PigPen:用Clojure写MapReduce Introducing PigPen: Map-Reduce for Clojure
来源:互联网 发布:linux 编译tar.gz 编辑:程序博客网 时间:2024/05/16 07:11
It is our pleasure to release PigPen to the world today. PigPen is map-reduce for Clojure. It compiles toApache Pig, but you don’t need to know much about Pig to use it.
What is PigPen?
- A map-reduce language that looks and behaves like clojure.core
- The ability to write map-reduce queries as programs, not scripts
- Strong support for unit tests and iterative development
Note: If you are not familiar at all with Clojure, we strongly recommend that you try a tutorial here, here, orhere to understand some of the basics.
Really, yet another map-reduce language?
If you know Clojure, you already know PigPen
The primary goal of PigPen is to take language out of the equation. PigPen operators are designed to be as close as possible to the Clojure equivalents. There are no special user defined functions (UDFs). Define Clojure functions, anonymously or named, and use them like you would in any Clojure program.
Here’s the proverbial word count:
(require '[pigpen.core :as pig])(defn word-count [lines] (->> lines (pig/mapcat #(-> % first (clojure.string/lower-case) (clojure.string/replace #"[^\w\s]" "") (clojure.string/split #"\s+"))) (pig/group-by identity) (pig/map (fn [[word occurrences]] [word (count occurrences)]))))This defines a function that returns a PigPen query expression. The query takes a sequence of lines and returns the frequency that each word appears. As you can see, this is just the word count logic. We don’t have to conflate external concerns, like where our data is coming from or going to.
Will it compose?
Yep - PigPen queries are written as function compositions - data in, data out. Write it once and avoid the copy & paste routine.
Here we use our word-count function (defined above), along with a load and store command, to make a PigPen query:
(defn word-count-query [input output] (->> (pig/load-tsv input) (word-count) (pig/store-tsv output)))This function returns the PigPen representation of the query. By itself, it won’t do anything - we have to execute it locally or generate a script (more on that later).
You like unit tests? Yeah, we do that
With PigPen, you can mock input data and write a unit test for your query. No more crossing your fingers & wondering what will happen when you submit to the cluster. No more separate files for test input & output.
Mocking data is really easy. With pig/return and pig/constantly, you can inject arbitrary data as a starting point for your script.
A common pattern is to use pig/take to sample a few rows of the actual source data. Wrap the result withpig/return and you’ve got mock data.
(use 'clojure.test)(deftest test-word-count (let [data (pig/return [["The fox jumped over the dog."] ["The cow jumped over the moon."]])] (is (= (pig/dump (word-count data)) [["moon" 1] ["jumped" 2] ["dog" 1] ["over" 2] ["cow" 1] ["fox" 1] ["the" 4]]))))The pig/dump operator runs the query locally.
Closures (yes, the kind with an S)
Parameterizing your query is trivial. Any in-scope function parameters or let bindings are available to use in functions.
(defn reusable-fn [lower-bound data] (let [upper-bound (+ lower-bound 10)] (pig/filter (fn [x] (< lower-bound x upper-bound)) data)))Note that lower-bound and upper-bound are present when we generate the script, and are made available when the function is executed within the cluster.
So how do I use it?
Just tell PigPen where to write the query as a Pig script:
(pig/write-script "word-count.pig" (word-count-query "input.tsv" "output.tsv"))And then you have a Pig script which you can submit to your cluster. The script uses pigpen.jar, an uberjar with all of the dependencies, so make sure that is submitted with it. Another option is to build an uberjar for your project and submit that instead. Just rename it prior to submission. Check out the tutorial for how to build an uberjar.
As you saw before, we can also use pig/dump to run the query locally and return Clojure data:
=> (def data (pig/return [["The fox jumped over the dog."] ["The cow jumped over the moon."]]))#'pigpen-demo/data=> (pig/dump (word-count data))[["moon" 1] ["jumped" 2] ["dog" 1] ["over" 2] ["cow" 1] ["fox" 1] ["the" 4]]If you want to get started now, check out getting started & tutorials.
Why do I need Map-Reduce?
Map-Reduce is useful for processing data that won’t fit on a single machine. With PigPen, you can process massive amounts of data in a manner that mimics working with data locally. Map-Reduce accomplishes this by distributing the data across potentially thousands of nodes in a cluster. Each of those nodes can process a small amount of the data, all in parallel, and accomplish the task much faster than a single node alone. Operations such as join and group, which require coordination across the dataset, are computed by partitioning the data with a common join key. Each value of the join key is then sent to a specific machine. Once that machine has all of the potential values, it can then compute the join or do other interesting work with them.
To see how PigPen does joins, let’s take a look at pig/cogroup. Cogroup takes an arbitrary number of data sets and groups them all by a common key. Say we have data that looks like this:
foo: {:id 1, :a "abc"} {:id 1, :a "def"} {:id 2, :a "abc"}bar: [1 42] [2 37] [2 3.14]baz: {:my_id "1", :c [1 2 3]]}If we want to group all of these by id, it looks like this:
(pig/cogroup (foo by :id) (bar by first) (baz by #(-> % :my_id Long/valueOf)) (fn [id foos bars bazs] ...))The first three arguments are the datasets to join. Each one specifies a function that is applied to the source data to select the key. The last argument is a function that combines the resulting groups. In our example, it would be called twice, with these arguments:
[1 ({:id 1, :a "abc"}, {:id 1, :a "def"}) ([1 42]) ({:my_id "1", :c [1 2 3]]})][2 ({:id 2, :a "abc"}) ([2 37] [2 3.14]) ()]As you can see, this consolidates all of the values with an id of 1, all of the values with 2, etc. Each different key value can then be processed independently on different machines. By default, keys are not required to be present in all sources, but there are options that can make them required.
Hadoop provides a very low-level interface for doing map-reduce jobs, but it’s also very limited. It can only run a single map-reduce pair at a time as it has no concept of data flow or a complex query. Pig adds a layer of abstraction on top of Hadoop, but at the end of the day, it’s still a scripting language. You are still required to use UDFs (user defined functions) to do interesting tasks with your data. PigPen furthers that abstraction by making map-reduce available as a first class language.
If you are new to map-reduce, we encourage you to learn more here.
Motivations for creating PigPen
- Code reuse. We want to be able to define a piece of logic once, parameterize it, and reuse it for many different jobs.
- Consolidate our code. We don’t like switching between a script and a UDF written in different languages. We don’t want to think about mapping between differing data types in different languages.
- Organize our code. We want our code in multiple files, organized how we want - not dictated by the job it belongs to.
- Unit testing. We want our sample data inline with our unit tests. We want our unit tests to test the business logic of our jobs without complications of loading or storing data.
- Fast iteration. We want to be able to trivially inject mock data at any point in our jobs. We want to be able to quickly test a query without waiting for a JVM to start.
- Name what you want to. Most map-reduce languages force too many names and schemas on intermediate products. This can make it really difficult to mock data and test isolated portions of jobs. We want to organize and name our business logic as we see fit - not as dictated by the language.
- We’re done writing scripts; we’re ready to start programming!
Note: PigPen is not a Clojure wrapper for writing Pig scripts you can hand edit. While it’s entirely possible, the resulting scripts are not intended for human consumption.
Design & Features
PigPen was designed to match Clojure as closely as possible. Map-reduce is functional programming, so why not use an awesome functional programming language that already exists? Not only is there a lower learning curve, but most of the concepts translate very easily to big data.
In PigPen, queries are manipulated as expression trees. Each operation is represented as a map of information about what behavior is desired. These maps can be nested together to build a tree representation of a complex query. Each command also contains references to its ancestor commands. When executed, that query tree is converted into a directed acyclic query graph. This allows for easy merging of duplicate commands, optimizing sequences of related commands, and instrumenting the query with debug information.
Optimization
De-duping
When we represent our query as a graph of operations, de-duping them is trivial. Clojure provides value-equality, meaning that if two objects have the same content, they are equal. If any two operations have the same representation, then they are in fact identical. No care has to be taken to avoid duplicating commands when writing the query - they’re all optimized before executing it.
For example, say we have the following query:
(let [even-squares (->> (pig/load-clj "input.clj") (pig/map (fn [x] (* x x))) (pig/filter even?) (pig/store-clj "even-squares.clj")) odd-squares (->> (pig/load-clj "input.clj") (pig/map (fn [x] (* x x))) (pig/filter odd?) (pig/store-clj "odd-squares.clj"))] (pig/script even-squares odd-squares))In this query, we load data from a file, compute the square of each number, and then split it into even and odd numbers. Here’s what a graph of this operation would look like:

This matches our query, but it’s doing some extra work. It’s loading the same input.clj file twice and computing the squares of all of the numbers twice. This might not seem like a lot of work, but when you do it on a lot of data, simple operations really add up. To optimize this query, we look for operations that are identical. At first glance it looks like our operation to compute squares might be a good candidate, but they actually have different parents so we can’t merge them yet. We can, however, merge the load functions because they don’t have any parents and they load the same file.
Now our graph looks like this:
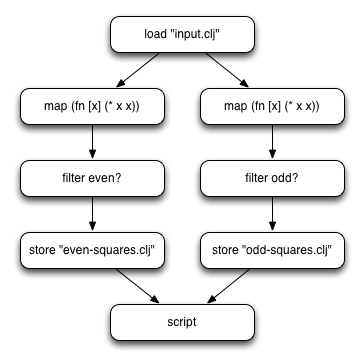
Now we’re loading the data once, which will save some time, but we’re still doing the squares computation twice. Since we now have a single load command, our map operations are now identical and can be merged:

Now we have an optimized query where each operation is unique. Because we always merge commands one at a time, we know that we’re not going to change the logic of the query. You can easily generate queries within loops without worrying about duplicated execution - PigPen will only execute the unique parts of the query.
Serialization
After we’re done processing data in Clojure, our data must be serialized into a binary blob so Pig can move it around between machines in a cluster. This is an expensive, but essential step for PigPen. Luckily, many consecutive operations in a script can often be packed together into a single operation. This saves a lot of time by not serializing and deserializing the data when we don’t need to. For example, any consecutive map,filter, and mapcat operations can be re-written as a single mapcat operation.
Let’s look at some examples to illustrate this:

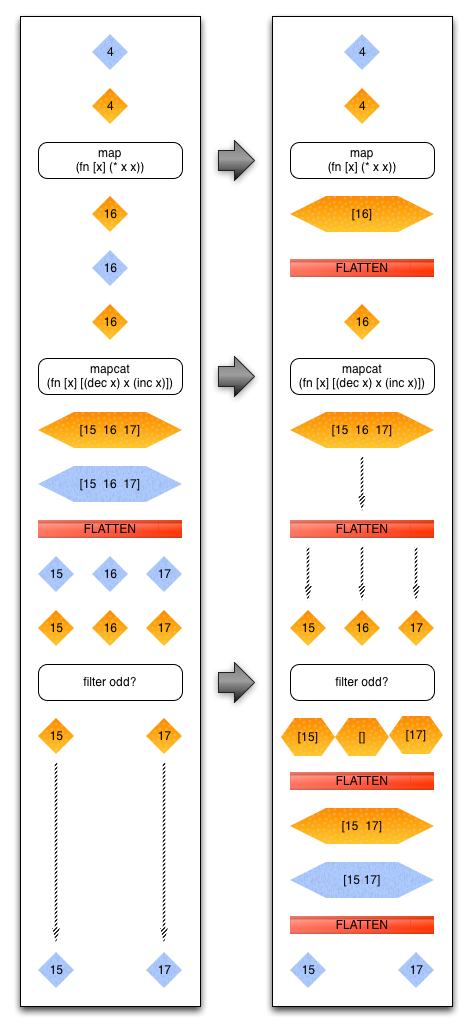
In this example, we start with a serialized (blue) value, 4, deserialize it (orange), apply our map function, and re-serialize the value.
Now let’s try a slightly more complex (and realistic) example. In this example, we apply a map, mapcat, andfilter operation.
If you haven’t used it before, mapcat is an operation where we apply a function to a value and that function returns a sequence of values. That sequence is then ‘flattened’ and each single value is fed into the next step. In Clojure, it’s the result of combining map and concat. In Scala, this is called flatMap and in c# it’s called selectMany.
In the diagram below, the flow on the left is our query before the optimization; the right is after the optimization. We start with the same value, 4, and calculate the square of the value; same as the first example. Then we take our value and apply a function that decrements the value, returns the value, and increments the value. Pig then takes this set of values and flattens them, making each one an input to the next step. Note that we had to serialize and deserialize the data when interacting with Pig. The third and final step is to filter the data; in this example we’re retaining only odd values. As you can see, we end up serializing and deserializing the data in between each step.
The right hand side shows the result of the optimization. Put simply, each operation now returns a sequence of elements. Our map operation returns a sequence of one element, 16, our mapcat remains the same, and our filter returns a sequence of zero or one elements. By making these commands more uniform, we can merge them more easily. We end up flattening more sequences of values within the set of commands, but there is no serialization cost between steps. While it looks more complex, this optimization results in much faster execution of each if these steps.
Testing, Local Execution, and Debugging
Iterative development, testing, and debuggability are key tenants of PigPen. When you have jobs that can run for days at a time, the last thing you need is an unexpected bug to show up in the eleventh hour. PigPen has a local execution mode that’s powered by rx. This allows us to write unit tests for our queries. We can then know with very high confidence that something will not crash when run and will actually return the expected results. Even better, this feature allows for iterative development of queries.
Typically, we start with just a few records of the source data and use that to populate a unit test. Because PigPen returns data in the REPL, we don’t have to go elsewhere to build our test data. Then, using the REPL, we add commands to map, filter, join, and reduce the mock data as required; each step of the way verifying that the result is what we expect. This approach produces more reliable results than building a giant monolithic script and crossing your fingers. Another useful pattern is to break up large queries into smaller functional units. Map-reduce queries tend to explode and contract the source data by orders of magnitude. When you try to test the script as a whole, you often have to start with a very large amount of data to end up with just a few rows. By breaking the query into smaller parts, you can test the first part, which may take 100 rows to produce two; and then test the second part by using those two rows as a template to simulate 100 more fake ones.
Debug mode has proven to be really useful for fixing the unexpected. When enabled, it will write to disk the result of every operation in the script, in addition to the normal outputs. This is very useful in an environment such as Hadoop, where you can’t step through code and hours may pass in between operations. Debug mode can also be coupled with a graph-viz visualization of the execution graph. You can then visually associate what it plans to do with the actual output of each operation.
To enable debug mode, see the options for pig/write-script and pig/generate-script. It will write the extra debug output to the folder specified.
Example of debug mode enabled:
(pig/write-script {:debug "/debug-output/"} "my-script.pig" my-pigpen-query)To enable visualization, take a look at pig/show and pig/dump&show
Example of visualization:
(pig/show my-pigpen-query) ;; Shows a graph of the query(pig/dump&show my-pigpen-query) ;; Shows a graph and runs it locallyExtending PigPen
One nice feature of PigPen is that it’s easy to build your own operators. For example, we built set and multi-set operators such as difference and intersection. These are just variants of other operations like co-group, but it’s really nice to define them once, test them thoroughly, and not have to think about the logic behind a multiset intersection of n sets ever again.
This is useful for more complex operators as well. We have a reusable statistics operator that computes the sum, avg, min, max, sd, and quantiles for a set of data. We also have a pivot operator that groups dimensional fields in the data and counts each group.
While each of these by themselves are simple operations, when you abstract them out of your query, your query starts to become a lot smaller and simpler. When your query is smaller and simpler, you can spend more time focusing on the actual logic of the problem you’re trying to solve instead of re-writing basic statistics each time. What you’re doing becomes clearer, every step of the way.
Why Pig?
We chose Pig because we didn’t want to re-implement all of the optimization work that has gone into Pig already. If you take away the language, Pig does an excellent job of moving big data around. Our strategy was to use Pig’s DataByteArray binary format to move around serialized Clojure data. In most cases, we found that Pig didn’t need to be aware of the underlying types present in the data. Byte arrays can be compared trivially and quickly, so for joins and groupings, Pig simply needs to compare the serialized blob. We get Clojure’s great value equality for free as equivalent data structures produce the same serialized output. Unfortunately, this doesn’t hold true for sorting data. The sorted order of a binary blob is far less than useful, and doesn’t match the sorted order of the native data. To sort data, we must fall back to the host language, and as such, we can only sort on simple types. This is one of very few places where Pig has imposed a limitation on PigPen.
We did evaluate other languages before deciding to build PigPen. The first requirement was that it was an actual programming language, not just a scripting language with UDFs. We briefly evaluated Scalding, which looks very promising, but our team primarily uses Clojure. It could be said that PigPen is to Clojure what Scalding is to Scala. Cascalog is usually the go-to language for map-reduce in Clojure, but from past experiences, datalog has proven less than useful for everyday tasks. There’s a complicated new syntax and concepts to learn, aligning variable names to do implicit joins is not always ideal, misplaced ordering of operations can often cause big performance problems, datalog will flatten data structures (which can be wasteful), and composition can be a mind bender.
We also evaluated a few options to use as a host language for PigPen. It would be possible to build a similar abstraction on top of Hive, but schematizing every intermediate product doesn’t fit well with the Clojure ideology. Also, Hive is similar to SQL, making translation from a functional language more difficult. There’s an impedance mismatch between relational models like SQL and Hive and functional models like Clojure or Pig. In the end, the most straightforward solution was to write an abstraction over Pig.
Future Work
Currently you can reference in-scope local variables within code that is executed remotely, as shown above. One limitation to this feature is that the value must be serializable. This has the downside of not being able to utilize compiled functions - you can’t get back the source code that created them in the first place. This means that the following won’t work:
(defn foo [x] ...)(pig/map foo)In this situation, the compiler will inform you that it doesn’t recognize foo. We’re playing around with different methods for requiring code remotely, but there are some nuances to this problem. Blindly loading the code that was present when the script was generated is an easy option, but it might not be ideal if that code accidentally runs something that was only intended to run locally. Another option would be for the user to explicitly specify what to load remotely, but this poses challenges as well, such as an elegant syntax to express what should be loaded. Everything we’ve tried so far is a little clunky and jar hell with Hadoop doesn’t make it any easier. That said, any code that’s available can be loaded from within any user function. If you upload your uberjar, you can then use a require statement to load other arbitrary code.
So far, performance in PigPen doesn’t seem to be an issue. Long term, if performance issues crop up, it will be relatively easy to migrate to running PigPen directly on Hadoop (or similar) without changing the abstraction. One of the key performance features we still have yet to build is incremental aggregation. Pig refers to this as algebraic operators (also referenced by Rich Hickey here as combining functions). These are operations that can compute partial intermediate products over aggregations. For example, say we want to take the average of a LOT of numbers - so many that we need map-reduce. The naive approach would be to move all of the numbers to one machine and compute the average. A better approach would be to partition the numbers, compute the sum and count of each of these smaller sets, and then use those intermediate products to compute the final average. The challenge for PigPen will be to consume many of these operations within a single function. For example, say we have a set of numbers and we want to compute the count, sum, and average. Ideally, we would want to define each of these computations independently as algebraic operations and then use them together over the same set of data, having PigPen do the work of maintaining a set of intermediate products. Effectively, we need to be able to compose and combine these operations while retaining their efficiency.
We use a number of other Pig & Hadoop tools at Netflix that will pair nicely with PigPen. We have some prototypes for integration with Genie, which adds a pig/submit operator. There’s also a loader for Aegisthus data in the works. And PigPen works with Lipstick as the resulting scripts are Pig scripts.
Conclusion
PigPen has been a lot of fun to build and we hope it’s even more fun to use. For more information on getting started with PigPen and some tutorials, check out the tutorial, or to contribute, take a look at our Github page: https://github.com/Netflix/PigPen
There are three distinct audiences for PigPen, so we wrote three different tutorials:
- Those coming from the Clojure community who want to do map-reduce: PigPen for Clojure users
- Those coming from the Pig community who want to use Clojure: PigPen for Pig users
- And a general tutorial for anybody wanting to learn it all: PigPen Tutorial
If you know both Clojure and Pig, you’ll probably find all of the tutorials interesting.
The full API documentation is located here
And if you love big data, check out our jobs.
from:http://techblog.netflix.com/search/label/Map-Reduce
- PigPen:用Clojure写MapReduce Introducing PigPen: Map-Reduce for Clojure
- clojure实战--schema for clojure
- clojure
- Clojure
- clojure
- clojure
- Clojure
- clojure中的map析构
- clojure 宏 配合 reduce 例子
- clojure实战——schema for clojure
- little crawler for clojure
- Clojure语言十一:map函数
- clojure读取文件->转换Map
- eclipse插件之pigpen安装与配置
- Clojure语言九:for循环
- HornetQ Topic/Queue for Clojure
- Cursive - IntelliJ plugin for clojure
- Clojure入门教程: Clojure – Functional Programming for the JVM中文版
- Java邮件发送
- js开发的45个人技巧
- 【算法】蛇形矩阵
- cocos开发环境配置
- 30.C语言结构体对齐访问
- PigPen:用Clojure写MapReduce Introducing PigPen: Map-Reduce for Clojure
- HDU 4292 最大流
- Android通过来电号码识别姓名。
- Ubuntu14 Server挂载光驱
- Hacker--基本术语
- C++ inserter
- 基于OpenCV 的美颜相机推送直播流
- Linux下抓包工具tcpdump使用
- redis 数据结构命令


