Ring Buffer (circular Buffer)环形缓冲区
来源:互联网 发布:贝塔分布算法 编辑:程序博客网 时间:2024/05/22 11:49
1、环形缓冲区的实现原理
环形缓冲区通常有一个读指针和一个写指针。读指针指向环形缓冲区中可读的数据,写指针指向环形缓冲区中可写的缓冲区。通过移动读指针和写指针就可以实现缓冲区的数据读取和写入。在通常情况下,环形缓冲区的读用户仅仅会影响读指针,而写用户仅仅会影响写指针。如果仅仅有一个读用户和一个写用户,那么不需要添加互斥保护机制就可以保证数据的正确性。如果有多个读写用户访问环形缓冲区,那么必须添加互斥保护机制来确保多个用户互斥访问环形缓冲区。
图1、图2和图3是一个环形缓冲区的运行示意图。图1是环形缓冲区的初始状态,可以看到读指针和写指针都指向第一个缓冲区处;图2是向环形缓冲区中添加了一个数据后的情况,可以看到写指针已经移动到数据块2的位置,而读指针没有移动;图3是环形缓冲区进行了读取和添加后的状态,可以看到环形缓冲区中已经添加了两个数据,已经读取了一个数据。
2、实例:环形缓冲区的实现
环形缓冲区是数据通信程序中使用最为广泛的数据结构之一,下面的代码,实现了一个环形缓冲区:
/*ringbuf .c*/
#include
#include
#define NMAX 8
int iput = 0; /* 环形缓冲区的当前放入位置 */
int iget = 0; /* 缓冲区的当前取出位置 */
int n = 0; /* 环形缓冲区中的元素总数量 */
double buffer[NMAX];
/* 环形缓冲区的地址编号计算函数,如果到达唤醒缓冲区的尾部,将绕回到头部。
环形缓冲区的有效地址编号为:0到(NMAX-1)
*/
int addring (int i)
{
return (i+1) == NMAX ? 0 : i+1;
}
/* 从环形缓冲区中取一个元素 */
double get(void)
{
int pos;
if (n>0){
Pos = iget;
iget = addring(iget);
n--;
return buffer[pos];
}
else {
printf(“Buffer is empty\n”);
return 0.0;
}
/* 向环形缓冲区中放入一个元素*/
void put(double z)
{
if (n<nmax){< span="" style="word-wrap: break-word;">
buffer[iput]=z;
iput = addring(iput);
n++;
}
else
printf(“Buffer is full\n”);
}
int main{void)
{
chat opera[5];
double z;
do {
printf(“Please input p|g|e?”);
scanf(“%s”, &opera);
switch(tolower(opera[0])){
case ‘p’: /* put */
printf(“Please input a float number?”);
scanf(“%lf”, &z);
put(z);
break;
case ‘g’: /* get */
z = get();
printf(“%8.2f from Buffer\n”, z);
break;
case ‘e’:
printf(“End\n”);
break;
default:
printf(“%s - Operation command error! \n”, opera);
}/* end switch */
}while(opera[0] != ’e’);
return 0;
}
在CAN通信卡设备驱动程序中,为了增强CAN通信卡的通信能力、提高通信效率,根据CAN的特点,使用两级缓冲区结构,即直接面向CAN通信卡的收发缓 冲区和直接面向系统调用的接收帧缓冲区。 通讯中的收发缓冲区一般采用环形队列(或称为FIFO队列),使用环形的缓冲区可以使得读写并发执行,读进程和写进程可以采用“生产者和消费者”的模型来 访问缓冲区,从而方便了缓存的使用和管理。然而,环形缓冲区的执行效率并不高,每读一个字节之前,需要判断缓冲区是否为空,并且移动尾指针时需要进行“折行处理”(即当指针指到缓冲区内存的末尾时,需要新将其定向到缓冲区的首地址);每写一个字节之前,需要判断缓区是否为,并且移动尾指针时同样需要进行“ 折行处理”。程序大部分的执行过程都是在处理个别极端的情况。只有小部分在进行实际有效的操作。这就是软件工程中所谓的“8比2”关系。结合CAN通讯实际情况,在本设计中对环形队列进行了改进,可以较大地提高数据的收发效率。 由于CAN通信卡上接收和发送缓冲器每次只接收一帧CAN数据,而且根据CAN的通讯协议,CAN控制器的发送数据由1个字节的标识符、一个字节的RTR 和DLC位及8个字节的数据区组成,共10个字节;接收缓冲器与之类似,也有10个字节的寄存器。所以CAN控制器收的数据是短小的定长帧(数据可以不满 8字节)。 于是,采用度为10字节的数据块业分配内存比较方便,即每次需要内存缓冲区时,直接分配10个字节,由于这10个字节的地址是线性的,故不需要进行“折行”处理。更重要的是,在向缓冲区中写数据时,只需要判断一次是否有空闲块并获取其块首指针就可以了,从而减少了重复性的条件判断,大大提高了程序的执行效率;同样在从缓冲队列中读取数据时,也是一次读取10字节的数据块,同样减少了重复性的条件判断。 在CAN卡驱动程序中采用如下所示的称为“Block_Ring_t”的数据结构作为收发数据的缓冲区:
typedef struct {
long signature;
unsigned char *head_p;
unsigned char *tail_p;
unsigned char *begin_p;
unsigned char *end_p;
unsigned char buffer [BLOCK_RING_BUFFER_SIZE];
int usedbytes;
}Block_Ring_t;
该数据结构在通用的环形队列上增加了一个数据成员usedbytes,它表示当前缓冲区中有多少字节的空间被占用了。使用usedbytes,可以比较方 便地进行缓冲区满或空的判断。当usedbytes=0时,缓冲区空;当usedbytes=BLOCK_RING_BUFFER_SIZE时,缓冲区 满。 本驱动程序除了收发缓冲区外,还有一个接收帧缓冲区,接收帧队列负责管理经Hilon A协议解包后得到的数据帧。由于有可能要同接收多个数据帧,而根据CAN总线遥通信协议,高优先级的报文将抢占总线,则有可能在接收一个低优先级且被分为 好几段发送的数据帧时,被一个优先级高的数据帧打断。这样会出现同时接收到多个数据帧中的数据包,因而需要有个接收队列对同时接收的数据帧进行管理。 当有新的数据包到来时,应根据addr(通讯地址),mode(通讯方式),index(数据包的序号)来判断是否是新的数据帧。如果是,则开辟新的 frame_node;否则如果已有相应的帧节点存地,则将数据附加到该帧的末尾;在插入数据的同时,应该检查接收包的序号是否正确,如不正确将丢弃这包 数据。 每次建立新的frame_node时,需要向frame_queue申请内存空间;当frame_queue已满时,释放掉队首的节点(最早接收的但未完成的帧)并返回该节点的指针。 当系统调用读取了接收帧后,释放该节点空间,使设备驱动程序可以重新使用该节点。
形缓冲区:环形缓冲队列学习
来源: 发布时间:星期四, 2008年9月25日 浏览:117次 评论:0
项目中需要线程之间共享一个缓冲FIFO队列,一个线程往队列中添数据,另一个线程取数据(经典的生产者-消费者问题)。开始考虑用STL的vector 容器, 但不需要随机访问,频繁的删除最前的元素引起内存移动,降低了效率。使用LinkList做队列的话,也需要频繁分配和释放结点内存。于是自己实现一个有 限大小的FIFO队列,直接采用数组进行环形读取。
队列的读写需要在外部进程线程同步(另外写了一个RWGuard类, 见另一文)
到项目的针对性简单性,实现了一个简单的环形缓冲队列,比STL的vector简单
PS: 第一次使用模板,原来类模板的定义要放在.h 文件中, 不然会出现连接错误。
template
class CShareQueue
{
public:
CShareQueue();
CShareQueue(unsigned int bufsize);
virtual ~CShareQueue();
_Type pop_front();
bool push_back( _Type item);
//返回容量
unsigned int capacity() { //warning:需要外部数据一致性
return m_capacity;
}
//返回当前个数
unsigned int size() { //warning:需要外部数据一致性
return m_size;
}
//是否满//warning: 需要外部控制数据一致性
bool IsFull() {
return (m_size >= m_capacity);
}
bool IsEmpty() {
return (m_size == 0);
}
protected:
UINT m_head;
UINT m_tail;
UINT m_size;
UINT m_capacity;
_Type *pBuf;
};
template
CShareQueue<_Type>::CShareQueue() : m_head(0), m_tail(0), m_size(0)
{
pBuf = new _Type[512];//默认512
m_capacity = 512;
}
template
CShareQueue<_Type>::CShareQueue(unsigned int bufsize) : m_head(0), m_tail(0)
{
if( bufsize > 512 || bufsize < 1)
{
pBuf = new _Type[512];
m_capacity = 512;
}
else
{
pBuf = new _Type[bufsize];
m_capacity = bufsize;
}
}
template
CShareQueue<_Type>::~CShareQueue()
{
delete[] pBuf;
pBuf = NULL;
m_head = m_tail = m_size = m_capacity = 0;
}
//前面弹出一个元素
template
_Type CShareQueue<_Type>::pop_front()
{
if( IsEmpty() )
{
return NULL;
}
_Type itemtmp;
itemtmp = pBuf[m_head];
m_head = (m_head + 1) % m_capacity;
--m_size;
return itemtmp;
}
//从尾部加入队列
template
bool CShareQueue<_Type>::push_back( _Type item)
{
if ( IsFull() )
{
return FALSE;
}
pBuf[m_tail] = item;
m_tail = (m_tail + 1) % m_capacity;
++m_size;
return TRUE;
}
#endif // !defined(_DALY_CSHAREQUEUE_H_)
循环缓冲区在一些竞争问题上提供了一种免锁的机制,免锁的前提是,生产者和消费
都只有一个的情况下,否则也要加锁。下面就内核中提取出来,而经过修改后的fifo进
行简要的分析。
先看其只要数据结构:
struct my_fifo {
unsignedchar *buffer;/* the buffer holding the data*/
unsignedint size;/* the size of the allocated buffer*/
unsignedint in;/* data is added at offset (in % size)*/
unsignedint out;/* data is extracted from off. (out % size)*/
}
也不用多说,一看就明白。size, in, out 都设成无符号型的,因为都不存在负值的情型。
/*form kernel/kfifo.c
*/
#include <stdio.h>
#include <stdlib.h>
#include <fifo.h>
#define min(a,b) ((a) < (b) ? (a):(b))
/*
my_fifo_init
*/
struct my_fifo *my_fifo_init(unsignedchar *buffer,unsigned int size){
struct my_fifo *fifo;
fifo = malloc(sizeof(struct my_fifo));
if (!fifo)
returnNULL;
fifo->buffer = buffer;
fifo->size = size;
fifo->in = fifo->out = 0;
return fifo;
}
这个初始化fifo结构的函数一般也不会在应用层里进行调用,而是被下面的fifo_alloc
调用。依我的观点来看,这两个函数合成一个函数会更加的清晰,但是这一情况只针对
buffer是系统开辟的空间,如果buffer的空间是由其它的函数来提供,就只能用上面的这个函数。
/*
my_fifo_alloc
*/
struct my_fifo *my_fifo_alloc(unsignedint size)
{
unsignedchar *buffer;
struct my_fifo *ret;
/*
* round up to the next power of 2, since our 'let the indices
* wrap' tachnique works only in this case.
*/
buffer = malloc(size);
if (!buffer)
returnNULL;
ret = my_fifo_init(buffer, size);
if (ret ==NULL)
free(buffer);
return ret;
}
/*
* my_fifo_free
*/
void my_fifo_free(struct my_fifo *fifo)
{
free(fifo->buffer);
free(fifo);
}
这两个函数也不作过多的分析,都很清晰。
/*
my_fifo_put()
*/
unsignedint my_fifo_put(struct my_fifo *fifo,
unsignedchar *buffer, unsigned int len)
{
unsignedint l;
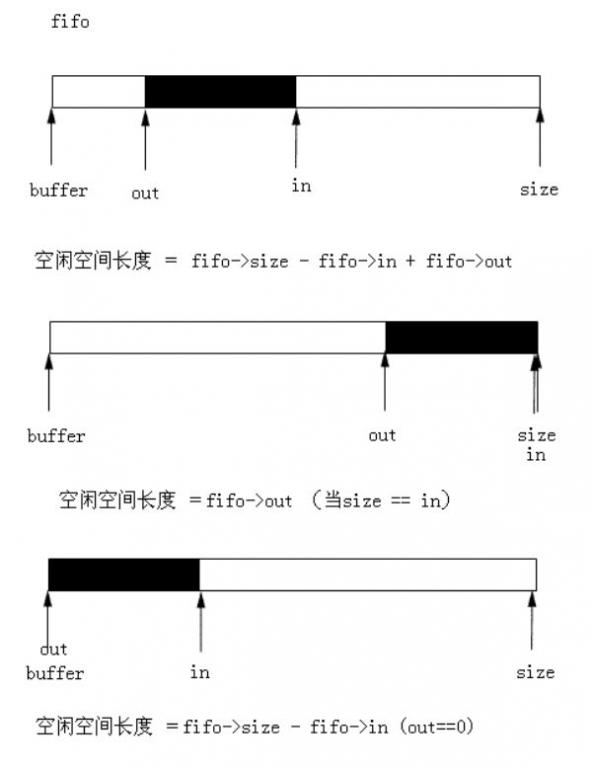
len = min(len, fifo->size - fifo->in + fifo->out);/*可能是缓冲区的空闲长度或者要写长度*/
/* first put the data starting from fifo->in to buffer end*/
l = min(len, fifo->size - (fifo->in & (fifo->size -1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size -1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer*/
memcpy(fifo->buffer, buffer + l, len - l);
fifo->in += len;
return len;
}
/*
my_fifo_get
*/
unsignedint my_fifo_get(struct my_fifo *fifo,
unsignedchar *buffer, unsigned int len)
{
unsignedint l;
len = min(len, fifo->in - fifo->out); /*可读数据*/
/* first get the data from fifo->out until the end of the buffer*/
l = min(len, fifo->size - (fifo->out & (fifo->size -1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size -1)), l);
/* then get the rest (if any) from the beginning of the buffer*/
memcpy(buffer + l, fifo->buffer, len - l);
fifo->out += len;
return len;
}
这两个读写结构才是循环缓冲区的重点。在fifo结构中,size是缓冲区的大小,是由用
户自己定义的,但是在这个设计当中要求它的大小必须是2的幂次。
当in==out时,表明缓冲区为空的,当(in-out)==size 时,说明缓冲区已满。
我们看下具体实现,在86行处如果size-in+out ==0,也即获得的len值会0,而没有数
据写入到缓冲区中。所以在设计缓冲区的大小的时候要恰当,读出的速度要比定入的速
度要快,否则缓冲区满了会使数据丢失,可以通过成功写入的反回值来做判断尝试再次
写入.
另一种情况则是缓冲区有足够的空间给要写入的数据,但是试想一下,如果空闲的空间
在缓冲的首尾两次,这又是如何实现呢?这部分代码实现得非常巧妙。
我们看fifo->in &(fifo->size-1) 这个表达式是什么意思呢?我们知道size是2的幂次
项,那么它减1即表示其值的二进制所有位都为1,与in相与的最终结果是in%size,比
size要小,所以看in及out的值都是不断地增加,但再相与操作后,它们即是以size为
周期的一个循环。89行就是比较要写入的数据应该是多少,如果缓冲区后面的还有足够
的空间可写,那么把全部的值写到后面,否则写满后面,再写到前面去93行。
读数据也可以作类似的分析,108行表示请求的数据要比缓冲区的数据要大时,只
读取缓冲区中可用的数据。
staticinline void my_fifo_reset(struct my_fifo *fifo)
{
fifo->in = fifo->out = 0;
}
staticinline unsigned int my_fifo_len(struct my_fifo *fifo)
return fifo->in - fifo->out;
}
在头文件里还有缓冲区置位及返回缓冲区中数据大小两个函数,很简单,不必解释
详见:http://home.eeworld.com.cn/my/space-uid-346593-blogid-239256.html
- Ring Buffer (circular Buffer)环形缓冲区简介
- Ring Buffer (circular Buffer)环形缓冲区
- Ring Buffer (circular Buffer)环形缓冲区简介
- Ring Buffer (circular Buffer)环形缓冲区简介(C++版本)
- 环形缓冲区 -- circular buffer
- 环形缓冲器 circular buffer, ring buffer
- linux网络编程--Circular Buffer(Ring Buffer) 环形缓冲区的设计与实现
- 环形缓冲区(ring buffer),环形队列(ring queue) 原理
- 环形缓冲区(ring buffer),环形队列(ring queue) 原理
- 环形缓冲区-boost circular buffer & 读写锁(shared_mutex)
- (转载)环形缓冲区的实现原理(ring buffer)
- 环形缓冲区的实现原理(ring buffer)
- 环形缓冲区的实现原理(ring buffer)
- 环形缓冲区的实现原理(ring buffer)
- (转载)环形缓冲区的实现原理(ring buffer) .
- 环形缓冲区的实现原理(ring buffer)
- 环形缓冲区的实现原理(ring buffer)
- 环形缓冲区的实现原理(ring buffer)
- 文件
- 操作系统之——常用端口列表
- CString转换为char*,在多字节与宽字节两种情况下
- 从数据库(wm_concat函数)接收值变成oracle.sql.CLOB@xxxxx类型的处理方法
- linux图形界面命令行切换
- Ring Buffer (circular Buffer)环形缓冲区
- java List 排序 Collections.sort() 对 List 排序
- Socket UDP通讯
- 教你透彻了解红黑树
- Ubuntu root 密码
- 对美国某核武器研究项目站点的一次渗透测试 2013-09-19 12:59
- c++中重载,重写,重定义
- Java并发编程:线程池的使用
- 出现( linker command failed with exit code 1)错误总结


