CS231n 卷积神经网络与计算机视觉 8 手把手实现神经网络分类
来源:互联网 发布:淘宝有信用卡套现的吗 编辑:程序博客网 时间:2024/06/04 21:02
本章将实现一个简单的两层神经网络,主要分两步走:
1. 实现线性分类器
2. 改变成神经网络
1 生成数据
我们先生成一个螺旋性的数据集,Python代码:
N = 100 # number of points per classD = 2 # dimensionalityK = 3 # number of classesX = np.zeros((N*K,D)) # data matrix (each row = single example)在二维平面内的300个点y = np.zeros(N*K, dtype='uint8') # class labels整数形式for j in xrange(K): ix = range(N*j,N*(j+1)) r = np.linspace(0.0,1,N) # radius t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta第一个linspace意为产生100个数,random是为了让这些角度分开 X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]#c_合并列 y[ix] = j# lets visualize the data:plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)#c代表颜色,s:scalar 大小 cmap:colormap改变了原始的颜色映射结果为 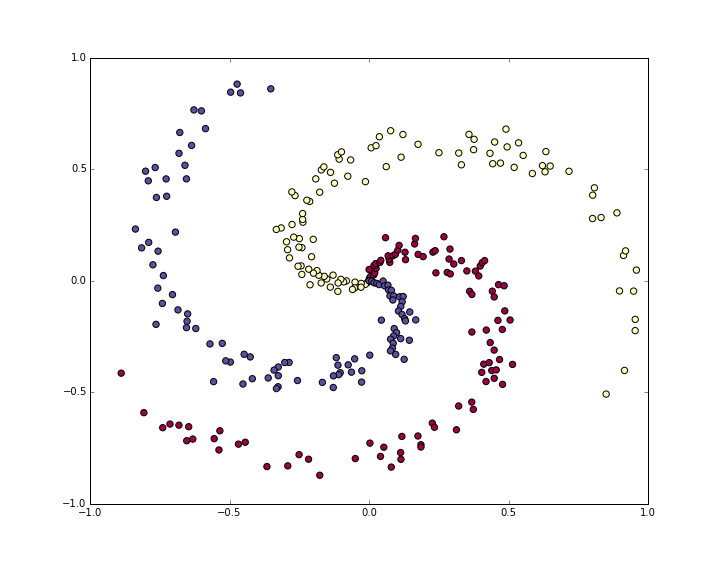
其中如果没有np.random.randn(N)*0.2得到是

2 预处理数据
这里因为比较简单,不需要进行预处理,预处理方法在这里。
3 训练Softmax线性分类器
3.1 初始化
根据之前softmax的知识,其损失函数为cross-entropy loss其中需要参数w和b,我们需要首先初始化参数。
# initialize parameters randomlyW = 0.01 * np.random.randn(D,K)#每一类需要两个w(因为在2维空间)2x3b = np.zeros((1,K))#每一类需要一个b 1x33.2 计算类别得分
# compute class scores for a linear classifierscores = np.dot(X, W) + b#300*2乘2*3得到300行3列的矩阵代表每个数据在三类中的得分300x2的X乘2x3W得到300行3列的矩阵代表每个数据在三类中的得分
3.3 建立损失函数
损失函数的建立是整个模型中重要的一节也是很难的一节,这里softmax的损失函数是cross-entropy loss,其公式如下,我们曾经从信息论和概率论角度来考虑他的含义,原文点这里。
概率论角度的理解比信息论角度要更直观些,括号内就是滴i类的概率,求-log就类似与求最大似然中的步骤,上面的f就是我们之前计算的得分函数。
括号内的分子是正确类别的得分,分母是所有类别的总得分,这样整个括号内的内容就是对正确类别的预测的概率,如果预测的是1那么完全正确,-log(1)=0,反之就会变成无穷大。所以让损失最小就可以得到最接近真实值的预测值。
另外loss函数有两部分 除了上面还有regression完整的结构如下:
首先我们先计算每个样本属于各个类别的概率:
# get unnormalized probabilitiesexp_scores = np.exp(scores)#这个score就是前面计算的300*3的矩阵# normalize them for each exampleprobs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)#注意这里面的参数axis和keepdims现在我们已经有了300个样本属于每一类的概率,这是一个300*3的矩阵。
现在可以计算-log概率了:
corect_logprobs = -np.log(probs[range(num_examples),y])#这里是选择了正确的那一列的概率,然后进行了-log运算 得到300x1个概率得到的上一步结果是一列向量,进一步计算data loss 并加入 regression loss
# compute the loss: average cross-entropy loss and regularizationdata_loss = np.sum(corect_logprobs)/num_examples#300个样本的得分平均值reg_loss = 0.5*reg*np.sum(W*W)#reg是惩罚因子lambdaloss = data_loss + reg_loss初始值我们是随便给的所以得到的预测的准确率可能是1/3,所以初始的loss可能是-log(1/3).
3.4 计算反向传播的梯度
这里又是一大难点,但是只要知道反向传播就是通过链式求导法则,慢慢来就可以得到结果,为了便于表示我们引入概率p:
损失函数只利用了正确类别的预测概率,所以我们我们需要计算的梯度公式(对于一个样本)如下:
经过计算可得到下列结果:
这就是说如果我们某一时刻计算的p是 [0.2, 0.3, 0.5],那么得分函数的梯度就是df = [0.2, -0.7, 0.5],我们可以直观的理解这一结果,沿着梯度的方向l是增大的,df的意思就是增加中间的得分,减小两侧的得分l就会减小。
下面是程序:
dscores = probsdscores[range(num_examples),y] -= 1dscores /= num_examples#300×3的矩阵dW = np.dot(X.T, dscores)#内积的形式得到的是2×3的矩阵db = np.sum(dscores, axis=0, keepdims=True)dW += reg*W # don't forget the regularization gradient3.5 更新参数
# perform a parameter updateW += -step_size * dWb += -step_size * db#注意要向着负梯度方向更新噢3.6 整合
#Train a Linear Classifier# initialize parameters randomlyW = 0.01 * np.random.randn(D,K)b = np.zeros((1,K))# some hyperparametersstep_size = 1e-0reg = 1e-3 # regularization strength# gradient descent loopnum_examples = X.shape[0]for i in xrange(200): # evaluate class scores, [N x K] scores = np.dot(X, W) + b # compute the class probabilities exp_scores = np.exp(scores) probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K] # compute the loss: average cross-entropy loss and regularization corect_logprobs = -np.log(probs[range(num_examples),y]) data_loss = np.sum(corect_logprobs)/num_examples reg_loss = 0.5*reg*np.sum(W*W) loss = data_loss + reg_loss if i % 10 == 0: print "iteration %d: loss %f" % (i, loss) # compute the gradient on scores dscores = probs dscores[range(num_examples),y] -= 1 dscores /= num_examples # backpropate the gradient to the parameters (W,b) dW = np.dot(X.T, dscores) db = np.sum(dscores, axis=0, keepdims=True) dW += reg*W # regularization gradient # perform a parameter update W += -step_size * dW b += -step_size * db我们得到的结果是
iteration 0: loss 1.096956iteration 10: loss 0.917265...........iteration 180: loss 0.786331iteration 190: loss 0.786302实际上运行到420次的时候得到最小的值
iteration 410: loss 0.762752iteration 420: loss 0.762751我们可以根据公式估算准确率
# evaluate training set accuracyscores = np.dot(X, W) + bpredicted_class = np.argmax(scores, axis=1)#返回最大值的列标print 'training accuracy: %.2f' % (np.mean(predicted_class == y))得到的结果是0.49
我们将结果可视化 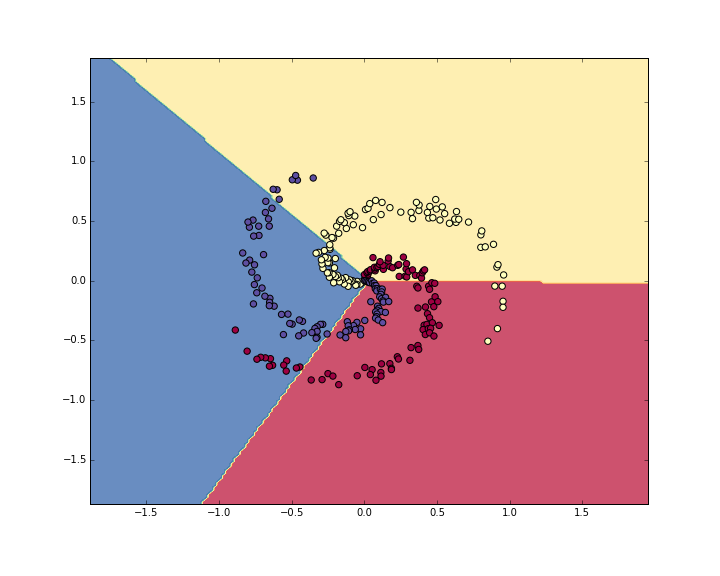
4 训练神经网络
以上结果可以看出线性分类器对非线性的分类结果不好,我们需要现在建立一个一层隐含层含100个隐藏神经单元的神经网络,那么这是一个两层神经网络,我们需要两套参数:

4.1 初始化数据:
# initialize parameters randomlyh = 100 # size of hidden layer=100个神经单元W = 0.01 * np.random.randn(D,h)#2*100个b = np.zeros((1,h))#100个W2 = 0.01 * np.random.randn(h,K)#100*3个b2 = np.zeros((1,K))#3个4.2 先前计算得分
一层一层剥开神经网络:
# evaluate class scores with a 2-layer Neural Networkhidden_layer = np.maximum(0, np.dot(X, W) + b) # note, ReLU activation如果不理解画一个神经网络连接下就行了scores = np.dot(hidden_layer, W2) + b24.3 计算反向梯度
依旧是链式求导
这里损失函数对得分函数的求导和前面是一样的,所以只需要按照4.2中的公式
w2和b2的梯度
# backpropate the gradient to the parameters# first backprop into parameters W2 and b2dW2 = np.dot(hidden_layer.T, dscores)db2 = np.sum(dscores, axis=0, keepdims=True)隐含层的梯度,注意经过激活函数的时候如果小于0那么梯度就直接等于0了
dhidden = np.dot(dscores, W2.T)# backprop the ReLU non-linearitydhidden[hidden_layer <= 0] = 0计算w,b梯度
# finally into W,bdW = np.dot(X.T, dhidden)db = np.sum(dhidden, axis=0, keepdims=True)这就算弄完了整合下:
# initialize parameters randomlyh = 100 # size of hidden layerW = 0.01 * np.random.randn(D,h)b = np.zeros((1,h))W2 = 0.01 * np.random.randn(h,K)b2 = np.zeros((1,K))# some hyperparametersstep_size = 1e-0reg = 1e-3 # regularization strength# gradient descent loopnum_examples = X.shape[0]for i in xrange(10000): # evaluate class scores, [N x K] hidden_layer = np.maximum(0, np.dot(X, W) + b) # note, ReLU activation scores = np.dot(hidden_layer, W2) + b2 # compute the class probabilities exp_scores = np.exp(scores) probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K] # compute the loss: average cross-entropy loss and regularization corect_logprobs = -np.log(probs[range(num_examples),y]) data_loss = np.sum(corect_logprobs)/num_examples reg_loss = 0.5*reg*np.sum(W*W) + 0.5*reg*np.sum(W2*W2) loss = data_loss + reg_loss if i % 1000 == 0: print "iteration %d: loss %f" % (i, loss) # compute the gradient on scores dscores = probs dscores[range(num_examples),y] -= 1 dscores /= num_examples # backpropate the gradient to the parameters # first backprop into parameters W2 and b2 dW2 = np.dot(hidden_layer.T, dscores) db2 = np.sum(dscores, axis=0, keepdims=True) # next backprop into hidden layer dhidden = np.dot(dscores, W2.T) # backprop the ReLU non-linearity dhidden[hidden_layer <= 0] = 0 # finally into W,b dW = np.dot(X.T, dhidden) db = np.sum(dhidden, axis=0, keepdims=True) # add regularization gradient contribution dW2 += reg * W2 dW += reg * W # perform a parameter update W += -step_size * dW b += -step_size * db W2 += -step_size * dW2 b2 += -step_size * db2结果是:
iteration 0: loss 1.098744iteration 1000: loss 0.294946iteration 2000: loss 0.259301iteration 3000: loss 0.248310iteration 4000: loss 0.246170iteration 5000: loss 0.245649iteration 6000: loss 0.245491iteration 7000: loss 0.245400iteration 8000: loss 0.245335iteration 9000: loss 0.245292估计结果:
# evaluate training set accuracyhidden_layer = np.maximum(0, np.dot(X, W) + b)scores = np.dot(hidden_layer, W2) + b2predicted_class = np.argmax(scores, axis=1)print 'training accuracy: %.2f' % (np.mean(predicted_class == y))得到98%的准确率
可视化结果: 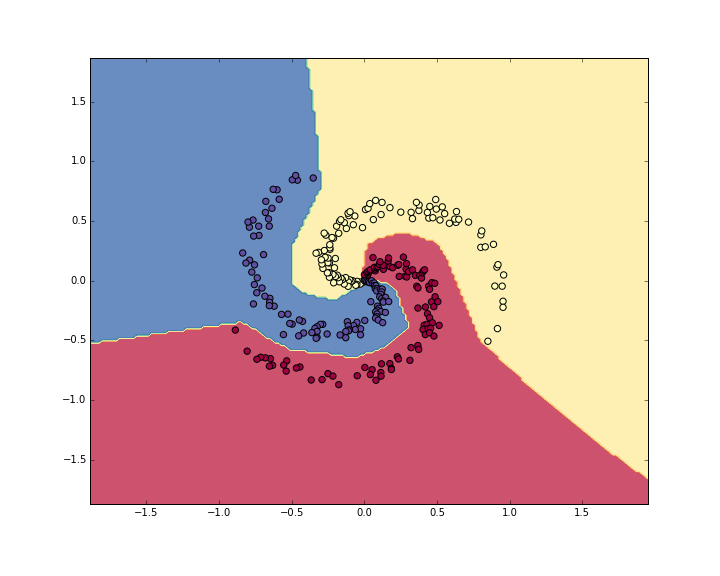

- CS231n 卷积神经网络与计算机视觉 8 手把手实现神经网络分类
- cs231n 卷积神经网络与计算机视觉 1 基础梳理与KNN图像分类
- cs231n 卷积神经网络与计算机视觉 2 SVM softmax
- CS231n 卷积神经网络与计算机视觉 9 卷积神经网络结构分析
- CS231n 卷积神经网络与计算机视觉 10 卷积神经网络学了些什么?
- CS231n 卷积神经网络与计算机视觉 11 卷积神经网络的 迁移学习 和微调
- 计算机视觉与卷积神经网络
- 计算机视觉与卷积神经网络
- cs231n 卷积神经网络与计算机视觉 5 神经网络基本结构 激活函数总结
- CS231n 卷积神经网络与计算机视觉 3 最优化与随机梯度下降
- cs231n 卷积神经网络与计算机视觉 4 Backpropagation 详解反向传播
- CS231n 卷积神经网络与计算机视觉 6 数据预处理 权重初始化 规则化 损失函数 等常用方法总结
- CS231n 卷积神经网络与计算机视觉 7 神经网络训练技巧汇总 梯度检验 参数更新 超参数优化 模型融合 等
- [cs231n]卷积神经网络的实现与理解(一)
- 深度学习与计算机视觉系列,细说卷积神经网络
- cs231n笔记(8)--卷积神经网络CNN
- 神经网络 与 卷积神经网络
- 卷积神经网络理解与实现
- Verilog编写VGA显示的小游戏
- 详解MySQL中DROP,TRUNCATE 和DELETE的区别实现mysql从零开始
- 《您的设计模式》(CBF4LIFE)之“代理模式”【整理】
- 大型门户网站架构分析
- mysql数据库导出导入
- CS231n 卷积神经网络与计算机视觉 8 手把手实现神经网络分类
- sigma.js框架初探
- 使用RxJava来改进用户体验
- 利用freemarker 静态化网页 多代码
- BZOJ 1202 带权并查集
- 关于画布反转问题
- 【Linux系列教程】01.在虚拟机中安装Centos7.0
- 《您的设计模式》(CBF4LIFE)之“单例模式”【整理】
- hdu-1317-XYZZY-Bellman-Ford判环、Floyd算法


