文档对象模型DOM
来源:互联网 发布:听音识曲哪个软件更好 编辑:程序博客网 时间:2024/06/06 01:14
DOM=DocumentObjectModel,文档对象模型,DOM可以以一种独立于平台和语言的方式访问和修改一个文档的内容和结构。换句话说,这是表示和处理一个HTML或XML文档的常用方法。有一点很重要,DOM的设计是以对象管理组织(OMG)的规约为基础的,因此可以用于任何编程语言。最初人们把它认为是一种让JavaScript在浏览器间可移植的方法,不过DOM的应用已经远远超出这个范围。Dom技术使得用户页面可以动态地变化,如可以动态地显示或隐藏一个元素,改变它们的属性,增加一个元素等,Dom技术使得页面的交互性大大地增强。[1]DOM实际上是以面向对象方式描述的文档模型。DOM定义了表示和修改文档所需的对象、这些对象的行为和属性以及这些对象之间的关系。可以把DOM认为是页面上数据和结构的一个树形表示,不过页面当然可能并不是以这种树的方式具体实现。通过JavaScript,您可以重构整个HTML文档。您可以添加、移除、改变或重排页面上的项目。要改变页面的某个东西,JavaScript就需要获得对HTML文档中所有元素进行访问的入口。这个入口,连同对HTML元素进行添加、移动、改变或移除的方法和属性,都是通过文档对象模型来获得的(DOM)。在1998年,W3C发布了第一级的DOM规范。这个规范允许访问和操作HTML页面中的每一个单独的元素。所有的浏览器都执行了这个标准,因此,DOM的兼容性问题也几乎难觅踪影了。DOM可被JavaScript用来读取、改变HTML、XHTML以及XML文档。DOM被分为不同的部分(核心、XML及HTML)和级别(DOMLevel1/2/3):
什么是 DOM?
DOM是W3C(万维网联盟)的标准。DOM定义了访问HTML和XML文档的标准:"W3C文档对象模型(DOM)是中立于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。"W3CDOM标准被分为3个不同的部分:编者注:DOM是DocumentObjectModel(文档对象模型)的缩写。
什么是 XML DOM?
XMLDOM是:[2]XMLDOM定义了所有XML元素的对象和属性,以及访问它们的方法(接口)。换句话说:XMLDOM是用于获取、更改、添加或删除XML元素的标准。
什么是 HTML DOM?
HTMLDOM是:[3]HTMLDOM定义了所有HTML元素的和,以及访问它们的。
2 DOM的分级
编辑根据W3CDOM规范,DOM是HTML与XML的应用编程接口(API),DOM将整个页面映射为一个由层次节点组成的文件。有1级、2级、3级共3个级别。
1级DOM
1级DOM在1998年10月份成为W3C的提议,由DOM核心与DOMHTML两个模块组成。DOM核心能映射以XML为基础的文档结构,允许获取和操作文档的任意部分。DOMHTML通过添加HTML专用的对象与函数对DOM核心进行了扩展。
2级DOM
鉴于1级DOM仅以映射文档结构为目标,DOM2级面向更为宽广。通过对原有DOM的扩展,2级DOM通过对象接口增加了对鼠标和用户界面事件(DHTML长期支持鼠标与用户界面事件)、范围、遍历(重复执行DOM文档)和层叠样式表(CSS)的支持。同时也对DOM1的核心进行了扩展,从而可支持XML命名空间。2级DOM引进了几个新DOM模块来处理新的接口类型:DOM视图:描述跟踪一个文档的各种视图(使用CSS样式设计文档前后)的接口;DOM事件:描述事件接口;DOM样式:描述处理基于CSS样式的接口;DOM遍历与范围:描述遍历和操作文档树的接口;
3级DOM
3级DOM通过引入统一方式载入和保存文档和文档验证方法对DOM进行进一步扩展,DOM3包含一个名为“DOM载入与保存”的新模块,DOM核心扩展后可支持XML1.0的所有内容,包扩XMLInfoset、XPath、和XMLBase。
"0级"DOM
当阅读与DOM有关的材料时,可能会遇到参考0级DOM的情况。需要注意的是并没有标准被称为0级DOM,它仅是DOM历史上一个参考点(0级DOM被认为是在InternetExplorer4.0与NetscapeNavigator4.0支持的最早的DHTML)。
节点
根据DOM,HTML文档中的每个成分都是一个节点。DOM是这样规定的:整个文档是一个文档节点每个HTML标签是一个元素节点包含在HTML元素中的文本是文本节点每一个HTML属性是一个属性节点注释属于注释节点
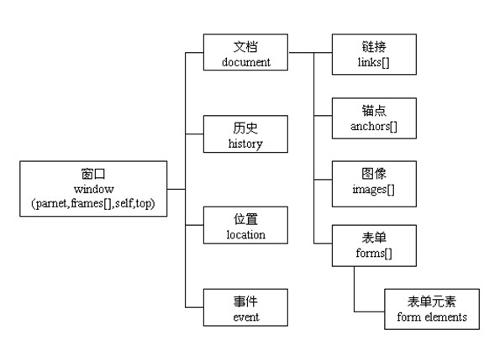
Node 层次
节点彼此都有等级关系。HTML文档中的所有节点组成了一个文档树(或节点树)。HTML文档中的每个元素、属性、文本等都代表着树中的一个节点。树起始于文档节点,并由此继续伸出枝条,直到处于这棵树最低级别的所有文本节点为止。下面这个图片表示一个文档树(节点树):
文档树(节点树)
请看下面这个HTML文档:DOMLessononeHelloworld!上面所有的节点彼此间都存在。除文档节点之外的每个节点都有。举例,和的父节点是节点,文本节点"Helloworld!"的父节点是节点。大部分元素节点都有。比方说,节点有一个子节点:节点。节点也有一个子节点:文本节点"DOMTutorial"。当节点分享同一个父节点时,它们就是。比方说,和是同辈,因为它们的父节点均是节点。节点也可以拥有,后代指某个节点的所有子节点,或者这些子节点的子节点,以此类推。比方说,所有的文本节点都是节点的后代,而第一个文本节点是节点的后代。节点也可以拥有。先辈是某个节点的父节点,或者父节点的父节点,以此类推。比方说,所有的文本节点都可把节点作为先辈节点。
3 查找并访问节点
编辑你可通过若干种方法来查找您希望操作的元素:通过使用getElementById()和getElementsByTagName()方法通过使用一个元素节点的parentNode、firstChild以及lastChild属性getElementById()和getElementsByTagName()这两种方法,可查找整个HTML文档中的任何HTML元素。这两种方法会忽略文档的结构。假如您希望查找文档中所有的元素,getElementsByTagName()会把它们全部找到,不管元素处于文档中的哪个层次。同时,getElementById()方法也会返回正确的元素,不论它被隐藏在文档结构中的什么位置。这两种方法会向您提供任何你所需要的HTML元素,不论它们在文档中所处的位置!getElementById()可通过指定的ID来返回元素:
getElementById() 语法
document.getElementById("ID");注释:getElementById()无法工作在XML中。在XML文档中,您必须通过拥有类型id的属性来进行搜索,而此类型必须在XMLDTD中进行声明。getElementsByTagName()方法会使用指定的标签名返回所有的元素(作为一个节点列表),这些元素是您在使用此方法时所处的元素的后代。getElementsByTagName()可被用于任何的HTML元素:
getElementsByTagName() 语法
document.getElementsByTagName("标签名称");或者:document.getElementById('ID').getElementsByTagName("标签名称");
实例 1
下面这个例子会返回文档中所有元素的一个节点列表:document.getElementsByTagName("p");
实例 2
下面这个例子会返回所有元素的一个节点列表,且这些元素必须是id为"maindiv"的元素的后代:document.getElementById('maindiv').getElementsByTagName("p");
节点列表(nodeList)
当我们使用节点列表时,通常要把此列表保存在一个变量中,就像这样:varx=document.getElementsByTagName("p");现在,变量x包含着页面中所有元素的一个列表,并且我们可以通过它们的索引号来访问这些元素。注释:索引号从0开始。您可以通过使用length属性来循环遍历节点列表:varx=document.getElementsByTagName("p");for(vari=0;i要访问第三个元素,您可以这么写:vary=x[4];parentNode、firstChild以及lastChild这三个属性parentNode、firstChild以及lastChild可遵循文档的结构,在文档中进行“短距离的旅行”。请看下面这个HTML片段:[5]JohnDoeAlaska在上面的HTML代码中,第一个是元素的首个子元素(firstChild),而最后一个是元素的最后一个子元素(lastChild)。此外,是每个元素的父节点(parentNode)。对firstChild最普遍的用法是访问某个元素的文本:varx=[aparagraph];vartext=x.firstChild.nodeValue;parentNode属性常被用来改变文档的结构。假设您希望从文档中删除带有id为"maindiv"的节点:varx=document.getElementById("maindiv");x.parentNode.removeChild(x);首先,您需要找到带有指定id的节点,然后移至其父节点并执行removeChild()方法。[6]
4 优点和缺点
编辑DOM的优势主要表现在:易用性强,使用DOM时,将把所有的XML文档信息都存于内存中,并且遍历简单,支持XPath,增强了易用性。DOM的缺点主要表现在:效率低,解析速度慢,内存占用量过高,对于大文件来说几乎不可能使用。另外效率低还表现在大量的消耗时间,因为使用DOM进行解析时,将为文档的每个element、attribute、processing-instrUCtion和comment都创建一个对象,这样在DOM机制中所运用的大量对象的创建和销毁无疑会影响其效率。
- DOM-文档对象模型
- 文档对象模型DOM
- DOM(文档对象模型)
- DOM 文档对象模型
- DOM 文档对象模型
- DOM文档对象模型
- 文档对象模型DOM
- 文档对象模型 (DOM)
- DOM(文档对象模型)
- DOM-----文档对象模型
- 文档对象模型DOM
- DOM文档对象模型
- DOM(文档对象模型)
- DOM文档对象模型
- 文档对象模型DOM
- 文档对象模型DOM
- DOM文档对象模型
- DOM文档对象模型
- Markdown的最基本最常用的语法
- java日志组件介绍(common-logging,log4j,slf4j,logback )
- HDOJ 2186-悼念512汶川大地震遇难同胞——一定要记住我爱你
- linux 安装 nginx
- utilities(C++)——单例(Singleton)
- 文档对象模型DOM
- XML与DTD
- {JSP}JSP页面的基本结构
- HDOJ 2187-悼念512汶川大地震遇难同胞——老人是真饿了
- 多线程中的锁系统(三)-WaitHandle、AutoResetEvent、ManualResetEvent
- STM32F103软件仿真进不了主函数 解决方案
- Android应用界面开发_学习笔记_第三周
- 第三周项目三-输出星号图(2)
- python实现统计你一共写了多少行代码


