决策树介绍一
来源:互联网 发布:零基础学java pdf 编辑:程序博客网 时间:2024/06/08 07:04
决策树(Decision tree)是一种基本的分类与回归方法,尤其是在各大竞赛中,很多最后胜出的算法都是树模型组合起来的.决策树的学习通常分为三部分:特征选择,决策树的生成和决策树的剪枝.本文主要介绍决策树学习的ID3,C4.5算法,C5.0算法和CART 树.为了更好的理解本文,请先阅读信息论基础.
1 例子
决策树可以理解成是很多
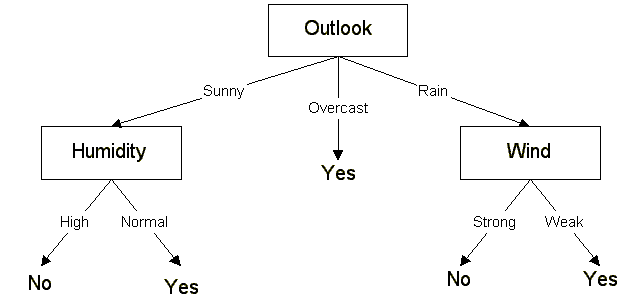
这棵决策树根据天气情况分类“星期六上午是否适合打网球”,根节点到叶节点的每一条路径构成了一条规则,路径上的内部节点对应规则的条件,叶节点的类对应着规则的结论.
- 规则1:如果晴天,湿度很高就不去打网球
- 规则2:如果晴天,湿度一般就去打网球
- 规则3:如果是阴天,就去打网球
- 规则4:如果是雨天,而且大风,就不去打网球
- 规则5:如果是雨天,但是微风,就去打网球
再比如,某位母亲给自己闺女物色了个男朋友,于有了下面这段对话:
- 女儿:多大年纪了?
- 母亲:26.
- 女儿:长得帅不帅?
- 母亲:挺帅的.
- 女儿:收入高不?
- 母亲:不算特别高,中等情况吧.
- 女儿:是不是公务员?
- 母亲:是,在税务局上班.
- 女儿:那好,见个面吧.
这个女孩的决策过程就是典型的分类决策过程.相当于通过年龄,长相,收入和是否是公务员将男人分成两类:见和不见.假设这个女孩对男人的要求是:30岁以下,长相中等,高收入或者中等收入的公务员,那么可以用下图来表示女孩的决策逻辑:
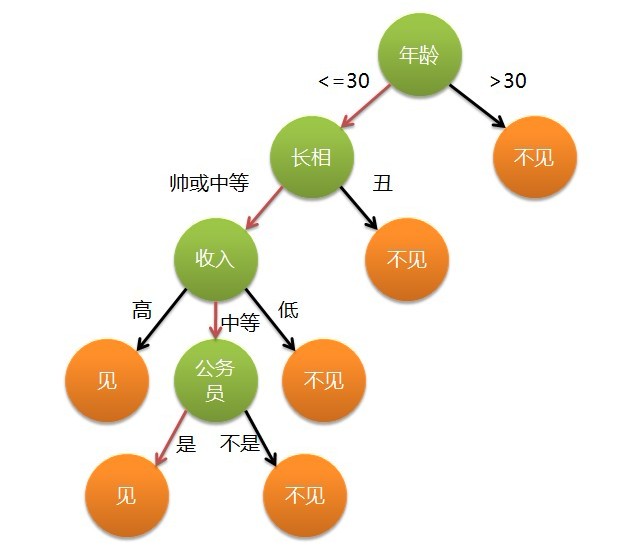
下面就以一个例子来说明决策树学习的各种算法.
我们希望能够学习出一个贷款申请的决策树,当新的客户提出申请贷款时,根据申请人的特征利用决策树决定是否批准申请贷款.
这个例子中,我们有年龄,工作,房子,信贷情况等特征:
年龄青年,中年,老年工作是,否房子是,否信贷情况一般,好,非常好如果我们根据这些条件逐步去构建决策树的话,如何选择每个节点呢? 比如我们的根节点是选年龄好还是选工作好? 不同的算法选择的标准不一样.在了解这些算法之前,请先阅读信息论基础这篇文章,确保理解了里面介绍到的概念.
2 ID3
ID3由Ross Quinlan于1986年提出.

它根据信息增益(Information gain)来选取Feature作为决策树分裂的节点.特征
实际上就是特征
所以:
所以:
由此可以计算出:
总结一下上面的计算过程,假设训练数据集为
- 计算数据集
D D 的经验熵 H(D)
- 计算特征
A A对数据集D D 的经验条件熵
ID3从根节点开始,计算所有可能特征的信息增益,取信息增益最大的特征作为节点的特征,然后由特征的不同取值,建立子节点,再对子节点递归调用以上方法,知道所有特征的信息增益都很小或者没有特征选择为止.
具体为:
- 若
D D中所有实例都属于同一类Ck Ck,则T T 为单节点树,并将类Ck Ck作为该节点的类标记,返回T T. - 若
A=Φ A=Φ,则T T为单节点树,并将D D中实例最大的类Ck Ck作为该节点的类标记,返回T T. - 否则,按照信息增益的算法,计算每个特征对
D D的信息增益,取信息增益最大的特征Ag Ag. - 如果
Ag<ε Ag<ε,则置T T 为单节点树,并将D D中实例最大的类Ck Ck作为该节点的类标记,返回T T. - 否则,对
Ag Ag的每一可能值ai ai,依Ag=ai Ag=ai将D D分成若干非空子集Di Di,将Di Di中实例最大的类作为标记,构建子节点,由节点和子节点构成树T T,返回T T. - 对第
i i 个子节点,以Di Di为训练集,以A−{Ag} A−{Ag} 为特征集,递归地调用步骤1到步骤5,得到子树Ti Ti,返回Ti Ti.
3 C4.5
C4.5由Ross Quinlan于1993年提出.ID3采用的信息增益度量存在一个内在偏置,它优先选择有较多属性值的Feature,因为属性值多的Feature会有相对较大的信息增益?(信息增益反映的给定一个条件以后不确定性减少的程度,必然是分得越细的数据集确定性更高,也就是条件熵越小,信息增益越大).避免这个不足的一个度量就是不用信息增益来选择Feature,而是用信息增益比率(gain ratio),增益比率通过引入一个被称作分裂信息(Split information)的项来惩罚取值较多的Feature,分裂信息用来衡量Feature分裂数据的广度和均匀性:
但是当某个
相比ID3,C4.5还能处理连续属性值,具体步骤为:
- 把需要处理的样本(对应根节点)或样本子集(对应子树)按照连续变量的大小从小到大进行排序.
- 假设该属性对应的不同的属性值一共有
N N个,那么总共有N−1 N−1个可能的候选分割阈值点,每个候选的分割阈值点的值为上述排序后的属性值中两两前后连续元素的中点,根据这个分割点把原来连续的属性分成bool属性.实际上可以不用检查所有N−1 N−1个分割点,具体请看下面的例子.- 用信息增益比率选择最佳划分.
假设上面关于贷款的例子还有个属性是收入情况,对应的数据如下(已经排好序):
收入(百)404860728090类别否否是是是否可以证明这时候的切分点,只能出现在目标分类不同的相邻实例之间,即出现在(48,60)和(80,90)之间,这时候选取切分点
C4.5还能对缺失值进行处理,处理的方式通常有三种:
- 赋上该属性最常见的值
- 根据节点的样例上该属性值出现的情况赋一个概率,比如该节点上有10个样本,其中属性A的取值有6个为是,4个为否.那么对改节点上缺失的属性A,以0.6的概率设为是,0.4的概率设为否.
- 丢弃有缺失值的样本
- 决策树介绍一
- 决策树介绍
- SPSS Modeler 介绍决策树
- 决策树介绍和使用
- 决策树绘图(一)
- 决策树(一) ID3
- 决策树学习(一)
- 决策树(一)
- 决策树(一)--ID3
- 决策树(一)
- 决策树(一)
- 决策树算法(一)
- 决策树算法实现(一)
- 决策树(一):基本概念
- 监督学习一 决策树
- C4.5决策树算法介绍
- 决策树算法介绍及应用
- 决策树算法介绍及应用
- OC关联objc_setAssociatedObject
- [leetcode] 327. Count of Range Sum 解题报告
- 自己写的java邮件客户端
- 第8周项目3 - 指向学生类的指针
- javasript dom 中获取元素类名 或者 改变类 引用另外一个类
- 决策树介绍一
- java杂记
- oracle导出、导入dmp文件
- UVA4260Fortune Card Game【dp】
- 第10、11周-程序阅读补充(1)
- 学习JavaScript应该尽早知道的几个技巧
- Android通知之Notification的用法剖析
- tomcat性能调优
- SiteWhere如何连接MongoDB


