IO流解析
来源:互联网 发布:中日高铁争夺战 知乎 编辑:程序博客网 时间:2024/05/18 03:47
前言
前阵子打算看看netty,结果在跑用例的时候,一直搞不清netty是怎么封装数据传输的,想想自己对Java IO的理解也确实不够,所以又回去看了看Java IO,尤其是流部分的源码,遂成此文。
内容简介
本文主要介绍Java IO包中,流部分的类结构及主要类的实现,由于JDK1.4之后IO包有部分类重新用NIO实现过,所以也会牵涉到NIO包的部分类,但对整个NIO包暂不做深究。IO包中的序列化部分也不在本文讨论范围之类。
背景知识
装饰器设计模式
适配器设计模式
IO包简要类图
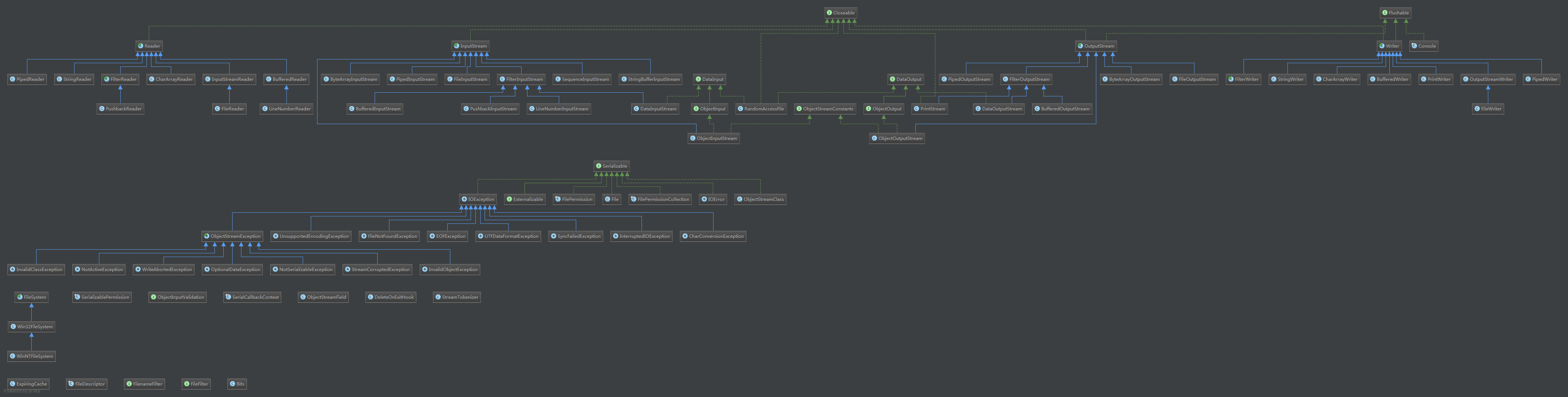
图很宽。。。直接生成的整个IO包的类图。其中的LineNumberInputStream已废弃(我想面向字节的流中根本不需要有“行”的概念)。
简单的说,Java I/O流部分分为两个模块,即Java1.0中就有的面向字节的流(Stream),以及Java1.1中大幅改动添加的面向字符的流(Reader & Writer)。添加面向字符的流主要是为了支持国际化,旧的I/O流仅支持8位的字节流,并不能很好的处理16位的Unicode字符(Java的基础类型char也是16位的Unicode)。
面向字节的流
InputStream(OutputStream)是所有面向字节流的基类。它的子类分为两大块,一是诸如ByteArrayInputStream(ByteArrayOutputStream),FileInputStream(FileOutputStream)等等面向各种不同的输入(输出)源的子类,另一块为了方便流操作的而进一步封装的装饰器系列FilterInputStream(FilterOutputStream)类及其子类。
BufferedInputStream
先讨论最重要的带缓冲区的流。IO、NIO包中所有 BufferedXXX 的实现方式都差不多,不过由于作者不尽相同,所以变量名各种不一样。。。但是理解了一种其余的也就好办了。下面以BufferedInputStream为例。
BufferedInputStream继承自FilterInputStream,在其内部维护一个字节数组作为缓冲区,而从底层流中读取数据的操作还是调用InputStream的方法完成。
缓冲区的控制变量:
- protected int count; //缓冲区中的第一个无效字符位置(有效数据长度 = count - pos)
- protected int pos; //当前位置(指向下一个待读取字符,而不是已读取的最后一个字符)
- protected int markpos = -1; //mark位置(mark和marklimit都是为了支持重读(reset & read)操作)
- protected int marklimit; //允许重读(reset & read)的最大长度
我们主要看看其中的fill, read, skip方法:
fill:填满缓冲区。本来是非常简单的操作,即一次从输入流中读取buf.length个字节过来。但是因为要提供mark & reset操作,所以情况变得有些复杂。如果markpos有效(不为-1),那么fill方法会依次选择以下方式处理:
尝试将markpos之后的有效数据移到缓冲区开头,然后填充剩余缓冲区
尝试将缓冲区大小扩充至marklimit大小,然后填充剩余缓冲区
经过上面两次尝试之后还是发现,要读取的数据太多,marklimit太小,于是别无他法,丢弃markpos,重新填充缓冲区
read:读取字节。有了fill方法,读取就简单得多了。缓冲区中有数据就读缓冲区,没数据就调用fill填充。
skip:跳过字节。表面上看和read操作差不多,只是一个返回数据,而一个直接忽略,且skip方法也会触发fill操作。但实际行为有很大不同,而这一点在方法的文档上并未注明,完全是由于代码实现造成的这种不同。skip方法的步骤如下:
判断缓冲区中是否还有可用(已缓冲未读取)字节,假设还有avail个字节可用,则即使调用中指明的skip字节数 n > avail,最多也只会跳过avail个字节,不会再触发fill方法
若没有可用字节,则首先判断markpos是否有效。若markpos无效,那么直接调用底层流的skip()方法,跳过n个字节;但若markpos有效,则会且仅会触发一次fill方法,然后最多跳过新的可用字节
于是总结起来skip的效果就是:不知道会跳过多少个字节,而且在一次调用中不会丢弃markpos。所以使用的时候一定要判断skip的返回的实际跳过的字节数。恩,这是一个比read更不靠谱的方法。
源码参见:BufferedInputStream.java
BufferedOutputStream
相比之下缓冲输出流就简单很多,基本上write方法可以说明一切了:
在缓冲区(也是字节数组)写满之前调用write方法只是将数据复制到内部缓冲区;
在缓冲区写满之后,现将旧的数据写入到底层输出流,然后将新的数据暂存到缓冲区(新的数据并未同时写入)
于是flush方法也找到了存在的意义:将现有数据全部写入。
源码参见:BufferedOutputStream.java
FileInputStream & FileOutputStream
以文件为输入输出目标的类,其实也可以想象得到,读写本地文件的类追溯上去肯定是本地方法。所以当然它的一系列read(write)方法都是native的。这个以后如果以机会的话再研究。
目前能看到的辅助功能有:
- FileInputStream(FileOutputStream)利用ThreadLocal类来判断打开这个流的线程数(ThreadLocal中定义了一个two-sized ThreadLocalMap,具体原理待我看完HashMap再回来 /_\)。
- 都可以调用getChannel()方法,利用sun.nio.ch.FileChannelImpl类返回一个FileChannel对象,即可以将文件流转为通道操作。
读写文件的这一溜方法大都在sun.nio.ch和sun.misc包里,有兴趣的可以去看openjdk提供的源码,不过Java里面也是调用native方法,而且考虑到跨平台特性估计设计上也会更加复杂,所以推荐先去了解C的文件读写。
ByteArrayInputStream & ByteArrayOutputStream
这两个类在很多地方被翻译成内存输入(输出)流,当时俺就被这高大上的名字深深的折服了。
其实它们的功能、实现都非常简单,先把所有的数据全存到它内部的字节数组里,然后用这个数组来继续读写,这个时候底层流你就可以不用管了,爱关就关没有影响。
插播:ByteArrayInputStream vs BufferedInputStream
经常会有人把这两个类混在一起,于是特地在此比划一番。说到它们的区别,但实际上从类的组织结构上可以看出来,这两个类其实没有什么联系:一个是以内存中的字节数组为输入目标的类,一个是为了更好的操作字节输入流而提供的带有缓冲区的装饰器类。它们的使用目的本就不一样,只不过由于名字似曾相识,打扮得(实现方式)也差不多,所以经常被误认为两兄弟。这两兄弟的差距还是蛮大的:
ByteArrayInputStream需要在内部的保存流的所有数据,所以需要一个足够大的字节数组,但数组的容量是受JVM中堆空间大小限制的,更极端的情况,即使你为JVM分配了一个很大的空间,由于Java数组使用的是int型索引,所以你也猜到了,它还是会被限制在INT_MAX范围以内。在底层流数据全部保存到ByteArrayInputStream后,你就可以不用再管流,转而去从ByteArrayInputStream读取数据了。
而BufferedInputStream只会用一个有限大小的缓存数组保存底层流的一小部分数据,你在读取数据的时候其实还是在和底层流打交道,只不过BufferedInputStream为了满足你变幻莫测的读取要求提供了缓冲区,让你的读取操作更加犀利流畅。
所以总结起来,它们除了同样从InputStream派生而来,同样使用了字节数组(这是个经常发生的巧合)以外,没有任何联系。
DataInputStream & DataOutputStream
这两个类允许我们以基本类型的形式操作字节流,可以理解为一个基本数据类型到字节之间的映射转换。
例如我想要从输入流中读取一个int类型数据(4字节),那么就需要先读4个字节,然后按照每个字节在int中的位置作相应移位处理,就得到这4个字节所代表的int型数据了。
PushbackInputStream
这个类的功能其实比较隐晦(至少我一开始是理解错了)。按照字面意思理解,它应该是为了在读取一定量字节之后,允许我们调用unread方法,重读这部分字节。实现上,它的内部也有一个字节数组作缓冲,恩,看起来一切正常。
可是测试它的unread(byte[])方法的时候发现被坑了,调用unread(byte[])之后再读取,读到的其实是你push进去的这个字节数组。它其实没有想象的那么聪明,在调用unread(byte[])方法的时候,只是很萌的把你传给它的这个字节数组当成你之前读取的数据,把它直接复制到内部缓冲区里。
也就是说,完全是 push what, get what…
其他
ObjectInputStream(ObjectOutputStream)与Serializable接口等一起构成了Java的序列化机制,其中牵涉到对象数据的描述、保存与恢复,在此暂不讨论。
面向字符的流(Reader & Writer)
Reader(Writer)是所有面向字符的流的基类。它同样有为了适配各种不同输入源的子类如PipedReader(PipedWriter)、CharArrayReader(CharArrayWriter)等,其中的FileReader(FileWriter)类是直接继承自InputStreamReader(OutputStreamWriter)。故在此主要关注以Stream为输入输出的InputStreamReader(OutputStreamWriter)类,以及BufferedReader(BufferedWriter)等装饰器类。
BufferedReader & BufferedWriter
谈到这个类就不得不吐槽一下类的作者Mark Reinhold,其实这俩类的功能和BufferedInputStream(BufferedOutputStream)明显非常类似,只不过是面向字符和面向字节的区别,说得再直白一点,缓冲区一个是char[],一个是byte[],除了面向字符要处理换行符(’\r’,’\n’,’\r\n’)问题以外,基本一样。
但是这位哥明显重写了一遍,用的一堆新的变量名,BufferedReader对应到BufferedInputStream如下:
再对照两者输入中的fill()方法,以及输出中的write()方法,也会发现BufferedReader的一些不足之处。最明显的莫过于BufferedReader的write()方法:
- public void write(char cbuf[], int off, int len) throws IOException {
- …
- // assert(len < nChars);
- /*
- 这里明显写得过于复杂,估计这哥脑子糊掉了,参考 @Arthur van Hoff 版的 BufferedOutputStream.java 实现改写可以更清晰简洁:
- if(len + nChars > cb.length) { //无缓存空间,flush
- flushBuffer();
- }
- System.arraycopy(cbuf, off, cb, nextChar, len); //将新数据保存到buffer(并没有立即写入)
- nChars += len;
- */
- int b = off, t = off + len;
- while (b < t) {
- int d = min(nChars - nextChar, t - b);
- System.arraycopy(cbuf, b, cb, nextChar, d);
- b += d;
- nextChar += d;
- if (nextChar >= nChars)
- flushBuffer();
- }
- }
而且这位哥还为在BufferedReader中为markedChar提供了两种无效状态,一种是UNMARKED(-1),另一种是INVALIDATED(-2),而这俩状态的唯一意义就是在调用reset发现状态无效的时候,能够打出两种不同的错误消息”Stream not marked”(从未调用过mark方法)和”Mark invalid”(mark位置无效),真是徒增烦恼。。。
不过这位哥和JSR-51 Expert Group出品的其他NIO类还是非常清晰简洁的,他好像还在继续开发JavaSE8。。。不过代码果然还是要让别人看看改改才好啊。
吐完槽说正事,BufferedReader中的readline方法(注意DataInputStream中的readline已废弃),先在缓冲区中的可用数据里找回车(‘\r’)或换行(‘\n’),没找着就继续读数据、填缓冲区,直到天荒地老 直到内存溢出。已读取的数据会存到一个StringBuffer对象中。
Reader & java.nio.Buffer
为什么这里要扯到nio包中的Buffer?主要是Reader这个基类里提供了一个把字符读到java.nio.CharBuffer类的read方法。于是我就很不淡定的跳到了CharBuffer,跳到了Buffer,最后跳到了ByteBuffer这个NIO网络传输中出镜率最高的类。实际上它们的实现方式与BufferedInputStream这些也都非常相似,于是一并在这里写出来。
NIO包数据处理部分的类图

Buffer
与BufferedInputStream相似,用同样的变量控制buf的读取,不过变量名也不同
可以看出一点区别,即Buffer类中没有marklimit(重读数量)限制。那么Buffer用什么来限制重读数据数量呢?答案就是缓冲区数组的固有长度capacity。与之前的BufferedInputStream和BufferedReader都不同,Buffer内部的缓冲区大小是定义对象的时候就已经确定且不可更改的,不会随着数据增长。所以对于Buffer类来说,各个控制变量之间有严格的如下关系:
mark <= position <= limit <= capacity
除了limit(缓冲区中第一个无效位置)的字面意义比较隐晦以外,老板再也不用担心我搞混marklimit和buffer.length了!不过这也就要求程序员必须不断试验以确定一个合适的缓冲区大小,以达到良好的性能。
三种操作:
clear:清空缓冲区。设置 position = 0,limit = capacity,mark = -1。
flip:flip缓冲区(我可不敢译成翻转- -)。设置limit = position,position = 0,mark = -1。
用法:在往缓冲区内填入一些数据之后,flip buffer,然后调用write方法将数据写入流或者调用get方法取出缓冲区的数据。
rewind:回滚缓冲区。设置position = 0, mark = -1。
用法:调用write或者get方法读取缓冲区之后,rewind buffer,然后可以再次读取旧的数据。
堆缓冲区与直接缓冲区
类图中可以看到,Java提供了两种缓冲区的实现:HeapByteBuffer和DirectByteBuffer,其余都是一些适配器类。
HeapByteBuffer就是在Java堆中分配的字节数组;而DirectByteBuffer可以利用本地方法,产生一个与操作系统有更高耦合性的直接缓冲区并包装到Java字节数组中,也就是说我们可以直接用Java对象操作本地代码申请的空间。但直接缓冲区的分配开支会更大,且具体实现随操作系统而不同,所以使用直接缓冲区之后必须再次测试程序,已确定是否获得速度提高。
InputStreamReader & OutputStreamWriter
这是两个适配器类,目的就是为了转换字节与字符。
实现上,使用了sun.nio.cs包中的StreamDecoder(StreamEncoder),而这两个类都是使用java.nio.charset中的Charset(提供Unicode字符与相应字节的对应关系),以及CharsetDecoder,CharsetEncoder,ok到此打住,编码解码问题以后再说。。。
PrintWriter vs PrintStream
PrintWriter与PrintStream的区别,这也是一个被讨论过很多次的问题。
首先要注意到的一点就是PrintStream是面向字节,而PrintWriter是面向字符。这也就意味着PrintStrem想要以可显示的形式输出数据时,就需要自己处理从字节到字符的转码问题。以前的PrintStream只能使用平台默认的编码格式,而且还饱受诟病的使用平台相关的换行符,所以被无数次吐槽。而PrintWriter由于是面向字符,根本不考虑转码的问题,转而将转码独立出来交给其他代码处理。不过再看一眼最新的源码你也许会很惊讶,现在PrintStream内部竟然直接维护了一个BufferedWriter对象来执行具体的写操作,即执行了如下转换:OutputStream -> OutputStreamWriter -> BufferedWriter,这也算是曲线救国了吧。另外自JDK1.4之后PrintStream已经可以指定编码格式,勉强解决了编码问题,换行符问题也已解决)。
其次在设置了自动刷新时,它们的刷新时机不同。PrintStream会在写完一个byte数组、调用println方法,或是遇到一个换行符时刷新缓冲区;而PrintWriter只会在println、printf、format方法被调用时刷新。
另外一个共同的缺陷就是它们把读取时所有抛出的IOException都吃掉了- -||,你只能调用checkError来查看输出的时候是否出现了错误(true / false),而且这个error flag不能被重置,使用范围很有限。
PrintStream的文档里面写到在需要打印字符时应该使用PrintWriter而不是PrintStream,sun在提供PrintWriter时也希望它能够完全替代PrintStream,不过残酷的现实是PrintStream已经被太多的程序使用无法挽回,尤其是System.out也是PrintStream类型。。。所以sun才会继续修补PrintStream类中的问题。
不过修补始终是修补,如果你非要硬着头皮使用PrintStream,就需得时时刻刻记住为在新建时指定编码,否则它还是会按照平台默认编码工作,而考虑到其中直接write字节数组的方法意义也不大:
所以在需要将数据转为可显示形式的场景里:接受PrintWriter的指引吧,它会带你按时回家。
源码参见:PrintStream.java
结语
本来只打算看看Stream和Reader中BufferedInputStream等缓冲读取的实现,结果先是被Reader坑了去找NIO里的CharBuffer。然后写着写着发现只写传输不行,数据输入也是一大块,于是又去看FileInputStream,顺带把其他几个输入类也都看了眼,然后又转到Reader那块,结果就是博文写完IO包里除了序列化的都看了一遍,真是在鞭挞中成长。以后有时间再研究下NIO包里的通道、选择器这并发大头。。。
- java io 流解析
- IO流解析概述
- IO流解析
- Java IO流详尽解析
- Java IO流详尽解析
- Java的IO流解析
- Java IO流详尽解析
- Java IO流详尽解析
- Java IO流详尽解析
- Java IO流详尽解析
- Java IO流详尽解析
- java IO流详尽解析
- Java IO流详尽解析
- Java IO流详尽解析
- Java IO流详尽解析
- java IO流解析(一)
- java IO流解析(二)
- java IO流解析(三)
- windows下后门技术(netcat篇)
- 数据结构(C++)—— 向量(Vector)
- Python 中一些需要查询的东西
- 程序员的基本素质
- akka入门
- IO流解析
- Linux命令 -- 批量修改文件名
- Java 的数据类型
- bzoj1503 郁闷的出纳员
- LeetCode-54&59.Spiral Matrix
- Phaser.js事件系统及用户交互篇
- linux gcc编译过程
- 深入浅出 - Android系统移植与平台开发(八)- HAL Stub框架分析
- eclipse导入maven工程后更改默认JDK1.5的方法


