Symbolic Aggregate approXimation.
来源:互联网 发布:开淘宝店邮费 编辑:程序博客网 时间:2024/04/30 02:26
Introduction
In short, Symbolic Aggregate approXimation (SAX) algorithm application to the input time series transforms its into a strings.
The algoithm was proposed by Lin et al.) and extends the PAA-based approach inheriting the original algorithm simplicity and low computational complexity while providing satisfactory sensitivity and selectivity in range query processing. Moreover, the use of a symbolic representation opened a door to the existing wealth of data-structures and string-manipulation algorithms in computer science such as hashing, regular expression, pattern matching, suffix trees, and grammatical inference.
The algorithm
SAX transforms a time-series X of length n into the string of arbitrary length $\omega$, where $\omega « n$ typically, using an alphabet A of size a > 2. The algorithm consist of two steps: (i) it transforms the original time-series into the PAA representation and (ii) it converts the PAA data into a string.
The use of PAA brings advantages of a simple and efficient dimensionality reduction while providing the important lower bounding property. The actual conversion of PAA coefficients into letters by using a lookup table is also computationally efficient and the contractive property of symbolic distance was proven by Lin et al.
Discretization of the PAA representation of a time-series into SAX is implemented in a way which produces symbols corresponding to the time-series features with equal probability. The extensive and rigorous analysis of various time-series datasets available to the original algorithm’s authors has shown that the values of z-normalizedtime-series follow the Normal distribution. By using its properties it’s easy to pick a equal-sized areas under the Normal curve using lookup tables for the cut lines coordinates, slicing the under-the-Gaussian-curve area.
The x coordinates of these lines called breakpoints or cuts in the SAX context. The list of breakpoints $ B = \beta_{1}, \beta_{2} ,…, \beta_{a-1} $ such that $\beta_{i-1}<\beta_{i}$ and $\beta_{0}=-\infty$, $\beta_{a}=\infty$ divides the area under N(0,1) into a equal areas. By assigning a corresponding alphabet symbol $alpha_{j}$ to each interval $[\beta_{j-1},\beta_{j})$, the conversion of the vector of PAA coefficients $\bar{C}$ into the string $\hat{C}$ implemented as follows:
SAX introduces new metrics for measuring distance between strings by extending Euclidean and PAA distances. The function returning the minimal distance between two string representations of original time series $\hat{Q}$ and $\hat{C}$ is defined as
where the dist function is implemented by using the lookup table for the particular set of the breakpoints (alphabet size) as shown in the Table below, and where the singular value for each cell (r,c) is computed as
The lookup table for 4-letters alphabet
As shown by Li et al, this SAX distance metrics lower-bounds the PAA distance, i.e.
The SAX lower bound was examined by Ding et al in great detail and found to be superior in precision to the spectral decomposition methods on bursty (non-periodic) data sets.
PAA approximates a time-series X of length n into vector $\bar{X}=(\bar{x}_{1},…,\bar{x}_{M})$ of any arbitrary length $ M \leq n $ where each of $ \bar{x_{i}} $ is calculated as follows:
Which simply means that in order to reduce the dimensionality from n to M, we first divide the original time-series into M equally sized frames and secondly compute the mean values for each frame. The sequence assembled from the mean values is the PAA approximation (i.e., transform) of the original time-series. As it was shown by Keogh et al, the complexity of the PAA transform can be reduced from O(NM) to O(Mm) where m is the number of frames. By using the following distance measure
Yi & Faloutsos, and Keogh et al, have shown that PAA satisfies to the lower bounding condition and guarantees no false dismissals, i.e.:
Example
In this primer I use the next time series:
series1 <- c(2.02, 2.33, 2.99, 6.85, 9.20, 8.80, 7.50, 6.00, 5.85, 3.85, 4.85, 3.85, 2.22, 1.45, 1.34)
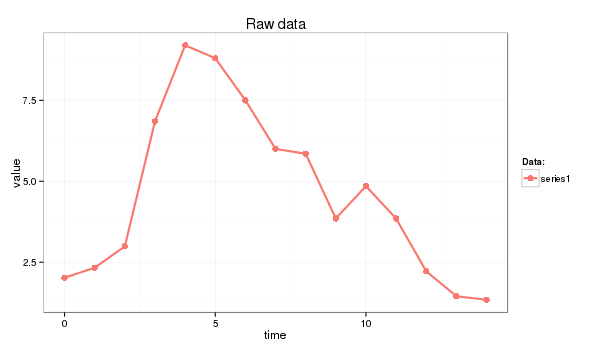
and the following R code:
paa <- function(ts, paa_size){ len = length(ts) if (len == paa_size) { ts } else { if (len %% paa_size == 0) { colMeans(matrix(ts, nrow=len %/% paa_size, byrow=F)) } else { res = rep.int(0, paa_size) for (i in c(0:(len * paa_size - 1))) { idx = i %/% len + 1# the spot pos = i %/% paa_size + 1 # the col spot res[idx] = res[idx] + ts[pos] } for (i in c(1:paa_size)) { res[i] = res[i] / len } res } }}whose application produces a seven-point piecewise aggregate approximation:
s1_paa = paa(series1,7)(2.23, 5.62, 8.67, 6.36, 4.58, 3.33, 1.45)
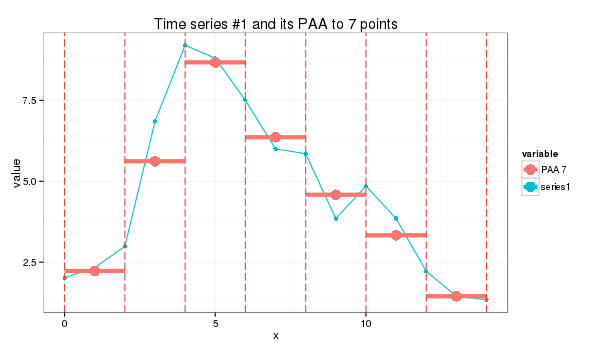
or a 9-point approximation which is a bit trickier:
s1_paa = paa(series1,9)(2.14, 3.63, 8.26, 8.28, 6.27, 4.65, 4.45, 2.39, 1.38)
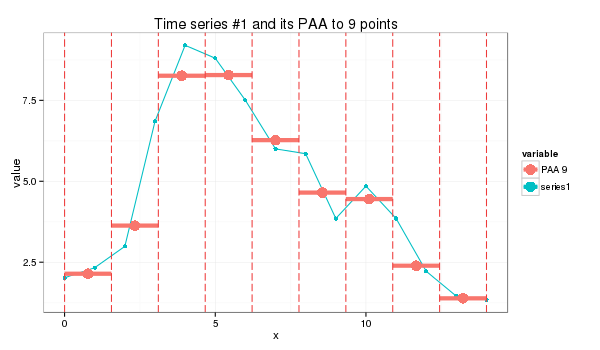
SAX primer
1.0 Timeseries data
I will use following time series for this example (the Euclidean distance between ts1 and ts2 is 11.4):
> ts1=c(2.02, 2.33, 2.99, 6.85, 9.20, 8.80, 7.50, 6.00, 5.85, 3.85, 4.85, 3.85, 2.22, 1.45, 1.34)> ts2=c(0.50, 1.29, 2.58, 3.83, 3.25, 4.25, 3.83, 5.63, 6.44, 6.25, 8.75, 8.83, 3.25, 0.75, 0.72)> dist(rbind(ts1,ts2), method = "euclidean") ts1ts2 11.42126
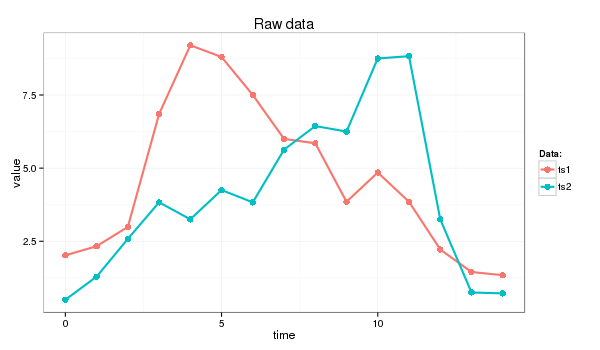
which I’ll transform into strings of length 9 whose letters come from an alphabet of size 4
2.0 Z-normalization
Before transforming timeseries with SAX we Z-normalize data first:
znorm <- function(ts){ ts.mean <- mean(ts) ts.dev <- sd(ts) (ts - ts.mean)/ts.dev}ts1_znorm=znorm(ts1)ts2_znorm=znorm(ts2)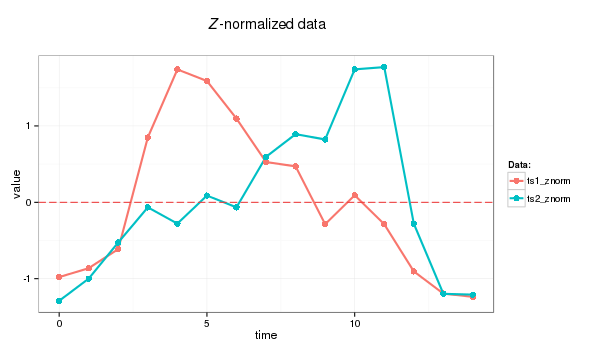
PAA follows the standard procedure:
3.0 PAA transform
PAA
paa <- function(ts, paa_size){ len = length(ts) if (len == paa_size) { ts } else { if (len %% paa_size == 0) { colMeans(matrix(ts, nrow=len %/% paa_size, byrow=F)) } else { res = rep.int(0, paa_size) for (i in c(0:(len * paa_size - 1))) { idx = i %/% len + 1# the spot pos = i %/% paa_size + 1 # the col spot res[idx] = res[idx] + ts[pos] } for (i in c(1:paa_size)) { res[i] = res[i] / len } res } }}paa_size=9s1_paa = paa(ts1_znorm,paa_size)s2_paa = paa(ts2_znorm,paa_size)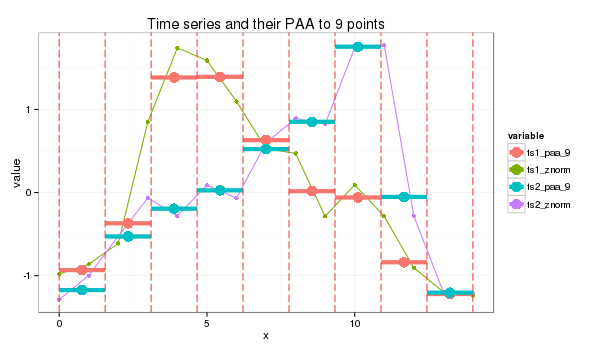
4.0 PAA values to letters
I use the 4 symbols alphabet {a,b,c,d} as in the table above. The cut lines for this alphabet shown as the thin blue lines on the plot below.
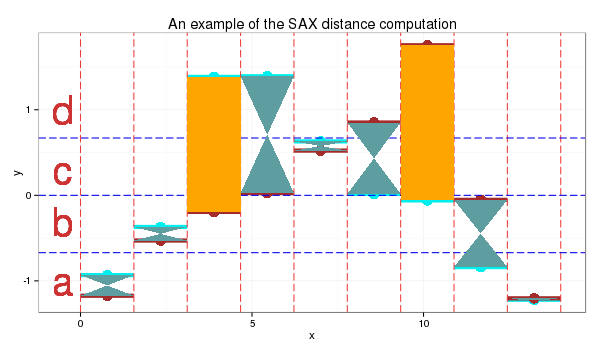
SAX transform of ts1 into string through 9-points PAA: “abddccbaa”
SAX transform of ts2 into string through 9-points PAA: “abbccddba”
SAX distance: 0 + 0 + 0.67 + 0 + 0 + 0 + 0.67 + 0 + 0 = 1.34
At the plot, orange color depicts symbols distance between which is counted - they are not “adjacent” to each other in the table.
- Symbolic Aggregate approXimation.
- Approximation Algorithms
- Symbolic Link
- Symbolic link
- symbolic link
- poj 1650 Integer Approximation
- 近似计算(approximation)
- Monte Carlo Approximation
- ZOJ1601:Integer Approximation
- Eikonal approximation Kichhoff
- 近似计算(approximation)
- Enumerable.Aggregate
- SORT AGGREGATE
- 聚合体Aggregate
- Scala aggregate
- mongo aggregate
- Aggregate方法
- mongo-aggregate
- cf#344-B - Print Check-暴力模拟
- d3系列2--api攻坚战04
- CSS3弹性布局内容对齐(justify-content)属性使用详解
- 常用算法积累
- cocos2d-js侧滑菜单SlidingMenu
- Symbolic Aggregate approXimation.
- 使用 GDB 调试多进程程序
- 如何查看PHP已安装的扩展
- 使用游标循环插入
- HTML5本地数据库详解
- 我CSDN博客被黑经历
- Windows Server 2008 R2服务器远程连接把上一个连接挤掉
- STS搭建Spring MVC 项目
- ProgressBar自定义


