逻辑回归(代价函数,梯度下降) logistic regression--cost function and gradient descent
来源:互联网 发布:游戏优化怎么做 编辑:程序博客网 时间:2024/05/17 09:07
逻辑回归(代价函数,梯度下降) logistic regression--cost function and gradient descent
对于有m个样本的训练集 ,
, 。在上篇介绍决策边界的时候已经介绍过了在logistic回归中的假设函数为:
。在上篇介绍决策边界的时候已经介绍过了在logistic回归中的假设函数为: 。因此我们定义logistic回归的代价函数(cost function)为:
。因此我们定义logistic回归的代价函数(cost function)为: , 下面来解释下这两个公式,先来看y=1时,
, 下面来解释下这两个公式,先来看y=1时, ,画出
,画出 的函数图像为:
的函数图像为:

从图中可以看出,y=1,当预测值 时,可以看出代价函数cost的值为0,这正是我们希望的。如果预测值
时,可以看出代价函数cost的值为0,这正是我们希望的。如果预测值 即
即 ,意思是预测y=1的概率为0,但是事实上y=1,因此代价函数
,意思是预测y=1的概率为0,但是事实上y=1,因此代价函数 相当于给学习算法一个惩罚。
相当于给学习算法一个惩罚。
同理我们也可以画出当y=0时,函数 的图像:
的图像:

同样也能看出上面y=1时介绍的那些信息,我就不再说了。
对于上面的代价函数, ,其中 可以写成更加简洁的形式:
,其中 可以写成更加简洁的形式: ,这个公式更加简洁,可以看出,当y=1时,公式变为,当y=0时,公式变为 与上面的公式完全等价。因此代价函数为:
,这个公式更加简洁,可以看出,当y=1时,公式变为,当y=0时,公式变为 与上面的公式完全等价。因此代价函数为:
为了求解使 最小的参数
最小的参数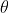 ,还是要用梯度下降(gradient descent),即
,还是要用梯度下降(gradient descent),即 ,
,
看来其和线性回归中的梯度下降函数形式一模一样,但其实是不一样的,因为在logistic回归中 。
为了让大家明白从公式 怎么推到公式
怎么推到公式 的,我把这个公式的求导过程写一下:
的,我把这个公式的求导过程写一下:

大家可以自己在纸上推推,对求导不熟悉的可以去补补高数上,微积分。
关于logistic回归里的代价函数和梯度下降就介绍到这。还有一些高级优化算法,如 conjugate gradient、BFGS和L-BFGS这些算法不需要手动选择学习率 ,而且收敛的速度要远快于梯度下降。但是这些算法太过复杂,不太容易搞明白。
,而且收敛的速度要远快于梯度下降。但是这些算法太过复杂,不太容易搞明白。
注意:再强调一下,写博客不容易,尤其编辑公式很花费时间。转载或者引用请注明原文作者和链接,尊重原创。最近发现有人公然复制博客当成自己的原创,这种行为不值得尊重。
1 0
- 逻辑回归(代价函数,梯度下降) logistic regression--cost function and gradient descent
- 线性回归、梯度下降、逻辑回归(Linear Regression、Gradient Descent、Logistic Regression)
- 回归(regression)、梯度下降(gradient descent)
- 回归(regression)、梯度下降(gradient descent)
- 回归(regression)、梯度下降(gradient descent)
- 回归(regression)、梯度下降(gradient descent)
- 回归(regression)、梯度下降(gradient descent)
- 回归(regression)、梯度下降(gradient descent)
- 回归(regression)、梯度下降(gradient descent)
- 回归(regression)、梯度下降(gradient descent)
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
- 机器学习(一)回归(regression)、梯度下降(gradient descent)
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
- 线性回归和梯度下降(Linear Regression and Gradient Descent)
- 线性回归与梯度下降(linear regression and gradient descent)
- 机器学习 线性回归(regression)、梯度下降(gradient descent)
- 机器学习中Lession1-回归(regression)、梯度下降(gradient descent)
- 解决C# FileUpload上传文件过大的时候出现的错误
- 【引用】 PB绝对有用的未公开函数
- 几个常见工具的使用
- 第八届河南省程序设计大赛-B.最大岛屿0000110011000000
- 逆向工程实战--Afkayas.1
- 逻辑回归(代价函数,梯度下降) logistic regression--cost function and gradient descent
- Lightoj-1356 Prime Independence(质因子分解&&二分图最大独立集)
- error:const char *类型的实参与LPCWSTR类型的形参不兼容
- android中的@{} @+id ?/attr
- POJ 2192 Zipper
- AlertDialog.Builder setCancelable用法
- Spring 属性注入的实现原理
- 在Android Studio中打开DDMS
- 使用系统图片选择页面


