Binary Tree Traversal二叉树遍历方法总结
来源:互联网 发布:mysql 博客 编辑:程序博客网 时间:2024/06/05 17:15
Binary Tree Traversal二叉树遍历方法总结
摘要
这里总结的二叉树遍历分为两大类:
- 深度优先(depth-first traversal)
- 广度优先(breadth-first traversal)
其中深度优先包括三种类型:
- PreOrder traversal:以“父节点-左子节点-右子节点”为顺序
- InOrder traversal:以“左子节点-父节点-右子节点”为顺序
- PostOrder traversal:以“左子节点-右子节点-父节点”为顺序
广度优先只包括一种类型:
- LevelOrder traversal:从上到下每层从左到右顺序
举个例子,不同方法遍历下图中的二叉树结果:

PreOrder traversal:8, 5, 9, 7, 1, 12, 2, 4, 11, 3
InOrder traversal:9, 5, 1, 7, 2, 12, 8, 4, 3, 11
PostOrder traversal:9, 1, 2, 12, 7, 5, 3, 11, 4, 8
LevelOrder traversal:8, 5, 4, 9, 7, 11, 1, 12, 3, 2
下图为不同方法遍历该树,访问的节点顺序:

代码实现
PreOrder traversal
在此类型中,我们将遍历的节点依次存入一个List中(也可以直接print)。
迭代方法
public class TreeNode { //树节点类,此后不再重复声明此类 int val; //树节点值 TreeNode left; //左子节点 TreeNode right; //右子节点 TreeNode(int x) { val = x; }}public class solution{ public ArrayList<Integer> preOrder(TreeNode root){ List<Integer> pre = new ArrayList<>(); preHelper(root, pre); return pre; } public void preHelper(TreeNode root, ArrayList pre){ if(root == null) return; pre.add(root.val); //此时访问的节点非空,先将其加入list preHelper(root.left, pre); //访问该节点的左子节点 preHelper(root.right, pre); //此时从根开始的左节点都访问完了,访问右节点 }}遍历方法
遍历方法借助Stack数据结构来实现,步骤如下:
1. 创建空Stack,先将根节点存入
2. 在Stack不为空的情况下重复以下步骤:
<1>弹出(.pop())一个Stack中的元素(元素类型为树节点)并将它的值存入list
<2>若<1>中弹出节点的右子节点非空,将该右子节点存入Stack
<3>若<1>中弹出节点的左子节点非空,将该左子节点存入Stack
此方法利用了Stack数据结构“后进先出”的特性,存入时先右后左,弹出时才能先弹出左,再弹出右,以下为代码:
public ArrayList<Integer> preOrderIterate(TreeNode root){ List<Integer> pre = new ArrayList<>(); if(root == null) return pre; Stack<TreeNode> tovisit = new Stack<>(); tovisit.push(root); //步骤1 while(!tovisit.empty()){ TreeNode visiting = tovisit.pop(); //步骤2<1> pre.add(visiting.val); //步骤2<1> if(visiting.right != null) tovisit.push(visiting.right); //步骤2<2> if(visiting.left != null) tovisit.push(visiting.left); //步骤2<3> }}InOrder traversal
迭代方法
public class Solution { List<Integer> result = new ArrayList<Integer>(); public List<Integer> inorderTraversal(TreeNode root) { if(root !=null){ helper(root); } return result; } public void helper(TreeNode p){ if(p.left!=null) helper(p.left); //若该节点的左子非空,先访问该左子节点 result.add(p.val); //此时访问节点的左子为空,存入访问节点 if(p.right!=null) helper(p.right); //再访问右子节点 }}遍历方法
public ArrayList<Integer> inorderTraversal(TreeNode root) { ArrayList<Integer> lst = new ArrayList<Integer>(); if(root == null) return lst; Stack<TreeNode> stack = new Stack<TreeNode>(); TreeNode p = root; //p为正在访问的节点 while(!stack.empty() || p != null){ //若正在访问的节点非空,先将其存入Stack,然后访问其左子节点 if(p != null){ stack.push(p); p = p.left; }else{ //正在访问的节点为空,弹出一个节点(为正在访问的空节点的父节点) TreeNode t = stack.pop(); lst.add(t.val); //将该父节点的值存入list p = t.right; //访问该父节点的右子节点 } } return lst; }PostOrder traversal
迭代方法
下图为postOrder迭代过程图:
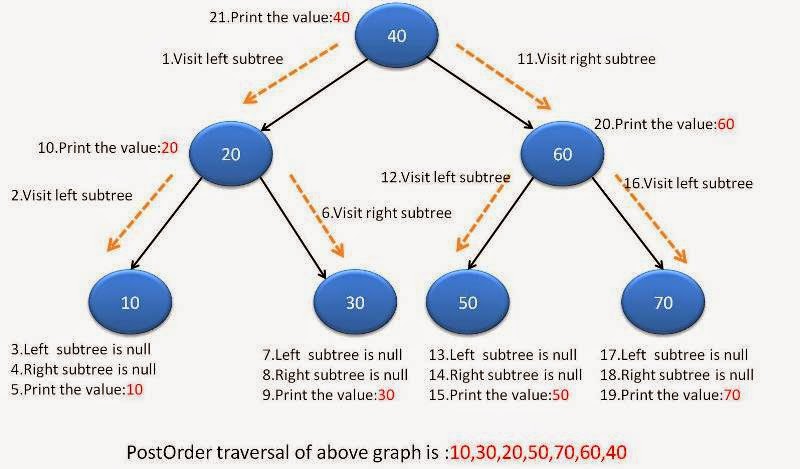
代码如下:
public void postOrder(TreeNode root){ if(root != null){ postOrder(root.left); postOrder(root.right); System.out.println(root.val); }}遍历方法
public List<Integer> postorderTraversal(TreeNode root) { List<Integer> res = new ArrayList<>(); if(root==null) { return res; } Stack<TreeNode> stack = new Stack<>(); stack.push(root); while(!stack.isEmpty()) { TreeNode temp = stack.peek(); if(temp.left==null && temp.right==null) { TreeNode pop = stack.pop(); res.add(pop.val); } else { //若不是末端节点,先存右子,再存左子进Stack if(temp.right!=null) { stack.push(temp.right); temp.right = null; } if(temp.left!=null) { stack.push(temp.left); temp.left = null; } } } return res; }不论是迭代还是遍历,深度优先的三种类型在代码上都有相似之处,且遍历方法都用到了Stack数据结构。这种相似性是由于都为深度优先而产生的,不同之处在于输出的节点顺序不同,对比一下代码比较容易发现规律。
LevelOrder traversal
广度优先遍历利用Queue的“先进先出”特性,代码如下:
Queue<TreeNode> queue=new LinkedList<TreeNode>(); queue.add(startNode); //存入根节点 while(!queue.isEmpty()) { TreeNode tempNode=queue.poll(); //弹出最早加入的节点(第一次弹出为根节点) System.out.printf("%d ",tempNode.data); //访问并打印出该节点 if(tempNode.left!=null) queue.add(tempNode.left); //若访问节点的左子非空,存入左子 if(tempNode.right!=null) queue.add(tempNode.right); //右子随后存入 } 下图可以辅助理解广度优先遍历,例如这个二叉树: 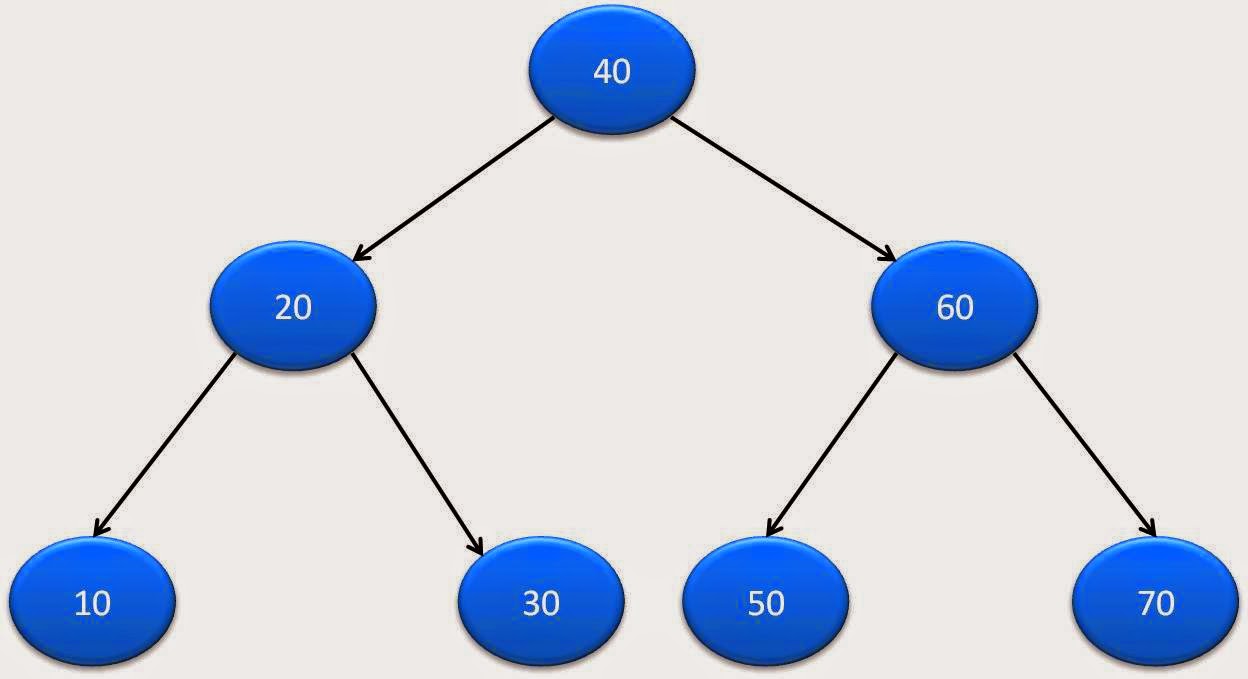
执行广度优先遍历代码时,运行过程如下: 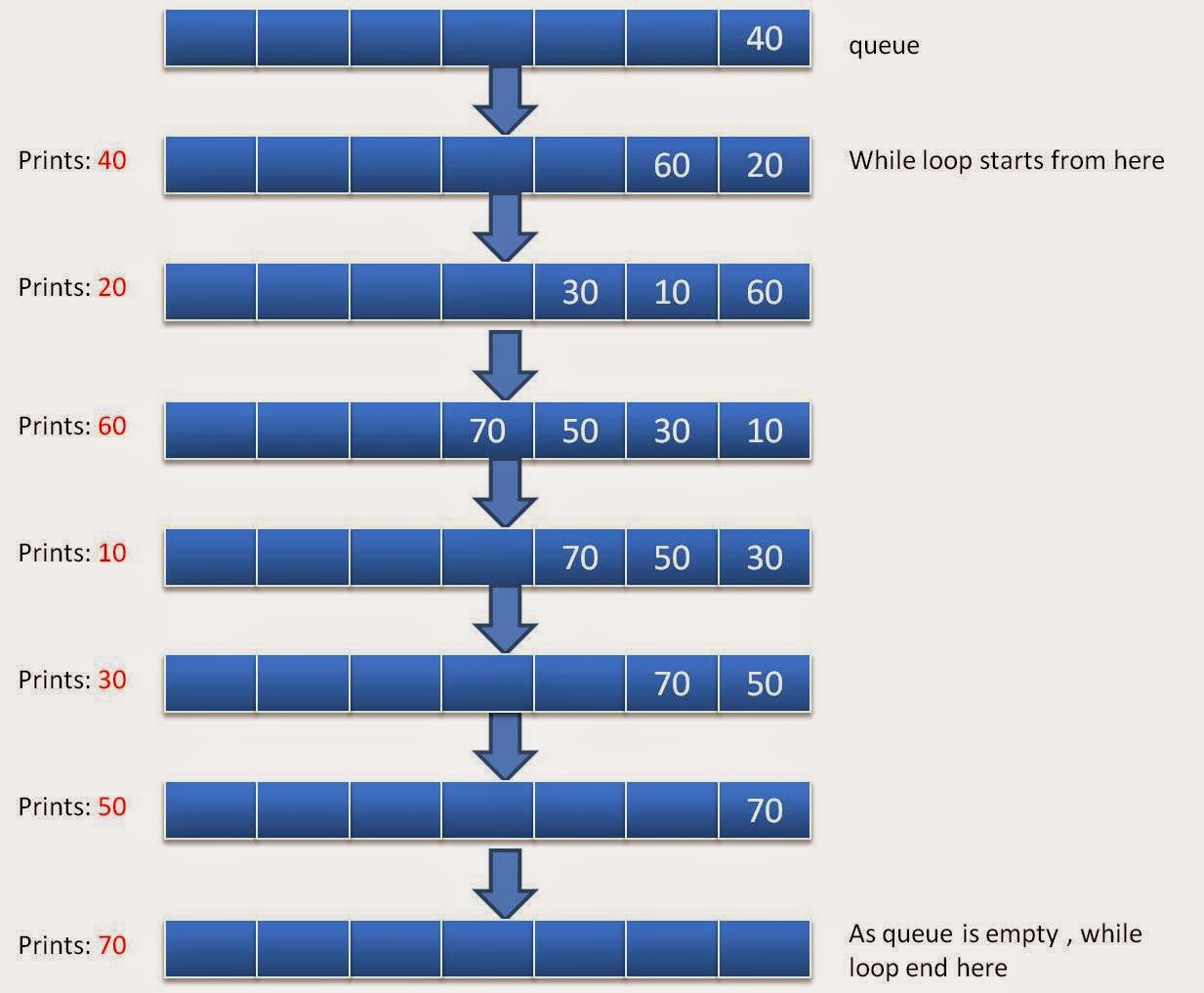
在广度优先中借助了先进先出的Queue数据结构,使得先存进去的上层节点被优先打印出来,而这也是和深度优先不同的地方,深度优先正是利用了先进后出的Stack数据结构,才使得先存进去的上层节点,在其左右子以某种顺序(Pre, In, Post)打印之后才被打印,由此实现了深度优先。
参考:https://www.cs.cmu.edu/~adamchik/15-121/lectures/Trees/trees.html
http://www.java2blog.com/2014/08/binary-tree-in-java.html
- Binary Tree Traversal二叉树遍历方法总结
- LeetCode:Binary Tree Preorder Traversal(非递归方法前序遍历二叉树)
- leetCode 102.Binary Tree Level Order Traversal (二叉树水平遍历) 解题思路和方法
- 【LeetCode】Binary Tree Preorder Traversal 二叉树的前序遍历(3种方法)- Easy+
- LeetCode Binary Tree Inorder Traversal 中序遍历二叉树
- 二叉树的先序遍历 Binary Tree Preorder Traversal
- Binary Tree Preorder Traversal--二叉树的先序遍历
- Binary Tree Level Order Traversal 分层遍历二叉树@LeetCode
- Binary Tree Postorder Traversal-二叉树的后序遍历
- Binary Tree Postorder Traversal 二叉树后续遍历@LeetCode
- Binary Tree Preorder Traversal 二叉树的前序遍历
- Binary Tree Inorder Traversal 二叉树的中序遍历
- Binary Tree Postorder Traversal 二叉树的后序遍历
- 二叉树的中序遍历 Binary Tree Inorder Traversal
- 【二叉树的后续遍历】Binary Tree Postorder Traversal
- 二叉树的后序遍历 Binary Tree Postorder Traversal
- 【二叉树层次遍历】Binary Tree Level Order Traversal
- Binary Tree Postorder Traversal 二叉树的后序遍历
- ScalaTest测试框架
- 提高你使用android studio的效率之键盘篇
- 2009年浙江大学计算机及软件工程研究生机试真题
- shader实例(二十)法线贴图实现凹凸效果
- 93. Restore IP Addresses
- Binary Tree Traversal二叉树遍历方法总结
- 【Leetcode】Reverse Words in a String II
- hdu 2521(反素数)
- 华为的JAVA面试题及答案(部分)
- 20070929迅雷面试部分题
- hello world
- 经典排序算法(Java版)
- HDU1298 T9
- JAVA面试题4


