Android中Serializable和Parcelable序列化对象
来源:互联网 发布:淘宝男模特招聘网 编辑:程序博客网 时间:2024/04/29 06:23
本文转载自:http://www.jb51.net/article/79933.htm
本文详细对Android中Serializable和Parcelable序列化对象进行学习,具体内容如下
学习内容:
1.序列化的目的
2.Android中序列化的两种方式
3.Parcelable与Serializable的性能比较
4.Android中如何使用Parcelable进行序列化操作
5.Parcelable的工作原理
6.相关实例
1.序列化的目的
1).永久的保存对象数据(将对象数据保存在文件当中,或者是磁盘中
2).通过序列化操作将对象数据在网络上进行传输(由于网络传输是以字节流的方式对数据进行传输的.因此序列化的目的是将对象数据转换成字节流的形式)
3).将对象数据在进程之间进行传递(Activity之间传递对象数据时,需要在当前的Activity中对对象数据进行序列化操作.在另一个Activity中需要进行反序列化操作讲数据取出)
4).Java平台允许我们在内存中创建可复用的Java对象,但一般情况下,只有当JVM处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比JVM的生命周期更长(即每个对象都在JVM中)但在现实应用中,就可能要停止JVM运行,但有要保存某些指定的对象,并在将来重新读取被保存的对象。这是Java对象序列化就能够实现该功能。(可选择入数据库、或文件的形式保存)
5).序列化对象的时候只是针对变量进行序列化,不针对方法进行序列化.
6).在Intent之间,基本的数据类型直接进行相关传递即可,但是一旦数据类型比较复杂的时候,就需要进行序列化操作了.
2.Android中实现序列化的两种方式
1).Implements Serializable 接口 (声明一下即可)
Serializable 的简单实例:
public class Person implementsSerializable{ privatestatic final long serialVersionUID = -7060210544600464481L; privateString name; privateint age; publicString getName(){ returnname; } publicvoid setName(String name){ this.name = name; } publicint getAge(){ returnage; } publicvoid setAge(intage){ this.age = age; }}2).Implements Parcelable 接口(不仅仅需要声明,还需要实现内部的相应方法)
Parcelable的简单实例:
注:写入数据的顺序和读出数据的顺序必须是相同的.
public class Book implementsParcelable{ privateString bookName; privateString author; privateint publishDate; publicBook(){ } publicString getBookName(){ returnbookName; } publicvoid setBookName(String bookName){ this.bookName = bookName; } publicString getAuthor(){ returnauthor; } publicvoid setAuthor(String author){ this.author = author; } publicint getPublishDate(){ returnpublishDate; } publicvoid setPublishDate(intpublishDate){ this.publishDate = publishDate; } @Override publicint describeContents(){ return0; } @Override publicvoid writeToParcel(Parcel out,int flags){ out.writeString(bookName); out.writeString(author); out.writeInt(publishDate); } publicstatic final Parcelable.Creator<Book> CREATOR = new Creator<Book>(){ @Override publicBook[] newArray(intsize){ returnnew Book[size]; } @Override publicBook createFromParcel(Parcel in){ returnnew Book(in); } }; publicBook(Parcel in){ //如果元素数据是list类型的时候需要: lits = new ArrayList<?> in.readList(list); 否则会出现空指针异常.并且读出和写入的数据类型必须相同.如果不想对部分关键字进行序列化,可以使用transient关键字来修饰以及static修饰. bookName = in.readString(); author = in.readString(); publishDate = in.readInt(); }}我们知道在Java应用程序当中对类进行序列化操作只需要实现Serializable接口就可以,由系统来完成序列化和反序列化操作,但是在Android中序列化操作有另外一种方式来完成,那就是实现Parcelable接口.也是Android中特有的接口来实现类的序列化操作.原因是Parcelable的性能要强于Serializable.因此在绝大多数的情况下,Android还是推荐使用Parcelable来完成对类的序列化操作的.
3.Parcelable与Serializable的性能比较
首先Parcelable的性能要强于Serializable的原因我需要简单的阐述一下
1). 在内存的使用中,前者在性能方面要强于后者
2). 后者在序列化操作的时候会产生大量的临时变量,(原因是使用了反射机制)从而导致GC的频繁调用,因此在性能上会稍微逊色
3). Parcelable是以Ibinder作为信息载体的.在内存上的开销比较小,因此在内存之间进行数据传递的时候,Android推荐使用Parcelable,既然是内存方面比价有优势,那么自然就要优先选择.
4). 在读写数据的时候,Parcelable是在内存中直接进行读写,而Serializable是通过使用IO流的形式将数据读写入在硬盘上.
但是:虽然Parcelable的性能要强于Serializable,但是仍然有特殊的情况需要使用Serializable,而不去使用Parcelable,因为Parcelable无法将数据进行持久化,因此在将数据保存在磁盘的时候,仍然需要使用后者,因为前者无法很好的将数据进行持久化.(原因是在不同的Android版本当中,Parcelable可能会不同,因此数据的持久化方面仍然是使用Serializable)
速度测试:
测试方法:
1)、通过将一个对象放到一个bundle里面然后调用Bundle#writeToParcel(Parcel, int)方法来模拟传递对象给一个activity的过程,然后再把这个对象取出来。
2)、在一个循环里面运行1000 次。
3)、两种方法分别运行10次来减少内存整理,cpu被其他应用占用等情况的干扰。
4)、参与测试的对象就是上面的相关代码
5)、在多种Android软硬件环境上进行测试
- LG Nexus 4 – Android 4.2.2
- Samsung Nexus 10 – Android 4.2.2
- HTC Desire Z – Android 2.3.3
结果如图:
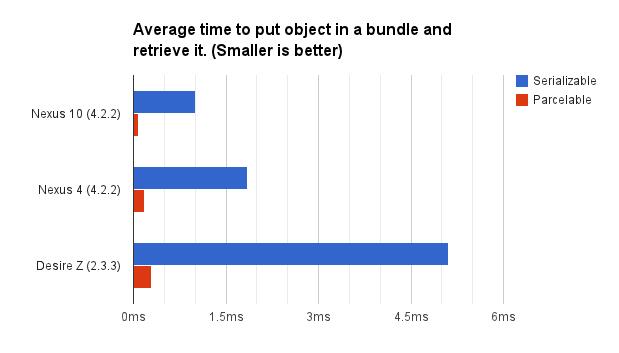
性能差异:
Nexus 10
Serializable: 1.0004ms, Parcelable: 0.0850ms – 提升10.16倍。
Nexus 4
Serializable: 1.8539ms – Parcelable: 0.1824ms – 提升11.80倍。
Desire Z
Serializable: 5.1224ms – Parcelable: 0.2938ms – 提升17.36倍。
由此可以得出: Parcelable 比 Serializable快了10多倍。
从相对的比较我们可以看出,Parcelable的性能要比Serializable要优秀的多,因此在Android中进行序列化操作的时候,我们需要尽可能的选择前者,需要花上大量的时间去实现Parcelable接口中的内部方法.
4.Android中如何使用Parcelable进行序列化操作
说了这么多,我们还是来看看Android中如何去使用Parcelable实现类的序列化操作吧.
Implements Parcelable的时候需要实现内部的方法:
1).writeToParcel 将对象数据序列化成一个Parcel对象(序列化之后成为Parcel对象.以便Parcel容器取出数据)
2).重写describeContents方法,默认值为0
3).Public static final Parcelable.Creator<T>CREATOR (将Parcel容器中的数据转换成对象数据) 同时需要实现两个方法:
3.1 CreateFromParcel(从Parcel容器中取出数据并进行转换.)
3.2 newArray(int size)返回对象数据的大小
因此,很明显实现Parcelable并不容易。实现Parcelable接口需要写大量的模板代码,这使得对象代码变得难以阅读和维护。具体的实例就是上面Parcelable的实例代码.就不进行列举了.(有兴趣的可以去看看Android中NetWorkInfo的源代码,是关于网络连接额外信息的一个相关类,内部就实现了序列化操作.大家可以去看看)
5.Parcelable的工作原理
无论是对数据的读还是写都需要使用Parcel作为中间层将数据进行传递.Parcel涉及到的东西就是与C++底层有关了.都是使用JNI.在Java应用层是先创建Parcel(Java)对象,然后再调用相关的读写操作的时候.就拿读写32为Int数据来说吧:
static jint android_os_Parcel_readInt(JNIEnv* env, jobject clazz){ Parcel* parcel = parcelForJavaObject(env, clazz); if(parcel != NULL) { returnparcel->readInt32(); } return0;}调用的方法就是这个过程,首先是将Parcel(Java)对象转换成Parcel(C++)对象,然后被封装在Parcel中的相关数据由C++底层来完成数据的序列化操作.
status_t Parcel::writeInt32(int32_t val){ returnwriteAligned(val);} template<classt="">status_t Parcel::writeAligned(T val) { COMPILE_TIME_ASSERT_FUNCTION_SCOPE(PAD_SIZE(sizeof(T)) == sizeof(T)); if((mDataPos+sizeof(val)) <= mDataCapacity) {restart_write: *reinterpret_cast<t*>(mData+mDataPos) = val; returnfinishWrite(sizeof(val)); } status_t err = growData(sizeof(val)); if(err == NO_ERROR) gotorestart_write; returnerr;}真正的读写过程是由下面的源代码来完成的.status_t Parcel::continueWrite(size_t desired){ // If shrinking, first adjust for any objects that appear // after the new data size. size_t objectsSize = mObjectsSize; if(desired < mDataSize) { if(desired == 0) { objectsSize =0; }else { while(objectsSize > 0) { if(mObjects[objectsSize-1] < desired) break; objectsSize--; } } } if(mOwner) { // If the size is going to zero, just release the owner's data. if(desired == 0) { freeData(); returnNO_ERROR; } // If there is a different owner, we need to take // posession. uint8_t* data = (uint8_t*)malloc(desired); if(!data) { mError = NO_MEMORY; returnNO_MEMORY; } size_t* objects = NULL; if(objectsSize) { objects = (size_t*)malloc(objectsSize*sizeof(size_t)); if(!objects) { mError = NO_MEMORY; returnNO_MEMORY; } // Little hack to only acquire references on objects // we will be keeping. size_t oldObjectsSize = mObjectsSize; mObjectsSize = objectsSize; acquireObjects(); mObjectsSize = oldObjectsSize; } if(mData) { memcpy(data, mData, mDataSize < desired ? mDataSize : desired); } if(objects && mObjects) { memcpy(objects, mObjects, objectsSize*sizeof(size_t)); } //ALOGI("Freeing data ref of %p (pid=%d)\n", this, getpid()); mOwner(this, mData, mDataSize, mObjects, mObjectsSize, mOwnerCookie); mOwner = NULL; mData = data; mObjects = objects; mDataSize = (mDataSize < desired) ? mDataSize : desired; ALOGV("continueWrite Setting data size of %p to %d\n",this, mDataSize); mDataCapacity = desired; mObjectsSize = mObjectsCapacity = objectsSize; mNextObjectHint =0; }else if(mData) { if(objectsSize < mObjectsSize) { // Need to release refs on any objects we are dropping. constsp<ProcessState> proc(ProcessState::self()); for(size_t i=objectsSize; i<mObjectsSize; i++) { constflat_binder_object* flat = reinterpret_cast<flat_binder_object*>(mData+mObjects[i]); if(flat->type == BINDER_TYPE_FD) { // will need to rescan because we may have lopped off the only FDs mFdsKnown =false; } release_object(proc, *flat,this); } size_t* objects = (size_t*)realloc(mObjects, objectsSize*sizeof(size_t)); if(objects) { mObjects = objects; } mObjectsSize = objectsSize; mNextObjectHint =0; } // We own the data, so we can just do a realloc(). if(desired > mDataCapacity) { uint8_t* data = (uint8_t*)realloc(mData, desired); if(data) { mData = data; mDataCapacity = desired; }else if(desired > mDataCapacity) { mError = NO_MEMORY; returnNO_MEMORY; } }else { if(mDataSize > desired) { mDataSize = desired; ALOGV("continueWrite Setting data size of %p to %d\n",this, mDataSize); } if(mDataPos > desired) { mDataPos = desired; ALOGV("continueWrite Setting data pos of %p to %d\n",this, mDataPos); } } }else { // This is the first data. Easy! uint8_t* data = (uint8_t*)malloc(desired); if(!data) { mError = NO_MEMORY; returnNO_MEMORY; } if(!(mDataCapacity ==0 && mObjects == NULL && mObjectsCapacity ==0)) { ALOGE("continueWrite: %d/%p/%d/%d", mDataCapacity, mObjects, mObjectsCapacity, desired); } mData = data; mDataSize = mDataPos =0; ALOGV("continueWrite Setting data size of %p to %d\n",this, mDataSize); ALOGV("continueWrite Setting data pos of %p to %d\n",this, mDataPos); mDataCapacity = desired; } returnNO_ERROR;}1).整个读写全是在内存中进行,主要是通过malloc()、realloc()、memcpy()等内存操作进行,所以效率比JAVA序列化中使用外部存储器会高很多
2).读写时是4字节对齐的,可以看到#define PAD_SIZE(s) (((s)+3)&~3)这句宏定义就是在做这件事情
3).如果预分配的空间不够时newSize = ((mDataSize+len)*3)/2;会一次多分配50%
4).对于普通数据,使用的是mData内存地址,对于IBinder类型的数据以及FileDescriptor使用的是mObjects内存地址。后者是通过flatten_binder()和unflatten_binder()实现的,目的是反序列化时读出的对象就是原对象而不用重新new一个新对象。
6.相关实例
最后上一个例子..
首先是序列化的类Book.class
public class Book implementsParcelable{ privateString bookName; privateString author; privateint publishDate; publicBook(){ } publicString getBookName(){ returnbookName; } publicvoid setBookName(String bookName){ this.bookName = bookName; } publicString getAuthor(){ returnauthor; } publicvoid setAuthor(String author){ this.author = author; } publicint getPublishDate(){ returnpublishDate; } publicvoid setPublishDate(intpublishDate){ this.publishDate = publishDate; } @Override publicint describeContents(){ return0; } @Override publicvoid writeToParcel(Parcel out,int flags){ out.writeString(bookName); out.writeString(author); out.writeInt(publishDate); } publicstatic final Parcelable.Creator<Book> CREATOR = new Creator<Book>(){ @Override publicBook[] newArray(intsize){ returnnew Book[size]; } @Override publicBook createFromParcel(Parcel in){ returnnew Book(in); } }; publicBook(Parcel in){ //如果元素数据是list类型的时候需要: lits = new ArrayList<?> in.readList(list); 否则会出现空指针异常.并且读出和写入的数据类型必须相同.如果不想对部分关键字进行序列化,可以使用transient关键字来修饰以及static修饰. bookName = in.readString(); author = in.readString(); publishDate = in.readInt(); }}第一个Activity,MainActivity
Book book = new Book();book.setBookname("Darker");book.setBookauthor("me");book.setPublishDate(20);Bundle bundle = new Bundle();bundle.putParcelable("book", book);Intent intent = new Intent(MainActivity.this,AnotherActivity.class);intent.putExtras(bundle);第二个Activity,AnotherActivity
Intent intent = getIntent();Bundle bun = intent.getExtras();Book book = bun.getParcelable("book");System.out.println(book);总结:Java应用程序中有Serializable来实现序列化操作,Android中有Parcelable来实现序列化操作,相关的性能也作出了比较,因此在Android中除了对数据持久化的时候需要使用到Serializable来实现序列化操作,其他的时候我们仍然需要使用Parcelable来实现序列化操作,因为在Android中效率并不是最重要的,而是内存,通过比较Parcelable在效率和内存上都要优秀与Serializable,尽管Parcelable实现起来比较复杂,但是如果我们想要成为一名优秀的Android软件工程师,那么我们就需要勤快一些去实现Parcelable,而不是偷懒与实现Serializable.当然实现后者也不是不行,关键在于我们头脑中的那一份思想。
以上就是本文的全部内容,希望对大家的学习有所帮助。
- Android中Serializable和Parcelable序列化对象
- Android中Serializable和Parcelable序列化对象详解
- Android中Serializable和Parcelable序列化对象详解
- Android中Serializable和Parcelable序列化对象详解
- Android中Serializable和Parcelable序列化对象详解
- Android中Serializable和Parcelable序列化对象详解
- Android中Serializable和Parcelable序列化对象详解
- Android中Serializable和Parcelable序列化对象详解
- Android中Serializable和Parcelable序列化对象详解
- Android对象序列化:Serializable和Parcelable
- android 对象序列化Parcelable,Serializable详解
- 对象序列化传递 Serializable 和Parcelable
- Android中Serializable和Parcelable序列化的区别
- android序列化 Parcelable和Serializable接口
- Android序列化:Serializable和Parcelable详解
- Android 序列化 Parcelable和Serializable 浅谈
- Android序列化Serializable和Parcelable区别
- Android序列化parcelable和 serializable分析
- Java类型的程序员成长
- BZOJ4199 NOI2015 品酒大会 题解&代码
- 那些年大家都在谈论的Android性能优化
- 【spark】采用MultilayerPerceptron对MNIST的0-9数字进行识别
- ORACLE数据库测试数据插入速度(十万)
- Android中Serializable和Parcelable序列化对象
- 错误票据
- Genymotion 运行Android虚拟机出现错误:Unable to staart the virtual device.To find out the cause of the problem
- c++上机报告1-2
- js库Modernizr的介绍和使用
- 网络编程_TCP_Socket通信_聊天室_客户端多线程_群聊JAVA191-192
- IOS传值方法-属性正向传值
- Android Studio 常用快捷键
- 小试循环


