【ATF】钱正平:大规模实时计算及其在阿里的应用与创新
来源:互联网 发布:linux 查看arp 编辑:程序博客网 时间:2024/06/14 16:43
2016 ATF阿里技术论坛于4月15日在清华大学举办,主旨是阐述阿里对世界创新做出的贡献。阿里巴巴集团技术委员会主席王坚,阿里巴巴集团首席技术官(CTO)张建锋(花名:行癫),阿里巴巴集团首席风险官(CRO)刘振飞(花名:振飞),蚂蚁金服首席技术官(CTO)程立(花名:鲁肃)以及来自阿里巴巴集团各部门多位技术大咖齐聚一堂,与莘莘学子分享阿里的技术梦想。

阿里云高级专家 钱正平正在分享《大规模实时计算及应用》
在下午的《云计算和大数据》分论坛中,阿里云高级专家钱正平(花名:布民) 深入分享了《大规模实时计算及应用》。他很沉浸,也很享受大规模实时计算的研究和实践,风趣的演讲让现场同学们不时会心一笑。
在他看来:虽然70-80年代分布式系统的理论已基本成熟,但使得这一技术能广泛应用并影响每个人的生活(如海量数据检索、低成本网络存储和机器学习以及人工智能等领域的突破),是来自近十几年的技术和实践创新。在演讲中,他始终想要传达的一个理念:用户需求是真正驱动分布式计算领域发展和变化的核心因素。“海量的数据,来自客户面临问题的真实需求,驱动了系统的发展。如果大家对分布式系统感兴趣,阿里云是目前全世界最好的做分布式系统的地方之一,如果在中国,可能把‘之一’去掉也是对的。”
以下为演讲速记整理:
事实上,要谈大规模实时计算发展,过去几年中有很明显的趋势:从10年前更加强调数据规模化到今天强调计算结果的实效性。也就是说,透过输出结果,来观察现实世界的物理活动和商业行为,时间发生点跟得到结果延迟已经非常短。比如很多在线服务预警监控,需要实时理解用户当前每个行为;广告投放,哪些是真实的人的点击,哪些是机器伪造的点击;在另一些场景中,如商业实时报表和流式数据处理,数据源源不断产生,如果不流式处理就很难有机会将数据存下来之后再计算。
举一个例子,去年在双11时,有个非常大的大屏,实时显示了整个双11零点过后情况,每一笔交易,从每个买家到每一个卖家,呈现的可视化交易都在上面呈现出来。可以看到35分钟的时候成交量达到200亿人民币。这背后是实时计算系统的支撑,每一笔交易发生之后,2.7秒时间我们就完成了数据的整合和最后展示。时间确实非常短,虽然有更低延时的场景,但大家要知道当时双11的规模是每秒有五千万事件,这是什么量级呢?举个对比例子,曾经公开数据中,Twitter最高峰值每秒十几万,双11的数据处理规模是非常大的。还有很多类似场景,背后都是复杂的数据流计算,并且要达到很小的延迟这是个很大的挑战。比如下面三点:
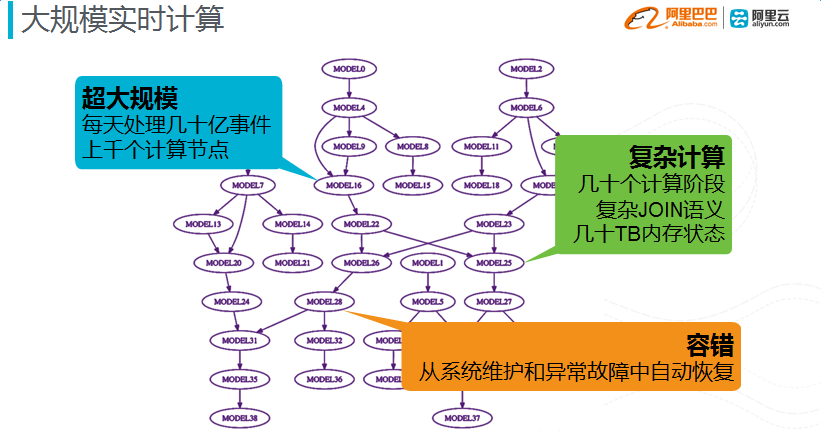
大规模实时计算
- 超大规模,每天处理几十亿事件,上千个计算节点;
- 复杂计算,几十个计算阶段,复杂JOIN语义,几十TB内存状态;
- 容错,从系统维护和异常故障中自动化恢复。
从系统架构的角度看,实时计算平台要处理各种各样的输入,比如移动设备、云服务器、事件存储、在线服务日志等;源事件经过实时计算平台产生输出事件推送到移动终端或监控、展示大屏等。我一直相信这一架构在未来也会扮演非常重要的角色。比如随着物联网时代的到来,很多在物理世界的信息采集点都会将信号传到云端,每一个物理世界的对象都会在云端有一个对应的虚拟对象。通过实时计算,虽然今天可能只是做聚合,但是今后这一计算将更为复杂,时时刻刻在云端监控虚拟世界的变化,挖掘有价值的信息,并将有意义的结果推回到物理世界。一个典型的应用就是连续的人脸识别。
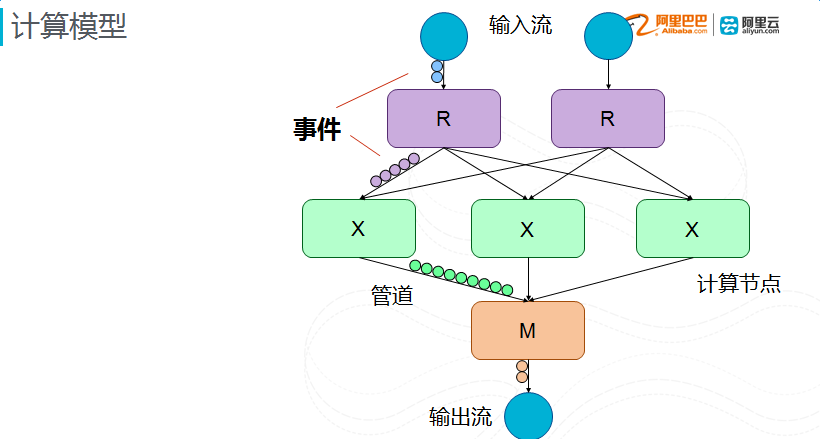
计算模型
架构背后是计算模型。实时计算可以表达成一个多阶段的数据流,每个阶段有多个结点,可以把一个计算分到很多机器上解决了扩展性的问题。第二个是事件流动,每个计算流水起来,中间尽量避免落盘,也是对批处理系统简单、自然的扩展。
这里面真正挑战在哪里?当有个结点发生故障的时候,可能有个事件会掉,一掉就会对下游产生影响,对输出产生影响。如果恢复结点就要重新算重新产生输出,这个时候依赖上游重新输入,就对上游有要求,上游没有保存输入,就会让你上游重新产生一个,最终一直滚到源头。内存中的计算状态也会丢失,需要重构才能继续。所以流计算和批处理最大的不同,就是有个错误的时候,上下游和计算状态的依赖使得处理非常复杂。
下面从研究角度简单概述近几年针对这一问题的解决方案和目前现状。最直观简单的做法就是所谓全局快照,虽然是流计算,但也是分布式计算,任何分布式计算都可以拿一个全局快照,意思是假设所有的计算那一刹那全部停止(包括数据流动),“照个相”把每条边上当前 正在进行的消息和结点计算状态,把这些都存下来,过一段时间又拍一个全局快照。但是全局快照问题是什么,当有个结点错误的时候相当于整个作业都错误了,因为那个节点错误要回滚到上一个照片,是所有的,都要保证跟它一致的状态,保证整个状态回滚。当然今天还有人在做(如Flink采用了类似的变种),不过回滚会带来性能开销,可能有些大了。
还有一个工作是,状态太困难,先把问题简化一下,假设整个流计算是没有状态的,大家可以想象每个结点的工作就是根据输入产生一些输出,但是结点里面没有维护这个状态。画一个例子就是在计算过程中间任何一个输出都对应于某个输入的,这样如果能够知道所有结点中输入输出的关系,如果有个错误发生,我知道某个事件掉了就能够通过这个依赖树里面把那个结点找到,从源头调一下就能恢复出来(如Storm)。但是这会有大量重复的计算。因为只要掉了一个,就需要恢复整个树。
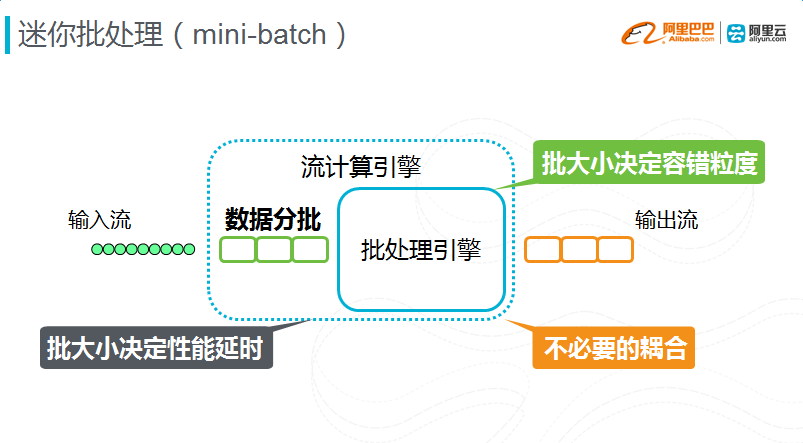
迷你批理器
所以后来有人(Spark Streaming)又想出另一个方法,迷你批处理做这个事情。因为依赖和状态很复杂,所以把输入数据切片,输入虽然是流,但是把它的分批,一段时间变成一批,对每一批用批处理系统,批处理引擎很成熟了。只要每对应一批批处理就产生一批输出,这是非常好的想法,是复用批处理里面的容错机制来检验实时计算里面的错误,如果这一批有任何故障就重算这是批处理的方式,这个想法什么问题?我们画两个框,外面从流计算系统衡量指标来看,分成片,片的大小决定性能延时,所以它是一个影响性能的参数;但是如果从里面被复用的批处理角度来讲,真正复用它的是基于容错的机制,每次有错误就一整批算,所以批大小决定容错粒度。我们希望把性能和容错分离开,这样一个系统里面把这两件事情,即性能和容错,混在一起是不必要的耦合,所以我们认为还有更好的设计。
最新的一个工作,从实时计算容错复杂性问题根源来看,如果一个问题的根源来自上下游依赖、对状态依赖,从系统设计原则讲非常简单的想法应该尽量试图解耦:所谓分而治之来管理这一复杂性。事实上,上下游依赖可以通过恰当的管道抽象来解耦。既然是上下游通过管道相互依赖,可以引入一个管道抽象满足以下属性:
- 唯一性:对于每一个序列号,存在唯一的事件值。
- 合理性:读操作成功,当且仅当之前存在一个针对相同序列号的写操作成功完成。
- 可靠性:如果一个写操作成功,后续到达相同序列号的读操作最终一定会成功。

管道及属性
最后一个可靠性实际上提供了“持久化”管道的“假象”。这样一来,每个结点就相互隔离了,我们只需要看单个结点来分析容错。对于单个结点,另一个重要概念是计算快照:单个节点连续运行,快照是指在当前所有状态,包括进度(输入输出序列号)和计算状态。利用快照,我们可以跟踪每个结点的执行,并且这样在多个快照中,可以从任一快照重启计算,从而实现回滚。我们要求流计算的每个结点满足这一可回滚的计算抽象,和前面的管道抽象类似。有了这两个抽象,流计算容错就变得很简单了,一个出错结点只要回滚到最近一个快照。
很重要的一点,抽象的好处是把系统属性(如容错)和实现特性分离。管道的实现可以有很多优化,如不一定要真的用持久化存储来实现管道,而可以把同步持久化操作通过内存缓存和异步写从执行的关键路径移除,从而提高性能;缓存的数据丢失时可以创建上游生产结点副本(回滚)来恢复。同样计算抽象也允许多种容错机制,如完全基于重算的快照(如TimeStream,Storm),基于(异步、增量)检查点(如我们的默认方案,Samza)甚至完全基于持久化存储实现(如MillWheel);很多相关系统其实都是这一抽象的特例化,我们甚至可以在同一个作业中混合使用不同的容错策略。
接下来讲阿里云实时计算实践,一个可用的实时计算平台除了容错一致性还需要能够支持很大规模的扩展性。从产品需求来看,有六个方面:一致性、扩展性、易用性、性能、服务化和成本优化。所以从研究到产品,尤其是面对真实的用户需求和场景化实践,阿里云做了很多工作,有很多有趣的创新尝试。
阿里云有一站式大数据平台MaxCompute。要想办法用现有的架构促进实时计算,而不是所有的东西从头开始做。从前面的介绍中,可以看出抽象的特点,比如管道和节点的抽象非常容易覆盖批处理的情况。我们确实这么做的,去扩展批处理系统处理实时情况下容错。这也允许我们很好复用和与现有基础架构集成,比如允许用户利用批处理做对比开发,流程序写完之后用批的形式验证每一阶段,验证完了切换到上线,这不仅是开发验证的切换还是资源的切换,因为管道抽象可以有单机版本实现,就可以调试几百个节点的任务。还有在线调试也很重要,一个流在线上出了问题,或者数据引起异常怎么在线分析问题,可以回到某个点重新算一算看一看发生了什么,这允许针对在线执行的作业克隆出一个结点做调试。
我们的产品叫StreamCompute,基于很多内部和外部的用户都在用的MaxCompute构建,除了实现前面提到的产品化方方面面的需求,还提供对多种输入输出源的支持、高层SQL语言、编译优化、资源调度和可视化开发环境。这一平台日均处理千亿级数据,平均CPU利用率30%以上(对比搜索引擎的20-30%集群利用率,已经非常高),支持上千个结点的大规模集群和成千上万的计算任务,是久经考验的通用实时计算平台。

大规模实时计算及其在阿里的应用与创新的实践经验
多年实践中,我们总结了许多经验,它们都来自真实的用户需求,例如:
- 审计:回溯到过去,查看历史执行结果。这也是用户提出的需求。“有一天用户跑过来问,昨天的记录。最初是不能理解的,但发现确实是用户需求”。
- 动态重构:流量资源变化,动态调整并行度或增加节点副本保障稳定性。
- 持续维护:系统维护升级,利用执行副本实现无间断过渡。
- 异常处理:节点进度监控,创建副本以解决异常节点。
- 数据特例:运行时补丁,规避问题数据。
我相信,实时计算正在加速创新,改变世界。我们要做的工作还有很多,实时计算场景和模型也会更加复杂,比如一个流进来需要一个图的模型做迭代计算,甚至增量机器学习等,这一领域大有可为。另一方面,大家在学校做研究,我觉得从研究角度,特别是系统领域,我们可能需要从方法上改变一下,真正深入理解真实的数据、真实的场景、去解决真实的问题,需要有数据和平台支撑,阿里有很好的机会。希望我们一起携手面对世界级的商业机会和系统挑战!谢谢大家!
云栖社区特别制作内容专题——《2016 ATF阿里技术论坛》,更多深度技术实践内容,不断更新,欢迎交流分享。
本文转载自云栖社区:https://yq.aliyun.com
本文转载自云栖社区:https://yq.aliyun.com
0 0
- 【ATF】钱正平:大规模实时计算及其在阿里的应用与创新
- 大规模图搜索和实时计算在阿里反作弊系统中的应用
- 大规模图搜索和实时计算在阿里反作弊系统中的应用
- 大规模图搜索和实时计算在阿里反作弊系统中的应用
- Swarm的进化和在阿里的大规模应用实践
- 基于GPU的大规模图计算系统与应用
- 基于GPU的大规模图计算系统与应用
- 【ATF】林伟:大数据计算平台的研究与实践
- 个性化实时计算系统及其应用探索
- 阿里移动11.11 | Weex 在双十一会场的大规模应用--备用
- 【PDF下载】金融技术峰会之大规模机器学习在蚂蚁+阿里的应用
- 数据引擎-阿里的ODPS大规模计算引擎
- Peacock:大规模主题模型及其在腾讯业务中的应用
- Peacock:大规模主题模型及其在腾讯业务中的应用
- Peacock:大规模主题模型及其在腾讯业务中的应用
- 基于AWS云服务的大数据与大规模计算的应用架构
- 云端大规模视频分析: MaxCompute在视觉计算中的应用
- 读redis在新浪的大规模应用
- JAVA EE 基础语法 及注释的重要性。
- Instruments检查视图卡顿和优化
- 20160416
- [LeetCode]70. Climbing Stairs
- ubuntu下使用VNC连接树莓派raspberry
- 【ATF】钱正平:大规模实时计算及其在阿里的应用与创新
- 一道程序的分析
- ubuntu14.04配opencv2.4.11
- EasyUI体验-分页多选,选项保留,以及历史记录相结合的保留
- String,StringBuffer,StringBuilder之间的区别
- 方便学习的一些经典网站
- SLAM学习
- 数据平台的简单使用
- Light OJ 1342 - Aladdin and the Magical Sticks (概率DP)


