自组织神经网络:Kohonen网络训练算法
来源:互联网 发布:数据库具备的特性 编辑:程序博客网 时间:2024/05/16 07:58
自组织神经网络:Kohonen网络训练算法
Kohonen网络的拓扑结构
网络上层为输出结点(假设为m个),按二维形式排成一个结点矩阵。

输入结点处于下方,若输入向量由n个元素,则输入端共有n个结点。
所有输入结点到输出结点都有权值连接,而在二维平面的输出结点相互间也可能有局部连接。
Kohonen网络的功能就是通过自组织方法,用大量的样本训练数据来调整网络的权值,使得最后网络的输出能够反映样本数据的分布情况。
网络自组织算法
网络开始训练时,某个输出结点能对某一类模式作出特别的反应,以代表该模式类,但这里规定二维平面上相邻的结点能对实际模式分布中相近的模式类作出特别的反应。当某类数据模式输入时,对其某一输出结点给予最大的刺激,以指示该类模式的所属区域,而同时对获胜结点周围的一些结点给予较大的刺激。
当输入模式从一个模式区域移到相邻的模式区域时,二维平面上的获胜结点也从原来的结点移到其相邻的结点。因此,从Kohonen网络的输出状况,不但能判断输入模式所属的类别并使输出结点代表某一类模式,还能够得到整个数据区域的大体分布情况,即从样本数据中抓到所有数据分布的大体本质特性。
为了能使二维输出平面上相邻的输出结点对相近的输入模式类作出特别反应,在训练过程中需定义获胜结点的邻域结点。
假设本次获胜结点为Nj,它在t时刻的邻域结点用NEj(t)表示,NEj(t)包含以结点Nj为中心而距离不超过某一半径的所有结点。随着训练的进行, NEj(t)的半径逐渐缩小,最后只包含获胜结点Nj自身,即在训练初始阶段,不但对获胜的结点做权值调整,也对其较大范围内的几何邻接结点做相应的调整,而随着训练过程的继续,与输出结点相连的权向量也越来越接近其代表的模式类。
此时,对获胜结点进行较细微的权值调整时,只对其几何邻域接近的结点(包括其自身)进行相应调整,直到最后只对获胜的结点本身做细微的权值调整。在训练结束后,几何上相近的输出结点所连接的权向量既有联系(类似性)又互相区别,从而保证对于某一类输入模式,获胜结点能做出最大响应,而相邻结点做出较大响应。几何上相邻的结点代表特征上相近的模式类别。
自组织神经网络:Kohonen网络训练算法
(1) 权连接初始化,对所有从输入结点到输出结点的连接权值赋予随机的小数,置时间计数t = 0。
(2) 对网络输入模式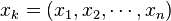 。
。
(3) 计算输入x_k与全部输出结点所连接向量 的距离: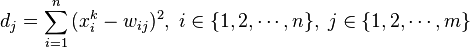
(4) 具有最小距离的结点 竞争获胜:
竞争获胜:

(5) 调整输出结点j*所连接的权值及
几何邻域 内的结点所连权值:
内的结点所连权值:
(6) 若还有输入样本数据,t = t+1,转(2)。
在算法中,
 是一种可变学习速度,随时间而衰减,表示随着训练过程的进行,权值调整的幅度越来越小,以使竞争获胜结点所连的权向量代表模式的本质属性。也随时间而收缩,最后当t充分大时,
是一种可变学习速度,随时间而衰减,表示随着训练过程的进行,权值调整的幅度越来越小,以使竞争获胜结点所连的权向量代表模式的本质属性。也随时间而收缩,最后当t充分大时, ,即只训练获胜结点本身以实现Kohonen网络的自组织特征映射功能。和都有许多不同的形式,在具体训练过程中可根据不同的数据分布进行选择和设计。
,即只训练获胜结点本身以实现Kohonen网络的自组织特征映射功能。和都有许多不同的形式,在具体训练过程中可根据不同的数据分布进行选择和设计。- 自组织神经网络:Kohonen网络训练算法
- 自组织神经网络模型与学习算法
- Kohonen网络
- Kohonen网络
- 矢量量化神经网络,自组织竞争神经网络,自组织映射网络
- SOM自组织神经网络
- SOM自组织神经网络
- 自组织神经网络
- 自组织神经网络的实现
- 自组织神经网络元音识别
- SOM自组织神经网络学习
- 自组织竞争网络
- 自组织映射网络
- 自组织迁移算法
- 卷积神经网络训练算法
- 广义回归神经网络GRNN ,竞争神经网络,自组织映射神经网络
- 自组织特征映射神经网络(SOFM)
- 自组织特征映射神经网络(SOM)
- Spark三种属性配置方式详细说明
- 二分查找
- USACO Section 3.3 A Game pascal
- URI和URL区别
- XML
- 自组织神经网络:Kohonen网络训练算法
- SQLite数据库基本语法
- 2151 Worm
- 工具进阶篇
- [leetcode] 【数组】36. Valid Sudoku
- 关于使用LIBSVM3.21过程中出现的问题
- git提交到远程仓库(or部署服务器)
- 如何处理海量数据(转)
- SQLite数据库函数基本使用


