日志搜集、过滤及推送处理框架logstash及fluentd总结
来源:互联网 发布:淘宝买家花呗开通条件 编辑:程序博客网 时间:2024/06/02 04:05
简介
Logstash是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。怎么样听起来挺厉害的吧?在一个典型的使用场景下(ELK):用Elasticsearch作为后台数据的存储,kibana用来前端的报表展示。Logstash在其过程中担任搬运工的角色,它为数据存储,报表查询和日志解析创建了一个功能强大的管道链。Logstash提供了多种多样的 input,filters,codecs和output组件,让使用者轻松实现强大的功能。好了让我们开始吧
依赖条件:JAVA
Logstash运行仅仅依赖java运行环境(jre)。各位可以在命令行下运行java -version命令 显示类似如下结果:java -versionjava version "1.7.0_45"Java(TM) SE Runtime Environment (build 1.7.0_45-b18)Java HotSpot(TM) 64-Bit Server VM (build 24.45-b08, mixed mode)为了确保成功运行Logstash建议大家使用较近期的jre版本。 可以获取开源版本的jre在:http://openjdk.java.net 或者你可以在官网下载Oracle jdk版本:http://www.oracle.com/technetwork/java/index.html 一旦jre已经成功在你的系统中安装完成,我们就可以继续了
启动和运行Logstash的两条命令示例
第一步我们先下载Logstashcurl -O https://download.elasticsearch.org/logstash/logstash/logstash-1.4.2.tar.gz现在你应该有了一个叫logstash-1.4.2.tar.gz的文件了。 我们把它解压一下
tar zxvf logstash-1.4.2.tar.gzcd logstash-1.4.2现在我们来运行一下:
bin/logstash -e 'input { stdin { } } output { stdout {} }'我们现在可以在命令行下输入一些字符,然后我们将看到logstash的输出内容:hello world2013-11-21T01:22:14.405+0000 0.0.0.0 hello worldOk,还挺有意思的吧... 以上例子我们在运行logstash中,定义了一个叫"stdin"的input还有一个"stdout"的output,无论我们输入什么字符,Logstash都会按照某种格式来返回我们输入的字符。这里注意我们在命令行中使用了-e参数,该参数允许Logstash直接通过命令行接受设置。这点尤其快速的帮助我们反复的测试配置是否正确而不用写配置文件。
让我们再试个更有意思的例子。首先我们在命令行下使用CTRL-C命令退出之前运行的Logstash。现在我们重新运行Logstash使用下面的命令:
bin/logstash -e 'input { stdin { } } output { stdout { codec => rubydebug } }'我们再输入一些字符,这次我们输入"goodnight moon":goodnight moon{ "message" => "goodnight moon", "@timestamp" => "2013-11-20T23:48:05.335Z", "@version" => "1", "host" => "my-laptop"}以上示例通过重新设置了叫"stdout"的output(添加了"codec"参数),我们就可以改变Logstash的输出表现。类似的我们可以通过在你的配置文件中添加或者修改inputs、outputs、filters,就可以使随意的格式化日志数据成为可能,从而订制更合理的存储格式为查询提供便利。使用Elasticsearch存储日志
现在,你也许会说:"它看起来还挺高大上的,不过手工输入字符,并把字符从控制台回显出来。实际情况并不实用"。说的好,那么接下来我们将建立Elasticsearch来存储输入到Logstash的日志数据。如果你还没有安装Elasticsearch,你可以下载RPM/DEB包或者手动下载tar包,通过以下命令:curl -O https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.1.1.tar.gztar zxvf elasticsearch-1.1.1.tar.gzcd elasticsearch-1.1.1/./bin/elasticsearch
注意 本篇文章实例使用Logstash 1.4.2和Elasticsearch 1.1.1。不同的Logstash版本都有对应的建议Elasticsearch版本。请确认你使用的Logstash版本!
更多有关安装和设置Elasticsearch的信息可以参考Elasticsearch官网。因为我们主要介绍Logstash的入门使用,Elasticsearch默认的安装和配置就已经满足我们要求。
言归正专,现在Elasticsearch已经运行并监听9200端口了(大家都搞定了,对吗?),通过简单的设置Logstash就可以使用Elasticsearch作为它的后端。默认的配置对于Logstash和Elasticsearch已经足够,我们忽略一些额外的选项来设置elasticsearch作为output:
bin/logstash -e 'input { stdin { } } output { elasticsearch { host => localhost } }'随意的输入一些字符,Logstash会像之前一样处理日志(不过这次我们将不会看到任何的输出,因为我们没有设置stdout作为output选项)you know, for logs我们可以使用curl命令发送请求来查看ES是否接收到了数据:
curl 'http://localhost:9200/_search?pretty'返回内容如下:
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "failed" : 0 }, "hits" : { "total" : 1, "max_score" : 1.0, "hits" : [ { "_index" : "logstash-2013.11.21", "_type" : "logs", "_id" : "2ijaoKqARqGvbMgP3BspJA", "_score" : 1.0, "_source" : {"message":"you know, for logs","@timestamp":"2013-11-21T18:45:09.862Z","@version":"1","host":"my-laptop"} } ] }}恭喜,至此你已经成功利用Elasticsearch和Logstash来收集日志数据了。Elasticsearch 插件(题外话)
这里介绍另外一个对于查询你的Logstash数据(Elasticsearch中数据)非常有用的工具叫Elasticsearch-kopf插件。更多的信息请见Elasticsearch插件。安装elasticsearch-kopf,只要在你安装Elasticsearch的目录中执行以下命令即可:bin/plugin -install lmenezes/elasticsearch-kopf接下来访问 http://localhost:9200/_plugin/kopf 来浏览保存在Elasticsearch中的数据,设置及映射!
多重输出
作为一个简单的例子来设置多重输出,让我们同时设置stdout和elasticsearch作为output来重新运行一下Logstash,如下:bin/logstash -e 'input { stdin { } } output { elasticsearch { host => localhost } stdout { } }'当我们输入了一些词组之后,这些输入的内容回回显到我们的终端,同时还会保存到Elasticsearch!(可以使用curl和kopf插件来验证)。默认配置 - 按照每日日期建立索引
你将发现Logstash可以足够灵巧的在Elasticsearch上建立索引... 每天会按照默认格式是logstash-YYYY.MM.DD来建立索引。在午夜(GMT),Logstash自动按照时间戳更新索引。我们可以根据追溯多长时间的数据作为依据来制定保持多少数据,当然你也可以把比较老的数据迁移到其他的地方(重新索引)来方便查询,此外如果仅仅是简单的删除一段时间数据我们可以使用Elasticsearch Curator。接下来
接下来我们开始了解更多高级的配置项。在下面的章节,我们着重讨论logstash一些核心的特性,以及如何和logstash引擎交互的。事件的生命周期
Inputs,Outputs,Codecs,Filters构成了Logstash的核心配置项。Logstash通过建立一条事件处理的管道,从你的日志提取出数据保存到Elasticsearch中,为高效的查询数据提供基础。为了让你快速的了解Logstash提供的多种选项,让我们先讨论一下最常用的一些配置。更多的信息,请参考Logstash事件管道。Inputs
input 及输入是指日志数据传输到Logstash中。其中常见的配置如下: file:从文件系统中读取一个文件,很像UNIX命令 "tail -0a"syslog:监听514端口,按照RFC3164标准解析日志数据redis:从redis服务器读取数据,支持channel(发布订阅)和list模式。redis一般在Logstash消费集群中作为"broker"角色,保存events队列共Logstash消费。lumberjack:使用lumberjack协议来接收数据,目前已经改为 logstash-forwarder。 Filters
Fillters 在Logstash处理链中担任中间处理组件。他们经常被组合起来实现一些特定的行为来,处理匹配特定规则的事件流。常见的filters如下: grok:解析无规则的文字并转化为有结构的格式。Grok 是目前最好的方式来将无结构的数据转换为有结构可查询的数据。有120多种匹配规则,会有一种满足你的需要。mutate:mutate filter 允许改变输入的文档,你可以从命名,删除,移动或者修改字段在处理事件的过程中。drop:丢弃一部分events不进行处理,例如:debug events。clone:拷贝 event,这个过程中也可以添加或移除字段。geoip:添加地理信息(为前台kibana图形化展示使用)Outputs
outputs是logstash处理管道的最末端组件。一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。一些常用的outputs包括: elasticsearch:如果你计划将高效的保存数据,并且能够方便和简单的进行查询...Elasticsearch是一个好的方式。是的,此处有做广告的嫌疑,呵呵。file:将event数据保存到文件中。graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。http://graphite.wikidot.com/。statsd:statsd是一个统计服务,比如技术和时间统计,通过udp通讯,聚合一个或者多个后台服务,如果你已经开始使用statsd,该选项对你应该很有用。 Codecs
codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。流行的codecs包括 json,msgpack,plain(text)。 json:使用json格式对数据进行编码/解码multiline:将汇多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息 获取完整的配置信息,请参考 Logstash文档中 "plugin configuration"部分。
更多有趣Logstash内容
使用配置文件
使用-e参数在命令行中指定配置是很常用的方式,不过如果需要配置更多设置则需要很长的内容。这种情况,我们首先创建一个简单的配置文件,并且指定logstash使用这个配置文件。如我们创建一个文件名是"logstash-simple.conf"的配置文件并且保存在和Logstash相同的目录中。内容如下:input { stdin { } }output { elasticsearch { host => localhost } stdout { codec => rubydebug }}接下来,执行命令:bin/logstash -f logstash-simple.conf我们看到logstash按照你刚刚创建的配置文件来运行例子,这样更加的方便。注意,我们使用-f参数来从文件获取而代替之前使用-e参数从命令行中获取配置。以上演示非常简单的例子,当然解析来我们继续写一些复杂一些的例子。
过滤器
filters是一个行处理机制将提供的为格式化的数据整理成你需要的数据,让我们看看下面的一个例子,叫grok filter的过滤器。input { stdin { } }filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } date { match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ] }}output { elasticsearch { host => localhost } stdout { codec => rubydebug }}执行Logstash按照如下参数:bin/logstash -f logstash-filter.conf现在粘贴下面一行信息到你的终端(当然Logstash就会处理这个标准的输入内容):
127.0.0.1 - - [11/Dec/2013:00:01:45 -0800] "GET /xampp/status.php HTTP/1.1" 200 3891 "http://cadenza/xampp/navi.php" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0"你将看到类似如下内容的反馈信息:
{ "message" => "127.0.0.1 - - [11/Dec/2013:00:01:45 -0800] \"GET /xampp/status.php HTTP/1.1\" 200 3891 \"http://cadenza/xampp/navi.php\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0\"", "@timestamp" => "2013-12-11T08:01:45.000Z", "@version" => "1", "host" => "cadenza", "clientip" => "127.0.0.1", "ident" => "-", "auth" => "-", "timestamp" => "11/Dec/2013:00:01:45 -0800", "verb" => "GET", "request" => "/xampp/status.php", "httpversion" => "1.1", "response" => "200", "bytes" => "3891", "referrer" => "\"http://cadenza/xampp/navi.php\"", "agent" => "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0\""}正像你看到的那样,Logstash(使用了grok过滤器)能够将一行的日志数据(Apache的"combined log"格式)分割设置为不同的数据字段。这一点对于日后解析和查询我们自己的日志数据非常有用。比如:HTTP的返回状态码,IP地址相关等等,非常的容易。很少有匹配规则没有被grok包含,所以如果你正尝试的解析一些常见的日志格式,或许已经有人为了做了这样的工作。如果查看详细匹配规则,参考logstash grok patterns。另外一个过滤器是date filter。这个过滤器来负责解析出来日志中的时间戳并将值赋给timestame字段(不管这个数据是什么时候收集到logstash的)。你也许注意到在这个例子中@timestamp字段是设置成December 11, 2013, 说明logstash在日志产生之后一段时间进行处理的。这个字段在处理日志中回添到数据中的,举例来说... 这个值就是logstash处理event的时间戳。
实用的例子
Apache 日志(从文件获取)
现在,让我们使用一些非常实用的配置... apache2访问日志!我们将从本地读取日志文件,并且通过条件设置处理满足我们需要的event。首先,我们创建一个文件名是logstash-apache.conf的配置文件,内容如下(你可以根据实际情况修改你的文件名和路径):input { file { path => "/tmp/access_log" start_position => beginning }}filter { if [path] =~ "access" { mutate { replace => { "type" => "apache_access" } } grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } } date { match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ] }}output { elasticsearch { host => localhost } stdout { codec => rubydebug }}接下来,我们按照上面的配置创建一个文件(在例子中是"/tmp/access.log"),可以将下面日志信息作为文件内容(也可以用你自己的webserver产生的日志):71.141.244.242 - kurt [18/May/2011:01:48:10 -0700] "GET /admin HTTP/1.1" 301 566 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.2.3) Gecko/20100401 Firefox/3.6.3"134.39.72.245 - - [18/May/2011:12:40:18 -0700] "GET /favicon.ico HTTP/1.1" 200 1189 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; InfoPath.2; .NET4.0C; .NET4.0E)"98.83.179.51 - - [18/May/2011:19:35:08 -0700] "GET /css/main.css HTTP/1.1" 200 1837 "http://www.safesand.com/information.htm" "Mozilla/5.0 (Windows NT 6.0; WOW64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"现在使用-f参数来执行一下上面的例子:
bin/logstash -f logstash-apache.conf你可以看到apache的日志数据已经导入到ES中了。这里logstash会按照你的配置读取,处理指定的文件,任何后添加到文件的内容也会被捕获处理最后保存到ES中。此外,数据中type的字段值会被替换成"apache_access"(这个功能在配置中已经指定)。
这个配置只是让Logstash监控了apache access_log,但是在实际中往往并不够用可能还需要监控error_log,只要在上面的配置中改变一行既可以实现,如下:
input { file { path => "/tmp/*_log"...现在你可以看到logstash处理了error日志和access日志。然而,如果你检查了你的数据(也许用elasticsearch-kopf),你将发现access_log日志被分成不同的字段,但是error_log确没有这样。这是因为我们使用了“grok”filter并仅仅配置匹配combinedapachelog日志格式,这样满足条件的日志就会自动的被分割成不同的字段。我们可以通过控制日志按照它自己的某种格式来解析日志,不是很好的吗?对吧。
此外,你也许还会发现Logstash不会重复处理文件中已经处理过得events。因为Logstash已经记录了文件处理的位置,这样就只处理文件中新加入的行数。漂亮!
条件判断
我们利用上一个例子来介绍一下条件判断的概念。这个概念一般情况下应该被大多数的Logstash用户熟悉掌握。你可以像其他普通的编程语言一样来使用if,else if和else语句。让我们把每个event依赖的日志文件类型都标记出来(access_log,error_log其他以log结尾的日志文件)。input { file { path => "/tmp/*_log" }}filter { if [path] =~ "access" { mutate { replace => { type => "apache_access" } } grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } date { match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ] } } else if [path] =~ "error" { mutate { replace => { type => "apache_error" } } } else { mutate { replace => { type => "random_logs" } } }}output { elasticsearch { host => localhost } stdout { codec => rubydebug }}我想你已经注意到了,我们使用"type"字段来标记每个event,但是我们实际上没有解析"error"和”random"类型的日志... 而实际情况下可能会有很多很多类型的错误日志,如何解析就作为练习留给各位读者吧,你可以依赖已经存在的日志。
Syslog
Ok,现在我们继续了解一个很实用的例子:syslog。Syslog对于Logstash是一个很长用的配置,并且它有很好的表现(协议格式符合RFC3164)。Syslog实际上是UNIX的一个网络日志标准,由客户端发送日志数据到本地文件或者日志服务器。在这个例子中,你根本不用建立syslog实例;我们通过命令行就可以实现一个syslog服务,通过这个例子你将会看到发生什么。首先,让我们创建一个简单的配置文件来实现logstash+syslog,文件名是 logstash-syslog.conf
input { tcp { port => 5000 type => syslog } udp { port => 5000 type => syslog }}filter { if [type] == "syslog" { grok { match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" } add_field => [ "received_at", "%{@timestamp}" ] add_field => [ "received_from", "%{host}" ] } syslog_pri { } date { match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } }}output { elasticsearch { host => localhost } stdout { codec => rubydebug }}执行logstash:
bin/logstash -f logstash-syslog.conf
通常,需要一个客户端链接到Logstash服务器上的5000端口然后发送日志数据。在这个简单的演示中我们简单的使用telnet链接到logstash服务器发送日志数据(与之前例子中我们在命令行标准输入状态下发送日志数据类似)。首先我们打开一个新的shell窗口,然后输入下面的命令:
telnet localhost 5000你可以复制粘贴下面的样例信息(当然也可以使用其他字符,不过这样可能会被grok filter不能正确的解析):
Dec 23 12:11:43 louis postfix/smtpd[31499]: connect from unknown[95.75.93.154]Dec 23 14:42:56 louis named[16000]: client 199.48.164.7#64817: query (cache) 'amsterdamboothuren.com/MX/IN' deniedDec 23 14:30:01 louis CRON[619]: (www-data) CMD (php /usr/share/cacti/site/poller.php >/dev/null 2>/var/log/cacti/poller-error.log)Dec 22 18:28:06 louis rsyslogd: [origin software="rsyslogd" swVersion="4.2.0" x-pid="2253" x-info="http://www.rsyslog.com"] rsyslogd was HUPed, type 'lightweight'.
之后你可以在你之前运行Logstash的窗口中看到输出结果,信息被处理和解析!
{ "message" => "Dec 23 14:30:01 louis CRON[619]: (www-data) CMD (php /usr/share/cacti/site/poller.php >/dev/null 2>/var/log/cacti/poller-error.log)", "@timestamp" => "2013-12-23T22:30:01.000Z", "@version" => "1", "type" => "syslog", "host" => "0:0:0:0:0:0:0:1:52617", "syslog_timestamp" => "Dec 23 14:30:01", "syslog_hostname" => "louis", "syslog_program" => "CRON", "syslog_pid" => "619", "syslog_message" => "(www-data) CMD (php /usr/share/cacti/site/poller.php >/dev/null 2>/var/log/cacti/poller-error.log)", "received_at" => "2013-12-23 22:49:22 UTC", "received_from" => "0:0:0:0:0:0:0:1:52617", "syslog_severity_code" => 5, "syslog_facility_code" => 1, "syslog_facility" => "user-level", "syslog_severity" => "notice"}恭喜各位,看到这里你已经成为一个合格的Logstash用户了。你将可以轻松的配置,运行Logstash,还可以发送event给Logstash,但是这个过程随着使用还会有很多值得深挖的地方。
logstash一个分布式日志收集工具。我们今天的演示内容。
虽然不涉及什么编程操作,但是我觉得熟悉这类工具对从事安全分析的人是非常的重要。
因为安全分为攻击型和防御行。日志分析就是防御型中最重要的部分之一,而日志的收集,管理,将会是非常耗时的一件事,尤其是分布式收集。如果以后去给哪个企业管服务器,难说用得上啊。
logstash就是把各个服务器(a,b,c,d,e,f........)上的日志,汇集到一起。假设是接收服务器是X。X可以把收集结果输出到web UI上或者本地文件,因此管理员只需要在一台机器上进行日志分析就行,而且还是自动收集。这东西另一个imba之处就是它无视日志格式,什么格式它都认。
老师说还有一个好处就是免费。。。。
好吧,说说这东西的配置:
分布式的架构分为发送端和接收端。运行logstash很简单,就是一个jar文件,命令在官网都有。主要是配置文件的设置。
发送端的配置如下:
input {
}
#这里可以写filter
output {
}
简单的来说,就是提取服务器本地的日志(input),经过过滤器的表达式(我没写)的过滤,然后把日志发送到接收端。
接收端的配置如下:
input {
}
output {
}
接收端不同的地方在于:
不止要运行logstash,还要运行一个amqp服务器,这个服务器才是负责接收消息的,然后转给logstash。如果要输出在web UI,就要运行一个叫elasticsearch的服务器。然后logstash的output指向相应IP就行,默认端口9300.以上的例子只是我本地的演示,把结果输出在本地文件(我的elasticsearch似乎有问题)。我们演示的时候用的是两台机器,配置文件几乎是一样的。。接收端是另外一台机器,那台机器上的elasticsearch就没问题,能出结果。
顺便BS一下logstash的官方,官方的分布式教程有问题(启动接收端的时候没说用配置文件。。),卡了我们一段时间。最后还是给我们自己发现和改出来了。
补充一下,一个阿里巴巴工作的朋友读完文档后给了我另外一些提示:
有3种原因会中断发送
内存 硬盘 还有就是发送端发送速度过快
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。
本文针对官方文档进行翻译以及实践,希望有更多的有用户了解、使用这款工具。
下载、安装、使用
这款工具是开箱即用的软件,下载地址戳这里,下载自己对应的系统版本即可。
下载后直接解压,就可以了。
通过命令行,进入到logstash/bin目录,执行下面的命令:
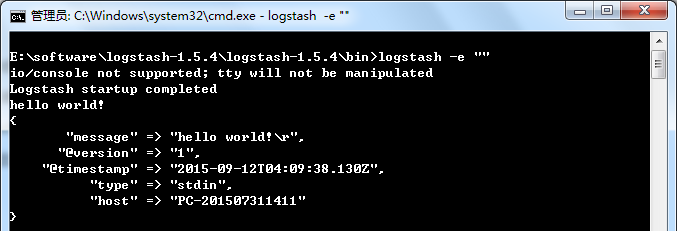
logstash -e ""
可以看到提示下面信息(这个命令稍后介绍),输入hello world!

可以看到logstash尾我们自动添加了几个字段,时间戳@timestamp,版本@version,输入的类型type,以及主机名host。
工作原理
Logstash使用管道方式进行日志的搜集处理和输出。有点类似*NIX系统的管道命令 xxx | ccc | ddd,xxx执行完了会执行ccc,然后执行ddd。
在logstash中,包括了三个阶段:
输入input --> 处理filter(不是必须的) --> 输出output

每个阶段都由很多的插件配合工作,比如file、elasticsearch、redis等等。
每个阶段也可以指定多种方式,比如输出既可以输出到elasticsearch中,也可以指定到stdout在控制台打印。
由于这种插件式的组织方式,使得logstash变得易于扩展和定制。
命令行中常用的命令
-f:通过这个命令可以指定Logstash的配置文件,根据配置文件配置logstash
-e:后面跟着字符串,该字符串可以被当做logstash的配置(如果是“” 则默认使用stdin作为输入,stdout作为输出)
-l:日志输出的地址(默认就是stdout直接在控制台中输出)
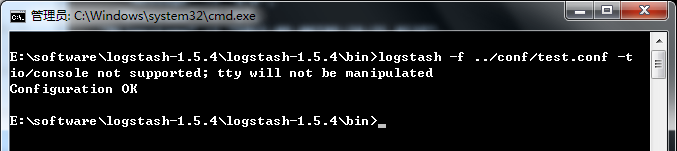
-t:测试配置文件是否正确,然后退出。
配置文件说明
前面介绍过logstash基本上由三部分组成,input、output以及用户需要才添加的filter,因此标准的配置文件格式如下:
input {...} filter {...} output {...}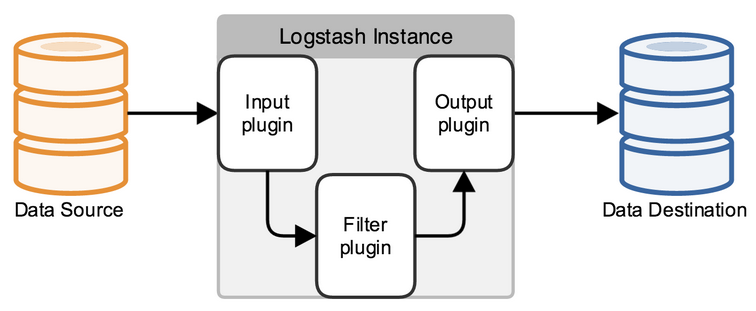
在每个部分中,也可以指定多个访问方式,例如我想要指定两个日志来源文件,则可以这样写:
input { file { path =>"/var/log/messages" type =>"syslog"} file { path =>"/var/log/apache/access.log" type =>"apache"} }类似的,如果在filter中添加了多种处理规则,则按照它的顺序一一处理,但是有一些插件并不是线程安全的。
比如在filter中指定了两个一样的的插件,这两个任务并不能保证准确的按顺序执行,因此官方也推荐避免在filter中重复使用插件。
说完这些,简单的创建一个配置文件的小例子看看:

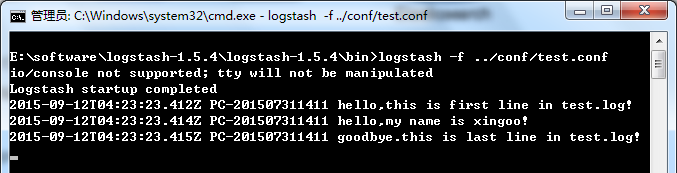
input { file {
#指定监听的文件路径,注意必须是绝对路径 path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/test.log" start_position => beginning }}filter { }output { stdout {}}
日志大致如下:
1 hello,this is first line in test.log!2 hello,my name is xingoo!3 goodbye.this is last line in test.log!
4
注意最后有一个空行。
执行命令得到如下信息:
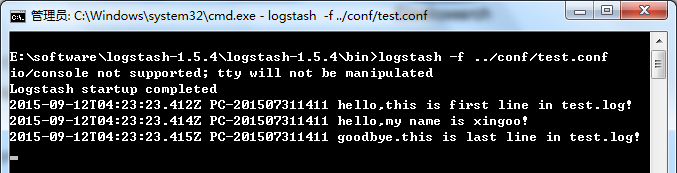
细心的会发现,这个日志输出与上面的logstash -e "" 并不相同,这是因为上面的命令默认指定了返回的格式是json形式。
至此,就是logstash入门篇的介绍了,稍后会介绍关于logstash更多的内容,感兴趣的可以关注哦!
F
参考
【1】Logstash官方文档:https://www.elastic.co/guide/en/logstash/current/index.html
Fluentd是一个日志收集系统,它的特点在于其各部分均是可定制化的,你可以通过简单的配置,将日志收集到不同的地方。
目前开源社区已经贡献了下面一些存储插件:MongoDB, Redis, CouchDB,AmazonS3, Amazon SQS, Scribe, 0MQ, AMQP, Delayed, Growl等等。

安装
可参考http://docs.fluentd.org/categories/installation安装
此版本采用: Installingtd-agent for Redhat and CentOS
http://docs.fluentd.org/articles/install-by-rpm
Fluentd 是由Ruby和C编写的,需要ruby进行,然而安装td-agent 是fluentd 的易安装版本,不用考虑太多的依赖关系。
1.首先please create /etc/yum.repos.d/td.repo with the followingcontents.
[treasuredata]
name=TreasureData
baseurl=http://packages.treasure-data.com/redhat/$basearch
gpgcheck=0
Then,you can install via yum command.
2. $ yumupdate
$ yuminstall td-agent
3. 安装完成后,可使用以下方式启动关闭服务。
$ /etc/init.d/td-agent start
$ /etc/init.d/td-agent stop
$/etc/init.d/td-agent restart
4. 默认的 /etc/td-agent/td-agent.conf 为td-agent的配置文件
/var/log/td-agent/td-agent.log 为td-agent的日志文件
5. 查看td-agent的安装
6.查看ruby fluent插件的列表:ruby的安装路径在/usr/lib64/fluent/ruby/

fluent-plugin-tail-ex与fluent-plugin-tail-multiline为后期安装的插件,其他的为安装td-agent后默认安装的插件。
fluent-plugin-tail-ex:为输入扩展插件,支持对文件路径、日期的扩展
fluent-plugin-tail-multiline:为输入扩展插件,支持多行数据的收集,能够更好的收集异常信息。
5. 插件安装
Fluent插件地址http://fluentd.org/plugin/
两种安装方法:
1) 可以本地安装,下载gem安装包 https://rubygems.org/gems,推荐此方法
2) ruby库远程安装
两种方法的安装命令为:$ /usr/lib64/fluent/ruby/bin/gem install 插件名称
6. 配置
首先我们编辑配置文件/etc/td-agent/td-agent.conf 中的source来设置日志来源
- <source>
- type tail
- format apache
- path /var/log/apache2/access_log
- pos_file /var/log/apache2/access_log.pos
- tag mongo.apache
- </source>
其中:
type tail: tail方式是 Fluentd 内置的输入方式,其原理是不停地从源文件中获取增量日志,与linx命令tail相似,也可以使用其他输入方式如http、forward等输入,也可以使用输入插件,将 tail 改为相应的插件名称 如: type tail_ex ,注意tail_ex为下划线。
format apache: 指定使用 Fluentd 内置的 Apache 日志解析器。可以自己配置表达式。
path /var/log/apache2/access_log: 指定收集日志文件位置。
Pos_file /var/log/apache2/access_log.pos:强烈建议使用此参数,access_log.pos文件可以自动生成,要注意access_log.pos文件的写入权限,因为要将access_log上次的读取长度写入到该文件,主要保证在fluentd服务宕机重启后能够继续收集,避免日志数据收集丢失,保证数据收集的完整性。
tag mongo.apache: 指定tag,tag被用来对不同的日志进行分类,与后面的标签match相匹配。
下面再来编辑输出配置,配置日志收集后存储到MongoDB中,也可以输出到其他组件如文件,转发等。
- <match mongo.**>
- # plugin type
- type mongo
- # mongodb db + collection
- database apache
- collection access
- # mongodb host + port
- host localhost
- port 27017
- # interval
- flush_interval 10s
- </match>
match标签后面可以跟正则表达式以匹配我们指定的tag,只有匹配成功的tag对应的日志才会运用里面的配置。配置中的其它项都比较好理解,看注释就可以了,其中flush_interval是用来控制多长时间将日志写入MongoDB一次。
7.高可用的配置:http://docs.fluentd.org/articles/high-availability

- # TCP input
- <source>
- type forward
- port 24224
- </source>
- # HTTP input
- <source>
- type http
- port 8888
- </source>
- # Log Forwarding
- <match mytag.**>
- type forward
- # primary host
- <server>
- host 192.168.0.1
- port 24224
- </server>
- # use secondary host
- <server>
- host 192.168.0.2
- port 24224
- standby
- </server>
- # use longer flush_interval to reduce CPU usage.
- # note that this is a trade-off against latency.
- flush_interval 60s
- </match>
8.fluent对java的支持:fluent-logger-java is a Java library, to record events via Fluentd, from Java application.
http://fluentd.org/releases/java/ 可下载最新的jar
- import java.util.HashMap;
- import java.util.Map;
- import org.fluentd.logger.FluentLogger;
- public class Main {
- private static FluentLogger LOG = FluentLogger.getLogger("app", "192.168.0.1", 24224);
- public static void main(String[] args) {
- // ...
- Map<String, String> data = new HashMap<String, String>();
- data.put("from", "aaa");
- data.put("to", "bbb");
- LOG.log("follow", data); //...
- FluentLogger.close();
- }
- }
配置fluentd服务器端/etc/td-agent/td-agent.conf
添加:
- <source>
- ##必须启动tcp端口,端口号为24224,不加port属性默认为24224
- type tcp
- port 24224
- </source>
- ##app.** 与java中的app匹配
- <match app.**>
- ##匹配输出到/var/log/td-agent/td-agent.log
- type stdout
- </match>
2013-06-06 12:56:01 +0800 app.follow: {"to":"bbb","from":"aaa"}
关于fluentd(td-agent)的使用
首先,td-agent是一个老外写的一个日子采集工具,可以方便的实时采集日志,并且有很多第三方的插件,可以使用。
td-agent的安装请参照:http://docs.fluentd.org/articles/install-by-rpm
安装完之后,核心的配置文件在/etc/td-agent/td-agent.conf,log的位置在/var/log/td-agent/td-agent.log
在使用中,我们一般会添加一些重要的插件。笔者,在使用的过程中就用了grep插件和kafka插件。
插件的安装方法如下:
安装成功后就可以通过 service td-agent start其中服务。
介绍一下配置文件:
重要的要素:
source:用来配置采集的文件的位置
<source>
type tail
path /home/wyyhzc/webApp.log
pos_file /home/wyyhzc/webApp.log.pos
tag webapp
format /^(?<message>(.*))$/
</source>
match:用来配置输出的位置
#用来对log进行过滤,毕竟我们不是所有的log都关心,笔者在关心的log的行里面增加了\u0001的特殊字符
<match webapp.**>
type grep
regexp1 message \u0001
add_tag_prefix webapp_filtered
</match>
#将过滤后的数据发送到kafka的队列里面
<match webapp_filtered.**>
type kafka
brokers hadoopdn1:9092
default_topic webapp_log
output_data_type json
</match>
fluentd结合kibana、elasticsearch实时搜索分析hadoop集群日志
Fluentd是一个开源收集事件和日志系统,它目前提供150+扩展插件让你存储大数据用于日志搜索,数据分析和存储。
官方地址http://fluentd.org/ 插件地址http://fluentd.org/plugin/
Kibana 是一个为 ElasticSearch 提供日志分析的 Web ui工具,可使用它对日志进行高效的搜索、可视化、分析等各种操作。官方地址http://www.elasticsearch.org/overview/kibana/
elasticsearch 是开源的(Apache2协议),分布式的,RESTful的,构建在Apache Lucene之上的的搜索引擎.
官方地址http://www.elasticsearch.org/overview/ 中文地址 http://es-cn.medcl.net/
具体的工作流程就是利用fluentd 监控并过滤hadoop集群的系统日志,将过滤后的日志内容发给全文搜索服务ElasticSearch, 然后用ElasticSearch结合Kibana 进行自定义搜索web页面展示.
下面开始说部署方法和过程。以下安装步骤在centos 5 64位测试通过
一、 elasticsearch安装部署
elasticsearch 官方提供了几种安装包,适用于windows的zip压缩包,适用于unix/linux的tar.gz压缩包,适用于centos系统的rpm包和ubuntu的deb包。大家可以自己选择安装使用。
因为elasticsearch 需要java环境运行,首先需要安装jdk,安装步骤就省略了。
使用.tar.gz压缩包安装部署的话,先下载压缩包
# wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-0.90.5.tar.gz
# tar zxvf elasticsearch-0.90.5.tar.gz
////////////如果是单机部署
# cd elasticsearch-0.90.5
# elasticsearch-0.90.5/bin/elasticsearch -f
就可以启动搜索服务了,查看端口9200是否打开,如果打开说明启动正常。
////////////////如果是部署集群的话,需要进行配置
例如在192.168.0.1 192.168.0.2 两台服务器部署,两台服务器都安装好jdk,下载elasticsearch 解压缩,然后编辑配置文件
//////////////////////192.168.0.1 服务器编辑文件
vi elasticsearch-0.90.5/config/elasticsearch.yml
删除cluster.name 前面注释,修改集群名称
cluster.name: es_cluster
删除node.name前注释 ,修改节点名称,不修改的话,系统启动后会生成随即node名称。
node.name: "elastic_inst1"
node.master: true 设置该节点为主节点
/////////////////////////192.168.0.2 编辑文件
vi elasticsearch-0.90.5/config/elasticsearch.yml
删除cluster.name 前面注释,修改集群名称
cluster.name: es_cluster
删除node.name前注释 ,修改节点名称,不修改的话,系统启动后会生成随即node名称。
node.name: "elastic_inst2"
node.master: false 设置该节点为主节点
分别启动两台服务器的服务后,在192.168.0.2的日志中会看到
[elastic_inst2] detected_master [elastic_inst1] 日志信息。说明集群连接成功。
二、安装部署fluentd
在需要监控分析的hadoop集群节点中安装fluentd,安装步骤很简单
curl -L http://toolbelt.treasure-data.com/sh/install-redhat.sh | sh安装完成后,编辑配置文件
# vim /etc/td-agent/td-agent.conf
- <source>
- type tail #### tail方式采集日志
- path /var/log/hadoop/mapred/hadoop-mapred-tasktracker-node-128-70.log ### hadoop日志路径
- pos_file /var/log/td-agent/task-access.log.pos
- tag task.mapred
- format /^(?<message>.+(WARN|ERROR).+)$/ #### 收集error 或者warn 日志。
- </source>
- <match task.**>
- host 192.168.0.1 ##### <span style="font-family:Arial,Helvetica,sans-serif">elasticsearch 服务器地址</span>
- type elasticsearch
- logstash_format true
- flush_interval 5s
- include_tag_key true
- tag_key mapred
- </match>
启动fluentd 服务
# service td-agent start
三、安装部署kibana 3
kibana 3 是使用html 和javascript 开发的web ui前端工具。
下载 wget http://download.elasticsearch.org/kibana/kibana/kibana-latest.zip
解压缩 unzip kibana-latest.zip
安装apache yum -y install httpd
cp -r kibana-latest /var/www/html
因为我将kibana3 安装在和elasticsearch同一台服务器中,所以不用修改配置文件
启动apache service httpd start
打开浏览器 http://ip/kibana 就可以看到kibana 界面
初次使用kibana 需要自己定义模块

- 日志搜集、过滤及推送处理框架logstash及fluentd总结
- 日志搜集处理框架------[Logstash]使用详解
- Logstash 日志搜集处理框架 安装配置
- log4j SocketAppender 使用及与向logstash端口推送日志
- (ELK/EFK)之Fluentd日志过滤解析与客户端IP地址地理位置处理
- sqlserver日志文件总结及充满处理
- sqlserver日志文件总结及充满处理
- iOS崩溃日志分析及搜集
- Elasticsearch索引和mapping及logstash配置文件过滤(教程2)
- logstash 处理tomcat日志
- Fluentd vs Logstash
- Logstash,Fluentd, Logtail比较
- SQL日志文件总结及日志满的处理
- SQL日志文件总结及日志满的处理
- MSSQL 日志文件总结及日志满的处理
- SQL Server日志文件总结及日志满的处理
- Logstash5.X 日志搜集处理框架 安装配置
- 搭建ELK(ElasticSearch+Logstash+Kibana)日志分析系统(八) elasticsearch配置外网访问及常见错误处理
- HTML5进阶(三)HBuilder实现软件自动升级(优化篇)
- TCP/IP入门(2)
- 杭电ACM2035人见人爱的A^B
- HttpServletResponse和HttpServletRequest常见应用
- 表分区建立以及删除.sql
- 日志搜集、过滤及推送处理框架logstash及fluentd总结
- Java Lambda表达式入门
- 移植代码到linux内核中大概流程
- Java中sleep()与wait()区别
- Silverlight 错误解决方案
- IOS中修改导航默认标题颜色、字体
- axis2 以 RPC的方式访问webservice
- python abc
- 图论


