AUC、ROC、ACC区别
来源:互联网 发布:手机淘宝虚拟试衣间 编辑:程序博客网 时间:2024/05/16 06:28
很多时候我们都用到ROC(receiver operating characteristic curve,受试者工作特征曲线)和AUC(Area Under Curve,被定义为ROC曲线下的面积)来评判一个二值分类器的优劣,其实AUC跟ROC息息相关,AUC就是ROC曲线下部分的面积,所以需要首先知道什么是ROC,ROC怎么得来的。然后我们要知道一般分类器会有个准确率ACC,那么既然有了ACC,为什么还要有ROC呢,ACC和ROC的区别又在哪儿,这是我喜欢的一种既生瑜何生亮问题。
最后又简单说明了一下有了ROC之后,为什么还要有AUC呢
ROC简介
ROC曲线的横坐标为false positive rate(FPR)即负类样本中被判定为正类的比例,也就是传说中的误纳率
纵坐标为true positive rate(TPR)即正类样本中被判定为正类的样本,1-TPR也就是传说中的误拒率
接下来我们考虑ROC曲线图中的四个点和一条线。
第一个点,(0,1),即左上角的点,在这个点意味着FPR=0,TPR=1,稍微翻译一下就是误纳率为0,误拒率为0,再翻译成人话就是负类样本中被判断为正类的比例为0,说明负类样本都被判断为负类,判断正确,正类样本中被判断为正类的比例为1,说明正类样本都被判断正确,所以这是一个完美的分类器,它将所有的样本都正确分类。
第二个点,(1,0),即右下角的点,在这个点意味着FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确分类。把该判断为正类的判断为负类,把该判断为负类的判断为正类
第三个点,(0,0),即左下角的点,在这个点意味着FPR=TPR=0,可以发现该分类器预测所有的样本都为负样本(negative),在后面我们可以看到这种情况说明阈值选得过高。
第四个点(1,1),即右下角的点,分类器实际上预测所有的样本都为正样本,在后面我们可以看到这种情况说明阈值选得过低。
如何画ROC曲线
由于每次从分类模型中只能得到一个用于判定分类结果的分数,要将这个分数与一个阈值进行比较,判定这个样本属于哪个类,所以我们可以更改阈值,得到不同的分类结果,也就是不同的TPR和FPR
之前说到当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点
将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。
既然有了ACC为什么要有ROC呢(既生瑜何生亮呢)
我们知道,我们常用ACC准确率来判断分类器分类结果的好坏,既然有了ACC为什么还需要ROC呢,很重要的一个因素是实际的样本数据集中经常会出现数据偏斜的情况,要么负类样本数大于正类样本数,要么正类样本数大于负类样本数。
比如说我负类样本数有9,000个,正类样本数有100个,如果阈值选得过高,正类样本都判断为负类,同样负类样本都判定为负类,那么准确率90%,看起来还不错,但是如果考虑ROC中的TPR和FPR的话就会知道,此时的TPR=0,FPR=0,也就是误纳率是0,但是误拒率是100%,是左下角的点,并不是很好的一个点,而原来的ACC就不具有代表性
既然有了ROC为什么要有AUC呢(既生瑜何生亮呢)
使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而相对于AUC是个数值而言,对应AUC更大的分类器效果更好,数值更好判断一些。
很多时候我们都用到ROC和AUC来评判一个二值分类器的优劣,其实AUC跟ROC息息相关,AUC就是ROC曲线下部分的面积,所以需要首先知道什么是ROC,ROC怎么得来的。然后我们要知道一般分类器会有个准确率ACC,那么既然有了ACC,为什么还要有ROC呢,ACC和ROC的区别又在哪儿,这是我喜欢的一种既生瑜何生亮问题。
最后又简单说明了一下有了ROC之后,为什么还要有AUC呢
顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的performance。
AUC的计算方法总结:
(AUC的值就是计算出ROC曲线下面的面积)
直接计算AUC是很麻烦的,所以就使用了AUC的一个性质(它和Wilcoxon-Mann-Witney Test是等价的)来进行计算。Wilcoxon-Mann-Witney Test就是测试任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score。有了这个定义,我们就得到了另外一中计算AUC的办法:得到这个概率。
方法一:统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以MN。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)。
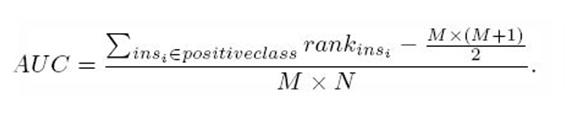
第二种方法实际上和上述方法是一样的,但是复杂度减小了。它也是首先对score从大到小排序,然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。然后把所有的正类样本的rank相加,再减去正类样本的score为最 小的那M个值的情况。得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。然后再除以M×N。即
AUC=((所有的正例位置相加)-M*(M+1))/(M*N)
另外,特别需要注意的是,再存在score相等的情况时,对相等score的样本,需要 赋予相同的rank(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是再把所有这些score相等的样本 的rank取平均。然后再使用上述公式。
- AUC、ROC、ACC区别
- 人脸认证-ROC曲线绘制计算AUC和ACC
- 数据挖掘-分类器的ROC曲线及相关指标(ROC、AUC、ACC)详解
- auc-roc
- AUC & ROC
- AUC ROC
- ROC and AUC
- ROC曲线,AUC,
- ROC 和 AUC
- ROC曲线与AUC
- PR,ROC,AUC计算方法
- ROC和AUC简介
- AUC与ROC
- ROC 和 AUC
- ROC和AUC介绍
- AUC与ROC
- ROC曲线与AUC
- ROC AUC详解
- CS231n 卷积神经网络与计算机视觉 3 最优化与随机梯度下降
- Android进阶——启动内置APK和动态发送接收自定义广播
- hibernate--HQL语法与详细解释
- too many positional arguments
- mybatis注解方式进行批量插入
- AUC、ROC、ACC区别
- PyCharm: Simplify chained comparison
- Android利用Fiddler进行网络数据抓包
- android 事件分发机制,最简单详解
- 生活用药记录
- 段落首行缩进 for CSDN 博客编辑器
- Unreal Engine 4 —— 使用反汇编来确定该进行优化的地方
- before和after的使用
- android基本架构


