最大似然估计(like-hood)
来源:互联网 发布:mac qq截图失效 编辑:程序博客网 时间:2024/05/29 17:37
原文地址:http://blog.csdn.net/sunanger_wang/article/details/8852770
原文地址:http://blog.csdn.net/yanqingan/article/details/6125812
给定一个概率分布 ,假定其概率密度函数(连续分布)或概率聚集函数(离散分布)为
,假定其概率密度函数(连续分布)或概率聚集函数(离散分布)为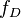 ,以及一个分布参数
,以及一个分布参数 ,我们可以从这个分布中抽出一个具有
,我们可以从这个分布中抽出一个具有 个值的采样
个值的采样 ,通过利用,我们就能计算出其概率:
,通过利用,我们就能计算出其概率:
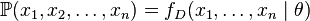
但是,我们可能不知道的值,尽管我们知道这些采样数据来自于分布。那么我们如何才能估计出呢?一个自然的想法是从这个分布中抽出一个具有个值的采样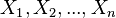 ,然后用这些采样数据来估计.
,然后用这些采样数据来估计.
一旦我们获得,我们就能从中找到一个关于的估计。最大似然估计会寻找关于的最可能的值(即,在所有可能的取值中,寻找一个值使这个采样的“可能性”最大化)。这种方法正好同一些其他的估计方法不同,如的非偏估计,非偏估计未必会输出一个最可能的值,而是会输出一个既不高估也不低估的值。
要在数学上实现最大似然估计法,我们首先要定义似然函数:
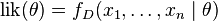
并且在的所有取值上,使这个函数最大化。这个使可能性最大的 值即被称为的最大似然估计。
值即被称为的最大似然估计。
注意
- 这里的似然函数是指
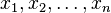 不变时,关于的一个函数。
不变时,关于的一个函数。 - 最大似然估计函数不一定是惟一的,甚至不一定存在。
例子
离散分布,离散有限参数空间
考虑一个抛硬币的例子。假设这个硬币正面跟反面轻重不同。我们把这个硬币抛80次(即,我们获取一个采样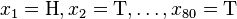 并把正面的次数记下来,正面记为H,反面记为T)。并把抛出一个正面的概率记为
并把正面的次数记下来,正面记为H,反面记为T)。并把抛出一个正面的概率记为 ,抛出一个反面的概率记为
,抛出一个反面的概率记为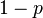 (因此,这里的即相当于上边的)。假设我们抛出了49个正面,31个反面,即49次H,31次T。假设这个硬币是我们从一个装了三个硬币的盒子里头取出的。这三个硬币抛出正面的概率分别为
(因此,这里的即相当于上边的)。假设我们抛出了49个正面,31个反面,即49次H,31次T。假设这个硬币是我们从一个装了三个硬币的盒子里头取出的。这三个硬币抛出正面的概率分别为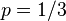 ,
,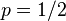 ,
, .这些硬币没有标记,所以我们无法知道哪个是哪个。使用最大似然估计,通过这些试验数据(即采样数据),我们可以计算出哪个硬币的可能性最大。这个似然函数取以下三个值中的一个:
.这些硬币没有标记,所以我们无法知道哪个是哪个。使用最大似然估计,通过这些试验数据(即采样数据),我们可以计算出哪个硬币的可能性最大。这个似然函数取以下三个值中的一个:
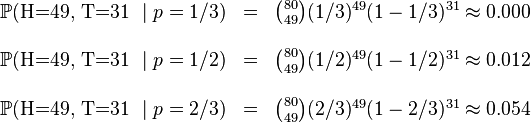
我们可以看到当 时,似然函数取得最大值。这就是的最大似然估计。
时,似然函数取得最大值。这就是的最大似然估计。
离散分布,连续参数空间
现在假设例子1中的盒子中有无数个硬币,对于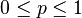 中的任何一个, 都有一个抛出正面概率为的硬币对应,我们来求其似然函数的最大值:
中的任何一个, 都有一个抛出正面概率为的硬币对应,我们来求其似然函数的最大值:
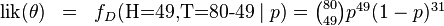
其中. 我们可以使用微分法来求最值。方程两边同时对取微分,并使其为零。
![\begin{matrix}0 & = & \frac{d}{dp} \left( \binom{80}{49} p^{49}(1-p)^{31} \right) \\ & & \\ & \propto & 49p^{48}(1-p)^{31} - 31p^{49}(1-p)^{30} \\ & & \\ & = & p^{48}(1-p)^{30}\left[ 49(1-p) - 31p \right] \\\end{matrix}](http://upload.wikimedia.org/math/f/4/3/f43c984e21445732edf403445fe32ea9.png)

其解为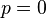 ,
,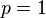 ,以及
,以及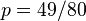 .使可能性最大的解显然是(因为和这两个解会使可能性为零)。因此我们说最大似然估计值为
.使可能性最大的解显然是(因为和这两个解会使可能性为零)。因此我们说最大似然估计值为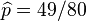 .
.
这个结果很容易一般化。只需要用一个字母 代替49用以表达伯努利试验中的被观察数据(即样本)的“成功”次数,用另一个字母代表伯努利试验的次数即可。使用完全同样的方法即可以得到最大似然估计值:
代替49用以表达伯努利试验中的被观察数据(即样本)的“成功”次数,用另一个字母代表伯努利试验的次数即可。使用完全同样的方法即可以得到最大似然估计值:
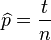
对于任何成功次数为,试验总数为的伯努利试验。
连续分布,连续参数空间
最常见的连续概率分布是正态分布,其概率密度函数如下:
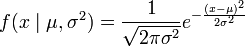
现在有个正态随机变量的采样点,要求的是一个这样的正态分布,这些采样点分布到这个正态分布可能性最大(也就是概率密度积最大,每个点更靠近中心点),其个正态随机变量的采样的对应密度函数(假设其独立并服从同一分布)为:
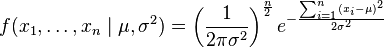
或:
 ,
,
这个分布有两个参数: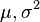 .有人可能会担心两个参数与上边的讨论的例子不同,上边的例子都只是在一个参数上对可能性进行最大化。实际上,在两个参数上的求最大值的方法也差不多:只需要分别把可能性
.有人可能会担心两个参数与上边的讨论的例子不同,上边的例子都只是在一个参数上对可能性进行最大化。实际上,在两个参数上的求最大值的方法也差不多:只需要分别把可能性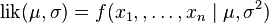 在两个参数上最大化即可。当然这比一个参数麻烦一些,但是一点也不复杂。使用上边例子同样的符号,我们有
在两个参数上最大化即可。当然这比一个参数麻烦一些,但是一点也不复杂。使用上边例子同样的符号,我们有 .
.
最大化一个似然函数同最大化它的自然对数是等价的。因为自然对数log是一个连续且在似然函数的值域内严格递增的上凸函数。[注意:可能性函数(似然函数)的自然对数跟信息熵以及Fisher信息联系紧密。]求对数通常能够一定程度上简化运算,比如在这个例子中可以看到:
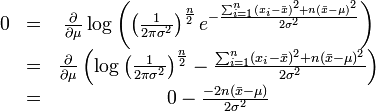
这个方程的解是 .这的确是这个函数的最大值,因为它是
.这的确是这个函数的最大值,因为它是 里头惟一的一阶导数等于零的点并且二阶导数严格小于零。
里头惟一的一阶导数等于零的点并且二阶导数严格小于零。
同理,我们对 求导,并使其为零。
求导,并使其为零。
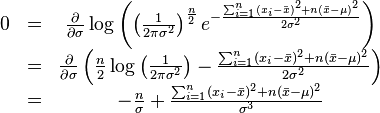
这个方程的解是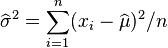 .
.
因此,其关于的最大似然估计为:
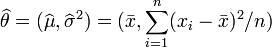 .
.
性质
泛函不变性(Functional invariance)
如果是的一个最大似然估计,那么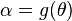 的最大似然估计是
的最大似然估计是 .函数g无需是一个一一映射。请参见George Casella与Roger L. Berger所著的Statistical Inference定理Theorem 7.2.10的证明。(中国大陆出版的大部分教材上也可以找到这个证明。)
.函数g无需是一个一一映射。请参见George Casella与Roger L. Berger所著的Statistical Inference定理Theorem 7.2.10的证明。(中国大陆出版的大部分教材上也可以找到这个证明。)
渐近线行为
最大似然估计函数在采样样本总数趋于无穷的时候达到最小方差(其证明可见于Cramer-Rao lower bound)。当最大似然估计非偏时,等价的,在极限的情况下我们可以称其有最小的均方差。 对于独立的观察来说,最大似然估计函数经常趋于正态分布。
偏差
最大似然估计的偏差是非常重要的。考虑这样一个例子,标有1到n的n张票放在一个盒子中。从盒子中随机抽取票。如果n是未知的话,那么n的最大似然估计值就是抽出的票上标有的n,尽管其期望值的只有 .为了估计出最高的n值,我们能确定的只能是n值不小于抽出来的票上的值。
.为了估计出最高的n值,我们能确定的只能是n值不小于抽出来的票上的值。
注意:
最大似然估计是个概率学的问题,其作用对象是一次采样的数据(包含了很多特征信息点,知道其满足什么分布,如高斯分布,但参数未知,从而转换为一个参数估计的问题),最大似然估计的作用是,利用一次采样的数据(不完整的数据,以抛硬币的例子来说明最贴切),来估计完整数据的真实分布,但该估计是最大可能的估计,而不是无偏估计。
1. 作用
在已知试验结果(即是样本)的情况下,用来估计满足这些样本分布的参数,把可能性最大的那个参数![]() 作为真实
作为真实![]() 的参数估计。
的参数估计。
2. 离散型
设![]() 为离散型随机变量,
为离散型随机变量,![]() 为多维参数向量,如果随机变量
为多维参数向量,如果随机变量![]() 相互独立且概率计算式为P{
相互独立且概率计算式为P{![]() ,则可得概率函数为P{
,则可得概率函数为P{![]() }=
}=![]() ,在
,在![]() 固定时,上式表示
固定时,上式表示![]() 的概率;当
的概率;当![]() 已知的时候,它又变成
已知的时候,它又变成![]() 的函数,可以把它记为
的函数,可以把它记为![]() ,称此函数为似然函数。似然函数值的大小意味着该样本值出现的可能性的大小,既然已经得到了样本值
,称此函数为似然函数。似然函数值的大小意味着该样本值出现的可能性的大小,既然已经得到了样本值![]() ,那么它出现的可能性应该是较大的,即似然函数的值也应该是比较大的,因而最大似然估计就是选择使
,那么它出现的可能性应该是较大的,即似然函数的值也应该是比较大的,因而最大似然估计就是选择使![]() 达到最大值的那个
达到最大值的那个![]() 作为真实
作为真实![]() 的估计。
的估计。
3. 连续型
设![]() 为连续型随机变量,其概率密度函数为
为连续型随机变量,其概率密度函数为![]() ,
,![]() 为从该总体中抽出的样本,同样的如果
为从该总体中抽出的样本,同样的如果![]() 相互独立且同分布,于是样本的联合概率密度为
相互独立且同分布,于是样本的联合概率密度为![]() 。大致过程同离散型一样。
。大致过程同离散型一样。
4. 关于概率密度(PDF)
我们来考虑个简单的情况(m=k=1),即是参数和样本都为1的情况。假设进行一个实验,实验次数定为10次,每次实验成功率为0.2,那么不成功的概率为0.8,用y来表示成功的次数。由于前后的实验是相互独立的,所以可以计算得到成功的次数的概率密度为:
![]() =
=![]() 其中y
其中y![]()
由于y的取值范围已定,而且![]() 也为已知,所以图1显示了y取不同值时的概率分布情况,而图2显示了当
也为已知,所以图1显示了y取不同值时的概率分布情况,而图2显示了当![]() 时的y值概率情况。
时的y值概率情况。

图1 ![]() 时概率分布图
时概率分布图

图2 ![]() 时概率分布图
时概率分布图
那么![]() 在[0,1]之间变化而形成的概率密度函数的集合就形成了一个模型。
在[0,1]之间变化而形成的概率密度函数的集合就形成了一个模型。
5. 最大似然估计的求法
由上面的介绍可以知道,对于图1这种情况y=2是最有可能发生的事件。但是在现实中我们还会面临另外一种情况:我们已经知道了一系列的观察值和一个感兴趣的模型,现在需要找出是哪个PDF(具体来说参数![]() 为多少时)产生出来的这些观察值。要解决这个问题,就需要用到参数估计的方法,在最大似然估计法中,我们对调PDF中数据向量和参数向量的角色,于是可以得到似然函数的定义为:
为多少时)产生出来的这些观察值。要解决这个问题,就需要用到参数估计的方法,在最大似然估计法中,我们对调PDF中数据向量和参数向量的角色,于是可以得到似然函数的定义为:
![]()
该函数可以理解为,在给定了样本值的情况下,关于参数向量![]() 取值情况的函数。还是以上面的简单实验情况为例,若此时给定y为7,那么可以得到关于
取值情况的函数。还是以上面的简单实验情况为例,若此时给定y为7,那么可以得到关于![]() 的似然函数为:
的似然函数为:
![]()
继续回顾前面所讲,图1,2是在给定![]() 的情况下,样本向量y取值概率的分布情况;而图3是图1,2横纵坐标轴相交换而成,它所描述的似然函数图则指出在给定样本向量y的情况下,符合该取值样本分布的各种参数向量
的情况下,样本向量y取值概率的分布情况;而图3是图1,2横纵坐标轴相交换而成,它所描述的似然函数图则指出在给定样本向量y的情况下,符合该取值样本分布的各种参数向量![]() 的可能性。若
的可能性。若![]() 相比于
相比于![]() ,使得y=7出现的可能性要高,那么理所当然的
,使得y=7出现的可能性要高,那么理所当然的![]() 要比
要比![]() 更加接近于真正的估计参数。所以求
更加接近于真正的估计参数。所以求![]() 的极大似然估计就归结为求似然函数
的极大似然估计就归结为求似然函数![]() 的最大值点。那么
的最大值点。那么![]() 取何值时似然函数
取何值时似然函数![]() 最大,这就需要用到高等数学中求导的概念,如果是多维参数向量那么就是求偏导。
最大,这就需要用到高等数学中求导的概念,如果是多维参数向量那么就是求偏导。

图3 ![]() 的似然函数分布图
的似然函数分布图
主要注意的是多数情况下,直接对变量进行求导反而会使得计算式子更加的复杂,此时可以借用对数函数。由于对数函数是单调增函数,所以![]() 与
与![]() 具有相同的最大值点,而在许多情况下,求
具有相同的最大值点,而在许多情况下,求![]() 的最大值点比较简单。于是,我们将求
的最大值点比较简单。于是,我们将求![]() 的最大值点改为求
的最大值点改为求![]() 的最大值点。
的最大值点。
![]()
若该似然函数的导数存在,那么对![]() 关于参数向量的各个参数求导数(当前情况向量维数为1),并命其等于零,得到方程组:
关于参数向量的各个参数求导数(当前情况向量维数为1),并命其等于零,得到方程组:
![]()
可以求得![]() 时似然函数有极值,为了进一步判断该点位最大值而不是最小值,可以继续求二阶导来判断函数的凹凸性,如果
时似然函数有极值,为了进一步判断该点位最大值而不是最小值,可以继续求二阶导来判断函数的凹凸性,如果![]() 的二阶导为负数那么即是最大值,这里再不细说。
的二阶导为负数那么即是最大值,这里再不细说。
还要指出,若函数![]() 关于
关于![]() 的导数不存在,我们就无法得到似然方程组,这时就必须用其它的方法来求最大似然估计值,例如用有界函数的增减性去求
的导数不存在,我们就无法得到似然方程组,这时就必须用其它的方法来求最大似然估计值,例如用有界函数的增减性去求![]() 的最大值点
的最大值点
6. 总结
最大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。最大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
求最大似然函数估计值的一般步骤:
(1) 写出似然函数
(2) 对似然函数取对数,并整理
(3) 求导数
(4) 解似然方程
对于最大似然估计方法的应用,需要结合特定的环境,因为它需要你提供样本的已知模型进而来估算参数,例如在模式识别中,我们可以规定目标符合高斯模型。而且对于该算法,我理解为,“知道”和“能用”就行,没必要在程序设计时将该部分实现,因为在大多数程序中只会用到我最后推导出来的结果。个人建议,如有问题望有经验者指出。在文献[1]中讲解了本文的相关理论内容,在文献[2]附有3个推导例子。
7. 参考文献
[1]I.J. Myung. Tutorial on maximum likelihood estimation[J]. Journal of Mathematical Psychology, 2003, 90-100.
[2] http://edu6.teacher.com.cn/ttg006a/chap7/jiangjie/72.htm
该文通过Windows Live Writer上传,如有版面问题影响视觉效果请见谅,可以通过点击看清晰图!^0^
- 最大似然估计(like-hood)
- 最大似然估计(like-hood)
- 最大似然估计,最大后验估计,贝叶斯估计
- 最大似然估计、最大后验估计、贝叶斯估计
- 最大似然估计
- 最大似然估计
- 最大似然估计
- 最大似然估计
- 最大似然估计
- 最大似然估计
- 最大似然估计
- 最大似然估计
- 最大似然估计
- 最大似然估计
- 最大似然估计
- 最大似然估计
- 最大似然估计
- 最大似然估计
- SqlServer ETL 数据抽取工具SSIS之环境搭建
- AutoCompleteTextView:自动提示
- 1001. A+B Format (20)
- 零基础学习JAVA的初期笔记--自己的笔记
- Codeblocks快捷键的使用
- 最大似然估计(like-hood)
- 三言两语说shader(八)墙体透明
- 破解提高mac电脑分辨率2560 github地址 rootless Can't rename Operation not permitted, skipping file.
- Codeforces 630P Area of a Star
- UVa 10340 All in All
- 【剑指 offer】(二十九)—— 数组中出现次数超过一半的数字(及该数字出现的次数)
- 记票统计(华为oj)
- javaScript中的自定义类型和继承
- 排序


