隐马尔可夫模型
来源:互联网 发布:裸钻哪里买 知乎 编辑:程序博客网 时间:2024/05/22 06:10
隐马尔可夫模型
标签: 模式分类
@author lancelot-vim
在一些与时间相关的问题中,我们会遇到t时刻发生的事件受t-1时刻发生事件的直接影响,处理这些问题时,隐马尔可夫模型(hidden markov model, HMM)得到了最好的应用,例如在语音识别或者手势识别领域,隐马尔可夫模型具有一组已经设计好的参数,他们可以最好地解释特定类别中的样本。在使用中,一个测试样本被归类为能产生最大后验概率的那个类别,也就是说,这个类别的模型最好地解释了这个测试样本。
一阶马尔可夫模型
考虑连续时间上的一系列状态,在t时刻的状态被记为
产生数据的机理是通过转移概率,记为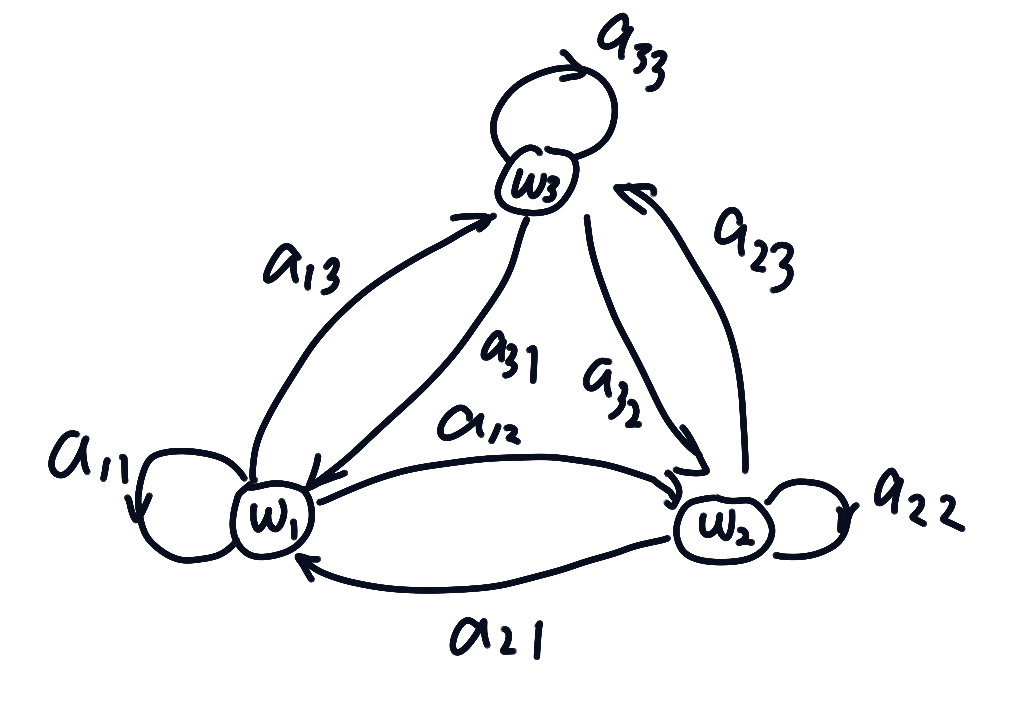
假设已有模型
到目前为止,我们讨论的是一阶马尔可夫模型,因为某一时刻的概率仅仅和前一时刻有关,但是人们可能不能直接观测到某些状态,比如单词”cat”,需要从音标/k/转移到/a/,再转移到/t/,但人们往往只能听到发音而感受不到这些特定的状态,所以我们需要改变当前讨论的模型,引入”可见状态”(visible state)——即那些可以观测到的外部状态,和状态
一阶隐马尔可夫模型
假设在某一时刻t,系统都处于某个状态
在t时刻的状态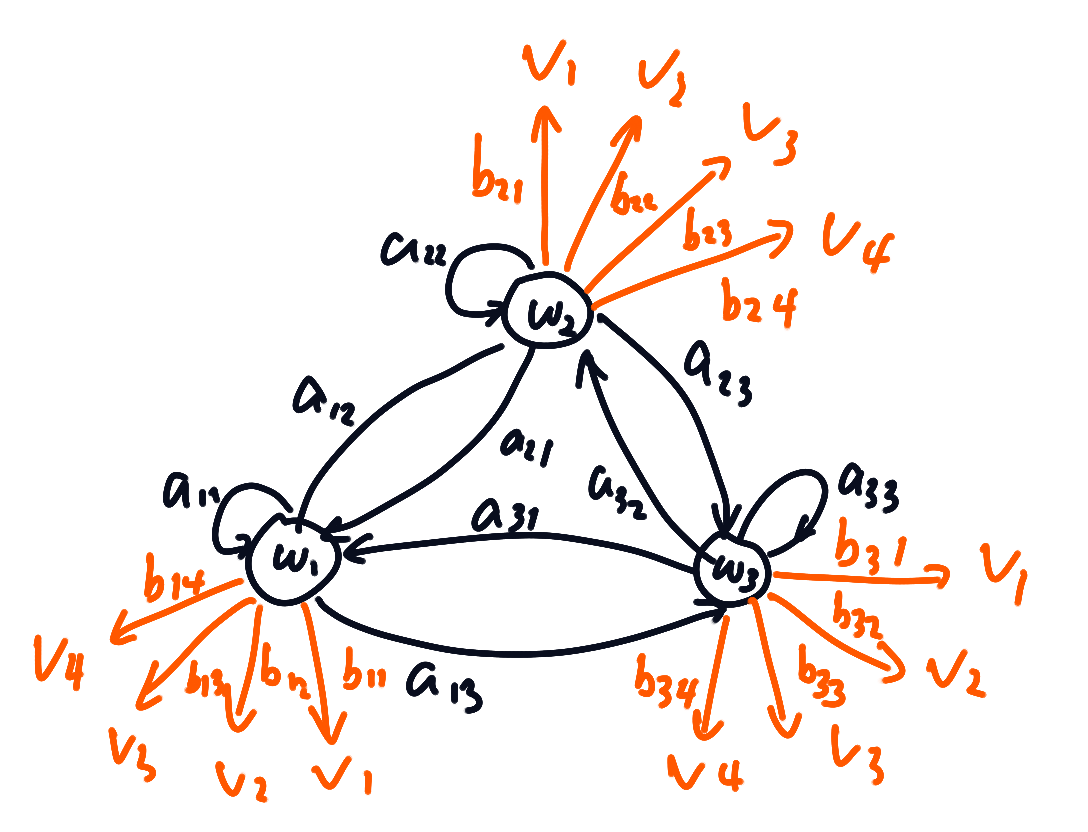
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- 隐马尔可夫模型
- java Arrays工具类
- 动画的设置 pop
- HTTPS的误解(一)
- IGMP补充
- 二叉树相关笔试题(一)
- 隐马尔可夫模型
- log4j 打印sql,按日期生成文件,生成文件位置
- Android内存优化之OOM
- MySQL的varchar定义长度到底是字节还是字符
- CTSVerifier test 教程
- ios开发中类方法与self的注意点 与实例方法区别
- wordpress使用记录
- linux ps命令学习
- MySQL 建表字段长度的限制问题


