BP神经网络推导过程详解
来源:互联网 发布:mysql offset用法 编辑:程序博客网 时间:2024/05/17 06:44
http://www.cnblogs.com/biaoyu/archive/2015/06/20/4591304.html
BP神经网络推导过程详解
BP算法是一种最有效的多层神经网络学习方法,其主要特点是信号前向传递,而误差后向传播,通过不断调节网络权重值,使得网络的最终输出与期望输出尽可能接近,以达到训练的目的。
一、多层神经网络结构及其描述
下图为一典型的多层神经网络。

通常一个多层神经网络由L层神经元组成,其中:第1层称为输入层,最后一层(第L层)被称为输出层,其它各层均被称为隐含层(第2层~第L-1层)。
令输入向量为:
输出向量为:
第l隐含层各神经元的输出为:
其中,
设
其中,
二、激活函数
BP神经网络通常使用下面两种非线性激活函数:
第一种称为sigmod函数或者logistics函数,第二种为双曲正切函数。
Sigmod函数的图像如下图所示,它的变化范围为(0, 1),其导数为

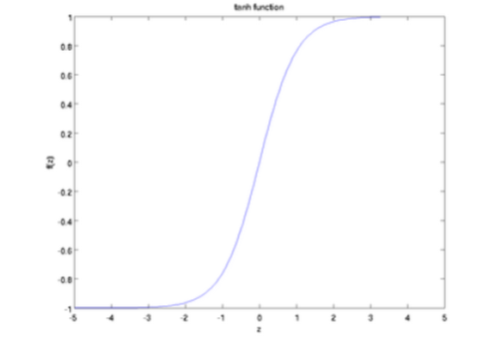
双曲正切函数的图像如下图所示,它的变化范围为(-1, 1),其导数为
三、BP算法推导过程
假定我们有m个训练样本
采用批量更新方法,对于给定的m个训练样本,定义误差函数为:
其中,E(i)为单个样本的训练误差:
因此,
BP算法每一次迭代按照以下方式对权值以及偏置进行更新:
其中,
对于单个训练样本,输出层的权值偏导数计算过程:
即:
同理可得,
令:
则:
对隐含层L-1层:
因为,
所以,
同理,
令:
由上可推,第l层(
其中,
四、BP算法过程描述
采用批量更新方法对神经网络的权值和偏置进行更新:
- 对所有的层
2≤l≤L ,设ΔW(l)=0,Δb(l)=0 ,这里ΔW(l) 和Δb(l) 分别为全零矩阵和全零向量; - For i = 1:m,
- 使用反向传播算法,计算各层神经元权值和偏置的梯度矩阵
∇W(l)(i) 和向量和∇b(l)(i) ; - 计算
ΔW(l)=∇W(l)(i) ; - 计算
Δb(l)=∇b(l)(i) 。
- 使用反向传播算法,计算各层神经元权值和偏置的梯度矩阵
- 更新权值和偏置:
- 计算
W(l)=W(l)+1mΔW(l) ; - 计算
b(l)=b(l)+1mΔb(l) 。
- 计算
- BP神经网络推导过程详解
- BP神经网络数学推导详解
- BP神经网络数学原理及推导过程
- BP神经网络算法推导
- 神经网络及BP推导
- BP神经网络原理推导
- BP神经网络算法推导
- BP神经网络算法推导
- BP神经网络推导
- BP神经网络公式推导
- BP算法推导过程
- bp算法推导过程
- bp算法推导过程
- 卷积神经网络BP算法推导
- 神经网络与BP算法推导
- BP神经网络权值推导
- 神经网络BP算法简单推导
- BP神经网络的数学公式推导
- 获取form表单的内容
- android 测试教程(转)
- JS基础(二)
- c#语言学习
- centos下安装resin4
- BP神经网络推导过程详解
- 多进程通信
- 《tar命令打包格式及组合find应用原理及误区详解》
- UE3 Animation Compression Technical Guide
- MySql
- 解决android4.4以上系统的相册选择图片后获取不到有效的URI
- Spring事务管理之HibernateTransactionManager
- 双核心四线程变成单核心单线程,肿么办
- ffmpeg的php扩展 在64位系统下的安装


