Google深度学习笔记 Stochastic Optimization
来源:互联网 发布:windows模拟器 安卓 编辑:程序博客网 时间:2024/05/16 14:57
转载请注明作者:梦里风林
Github工程地址:https://github.com/ahangchen/GDLnotes
欢迎star,有问题可以到Issue区讨论
官方教程地址
视频/字幕下载
- 实践中大量机器学习都是通过梯度算子来求优化的
- 但有一些问题,最大的问题就是,梯度很难计算
- 我们要计算train loss,这需要基于整个数据集的数据做一个计算
- 而计算使 train loss 下降最快的调整方向需要的时间是计算train loss本身的三倍

- 因此有了SGD:Stochastic Gradient Descent
- 计算train loss时,只随机取一小部分数据集做为输入
- 调整W和b时,调整的大小step需要比较小,因为数据集小,我们找到的不一定是对的方向
- 这样也就增加了调整的次数
- 但可观地减小了计算量

SGD的优化
实际上SGD会使得每次寻找的方向都不是很准,因此有了这些优化
- 随机的初始值

- Momentum
考虑以前的平均调整方向来决定每一步的调整方向

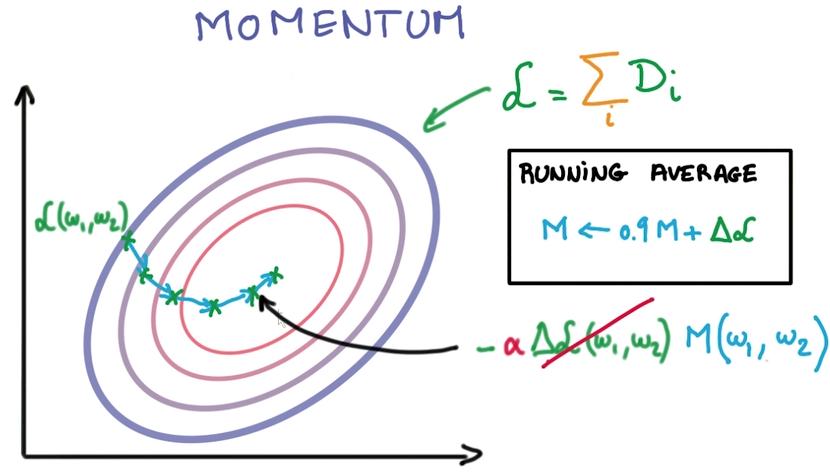
Learning Rate Decay
- 训练越靠近目标,步长应该越小
Parameter Hyperspace
- Learning Rate(即调整的step)不是越大越好,可能有瓶颈
- SGD有许多参数可以调整,所以被称为黑魔法

- AdaGurad
- 自动执行momentum和learning rate decay
- 使得SGD对参数不像原来那样敏感
- 自动调整效果不如原来的好,但仍然是一个option
觉得得我的文章对您有帮助的话,就给个star吧~
1 0
- Google深度学习笔记 Stochastic Optimization
- TensorFlow深度学习笔记 Stochastic Optimization
- [深度学习论文笔记][Optimization] Unit Tests for Stochastic Optimization
- CS231N学习笔记4 Optimization: Stochastic Gradient Descent
- Stochastic Optimization Techniques随机优化相关笔记
- 笔记:Online Robust PCA via Stochastic Optimization
- Google 深度学习笔记
- Robust Optimization VS Stochastic Optimization
- Optimization:Stochastic Gradient Descent
- Optimization: Stochastic Gradient Descent
- CS231n Optimization: Stochastic Gradient Descent
- <<Stochastic Discrete Event Systems >>学习笔记
- [论文笔记]Adaptive Subgradient Methods for Online Learning and Stochastic Optimization
- Google深度学习笔记 Logistic Classification
- Google 深度学习笔记 卷积神经网络
- Google深度学习笔记 循环神经网络实践
- udacity上Google的深度学习笔记
- Tensorflow实战Google深度学习框架 笔记
- Java正则表达式
- Linux - poll()
- Linux创建子线程
- 网格视图GridView的使用
- Light oj 1338 - Hidden Secret!【字符串】
- Google深度学习笔记 Stochastic Optimization
- java 的 boolean 形式
- BroadcastReceiver详解
- Android——View事件分发机制
- Python学习笔记--生成器
- python字符串内建函数str.index()和str.rindex()
- (Android Studio)自定义 ProgressBar (二)
- Redis集群使用总结(二)
- 单例模式


