一直没学透的贝叶斯
来源:互联网 发布:银行网络宣传总结报告 编辑:程序博客网 时间:2024/04/29 00:00
一直没学透的贝叶斯
本文是参考数学之美番外篇by刘未鹏写的,感觉说理特别清楚,mark一下,顺便写点自己的感受。
概率论只不过是把常识用数学公式表达了出来。
——拉普拉斯1.历史
托马斯·贝叶斯(Thomas Bayes)同学的详细生平在这里。以下摘一段 wikipedia 上的简介:
所谓的贝叶斯方法源于他生前为解决一个“逆概”问题写的一篇文章,而这篇文章是在他死后才由他的一位朋友发表出来的。在贝叶斯写这篇文章之前,人们已经能够计算“正向概率”,如“假设袋子里面有N个白球,M个黑球,你伸手进去摸一把,摸出黑球的概率是多大”。而一个自然而然的问题是反过来:“如果我们事先并不知道袋子里面黑白球的比例,而是闭着眼睛摸出一个(或好几个)球,观察这些取出来的球的颜色之后,那么我们可以就此对袋子里面的黑白球的比例作出什么样的推测”。这个问题,就是所谓的逆概问题。
我们日常所观察到的只是事物表面上的结果,沿用刚才那个袋子里面取球的比方,我们往往只能知道从里面取出来的球是什么颜色,而并不能直接看到袋子里面实际的情况。这个时候,我们就需要提供一个猜测(hypothesis,更为严格的说法是“假设”,这里用“猜测”更通俗易懂一点),所谓猜测,当然就是不确定的(很可能有好多种乃至无数种猜测都能满足目前的观测),但也绝对不是两眼一抹黑瞎蒙——具体地说,我们需要做两件事情:1. 算出各种不同猜测的可能性大小。2. 算出最靠谱的猜测是什么。第一个就是计算特定猜测的后验概率,对于连续的猜测空间则是计算猜测的概率密度函数。第二个则是所谓的模型比较,模型比较如果不考虑先验概率的话就是最大似然方法。
1.1 一个例子:自然语言的二义性
下面举一个自然语言的不确定性的例子。当你看到这句话:
The girl saw the boy with a telescope.
你对这句话的含义有什么猜测?平常人肯定会说:那个女孩拿望远镜看见了那个男孩(即你对这个句子背后的实际语法结构的猜测是:The girl saw-with-a-telescope the boy )。然而,仔细一想,你会发现这个句子完全可以解释成:那个女孩看见了那个拿着望远镜的男孩(即:The girl saw the-boy-with-a-telescope )。那为什么平常生活中我们每个人都能够迅速地对这种二义性进行消解呢?这背后到底隐藏着什么样的思维法则?我们留到后面解释。
1.2 贝叶斯公式
贝叶斯公式是怎么来的?
我们还是使用 wikipedia 上的一个例子:
一所学校里面有 60% 的男生,40% 的女生。男生总是穿长裤,女生则一半穿长裤一半穿裙子。有了这些信息之后我们可以容易地计算“随机选取一个学生,他(她)穿长裤的概率和穿裙子的概率是多大”,这个就是前面说的“正向概率”的计算。然而,假设你走在校园中,迎面走来一个穿长裤的学生(很不幸的是你高度近似,你只看得见他(她)穿的是否长裤,而无法确定他(她)的性别),你能够推断出他(她)是男生的概率是多大吗?
一些认知科学的研究表明(《决策与判断》以及《Rationality for Mortals》第12章:小孩也可以解决贝叶斯问题),我们对形式化的贝叶斯问题不擅长,但对于以频率形式呈现的等价问题却很擅长。
我们来算一算:假设学校里面人的总数是 U 个。60% 的男生都穿长裤,于是我们得到了 U * P(Boy) * P(Pants|Boy) 个穿长裤的(男生)(其中 P(Boy) 是男生的概率 = 60%,这里可以简单的理解为男生的比例;P(Pants|Boy) 是条件概率,即在 Boy 这个条件下穿长裤的概率是多大,这里是 100% ,因为所有男生都穿长裤)。40% 的女生里面又有一半(50%)是穿长裤的,于是我们又得到了 U * P(Girl) * P(Pants|Girl) 个穿长裤的(女生)。加起来一共是 U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl) 个穿长裤的,其中有 U * P(Girl) * P(Pants|Girl) 个女生。两者一比就是你要求的答案。
下面我们把这个答案形式化一下:我们要求的是 P(Girl|Pants) (穿长裤的人里面有多少女生),我们计算的结果是 U * P(Girl) * P(Pants|Girl) / [U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl)] 。容易发现这里校园内人的总数是无关的,可以消去。于是得到:
P(Girl|Pants) = P(Girl) * P(Pants|Girl) / [P(Boy) * P(Pants|Boy) + P(Girl) * P(Pants|Girl)]
注意,如果把上式收缩起来,分母其实就是 P(Pants) ,分子其实就是 P(Pants, Girl) 。而这个比例很自然地就读作:在穿长裤的人( P(Pants) )里面有多少(穿长裤)的女孩( P(Pants, Girl) )。
上式中的 Pants 和 Boy/Girl 可以指代一切东西,所以其一般形式就是:
P(B|A) = P(A|B) * P(B) / [P(A|B) * P(B) + P(A|~B) * P(~B) ]
收缩起来就是:
P(B|A) = P(AB) / P(A)
其实这个就等于:
P(B|A) * P(A) = P(AB)
难怪拉普拉斯说概率论只是把常识用数学公式表达了出来。
2. 拼写纠正
经典著作《人工智能:现代方法》的作者之一 Peter Norvig 曾经写过一篇介绍如何写一个拼写检查/纠正器的文章,里面用到的就是贝叶斯方法,这里我们不打算复述他写的文章,而是简要地将其核心思想介绍一下。
首先,我们需要询问的是:“问题是什么?”
问题是我们看到用户输入了一个不在字典中的单词,我们需要去猜测:“这个家伙到底真正想输入的单词是什么呢?”用刚才我们形式化的语言来叙述就是,我们需要求:
P(我们猜测他想输入的单词 | 他实际输入的单词)
这个概率。并找出那个使得这个概率最大的猜测单词。显然,我们的猜测未必是唯一的,就像前面举的那个自然语言的歧义性的例子一样;这里,比如用户输入: thew ,那么他到底是想输入 the ,还是想输入 thaw ?到底哪个猜测可能性更大呢?幸运的是我们可以用贝叶斯公式来直接出它们各自的概率,我们不妨将我们的多个猜测记为 h1 h2 .. ( h 代表 hypothesis),它们都属于一个有限且离散的猜测空间 H (单词总共就那么多而已),将用户实际输入的单词记为 D ( D 代表 Data ,即观测数据),于是
P(我们的猜测1 | 他实际输入的单词)
可以抽象地记为:
P(h1 | D)
类似地,对于我们的猜测2,则是 P(h2 | D)。不妨统一记为:
P(h | D)
运用一次贝叶斯公式,我们得到:
P(h | D) = P(h) * P(D | h) / P(D)
对于不同的具体猜测 h1 h2 h3 .. ,P(D) 都是一样的,所以在比较 P(h1 | D) 和 P(h2 | D) 的时候我们可以忽略这个常数。即我们只需要知道:
P(h | D) ∝ P(h) * P(D | h)
这个式子的抽象含义是:对于给定观测数据,一个猜测是好是坏,取决于“这个猜测本身独立的可能性大小(先验概率,Prior )”和“这个猜测生成我们观测到的数据的可能性大小”(似然,Likelihood )的乘积。具体到我们的那个 thew 例子上,含义就是,用户实际是想输入 the 的可能性大小取决于 the 本身在词汇表中被使用的可能性(频繁程度)大小(先验概率)和 想打 the 却打成 thew 的可能性大小(似然)的乘积。
一点注记:Norvig 的拼写纠正器里面只提取了编辑距离为 2 以内的所有已知单词。这是为了避免去遍历字典中每个单词计算它们的 P(h) * P(D | h) ,但这种做法为了节省时间带来了一些误差。但话说回来难道我们人类真的会去遍历每个可能的单词来计算他们的后验概率吗?不可能。实际上,根据认知神经科学的观点,我们首先根据错误的单词做一个 bottom-up 的关联提取,提取出有可能是实际单词的那些候选单词,这个提取过程就是所谓的基于内容的提取,可以根据错误单词的一些模式片段提取出有限的一组候选,非常快地缩小的搜索空间(比如我输入 explaination ,单词里面就有充分的信息使得我们的大脑在常数时间内把可能性 narrow down 到 explanation 这个单词上,至于具体是根据哪些线索——如音节——来提取,又是如何在生物神经网络中实现这个提取机制的,目前还是一个没有弄清的领域)。然后,我们对这有限的几个猜测做一个 top-down 的预测,看看到底哪个对于观测数据(即错误单词)的预测效力最好,而如何衡量预测效率则就是用贝叶斯公式里面的那个 P(h) * P(D | h) 了。
3. 模型比较与奥卡姆剃刀
(这个剃刀看起来很厉害)
3.1 再访拼写纠正
介绍了贝叶斯拼写纠正之后,接下来的一个自然而然的问题就来了:“为什么?”为什么要用贝叶斯公式?为什么贝叶斯公式在这里可以用?我们可以很容易地领会为什么贝叶斯公式用在前面介绍的那个男生女生长裤裙子的问题里是正确的。但为什么这里?
为了回答这个问题,一个常见的思路就是想想:非得这样吗?因为如果你想到了另一种做法并且证明了它也是靠谱的,那么将它与现在这个一比较,也许就能得出很有价值的信息。那么对于拼写纠错问题你能想到其他方案吗?
不管怎样,一个最常见的替代方案就是,选择离 thew 的编辑距离最近的。然而 the 和 thaw 离 thew 的编辑距离都是 1 。这可咋办捏?你说,不慌,那还是好办。我们就看到底哪个更可能被错打为 thew 就是了。我们注意到字母 e 和字母 w 在键盘上离得很紧,无名指一抽筋就不小心多打出一个 w 来,the 就变成 thew 了。而另一方面 thaw 被错打成 thew 的可能性就相对小一点,因为 e 和 a 离得较远而且使用的指头相差一个指头(一个是中指一个是小指,不像 e 和 w 使用的指头靠在一块——神经科学的证据表明紧邻的身体设施之间容易串位)。OK,很好,因为你现在已经是在用最大似然方法了,或者直白一点,你就是在计算那个使得 P(D | h) 最大的 h 。
而贝叶斯方法计算的是什么?是 P(h) * P(D | h) 。多出来了一个 P(h) 。我们刚才说了,这个多出来的 P(h) 是特定猜测的先验概率。为什么要掺和进一个先验概率?刚才说的那个最大似然不是挺好么?很雄辩地指出了 the 是更靠谱的猜测。有什么问题呢?既然这样,我们就从给最大似然找茬开始吧——我们假设两者的似然程度是一样或非常相近,这样不就难以区分哪个猜测更靠谱了吗?比如用户输入tlp ,那到底是 top 还是 tip ?(这个例子不怎么好,因为 top 和 tip 的词频可能仍然是接近的,但一时想不到好的英文单词的例子,我们不妨就假设 top 比 tip 常见许多吧,这个假设并不影响问题的本质。)这个时候,当最大似然不能作出决定性的判断时,先验概率就可以插手进来给出指示——“既然你无法决定,那么我告诉你,一般来说 top 出现的程度要高许多,所以更可能他想打的是 top ”)。
以上只是最大似然的一个问题,即并不能提供决策的全部信息。
最大似然还有另一个问题:即便一个猜测与数据非常符合,也并不代表这个猜测就是更好的猜测,因为这个猜测本身的可能性也许就非常低。比如 MacKay 在《Information Theory : Inference and Learning Algorithms》里面就举了一个很好的例子:-1 3 7 11 你说是等差数列更有可能呢?还是 -X^3 / 11 + 9/11*X^2 + 23/11 每项把前项作为 X 带入后计算得到的数列?此外曲线拟合也是,平面上 N 个点总是可以用 N-1 阶多项式来完全拟合,当 N 个点近似但不精确共线的时候,用 N-1 阶多项式来拟合能够精确通过每一个点,然而用直线来做拟合/线性回归的时候却会使得某些点不能位于直线上。你说到底哪个好呢?多项式?还是直线?一般地说肯定是越低阶的多项式越靠谱(当然前提是也不能忽视“似然”P(D | h) ,明摆着一个多项式分布您愣是去拿直线拟合也是不靠谱的,这就是为什么要把它们两者乘起来考虑。),原因之一就是低阶多项式更常见,先验概率( P(h) )较大(原因之二则隐藏在 P(D | h) 里面),这就是为什么我们要用样条来插值,而不是直接搞一个 N-1 阶多项式来通过任意 N 个点的原因。
以上分析当中隐含的哲学是,观测数据总是会有各种各样的误差,比如观测误差(比如你观测的时候一个 MM 经过你一不留神,手一抖就是一个误差出现了),所以如果过分去寻求能够完美解释观测数据的模型,就会落入所谓的数据过拟合(overfitting)的境地,一个过拟合的模型试图连误差(噪音)都去解释(而实际上噪音又是不需要解释的),显然就过犹不及了。所以 P(D | h) 大不代表你的 h (猜测)就是更好的 h。还要看 P(h) 是怎样的。所谓奥卡姆剃刀精神就是说:如果两个理论具有相似的解释力度,那么优先选择那个更简单的(往往也正是更平凡的,更少繁复的,更常见的)。
3.2 模型比较理论(Model Comparison)与贝叶斯奥卡姆剃刀(Bayesian Occam’s Razor)
实际上,模型比较就是去比较哪个模型(猜测)更可能隐藏在观察数据的背后。其基本思想前面已经用拼写纠正的例子来说明了。我们对用户实际想输入的单词的猜测就是模型,用户输错的单词就是观测数据。我们通过:
P(h | D) ∝ P(h) * P(D | h)
来比较哪个模型最为靠谱。前面提到,光靠 P(D | h) (即“似然”)是不够的,有时候还需要引入 P(h) 这个先验概率。奥卡姆剃刀就是说 P(h) 较大的模型有较大的优势,而最大似然则是说最符合观测数据的(即 P(D | h) 最大的)最有优势。整个模型比较就是这两方力量的拉锯。我们不妨再举一个简单的例子来说明这一精神:你随便找枚硬币,掷一下,观察一下结果。好,你观察到的结果要么是“正”,要么是“反”(不,不是少林足球那枚硬币:P ),不妨假设你观察到的是“正”。现在你要去根据这个观测数据推断这枚硬币掷出“正”的概率是多大。根据最大似然估计的精神,我们应该猜测这枚硬币掷出“正”的概率是 1 ,因为这个才是能最大化 P(D | h) 的那个猜测。然而每个人都会大摇其头——很显然,你随机摸出一枚硬币这枚硬币居然没有反面的概率是“不存在的”,我们对一枚随机硬币是否一枚有偏硬币,偏了多少,是有着一个先验的认识的,这个认识就是绝大多数硬币都是基本公平的,偏得越多的硬币越少见(可以用一个 beta 分布来表达这一先验概率)。将这个先验正态分布 p(θ) (其中 θ 表示硬币掷出正面的比例,小写的 p 代表这是概率密度函数)结合到我们的问题中,我们便不是去最大化 P(D | h) ,而是去最大化 P(D | θ) * p(θ) ,显然 θ = 1 是不行的,因为 P(θ=1) 为 0 ,导致整个乘积也为 0 。实际上,只要对这个式子求一个导数就可以得到最值点。
以上说的是当我们知道先验概率 P(h) 的时候,光用最大似然是不靠谱的,因为最大似然的猜测可能先验概率非常小。然而,有些时候,我们对于先验概率一无所知,只能假设每种猜测的先验概率是均等的,这个时候就只有用最大似然了。实际上,统计学家和贝叶斯学家有一个有趣的争论,统计学家说:我们让数据自己说话。言下之意就是要摒弃先验概率。而贝叶斯支持者则说:数据会有各种各样的偏差,而一个靠谱的先验概率则可以对这些随机噪音做到健壮。事实证明贝叶斯派胜利了,胜利的关键在于所谓先验概率其实也是经验统计的结果,譬如为什么我们会认为绝大多数硬币是基本公平的?为什么我们认为大多数人的肥胖适中?为什么我们认为肤色是种族相关的,而体重则与种族无关?先验概率里面的“先验”并不是指先于一切经验,而是仅指先于我们“当前”给出的观测数据而已,在硬币的例子中先验指的只是先于我们知道投掷的结果这个经验,而并非“先天”。
我们来看看 MacKay 在书中举的一个漂亮的例子: 
图中有多少个箱子?特别地,那棵书后面是一个箱子?还是两个箱子?还是三个箱子?还是.. 你可能会觉得树后面肯定是一个箱子,但为什么不是两个呢?如下图: 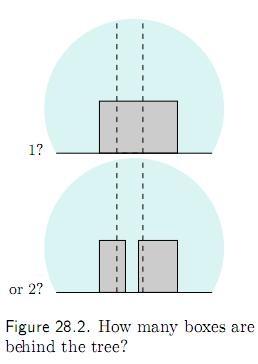
很简单,你会说:要是真的有两个箱子那才怪了,怎么就那么巧这两个箱子刚刚好颜色相同,高度相同呢?
用概率论的语言来说,你刚才的话就翻译为:猜测 h 不成立,因为 P(D | h) 太小(太巧合)了。我们的直觉是:巧合(小概率)事件不会发生。所以当一个猜测(假设)使得我们的观测结果成为小概率事件的时候,我们就说“才怪呢,哪能那么巧捏?!”(之前没搞明白为什么 P(D | h) 太小,仔细考虑后发现自己的假设搞错了,这里的假设h应该是”树后面有两个箱子“”而不是“树后面有两个刚刚好颜色相同,高度相同的箱子”,也就是说自己给出了太强的假设,附加了额外的条件,若是我原先以为的那个强假设,这里P(D | h)应该也是一个较大的值。)
稍稍比较一下
P(D | h) 太小代表当前假设下,观测到情况D的概率非常小,是个小概率事件,那么假设h不成立。
P(D | h) 很大,但是P(h)很小,这是前面提到的过拟合情况,也是奥卡姆剃刀精神所反对的。
这两种是P(D | h) *P(h)较小的可能发生的情况,需要区分一下。
回应最开始的那个问题,现在我们可以回到那个自然语言二义性的例子,并给出一个完美的解释了:如果语法结构是 The girl saw the-boy-with-a-telecope 的话,怎么那个男孩偏偏手里拿的就是望远镜——一个可以被用来 saw-with 的东东捏?这也忒小概率了吧。他咋就不会拿本书呢?拿什么都好。怎么偏偏就拿了望远镜?所以唯一的解释是,这个“巧合”背后肯定有它的必然性,这个必然性就是,如果我们将语法结构解释为 The girl saw-with-a-telescope the boy 的话,就跟数据完美吻合了——既然那个女孩是用某个东西去看这个男孩的,那么这个东西是一个望远镜就完全可以解释了(不再是小概率事件了)。
注意,以上做的是似然估计(即只看 P(D | h) 的大小),不含先验概率。通过这两个例子,尤其是那个树后面的箱子的例子我们可以看到,似然估计里面也蕴含着奥卡姆剃刀:树后面的箱子数目越多,这个模型就越复杂。单个箱子的模型是最简单的。似然估计选择了更简单的模型。
这个就是所谓的贝叶斯奥卡姆剃刀(Bayesian Occam’s Razor),因为这个剃刀工作在贝叶斯公式的似然(P(D | h) )上,而不是模型本身( P(h) )的先验概率上,后者是传统的奥卡姆剃刀。关于贝叶斯奥卡姆剃刀我们再来看一个前面说到的曲线拟合的例子:如果平面上有 N 个点,近似构成一条直线,但绝不精确地位于一条直线上。这时我们既可以用直线来拟合(模型1),也可以用二阶多项式(模型2)拟合,也可以用三阶多项式(模型3),.. ,特别地,用 N-1 阶多项式便能够保证肯定能完美通过 N 个数据点。那么,这些可能的模型之中到底哪个是最靠谱的呢?前面提到,一个衡量的依据是奥卡姆剃刀:越是高阶的多项式越是繁复和不常见。然而,我们其实并不需要依赖于这个先验的奥卡姆剃刀,因为有人可能会争辩说:你怎么就能说越高阶的多项式越不常见呢?我偏偏觉得所有阶多项式都是等可能的。好吧,既然如此那我们不妨就扔掉 P(h) 项,看看 P(D | h) 能告诉我们什么。我们注意到越是高阶的多项式,它的轨迹弯曲程度越是大,到了八九阶简直就是直上直下,于是我们不仅要问:一个比如说八阶多项式在平面上随机生成的一堆 N 个点偏偏恰好近似构成一条直线的概率(即 P(D | h) )有多大?太小太小了。反之,如果背后的模型是一条直线,那么根据该模型生成一堆近似构成直线的点的概率就大得多了。这就是贝叶斯奥卡姆剃刀。
原文链接:http://mindhacks.cn/2008/09/21/the-magical-bayesian-method/
- 一直没学透的贝叶斯
- 一直的我
- 一直的期待
- 一直的心愿...
- 一直的痛,英语
- 一直的痛,英语
- 一直走,勇敢的
- 一直很喜欢的 .bat
- 一直滚动的TextView
- 一直的没思想
- 一直滚动的TextView
- 一直
- 开始的一直的胡思乱想
- 一直困扰我的事!!!
- 我一直很自卑的
- 一直追求爱的女孩
- 一直搞不懂的 sigpromask ()
- 让我一直感动的
- javascript 闭包详解+示例(一)
- 图像拼接
- MYSQL添加新用户 MYSQL为用户创建数据库 MYSQL为新用户分配权限
- Android之权重
- hibernat异常:Unable to get the default Bean Validation factory
- 一直没学透的贝叶斯
- css之!important最高优先级
- Matlab保留ROI区域,并将非ROI区域颜色置0
- action重定向
- Androi之 9patch图详解
- LeetCode 144. Binary Tree Preorder Traversal(二叉树前缀遍历)
- Java开发中的23种设计模式详解之三:11种行为型模式
- 理解矩阵乘法
- HTML入门


