第84讲:StreamingContext、DStream、Receiver深度剖析
来源:互联网 发布:淘宝服装时尚图片模板 编辑:程序博客网 时间:2024/04/30 17:02
有兴趣想学习国内整套Spark+Spark Streaming+Machine learning最顶级课程的,可加我qq 471186150。共享视频,性价比超高!
本课分成四部分讲解,第一部分对StreamingContext功能及源码剖析;第二部分对DStream功能及源码剖析;第三部分对Receiver功能及源码剖析;最后一部分将StreamingContext、DStream、Receiver结合起来分析其流程。
一、StreamingContext功能及源码剖析:
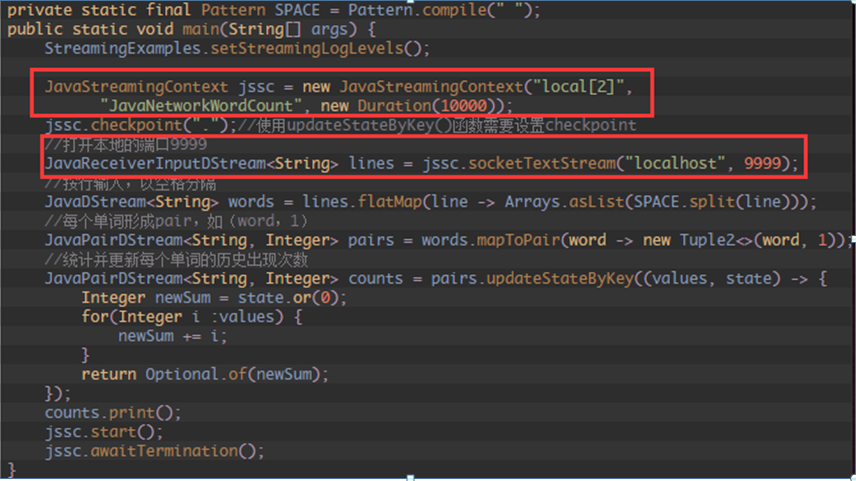
1、 通过Spark Streaming对象jssc,创建应用程序主入口,并连上Driver上的接收数据服务端口9999写入源数据:
2、 Spark Streaming的主要功能有:
- 主程序的入口;
- 提供了各种创建DStream的方法接收各种流入的数据源(例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等);
- 通过构造函数实例化Spark Streaming对象时,可以指定master URL、appName、或者传入SparkConf配置对象、或者已经创建的SparkContext对象;
- 将接收的数据流传入DStreams对象中;
- 通过Spark Streaming对象实例的start方法启动当前应用程序的流计算框架或通过stop方法结束当前应用程序的流计算框架;

二、DStream功能及源码剖析:
1、 DStream是RDD的模板,DStream是抽象的,RDD也是抽象
2、 DStream的具体实现子类如下图所示:

3、 以StreamingContext实例的socketTextSteam方法为例,其执行完的结果返回DStream对象实例,其源码调用过程如下图:

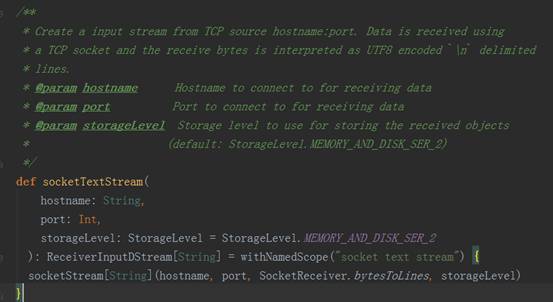
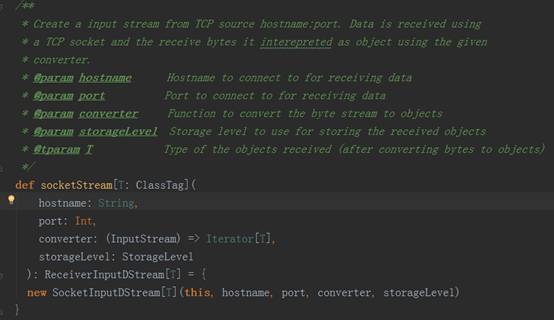
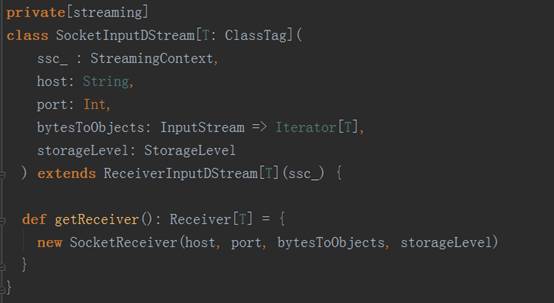
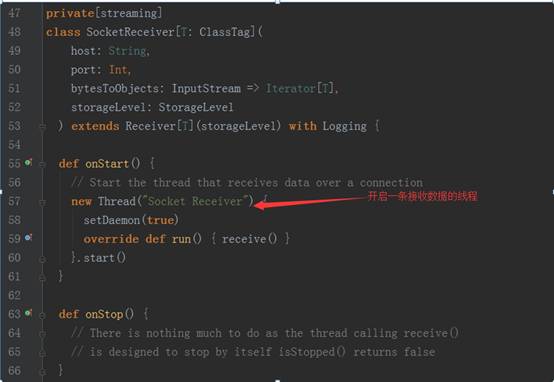
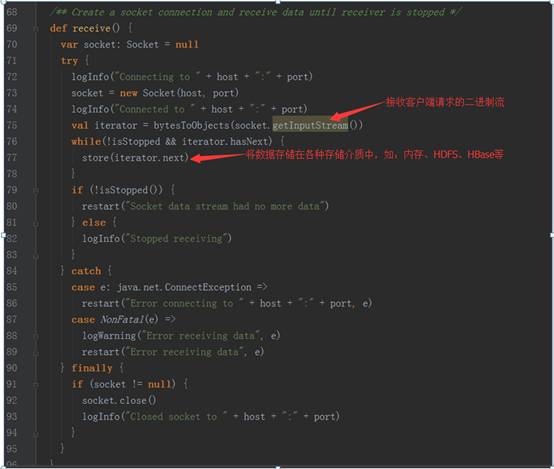
socket.getInputStream获取数据,while循环来存储储蓄数据(内存、磁盘)
三、Receiver功能及源码剖析:
1、Receiver代表数据的输入,接收外部输入的数据,如从Kafka上抓取数据;
2、Receiver运行在Worker节点上;
3、Receiver在Worker节点上抓取Kafka分布式消息框架上的数据时,具体实现类是KafkaReceiver;
4、Receiver是抽象类,其抓取数据的实现子类如下图所示:
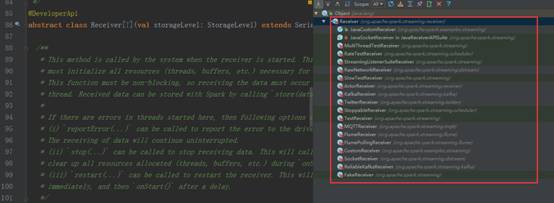
5、 如果上述实现类都满足不了您的要求,您自己可以定义Receiver类,只需要继承Receiver抽象类来实现自己子类的业务需求。
四、StreamingContext、DStream、Receiver结合流程分析:
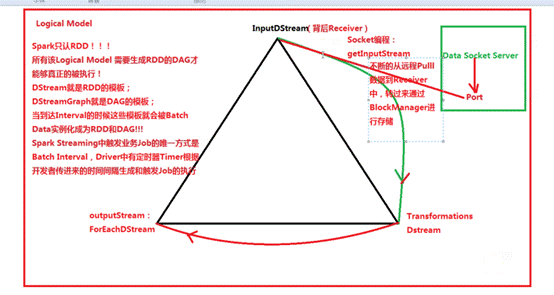
(1)inputStream代表了数据输入流(如:Socket、Kafka、Flume等)
(2)Transformation代表了对数据的一系列操作,如flatMap、map等
(3)outputStream代表了数据的输出,例如wordCount中的println方法:

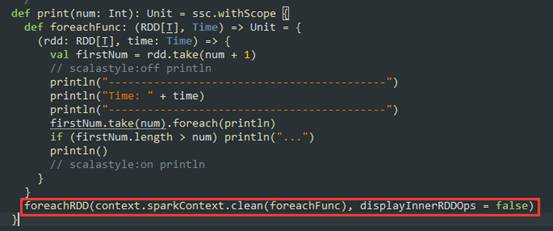

数据数据在流进来之后最终会生成Job,最终还是基于Spark Core的RDD进行执行:在处理流进来的数据时是DStream进行Transformation由于是StreamingContext所以根本不会去运行,StreamingContext会根据Transformation生成”DStream的链条”及DStreamGraph,而DStreamGraph就是DAG的模板,这个模板是被框架托管的。当我们指定时间间隔的时候,Driver端就会根据这个时间间隔来触发Job而触发Job的方法就是根据OutputDStream中指定的具体的function,例如wordcount中print,这个函数一定会传给ForEachDStream,它会把函数交给最后一个DStream产生的RDD,也就是RDD的print操作,而这个操作就是RDD触发Action。
总结:
使用Spark Streaming可以处理各种数据来源类型,如:数据库、HDFS,服务器log日志、网络流,其强大超越了你想象不到的场景,只是很多时候大家不会用,其真正原因是对Spark、spark streaming本身不了解。
- 第84讲:StreamingContext、DStream、Receiver深度剖析
- StreamingContext、DStream、Receiver深度剖析
- 0084:StreamingContext、DStream、Receiver深度剖析
- IMF传奇行动第84课:Spark Streaming第三课:StreamingContext、DStream、Receiver深度剖析
- SparkStreaming之 StreamingContext、DStream、Receiver深度剖析-3
- 图解StreamingContext、DStream、Receiver 第三讲spark streaming
- 大数据IMF传奇行动绝密课程第84课:图解StreamingContext、DStream、Receiver并结合源码分析
- 第5讲 zend原理深度剖析
- day84:StreamContext、DStream、receiver
- JavaSE第一百讲:线程同步问题深度剖析
- Servlet自学第14讲:深度剖析http请求
- 6.Spark Streaming:输入DStream和Receiver详解
- 第3讲 zend原理剖析
- JavaSE第三十讲:String类陷阱深度剖析
- JavaSE第四十六讲:迭代器、TreeSet及Comparator深度剖析
- JavaSE第五十二讲:HashSet 与HashMap源代码深度剖析
- JavaSE第六十一讲:Java反射机制深度剖析
- JavaSE第六十五讲:静态代理模式深度剖析
- 命令行查看.mobileprovision .a文件
- 一款很实用的小demo 字母条索引+自定义进度条+listview/checkbox+长按多选+读取联系人\头像
- rails 提供下拉框select和select_tag用法(附加form_for, form_tag提交表单的内容)
- linux qt 4.8 x86 arm开发环境配置(openSUSE Leap 42.1)
- vector的两种读取方式
- 第84讲:StreamingContext、DStream、Receiver深度剖析
- CoreLocation
- Unable to instantiate default tuplizer [org.hibernate.tuple.entity.PojoEntityTuplizer]
- (一般)POJ-1328 区间贪心,几何
- Error:Execution failed for task ':app:transformResourcesWithMergeJavaResForUmengDebug'. > com.androi
- Android 常用的颜色
- iOS 获取本地相册的所有图片
- android的消息处理机制(图+源码分析)——Looper,Handler,Message
- Android学习之路


