Codeforces Round #344 (Div. 2) D. Messenger
来源:互联网 发布:mysql 拆分字符串函数 编辑:程序博客网 时间:2024/05/13 13:50
Each employee of the "Blake Techologies" company uses a special messaging app "Blake Messenger". All the stuff likes this app and uses it constantly. However, some important futures are missing. For example, many users want to be able to search through the message history. It was already announced that the new feature will appear in the nearest update, when developers faced some troubles that only you may help them to solve.
All the messages are represented as a strings consisting of only lowercase English letters. In order to reduce the network load strings are represented in the special compressed form. Compression algorithm works as follows: string is represented as a concatenation of nblocks, each block containing only equal characters. One block may be described as a pair (li, ci), where li is the length of the i-th block and ci is the corresponding letter. Thus, the string s may be written as the sequence of pairs  .
.
Your task is to write the program, that given two compressed string t and s finds all occurrences of s in t. Developers know that there may be many such occurrences, so they only ask you to find the number of them. Note that p is the starting position of some occurrence of s in t if and only if tptp + 1...tp + |s| - 1 = s, where ti is the i-th character of string t.
Note that the way to represent the string in compressed form may not be unique. For example string "aaaa" may be given as 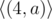 ,
,  ,
, 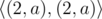 ...
...
The first line of the input contains two integers n and m (1 ≤ n, m ≤ 200 000) — the number of blocks in the strings t and s, respectively.
The second line contains the descriptions of n parts of string t in the format "li-ci" (1 ≤ li ≤ 1 000 000) — the length of the i-th part and the corresponding lowercase English letter.
The second line contains the descriptions of m parts of string s in the format "li-ci" (1 ≤ li ≤ 1 000 000) — the length of the i-th part and the corresponding lowercase English letter.
Print a single integer — the number of occurrences of s in t.
5 33-a 2-b 4-c 3-a 2-c2-a 2-b 1-c
1
6 13-a 6-b 7-a 4-c 8-e 2-a3-a
6
5 51-h 1-e 1-l 1-l 1-o1-w 1-o 1-r 1-l 1-d
0
In the first sample, t = "aaabbccccaaacc", and string s = "aabbc". The only occurrence of string s in string t starts at position p = 2.
In the second sample, t = "aaabbbbbbaaaaaaacccceeeeeeeeaa", and s = "aaa". The occurrences of s in t start at positions p = 1,p = 10, p = 11, p = 12, p = 13 and p = 14.
题目大意:求b串在a串中出现多少次。
解题思路:实质是kmp匹配,先把相邻相同的字母合并起来先,a串长度为n,b串的长度为m,匹配的条件是:
当b[1,m-2]与a[i,j]匹配了:
1.判断a[i-1]与b[0]的字母是否一样,而且a[i-1]字母数>=b[0]的字母数。
2.判断a[j+1]与b[m-1]的字母是否一样,而且a[j+1]字母数>=b[m-1]的字母数。
所以,可以看作把b串的头尾去掉后进行匹配,然后再进行头尾的匹配,然后注意
m=1 or 2的情况,特判一下即可。
/* ***********************************************┆ ┏┓ ┏┓ ┆┆┏┛┻━━━┛┻┓ ┆┆┃ ┃ ┆┆┃ ━ ┃ ┆┆┃ ┳┛ ┗┳ ┃ ┆┆┃ ┃ ┆┆┃ ┻ ┃ ┆┆┗━┓ 马 ┏━┛ ┆┆ ┃ 勒 ┃ ┆ ┆ ┃ 戈 ┗━━━┓ ┆┆ ┃ 壁 ┣┓┆┆ ┃ 的草泥马 ┏┛┆┆ ┗┓┓┏━┳┓┏┛ ┆┆ ┃┫┫ ┃┫┫ ┆┆ ┗┻┛ ┗┻┛ ┆************************************************ */#include <stdio.h>#include <string.h>#include <iostream>#include <algorithm>#include <vector>#include <queue>#include <stack>#include <set>#include <map>#include <string>#include <math.h>#include <stdlib.h>using namespace std;#define rep(i,a,b) for (int i=(a),_ed=(b);i<_ed;i++)#define per(i,a,b) for (int i=(b)-1,_ed=(a);i>=_ed;i--)#define inf 0x3f3f3f3f#define mod 1000000007#define ll long long#define ull unsigned long longconst int N = 2e5 + 5;pair<int,ll>a[N],b[N],c[N];void Union(pair<int,ll>d[],int &n){ int pos=0; for(int i=1;i<=n;i++) { if(pos==0 || d[i].first!=d[pos].first) { d[++pos]=d[i]; } else d[pos].second+=d[i].second; } n=pos;}int nex[N],mark[N];void kmp(int n,int m){ for(int i=2;i<m;i++) { c[i-1]=b[i]; } m-=2; for(int i=1,j=0;i<=m;) { if(j==0 || c[j]==c[i]) { j++,i++; nex[i]=j; } else j=nex[j]; } for(int i=1,j=0;i<=n;i++) { while (j != 0 && a[i] != c[j + 1]) j = nex[j]; if (c[j + 1] == a[i]) ++j; if (j == m) { mark[i] = 1; j = nex[j]; } }}int main(){ //freopen("in.txt","r",stdin); //freopen("out.txt","w",stdout);int n,m;scanf("%d%d",&n,&m);int x; char y;for(int i=1;i<=n;i++) { scanf("%d-%c",&x,&y); a[i]=make_pair(y,x); } for(int i=1;i<=m;i++) { scanf("%d-%c",&x,&y); b[i]=make_pair(y,x); } Union(a,n); Union(b,m); ll ans=0; if(m==1) { for(int i=1;i<=n;i++) { if(a[i].first==b[1].first && a[i].second>=b[1].second) ans += a[i].second - b[1].second + 1; } } else if(m==2) { for (int i = 1; i < n; ++i) { if (a[i].first == b[1].first && a[i + 1].first == b[2].first && a[i].second >= b[1].second && a[i + 1].second >= b[2].second) ans++; } } else { kmp(n,m); for (int i = 1; i < n; ++i) { if (mark[i] && b[1].first == a[i + 1 - m + 1].first && b[1].second <= a[i + 1 - m + 1].second &&b[m].first == a[i + 1].first && b[m].second <= a[i + 1].second) ans++; } } cout<<ans<<endl; return 0;}- Codeforces Round #344 (Div. 2) D. Messenger
- Codeforces Round #344 (Div. 2) D. Messenger
- Codeforces Round #344 (Div. 2) D. Messenger(kmp)
- Codeforces Round #344 (Div. 2)D. Messenger【kmp】
- Codeforces Round #344 (Div. 2) D. Messenger(kmp,细节)
- Codeforces Round #344 (Div. 2) D. Messenger (KMP)
- Codeforces Round #344 (Div. 2) D. Messenger CF631D
- Codeforces Round #200 (Div. 2)344D Alternating Current(栈)
- hdu 1711 && Codeforces Round #344 (Div. 2) D 【KMP】
- Codeforces Round #103 (Div. 2) D
- Codeforces Round #104 (Div. 2) D
- Codeforces Round #105 (Div. 2) D
- Codeforces Round #139 (Div. 2) D. Snake
- Codeforces Round #155 (Div. 2) D-rats
- Codeforces Round #159 (Div. 2) D sum
- Codeforces Round #184 (Div. 2) D、E
- Codeforces Round#186(Div 2) D
- codeforces Round # 187(Div.2) D
- JDBC学习笔记
- Nginx负载均衡+动静分离
- 交换机和路由器的区别
- java基础部分总结第一部分
- Android 对话框
- Codeforces Round #344 (Div. 2) D. Messenger
- 安卓中搜索本地音乐图片方面详解(音乐图片,切图,画图,描边)
- Hibernate主键生成策略
- 友盟分享调不起微信
- Unity中集成ShareSDK(3.X)的功能-IOS平台
- vs2010配置cocos2d-x出现的错误及解决方法
- DatePickerDialog 隐藏子控件
- JDBC操作数据库的基本步骤
- java基础部分总结第二部分


