的数量较大(可能比输入像素的个数还要多),我们仍然通过给自编码神经网络施加一些其他的限制条件来发现输入数据中的结构。具体来说,如果我们给隐藏神经元加入稀疏性限制,那么自编码神经网络即使在隐藏神经元数量较多的情况下仍然可以发现输入数据中一些有趣的结构。
稀疏性可以被简单地解释如下。如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。这里我们假设的神经元的激活函数是sigmoid函数。如果你使用tanh作为激活函数的话,当神经元输出为-1的时候,我们认为神经元是被抑制的。
注意到 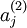 表示隐藏神经元
表示隐藏神经元 的激活度,但是这一表示方法中并未明确指出哪一个输入 带来了这一激活度。所以我们将使用
的激活度,但是这一表示方法中并未明确指出哪一个输入 带来了这一激活度。所以我们将使用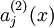 来表示在给定输入为 情况下,自编码神经网络隐藏神经元 的激活度。 进一步,让
来表示在给定输入为 情况下,自编码神经网络隐藏神经元 的激活度。 进一步,让
![\begin{align}\hat\rho_j = \frac{1}{m} \sum_{i=1}^m \left[ a^{(2)}_j(x^{(i)}) \right]\end{align}](http://ufldl.stanford.edu/wiki/images/math/8/7/2/8728009d101b17918c7ef40a6b1d34bb.png)
表示隐藏神经元 的平均活跃度(在训练集上取平均)。我们可以近似的加入一条限制
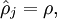
其中, 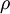 是稀疏性参数,通常是一个接近于0的较小的值(比如
是稀疏性参数,通常是一个接近于0的较小的值(比如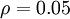 )。换句话说,我们想要让隐藏神经元 的平均活跃度接近0.05。为了满足这一条件,隐藏神经元的活跃度必须接近于0。
)。换句话说,我们想要让隐藏神经元 的平均活跃度接近0.05。为了满足这一条件,隐藏神经元的活跃度必须接近于0。
为了实现这一限制,我们将会在我们的优化目标函数中加入一个额外的惩罚因子,而这一惩罚因子将惩罚那些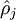 和 有显著不同的情况从而使得隐藏神经元的平均活跃度保持在较小范围内。惩罚因子的具体形式有很多种合理的选择,我们将会选择以下这一种:
和 有显著不同的情况从而使得隐藏神经元的平均活跃度保持在较小范围内。惩罚因子的具体形式有很多种合理的选择,我们将会选择以下这一种:
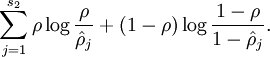
这里, 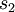 是隐藏层中隐藏神经元的数量,而索引 依次代表隐藏层中的每一个神经元。如果你对相对熵(KL divergence)比较熟悉,这一惩罚因子实际上是基于它的。于是惩罚因子也可以被表示为
是隐藏层中隐藏神经元的数量,而索引 依次代表隐藏层中的每一个神经元。如果你对相对熵(KL divergence)比较熟悉,这一惩罚因子实际上是基于它的。于是惩罚因子也可以被表示为
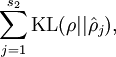
其中 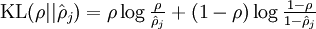 是一个以 为均值和一个以 为均值的两个伯努利随机变量之间的相对熵。相对熵是一种标准的用来测量两个分布之间差异的方法。(如果你没有见过相对熵,不用担心,所有你需要知道的内容都会被包含在这份笔记之中。)
是一个以 为均值和一个以 为均值的两个伯努利随机变量之间的相对熵。相对熵是一种标准的用来测量两个分布之间差异的方法。(如果你没有见过相对熵,不用担心,所有你需要知道的内容都会被包含在这份笔记之中。)
这一惩罚因子有如下性质,当 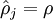 时
时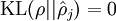 ,并且随着 与 之间的差异增大而单调递增。举例来说,在下图中,我们设定
,并且随着 与 之间的差异增大而单调递增。举例来说,在下图中,我们设定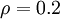 并且画出了相对熵值
并且画出了相对熵值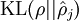 随着 变化的变化。
随着 变化的变化。
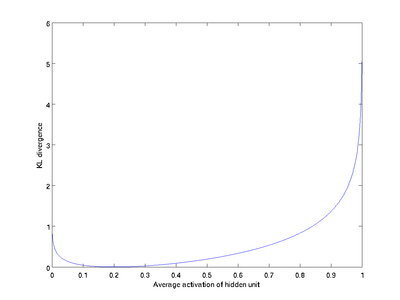
我们可以看出,相对熵在 时达到它的最小值0,而当 靠近0或者1的时候,相对熵则变得非常大(其实是趋向于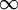 )。所以,最小化这一惩罚因子具有使得 靠近 的效果。 现在,我们的总体代价函数可以表示为
)。所以,最小化这一惩罚因子具有使得 靠近 的效果。 现在,我们的总体代价函数可以表示为
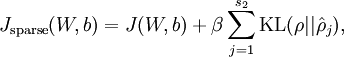
其中 如之前所定义,而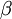 控制稀疏性惩罚因子的权重。 项则也(间接地)取决于 ,因为它是隐藏神经元 的平均激活度,而隐藏层神经元的激活度取决于 。
控制稀疏性惩罚因子的权重。 项则也(间接地)取决于 ,因为它是隐藏神经元 的平均激活度,而隐藏层神经元的激活度取决于 。
为了对相对熵进行导数计算,我们可以使用一个易于实现的技巧,这只需要在你的程序中稍作改动即可。具体来说,前面在后向传播算法中计算第二层( )更新的时候我们已经计算了
)更新的时候我们已经计算了
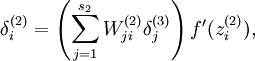
现在我们将其换成
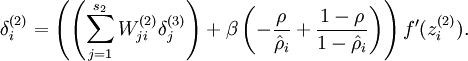
(开始推倒上面这个带惩罚因子的残差推了很久推不出来,然后搜索了一下熵的定义,教程中应该意思是log=ln就可以了。)
有一个需要注意的地方就是我们需要知道 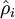 来计算这一项更新。所以在计算任何神经元的后向传播之前,你需要对所有的训练样本计算一遍前向传播,从而获取平均激活度。如果你的训练样本可以小到被整个存到内存之中(对于编程作业来说,通常如此),你可以方便地在你所有的样本上计算前向传播并将得到的激活度存入内存并且计算平均激活度 。然后你就可以使用事先计算好的激活度来对所有的训练样本进行后向传播的计算。如果你的数据量太大,无法全部存入内存,你就可以扫过你的训练样本并计算一次前向传播,然后将获得的结果累积起来并计算平均激活度 (当某一个前向传播的结果中的激活度
来计算这一项更新。所以在计算任何神经元的后向传播之前,你需要对所有的训练样本计算一遍前向传播,从而获取平均激活度。如果你的训练样本可以小到被整个存到内存之中(对于编程作业来说,通常如此),你可以方便地在你所有的样本上计算前向传播并将得到的激活度存入内存并且计算平均激活度 。然后你就可以使用事先计算好的激活度来对所有的训练样本进行后向传播的计算。如果你的数据量太大,无法全部存入内存,你就可以扫过你的训练样本并计算一次前向传播,然后将获得的结果累积起来并计算平均激活度 (当某一个前向传播的结果中的激活度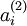 被用于计算平均激活度 之后就可以将此结果删除)。然后当你完成平均激活度 的计算之后,你需要重新对每一个训练样本做一次前向传播从而可以对其进行后向传播的计算。对于后一种情况,你对每一个训练样本需要计算两次前向传播,所以在计算上的效率会稍低一些。
被用于计算平均激活度 之后就可以将此结果删除)。然后当你完成平均激活度 的计算之后,你需要重新对每一个训练样本做一次前向传播从而可以对其进行后向传播的计算。对于后一种情况,你对每一个训练样本需要计算两次前向传播,所以在计算上的效率会稍低一些。

证明上面算法能达到梯度下降效果的完整推导过程不再本教程的范围之内。不过如果你想要使用经过以上修改的后向传播来实现自编码神经网络,那么你就会对目标函数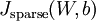 做梯度下降。使用梯度验证方法,你可以自己来验证梯度下降算法是否正确。
做梯度下降。使用梯度验证方法,你可以自己来验证梯度下降算法是否正确。
- 第五部分就是教程中的可视化自编码器训练结果
训练完(稀疏)自编码器。在10×10图像(即n=100)上训练自编码器为例。在该自编码器中,每个隐藏单元i对如下关于输入的函数进行计算:
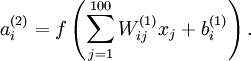
我们将要可视化的函数,就是上面这个以2D图像为输入、并由隐藏单元i计算出来的函数。它是依赖于参数的(暂时忽略偏置项bi)。需要注意的是,可看作输入的非线性特征。不过还有个问题:什么样的输入图像可让得到最大程度的激励?(通俗一点说,隐藏单元要找个什么样的特征?)。这里我们必须给加约束,否则会得到平凡解。若假设输入有范数约束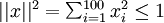 ,则可证(请读者自行推导)令隐藏单元得到最大激励的输入应由下面公式计算的像素
,则可证(请读者自行推导)令隐藏单元得到最大激励的输入应由下面公式计算的像素 给出(共需计算100个像素,j=1,…,100):
给出(共需计算100个像素,j=1,…,100):
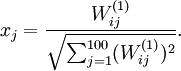
当我们用上式算出各像素的值、把它们组成一幅图像、并将图像呈现在我们面前之时,隐藏单元所追寻特征的真正含义也渐渐明朗起来。
假如训练的自编码器有100个隐藏单元,可视化结果就会包含100幅这样的图像——每个隐藏单元都对应一幅图像。审视这100幅图像,我们可以试着体会这些隐藏单元学出来的整体效果是什么样的。
当稀疏自编码器(100个隐藏单元,在10X10像素的输入上训练 )进行上述可视化处理之后,结果如下所示:

上图的每个小方块都给出了一个(带有有界范数 的)输入图像,它可使这100个隐藏单元中的某一个获得最大激励。不同的隐藏单元学会了在图像的不同位置和方向进行边缘检测。
- 第六部分稀疏自编码器符号一览表
下面是我们在推导sparse autoencoder时使用的符号一览表:
符号含义训练样本的输入特征,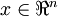 .输出值/目标值. 这里 可以是向量. 在autoencoder中,
.输出值/目标值. 这里 可以是向量. 在autoencoder中, .
.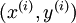 第 个训练样本输入为 时的假设输出,其中包含参数. 该输出应当与目标值 具有相同的维数.连接第 层 单元和第 层 单元的参数.
第 个训练样本输入为 时的假设输出,其中包含参数. 该输出应当与目标值 具有相同的维数.连接第 层 单元和第 层 单元的参数.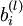 第 层 单元的偏置项. 也可以看作是连接第 层偏置单元和第 层 单元的参数.参数向量. 可以认为该向量是通过将参数 组合展开为一个长的列向量而得到.网络中第 层 单元的激活(输出)值.
第 层 单元的偏置项. 也可以看作是连接第 层偏置单元和第 层 单元的参数.参数向量. 可以认为该向量是通过将参数 组合展开为一个长的列向量而得到.网络中第 层 单元的激活(输出)值.另外,由于 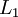 层是输入层,所以
层是输入层,所以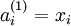 .
.
激活函数. 本文中我们使用 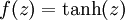 .
.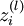 第 层 单元所有输入的加权和. 因此有
第 层 单元所有输入的加权和. 因此有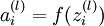 .学习率
.学习率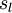 第 层的单元数目(不包含偏置单元).网络中的层数. 通常 层是输入层, 层是输出层.权重衰减系数.对于一个autoencoder,该符号表示其输出值;亦即输入值 的重构值. 与 含义相同.稀疏值,可以用它指定我们所需的稀疏程度(sparse autoencoder中)隐藏单元 的平均激活值.(sparse autoencoder目标函数中)稀疏值惩罚项的权重.
第 层的单元数目(不包含偏置单元).网络中的层数. 通常 层是输入层, 层是输出层.权重衰减系数.对于一个autoencoder,该符号表示其输出值;亦即输入值 的重构值. 与 含义相同.稀疏值,可以用它指定我们所需的稀疏程度(sparse autoencoder中)隐藏单元 的平均激活值.(sparse autoencoder目标函数中)稀疏值惩罚项的权重.=========================参考=================================
http://ufldl.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B
http://m.blog.csdn.net/blog/fghsakyu/40261851
http://freemind.pluskid.org/machine-learning/sparsity-and-some-basics-of-l1-regularization/
http://blog.sina.com.cn/s/blog_4a1853330102v0mr.html
http://www.cnblogs.com/guangmingyixuan/p/3418404.html
http://www.cnblogs.com/ZJUT-jiangnan/p/4333314.html
- 理解文章《Notes on Convolutinal Neural Networks》
- Notes on Convolutional Neural Networks
- Notes on Convolutional Neural Networks
- 《Notes on Convolutional Neural Networks》
- 《Notes on Convolutional Neural Networks》
- 《Notes on Convolutional Neural Networks》
- Notes on Convolutional Neural Networks
- Notes on Convolutional Neural Networks(阅读)
- 译《Notes on Convolutional Neural Networks》
- 基于Notes on Convolutional Neural Networks的卷积神经网络反向求导的理解
- 【Notes on Neural Networks and Deep Learning】(to be continued)
- Notes on NNDL(Neural Networks and Deep Learning)
- CNN卷积神经网络--反向传播(3,Notes on Convolutional Neural Networks)
- 170904 Training Deep Neural Networks on Noisy Labels with Bootstrapping-Notes(TBC)
- 【Learning Notes】Quasi-recurrent Neural Networks
- BP Neural Networks初步理解
- On the future of neural networks
- Neural networks
- Fragment加载轮换add,show,hide,replace方法
- 了解学习JS中this的指向
- 纪录一下最近被微信坑的事情
- OpenGL ES着色器语言之着色概览(官方文档第二章)
- FOJ-2214 Knapsack problem
- 理解文章《Notes on Convolutinal Neural Networks》
- 【leetcode】【54】Spiral Matrix
- php中cal_days_in_month不可用时的替代方法
- Material Design之Toolbar的使用以及修改菜单和字体颜色
- android draw过程分析
- java.lang.OutOfMemoryError: Java heap space解决方法
- iOS 第三方库冲突的处理
- 生活随笔
- syslog-ng解析dns,引起dhcpd 工作失效!


