Hadoop configuration详解
来源:互联网 发布:ubuntu install git 编辑:程序博客网 时间:2024/05/16 05:52
2.2 Hadoop Configuration详解
Hadoop没有使用java.util.Properties管理配置文件,也没有使用Apache Jakarta Commons Configuration管理配置文件,而是使用了一套独有的配置文件管理系统,并提供自己的API,即使用org.apache.hadoop.conf.Configuration处理配置信息。
2.2.1 Hadoop配置文件的格式
Hadoop配置文件采用XML格式,下面是Hadoop配置文件的一个例子:
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>io.sort.factor</name>
- <value>10</value>
- <description>The number of streams to merge at once while sorting
- files. This determines the number of open file handles.</description>
- </property>
- <property>
- <name>dfs.name.dir</name>
- <value>${hadoop.tmp.dir}/dfs/name</value>
- <description>Determines where on the local filesystem the DFS name
- nodeshould store the name table(fsimage). ……</description>
- </property>
- <property>
- <name>dfs.web.ugi</name>
- <value>webuser,webgroup</value>
- <final>true</final>
- <description>The user account used by the web interface.
- Syntax: USERNAME,GROUP1,GROUP2, ……</description>
- </property>
- </configuration>
Hadoop配置文件的根元素是configuration,一般只包含子元素property。每一个property元素就是一个配置项,配置文件不支持分层或分级。每个配置项一般包括配置属性的名称name、值value和一个关于配置项的描述description;元素final和Java中的关键字final类似,意味着这个配置项是“固定不变的”。final一般不出现,但在合并资源的时候,可以防止配置项的值被覆盖。
在上面的示例文件中,配置项dfs.web.ugi的值是“webuser,webgroup”,它是一个final配置项;从description看,这个配置项配置了Hadoop Web界面的用户账号,包括用户名和用户组信息。这些信息可以通过Configuration类提供的方法访问。
在Configuration中,每个属性都是String类型的,但是值类型可能是以下多种类型,包括Java中的基本类型,如boolean(getBoolean)、int(getInt)、long(getLong)、float(getFloat),也可以是其他类型,如String(get)、java.io.File(getFile)、String数组(getStrings)等。以上面的配置文件为例,getInt("io.sort.factor")将返回整数10;而getStrings("dfs.web.ugi")返回一个字符串数组,该数组有两个元素,分别是webuser和webgroup。
合并资源指将多个配置文件合并,产生一个配置。如果有两个配置文件,也就是两个资源,如core-default.xml和core-site.xml,通过Configuration类的loadResources()方法,把它们合并成一个配置。代码如下:
- Configurationconf = new Configuration();
- conf.addResource("core-default.xml");
- conf.addResource("core-site.xml");
如果这两个配置资源都包含了相同的配置项,而且前一个资源的配置项没有标记为final,那么,后面的配置将覆盖前面的配置。上面的例子中,core-site.xml中的配置将覆盖core-default.xml中的同名配置。如果在第一个资源(core-default.xml)中某配置项被标记为final,那么,在加载第二个资源的时候,会有警告提示。
Hadoop配置系统还有一个很重要的功能,就是属性扩展。如配置项dfs.name.dir的值是${hadoop.tmp.dir}/dfs/name,其中,${hadoop.tmp.dir}会使用Configuration中的相应属性值进行扩展。如果hadoop.tmp.dir的值是“/data”,那么扩展后的dfs.name.dir的值就是“/data/dfs/name”。
使用Configuration类的一般过程是:构造Configuration对象,并通过类的addResource()方法添加需要加载的资源;然后就可以使用get*方法和set*方法访问/设置配置项,资源会在第一次使用的时候自动加载到对象中。
2.2.2 Configuration的成员变量
org.apache.hadoop.conf.Configuration类图如图2-2所示。
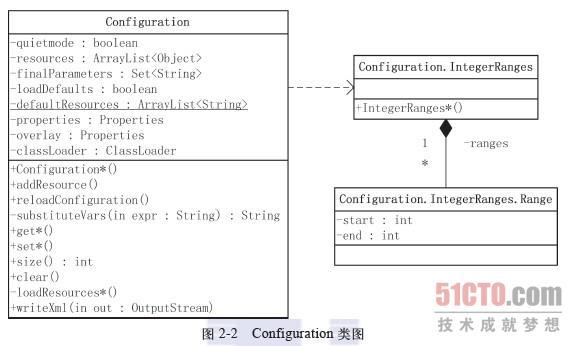
从类图可以看到,Configuration有7个主要的非静态成员变量。
布尔变量quietmode,用来设置加载配置的模式。如果quietmode为true(默认值),则在加载解析配置文件的过程中,不输出日志信息。quietmode只是一个方便开发人员调试的变量。
数组resources保存了所有通过addResource()方法添加Configuration对象的资源。Configuration.addResource()有如下4种形式:
- public void addResource(InputStream in)
- public void addResource(Path file)
- public void addResource(String name) //CLASSPATH资源
- public void addResource(URL url)
也就是说,用户可以添加如下形式的资源:
一个已经打开的输入流InputStream;
Hadoop文件路径org.apache.hadoop.fs.Path形式(后面会讨论Path类)的资源,如hdfs:// www.example.com:54300/conf/core-default.xml;
URL,如http://www.example.com/core-default.xml;
CLASSPATH资源(String形式),前面提到的“core-default.xml”就是这种形式。
布尔变量loadDefaults用于确定是否加载默认资源,这些默认资源保存在defaultResources中。注意,defaultResources是个静态成员变量,通过方法addDefaultResource()可以添加系统的默认资源。在HDFS中,会把hdfs-default.xml和hdfs-site.xml作为默认资源,并通过addDefaultResource()保存在成员变量defaultResources中;在MapReduce中,默认资源是mapred-default.xml和mapred-site.xml。如HDFS的DataNode中,就有下面的代码,加载上述两个默认资源:
- //下面的代码来自org.apache.hadoop.hdfs.server.datanode.DataNode
- static{
- Configuration.addDefaultResource("hdfs-default.xml");
- Configuration.addDefaultResource("hdfs-site.xml");
- }
properties、overlay和finalParameters都是和配置项相关的成员变量。其中,properties和overlay的类型都是前面介绍过的java.util.Properties。Hadoop配置文件解析后的键–值对,都存放在properties中。变量finalParameters的类型是Set<String>,用来保存所有在配置文件中已经被声明为final的键–值对的键,如前面配置文件例子中的键“dfs.web.ugi”。变量overlay用于记录通过set()方式改变的配置项。也就是说,出现在overlay中的键–值对是应用设置的,而不是通过对配置资源解析得到的。
Configuration中最后一个重要的成员变量是classLoader,这是一个类加载器变量,可以通过它来加载指定类,也可以通过它加载相关的资源。上面提到addResource()可以通过字符串方式加载CLASSPATH资源,它其实通过Configuration中的getResource()将字符串转换成URL资源,相关代码如下:
- public URL getResource(String name) {
- return classLoader.getResource(name);
- }
其中,getResource()用于根据资源的名称查找相应的资源,并返回读取资源的URL 对象。
注意 这里的资源,指的是可以通过类代码以与代码基无关的方式访问的一些数据,如图像、声音、文本等,不是前面提到的配置资源。
了解了Configuration各成员变量的具体含义,Configuration类的其他部分就比较容易理解了,它们都是为了操作这些变量而实现的解析、设置、获取方法。
2.2.3 资源加载(1)
资源通过对象的addResource()方法或类的静态addDefaultResource()方法(设置了loadDefaults标志)添加到Configuration对象中,添加的资源并不会立即被加载,只是通过reloadConfiguration()方法清空properties和finalParameters。相关代码如下:
- public void addResource(String name) { // 以CLASSPATH资源为例
- addResourceObject(name);
- }
- private synchronized void addResourceObject(Object resource) {
- resources.add(resource);// 添加到成员变量resources中
- reloadConfiguration();
- }
- public synchronized void reloadConfiguration() {
- properties = null;// 会触发资源的重新加载
- finalParameters.clear();
- }
静态方法addDefaultResource()也能清空Configuration对象中的数据(非静态成员变量),这是通过类的静态成员REGISTRY作为媒介进行的。
静态成员REGISTRY记录了系统中所有的Configuration对象,所以,addDefaultResource()被调用时,遍历REGISTRY中的元素并在元素(即Configuration对象)上调用reloadConfiguration()方法,即可触发资源的重新加载,相关代码如下:
- public static synchronized void addDefaultResource(String name) {
- if(!defaultResources.contains(name)) {
- defaultResources.add(name);
- for(Configuration conf : REGISTRY.keySet()) {
- if(conf.loadDefaults) {
- conf.reloadConfiguration(); // 触发资源的重新加载
- }
- }
- }
- }
成员变量properties中的数据,直到需要的时候才会加载进来。在getProps()方法中,如果发现properties为空,将触发loadResources()方法加载配置资源。这里其实采用了延迟加载的设计模式,当真正需要配置数据的时候,才开始分析配置文件。相关代码如下:
- private synchronized Properties getProps() {
- if (properties == null) {
- properties = new Properties();
- loadResources(properties, resources, quietmode);
- ……
- }
- }
Hadoop的配置文件都是XML形式,JAXP(Java API for XML Processing)是一种稳定、可靠的XML处理API,支持SAX(Simple API for XML)和DOM(Document Object Model)两种XML处理方法。
SAX提供了一种流式的、事件驱动的XML处理方式,但编写处理逻辑比较复杂,比较适合处理大的XML文件。
DOM和SAX不同,其工作方式是:首先将XML文档一次性装入内存;然后根据文档中定义的元素和属性在内存中创建一个“树形结构”,也就是一个文档对象模型,将文档对象化,文档中每个节点对应着模型中一个对象;然后使用对象提供的编程接口,访问XML文档进而操作XML文档。由于Hadoop的配置文件都是很小的文件,因此Configuration使用DOM处理XML。
首先分析DOM加载部分的代码:
- private void loadResource(Properties properties,
- Object name, boolean quiet) {
- try {
- //得到用于创建DOM解析器的工厂
- DocumentBuilderFactory docBuilderFactory
- = DocumentBuilderFactory.newInstance();
- //忽略XML中的注释
- docBuilderFactory.setIgnoringComments(true);
- //提供对XML名称空间的支持
- docBuilderFactory.setNamespaceAware(true);
- try {
- //设置XInclude处理状态为true,即允许XInclude机制
- docBuilderFactory.setXIncludeAware(true);
- } catch (UnsupportedOperationException e) {
- ……
- }
- //获取解析XML的DocumentBuilder对象
- DocumentBuilder builder = docBuilderFactory.newDocumentBuilder();
- Document doc = null;
- Element root = null;
- //根据不同资源,做预处理并调用相应形式的DocumentBuilder.parse
- if (name instanceof URL) {//资源是URL形式
- ……
- doc = builder.parse(url.toString());
- ……
- } else if (name instanceof String) {//CLASSPATH资源
- ……
- } else if (name instanceof Path) {//资源是Hadoop Path形式的
- ……
- } else if (name instanceof InputStream) {//InputStream
- ……
- } else if (name instanceof Element) {//处理configuration子元素
- root = (Element)name;
- }
- if (doc == null && root == null) {
- if (quiet)
- return;
- throw new RuntimeException(name + " not found");
- }
- ……
2.2.3 资源加载(2)
一般的JAXP处理都是从工厂开始,通过调用DocumentBuilderFactory的newInstance()方法,获得用于创建DOM解析器的工厂。这里并没有创建出DOM解析器,只是获得一个用于创建DOM解析器的工厂,接下来需要对上述newInstance()方法得到的docBuilderFactory对象进行一些设置,才能进一步通过DocumentBuilderFactory,得到DOM解析器对象builder。
针对DocumentBuilderFactory对象进行的主要设置包括:
忽略XML文档中的注释;
支持XML空间;
支持XML的包含机制(XInclude)。
XInclude机制允许将XML文档分解为多个可管理的块,然后将一个或多个较小的文档组装成一个大型文档。也就是说,Hadoop的一个配置文件中,可以利用XInclude机制将其他配置文件包含进来一并处理,下面是一个例子:
- <configuration xmlns:xi="http://www.w3.org/2001/XInclude">
- ……
- <xi:include href="conf4performance.xml"/>
- ……
- </configuration>
通过XInclude机制,把配置文件conf4performance.xml嵌入到当前配置文件,这种方法更有利于对配置文件进行模块化管理,同时就不需要再使用Configuration.addResource()方法加载资源conf4performance.xml了。
设置完DocumentBuilderFactory对象以后,通过docBuilderFactory.newDocumentBuilder()获得了DocumentBuilder对象,用于从各种输入源解析XML。在loadResource()中,需要根据Configuration支持的4种资源分别进行处理,不过这4种情况最终都调用DocumentBuilder.parse()函数,返回一个DOM解析结果。
如果输入是一个DOM的子元素,那么将解析结果设置为输入元素。这是为了处理下面出现的元素configuration包含configuration子节点的特殊情况。
成员函数loadResource的第二部分代码,就是根据DOM的解析结果设置Configuration的成员变量properties和finalParameters。
在确认XML的根节点是configuration以后,获取根节点的所有子节点并对所有子节点进行处理。这里需要注意,元素configuration的子节点可以是configuration,也可以是properties。如果是configuration,则递归调用loadResource(),在loadResource()的处理过程中,子节点会被作为根节点得到继续的处理。
如果是property子节点,那么试图获取property的子元素name、value和final。在成功获得name和value的值后,根据情况设置对象的成员变量properties和finalParameters。相关代码如下:
- if (root == null) {
- root = doc.getDocumentElement();
- }
- //根节点应该是configuration
- if (!"configuration".equals(root.getTagName()))
- LOG.fatal("bad conf file: top-level element not <configuration>");
- //获取根节点的所有子节点
- NodeList props = root.getChildNodes();
- for (int i = 0; i <props.getLength(); i++) {
- Node propNode = props.item(i);
- if (!(propNode instanceof Element))
- continue; //如果子节点不是Element,忽略
- Element prop = (Element)propNode;
- if ("configuration".equals(prop.getTagName())) {
- //如果子节点是configuration,递归调用loadResource进行处理
- //这意味着configuration的子节点可以是configuration
- loadResource(properties, prop, quiet);
- continue;
- }
- //子节点是property
- if (!"property".equals(prop.getTagName()))
- LOG.warn("bad conf file: element not <property>");
- NodeList fields = prop.getChildNodes();
- String attr = null;
- String value = null;
- boolean finalParameter = false;
- //查找name、value和final的值
- for (int j = 0; j <fields.getLength(); j++) {
- Node fieldNode = fields.item(j);
- if (!(fieldNode instanceof Element))
- continue;
- Element field = (Element)fieldNode;
- if ("name".equals(field.getTagName()) &&field.hasChildNodes())
- attr = ((Text)field.getFirstChild()).getData().trim();
- if ("value".equals(field.getTagName()) &&field.hasChildNodes())
- value = ((Text)field.getFirstChild()).getData();
- if ("final".equals(field.getTagName()) &&field.hasChildNodes())
- finalParameter =
- "true".equals(((Text)field.getFirstChild()).getData());
- }
- if (attr != null && value != null) {
- //如果属性已经标志为'final',忽略
- if (!finalParameters.contains(attr)) {
- //添加键-值对到properties中
- properties.setProperty(attr, value);
- if (finalParameter) {
- //该属性标志为'final',添加name到finalParameters中
- finalParameters.add(attr);
- }
- }
- ……
- }
- }
- //处理异常
- ……
- }
2.2.4 使用get*和set*访问/设置配置项
1. get*
get*一共代表21个方法,它们用于在Configuration对象中获取相应的配置信息。这些配置信息可以是boolean(getBoolean)、int(getInt)、long(getLong)等基本类型,也可以是其他一些Hadoop常用类型,如类的信息(getClassByName、getClasses、getClass)、String数组(getStringCollection、getStrings)、URL(getResource)等。这些方法里最重要的是get()方法,它根据配置项的键获取对应的值,如果键不存在,则返回默认值defaultValue。其他的方法都会依赖于Configuration.get(),并在get()的基础上做进一步处理。get()方法如下:
- public String get(String name, String defaultValue)
Configuration.get()会调用Configuration的私有方法substituteVars(),该方法会完成配置的属性扩展。属性扩展是指配置项的值包含${key}这种格式的变量,这些变量会被自动替换成相应的值。也就是说,${key}会被替换成以key为键的配置项的值。注意,如果${key}替换后,得到的配置项值仍然包含变量,这个过程会继续进行,直到替换后的值中不再出现变量为止。
substituteVars的工作依赖于正则表达式:
- varPat:\$\{[^\}\$ ]+\}
由于“$”、左花括号“{”、右花括号“}”都是正则表达式中的保留字,因此需要通过“\”进行转义。正则表达式varPat中,“\$\{”部分用于匹配${key}中的key前面的“${”,最后的“\}”部分匹配属性扩展项的右花括号“}”,中间部分“[^\}\$ ]+”用于匹配属性扩展键,它使用了两个正则表达式规则:
[^ ]规则,通过[^ ]包含一系列的字符,使表达式匹配这一系列字符以外的任意一个字符。也就是说,“[^\}\$ ]”将匹配除了“}”、“$”和空格以外的所有字符。注意,$后面还包含了一个空格,这个看不见的空格,是通过空格的Unicode字符\u0020添加到表达式中的。
+是一个修饰匹配次数的特殊符号,通过该符号保证了“+”前面的表达式“[^\}\$ ]”至少出现1次。
通过正则表达式“\$\{[^\}\$ ]+\}”,可以在输入字符串里找出需要进行属性扩展的地方,并通过字符串替换,进行属性扩展。
前面提过,如果一次属性扩展完成以后,得到的表达式里仍然包含可扩展的变量,那么,substituteVars()需要再次进行属性扩展。考虑下面的情况:
属性扩展${key1}的结果包含属性扩展${key2},而对${key2}进行属性扩展后,产生了一个包含${key1}的新结果,这会导致属性扩展进入死循环,没办法停止。
针对这种可能发生的情况,substituteVars()中使用了一个非常简单而又有效的策略,即属性扩展只能进行一定的次数(20次,通过Configuration的静态成员变量MAX_SUBST定义),避免出现上面分析的属性扩展死循环。
最后一点需要注意的是,substituteVars()中进行的属性扩展,不但可以使用保存在Configuration对象中的键–值对,而且还可以使用Java虚拟机的系统属性。如系统属性user.home包含了当前用户的主目录,如果用户有一个配置项需要使用这个信息,可以通过属性扩展${user.home},来获得对应的系统属性值。而且,Java命令行可以通过“-D<name>=<value>”的方式定义系统属性。这就提供了一个通过命令行,覆盖或者设置Hadoop运行时配置信息的方法。在substituteVars()中,属性扩展优先使用系统属性,然后才是Configuration对象中保存的键–值对。具体代码如下:
- //正则表达式对象,包含正则表达式\$\{[^\}\$ ]+\}
- //注意,u0020前面只有一个”\”,转义发生在Java里,不在正则表达式里
- private static Pattern varPat =
- Pattern.compile("\\$\\{[^\\}\\$\u0020]+\\}");
- //最多做20次属性扩展
- private static int MAX_SUBST = 20;
- private String substituteVars(String expr) {
- if (expr == null) {
- return null;
- }
- Matcher match = varPat.matcher("");
- String eval = expr;
- //循环,最多做MAX_SUBST次属性扩展
- for(int s=0; s<MAX_SUBST; s++) {
- match.reset(eval);
- if (!match.find()) {
- return eval; //什么都没有找到,返回
- }
- String var = match.group();
- varvar = var.substring(2, var.length()-1); //获得属性扩展的键
- String val = null;
- try {
- //看看系统属性里有没有var对应的val
- //这一步保证了我们首先使用系统属性做属性扩展
- val = System.getProperty(var);
- } catch(SecurityException se) {
- LOG.warn("Unexpected SecurityException in Configuration", se);
- }
- if (val == null) {
- //看看Configuration保存的键-值对里有没有var对应的val
- val = getRaw(var);
- }
- if (val == null) {
- //属性扩展中的var没有绑定,不做扩展,返回
- return eval;
- }
- //替换${……},完成属性扩展
- evaleval = eval.substring(0,match.start())
- +val+eval.substring(match.end());
- }
- //属性扩展次数过多,抛异常
- throw new IllegalStateException(……);
- }
2. set*
相对于get*来说,set*的大多数方法都很简单,这些方法对输入进行类型转换等处理后,最终都调用了下面的Configuration.set()方法:
- public String set(String name, String value)
对比相对复杂的Configuration.get(),成员函数set()只是简单地调用了成员变量properties和overlay的setProperty()方法,保存传入的键–值对。
原文链接:http://f.dataguru.cn/thread-258563-1-1.html
- 2.2 Hadoop Configuration详解
- Hadoop Configuration详解
- Hadoop Configuration详解
- Hadoop Configuration详解
- Hadoop Configuration详解
- Hadoop configuration详解
- Hadoop Configuration 源码详解
- hadoop Configured Configrable Configuration Tool 源码详解
- Hadoop源码分析笔记(一):Hadoop Configuration详解
- hadoop Configuration
- hadoop源码学习(一)--configuration类详解
- hadoop configuration print
- hadoop ganglia configuration
- Hadoop Configuration介绍
- hadoop -- setup and configuration
- hadoop之Configuration.java
- hadoop源码之Configuration解析
- HADOOP集群配置(Configuration)
- IOS学习 模拟器上输入文本时,如何弹出键盘,显示中文,同一个模拟器有多个
- PHP运行出现Notice : Use of undefined constant 完美解决方案
- JavaScript计算一个字符串最多重复的字符及出现次数
- c++实现单例模式
- 金蝶K3无法进入系统、反应卡慢怎么解决
- Hadoop configuration详解
- Spring框架学习(四)
- imageloader配置
- 面试总结 —— 高级JAVA工程师【转转转】
- 设计模式之单例模式
- BZOJ3069: [Pa2011]Hard Choice 艰难的选择
- php 类中方法之间参数怎么调用 ?
- PAT1032
- java中List Map Set区别


