Lucene全文搜索原理与使用
来源:互联网 发布:数据库服务器选购 编辑:程序博客网 时间:2024/05/07 06:42
本文中主要是对于Lucene全文搜索的基础原理进行简单的分析,以及Lucene实现全文搜索的流程,之后就是Lucene在Java中的最简单使用:创建索引,查询索引库;
本文中使用的Lucene主要是4.10.3和6.0.0,两个版本的原理相同,但是API的使用并不相同;
1、结构化数据与非结构化数据
2、非结构化数据搜索
3、全文搜索
4、搜索如何实现
5、Lucene实现全文搜索流程
6、Lucene的API使用
根据上述1中所述的内容,所以两者在搜索上也是同样存在着一定的区别 (内容来自wiki):
模拟如下:


本文中使用的Lucene主要是4.10.3和6.0.0,两个版本的原理相同,但是API的使用并不相同;
1、结构化数据与非结构化数据
2、非结构化数据搜索
3、全文搜索
4、搜索如何实现
5、Lucene实现全文搜索流程
6、Lucene的API使用
1、结构化数据与非结构化数据
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等。
2、非结构化数据搜索
根据上述1中所述的内容,所以两者在搜索上也是同样存在着一定的区别 (内容来自wiki):
- 对于结构化的数据而言:对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
- 对于非结构化的数据而言:
- (1)顺序扫描法(Serial Scanning)
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。- (2)全文检索(Full-text Search)
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
3、全文搜索
(1)全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法。全文检索首先将要查询的目标文档中的词提取出来,组成索引,通过查询索引达到搜索目标文档的目的。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
(2)全文检索就是把文本中的内容拆分成若干个关键词,然后根据关键词创建索引。查询时,根据关键词查询索引,最终找到包含关键词的文章。整个过程类似于查字典的过程。(重点在于如何可以正确高效的拆分关键词,然后根据关键词创建索引)
(3)全文检索的应用领域
- 搜索引擎:例如百度、谷歌、搜狗。
- 站内搜索:例如论坛搜索,天涯论坛搜索、微博搜索。
- 电商搜索:搜索的是商品信息。例如淘宝、京东。
4、搜索如何实现(以百度/谷歌的搜索业务作为例子)
模拟如下:
5、Lucene实现全文搜索流程
- 1)创建文档对象:为每个文件对应的创建一个Document对象。把文件的属性都保存到document对象中。需要为每个属性创建一个field(在lucene中叫做域),把field添加到文档对象中。每个document都有一个唯一的编号。
- 2)分析文档:针对document中的域进行分析,例如分析文件名、文件内容两个域。先把文件内容域中的字符串根据空格进行分词,把单词进行统一转换成小写。把没有意义的单词叫做停用词。把停用词从词汇列表中去掉。去掉标点符号。最终得到一个关键词列表。每个关键词叫做一个Term。Term中包含关键词及其所在的域,不同的域中相当的单词是不同的term。
- 3)创建索引:索引:为了提高查询速度的一个数据结构。在关键词列表上创建一个索引;把索引和文档对象写入索引库,并记录关键词和文档对象的对应关系。
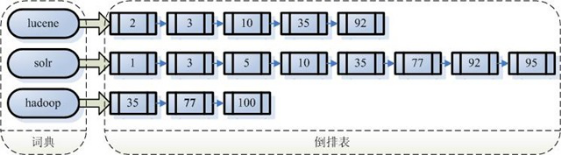
每个关键词对应一链表,链表中的每个元素都是document对象的id。对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。注意:创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。传统方法是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大、搜索慢。倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
- 4)查询索引
6、Lucene的API使用(建议使用maven的工程)
- 1)创建索引(使用6.0.0的方式创建)
pom.xml
[XML] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <!-- [url=http://mvnrepository.com/artifact/org.apache.lucene/lucene-core]http://mvnrepository.com/artifact/org.apache.lucene/lucene-core[/url] --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>6.0.0</version> </dependency> <!-- [url=http://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser]http://mvnrepository.com/artifac ... /lucene-queryparser[/url] --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>6.0.0</version> </dependency> <!-- [url=http://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common]http://mvnrepository.com/artifac ... ne-analyzers-common[/url] --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>6.0.0</version> </dependency> <!-- [url=http://mvnrepository.com/artifact/commons-io/commons-io]http://mvnrepository.com/artifact/commons-io/commons-io[/url] --> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.5</version> </dependency> </dependencies>IndexRepository.java
[Java] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
importjava.io.File;importjava.io.IOException;importjava.nio.file.Path;importorg.apache.commons.io.FileUtils;importorg.apache.lucene.analysis.Analyzer;importorg.apache.lucene.analysis.standard.StandardAnalyzer;importorg.apache.lucene.document.Document;importorg.apache.lucene.document.Field;importorg.apache.lucene.document.Field.Store;importorg.apache.lucene.document.StoredField;importorg.apache.lucene.document.TextField;importorg.apache.lucene.index.IndexWriter;importorg.apache.lucene.index.IndexWriterConfig;importorg.apache.lucene.store.Directory;importorg.apache.lucene.store.FSDirectory;/** * 索引存储 */publicclass IndexRepository { // 注意:此处使用的是Lucene6.0.0最新版本与4.X版本有一些区别,可以查看源码或者API进行了解 publicstatic void main(String[] args) throwsIOException { // 指定索引库的存放路径,需要在系统中首先进行索引库的创建 // 指定索引库存放路径 File indexrepository_file = newFile("此处是索引存放地址"); Path path = indexrepository_file.toPath(); Directory directory = FSDirectory.open(path); // 读取原始文档内容 File files = newFile("此处是源文件地址"); // 创建一个分析器对象 // 使用标准分析器 Analyzer analyzer = newStandardAnalyzer(); // 创建一个IndexwriterConfig对象 // 分析器 IndexWriterConfig config = newIndexWriterConfig(analyzer); // 创建一个IndexWriter对象,对于索引库进行写操作 IndexWriter indexWriter = newIndexWriter(directory, config); // 遍历一个文件 for(File f : files.listFiles()) { // 文件名 String fileName = f.getName(); // 文件内容 @SuppressWarnings("deprecation") String fileContent = FileUtils.readFileToString(f); // 文件路径 String filePath = f.getPath(); // 文件大小 longfileSize = FileUtils.sizeOf(f); // 创建一个Document对象 Document document = newDocument(); // 向Document对象中添加域信息 // 参数:1、域的名称;2、域的值;3、是否存储; Field nameField = newTextField("name", fileName, Store.YES); Field contentField = newTextField("content", fileContent , Store.YES); // storedFiled默认存储 Field pathField = newStoredField("path", filePath); Field sizeField = newStoredField("size", fileSize); // 将域添加到document对象中 document.add(nameField); document.add(contentField); document.add(pathField); document.add(sizeField); // 将信息写入到索引库中 indexWriter.addDocument(document); } // 关闭indexWriter indexWriter.close(); }}运行结果:
- 2)创建索引(使用4.10.3的方式创建)
pom.xml
[XML] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <!-- [url=http://mvnrepository.com/artifact/commons-io/commons-io]http://mvnrepository.com/artifact/commons-io/commons-io[/url] --> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.5</version> </dependency> <!-- [url=http://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common]http://mvnrepository.com/artifac ... ne-analyzers-common[/url] --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>4.10.3</version> </dependency> <!-- [url=http://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser]http://mvnrepository.com/artifac ... /lucene-queryparser[/url] --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>4.10.3</version> </dependency> <!-- [url=http://mvnrepository.com/artifact/org.apache.lucene/lucene-core]http://mvnrepository.com/artifact/org.apache.lucene/lucene-core[/url] --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>4.10.3</version> </dependency> </dependencies>IndexRepository.java
[Java] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
importjava.io.File;importjava.io.IOException;importorg.apache.commons.io.FileUtils;importorg.apache.lucene.analysis.Analyzer;importorg.apache.lucene.analysis.standard.StandardAnalyzer;importorg.apache.lucene.document.Document;importorg.apache.lucene.document.Field;importorg.apache.lucene.document.LongField;importorg.apache.lucene.document.StoredField;importorg.apache.lucene.document.TextField;importorg.apache.lucene.document.Field.Store;importorg.apache.lucene.index.IndexWriter;importorg.apache.lucene.index.IndexWriterConfig;importorg.apache.lucene.store.Directory;importorg.apache.lucene.store.FSDirectory;importorg.apache.lucene.util.Version;/** * 索引的创建 */publicclass IndexRepository { publicstatic void main(String[] args) throwsIOException { Directory directory = FSDirectory.open(newFile("此处是索引文件存放地址")); File files = newFile("此处是源文件地址"); Analyzer analyzer = newStandardAnalyzer(); IndexWriterConfig config = newIndexWriterConfig(Version.LATEST, analyzer); IndexWriter indexWriter = newIndexWriter(directory,config); for(File f : files.listFiles()) { // 文件名 String fileName = f.getName(); // 文件内容 @SuppressWarnings("deprecation") String fileContent = FileUtils.readFileToString(f); // 文件路径 String filePath = f.getPath(); // 文件大小 longfileSize = FileUtils.sizeOf(f); // 创建一个Document对象 Document document = newDocument(); // 向Document对象中添加域信息 // 参数:1、域的名称;2、域的值;3、是否存储; Field nameField = newTextField("name", fileName, Store.YES); Field contentField = newTextField("content", fileContent , Store.YES); // storedFiled默认存储 Field pathField = newStoredField("path", filePath); Field sizeField = newLongField("size", fileSize, Store.YES); // 将域添加到document对象中 document.add(nameField); document.add(contentField); document.add(pathField); document.add(sizeField); // 将信息写入到索引库中 indexWriter.addDocument(document); } indexWriter.close(); }}3)查询索引库
[Java] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
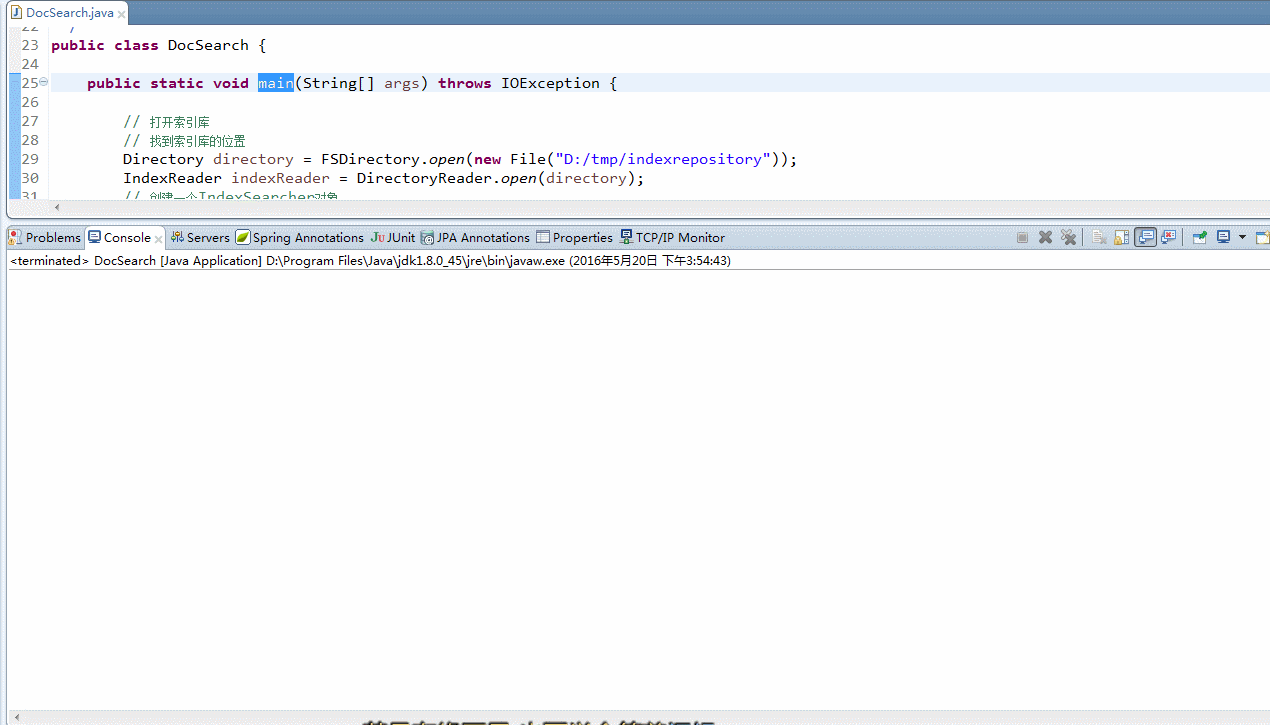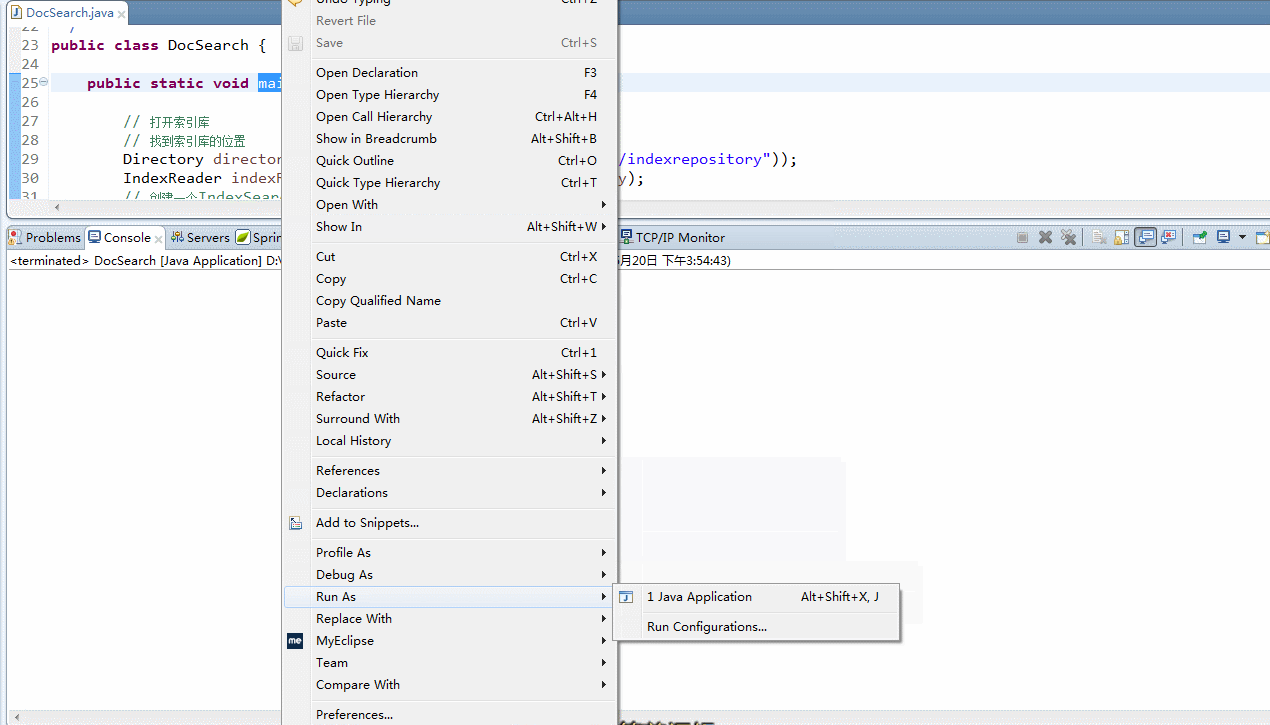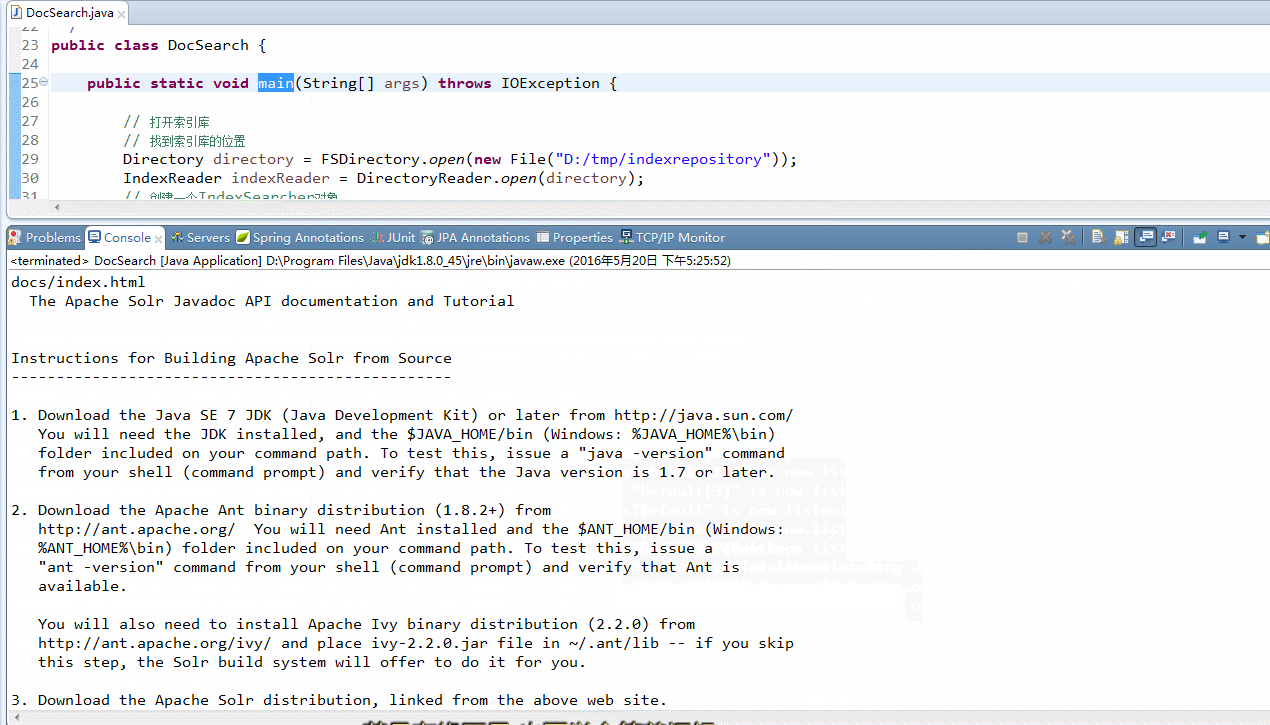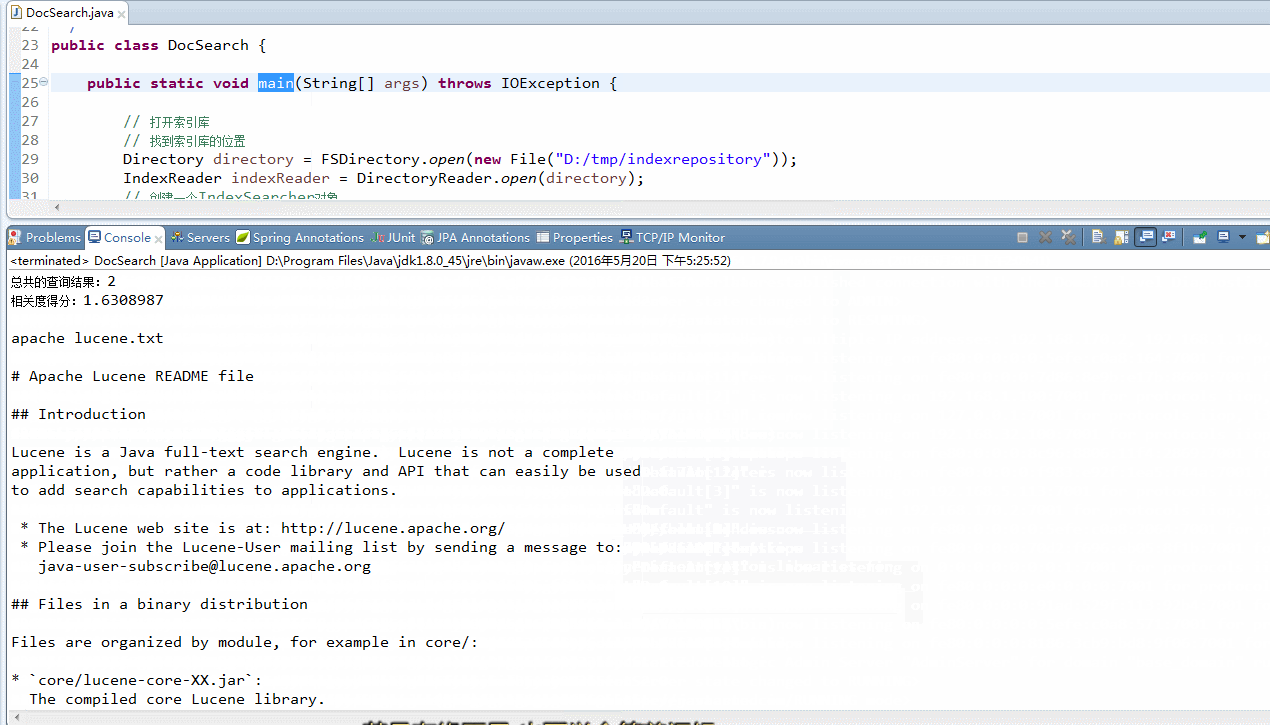
importjava.io.File;importjava.io.IOException;importorg.apache.lucene.document.Document;importorg.apache.lucene.index.DirectoryReader;importorg.apache.lucene.index.IndexReader;importorg.apache.lucene.index.Term;importorg.apache.lucene.search.IndexSearcher;importorg.apache.lucene.search.ScoreDoc;importorg.apache.lucene.search.TermQuery;importorg.apache.lucene.search.TopDocs;importorg.apache.lucene.store.Directory;importorg.apache.lucene.store.FSDirectory;/** * 文档搜索 * 通过关键词搜索文档 * */publicclass DocSearch { publicstatic void main(String[] args) throwsIOException { // 打开索引库 // 找到索引库的位置 Directory directory = FSDirectory.open(newFile("此处是索引文件存放地址")); IndexReader indexReader = DirectoryReader.open(directory); // 创建一个IndexSearcher对象 IndexSearcher indexSearcher = newIndexSearcher(indexReader); // 创建一个查询对象 TermQuery query = newTermQuery(newTerm("name","apache")); // 执行查询 // 返回的最大值,在分页的时候使用 TopDocs topDocs = indexSearcher.search(query, 5); // 取查询结果总数量 System.out.println("总共的查询结果:"+ topDocs.totalHits); // 查询结果,就是documentID列表 ScoreDoc[] scoreDocs = topDocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs) { // 取对象document的对象id intdocID = scoreDoc.doc; // 相关度得分 floatscore = scoreDoc.score; // 根据ID去document对象 Document document = indexSearcher.doc(docID); System.out.println("相关度得分:"+ score); System.out.println(""); System.out.println(document.get("name")); System.out.println(""); // 另外的一种使用方法 System.out.println(document.getField("content").stringValue()); System.out.println(document.get("path")); System.out.println(); System.out.println("======================="); } indexReader.close(); }}运行结果:
0 0
- Lucene全文搜索原理与使用
- Lucene全文搜索原理与使用
- Lucene全文搜索原理与使用
- 全文搜索 lucene使用与优化
- lucene:全文搜索的原理分析
- 使用Lucene.net 实现全文搜索
- 全文搜索lucene简介
- lucene全文搜索
- 全文搜索-Lucene
- Lucene全文搜索框架
- Lucene全文搜索学习
- Lucene全文搜索工具
- lucene 全文检索原理
- 全文检索Lucene使用与优化
- 全文检索技术与Lucene的使用
- 项目中用到的全文搜索(lucene与Compass)
- 全文搜索---Solr(它与lucene的关系)
- 使用Lucene进行全文检索(三)---进行搜索
- 我的android工作历程
- chrome安装插件,安装Postman
- 今天开始学习
- Elasticsearch 基础教程
- Centos7下安装php-redis扩展及简单使用
- Lucene全文搜索原理与使用
- TCP连接
- Android APK反编译必看
- 计算struct的大小
- Contiki协议栈Rime:包属性packetbuf_attr
- input框保留两位小数
- 为网上流行论点“UIAutomator不能通过中文文本查找控件”正名
- ASP.NET页面请求过程及生命周期管道事件
- iOS收到通知的相关内容


