Hadoop 之 hive 学习
来源:互联网 发布:大陆单片机 编辑:程序博客网 时间:2024/05/21 10:51
Hive 是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 QL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作。
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据
HIVE支持数据更新,有限更新;支持列式数据库;
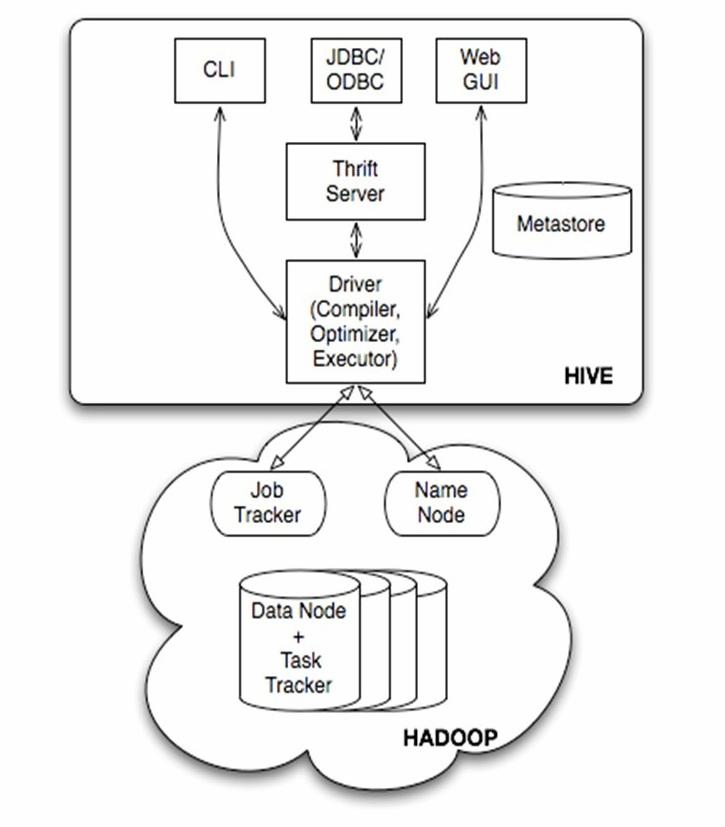
Hive的体系结构可以分为以下几部分:
(1)用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是CLI,Cli启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至Hive Server。在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。 WUI是通过浏览器访问Hive。
(2)Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
Hive将元数据存储在RDBMS中,
3. hive 与 mysql数据库
因为HIVE的元数据保存在MYSQL中,所以实际使用时需要在LINUX下安装和使用mysql数据库;
一,安装说明
按实验手册完成安装;
启动mysql时,使用root用户;
/etc/init.d/mysql restart //重启服务
service mysql status //查看状态;
进入mysql客户端,使用root用户,注意u和root之间没有空格;
mysql -uroot //初始安装后,root用户无密码,可以设置密码
或者mysql –uroot –p //使用密码登陆
二,使用mysql
查看内置用户, mysql数据库的user表(show tabes查看)。
在mysql下:
show databases; //包含系统数据库mysql
select Host, User, Password from mysql.user; //查看系统的用户表


新建mysql 用户hadoop(密码hadoop),并授权其在本机或者任何其他机器使用密码登陆,并可以操作任何数据库;注意,该字符的定界符,不是单引号’,而是`(键盘中,波浪线~键下方的按键);然后刷新权限。
mysql>grant all on *.* to hadoop@'%' identified by 'hadoop';
mysql>grant all on *.* to hadoop@'localhost' identified by 'hadoop';
mysql>grant all on *.* to hadoop@'master' identified by 'hadoop';
mysql>flush privileges;
在NAVICAT 工具中连接虚拟机数据库,要授权给root用户(允许其他其他机器访问本数据库);
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'zkpk' WITH GRANT OPTION;
FLUSH PRIVILEGES;
4. Hive QL 操 作
1, 内部表的建立和使用
create table stest(id int,name string) row format delimited fields terminated by ‘\t’;
describe stest;
//编辑文件testdata1(两个字段,以\t分隔, 输入几行数据),并上传(注意文件路径)到表中;
load data local inpath '/home/zkpk/testdata1' overwrite into table stest;
select * from stest;
2, 外部表的建立和使用
create external table stest_ext(id int,name string) row format delimited fields terminated by ‘\t’ location ‘/hive/ext’;
show create table stest_ext;
//编辑文件testdata2(两个字段,以\t分隔),并上传到表中;
load data local inpath '/home/zkpk/testdata2' overwrite into table stest_ext;
select * from stest_ext;
3, 分区表的建立和使用
create external table stest_par(id int,name string) partitioned by (class string) row format delimited fields terminated by ‘\t’ location ‘/hive/par’;
show create table stest_par;
//编辑文件testdata3(两个字段,以\t分隔),并上传到表中;
load data local inpath '/home/zkpk/testdata3' overwrite into table stest_par patition (class='A');
//编辑文件testdata4(两个字段,以\t分隔),并上传到表中;
load data local inpath '/home/zkpk/testdata4' overwrite into table stest_par patition (class='B');
dfs -cat /hive/par/testdata3;
select * from stest_par;
select * from stest_par a where a.class='A';
4 建Bucket表
5. Hive数据处理案例--搜狗搜索日志分析
1.数据和脚本程序(用于数据预处理)准备
使用SSH Secure File Transfer Client 将所需文件传到Linux虚拟机的本地目录
2.数据预处理
1.数据扩展
将日志记录的时间字段拆分,添加年,月,日,小时字段
进入脚本程序所在的文件目录,执行:bash sogou-log-extend.sh /home/sogou_data/sogou.500w.utf8 /home/sogou_data/sogou.500w.utf8.ext
2.数据过滤
过滤掉某几个字段为空的行(使用到数据扩展之后产生的数据)
进入脚本程序所在的文件目录,执行:bash sogou-log-extend.sh /home/sogou_data/sogou.500w.utf8.ext /home/sogou_data/sogou.500w.utf8.flt
3.基于Hive构建日志数据的数据仓库
首先在集群运行的环境下启动hive:启动命令 bin/hive,之后创建一个搜狗数据库:create database sogou
创建扩展4个字段(年,月,日,小时)数据的外部表
创建一个按年,月,日,小时分区的分区表
4.数据仓库建好之后就可以对数据进行分析了
1. 实现数据分析需求一:条数统计
1.数据总条数:
Select count(*) from sogou_flt;

2.独立uid总数:
Select count(distinct(uid)) from sogou_flt;

2.实现数据分析需求二:关键词分析
1.查询关键词长度统计:

2.查询频度排名(频度最高的前50词):
Selectkeyword, count(*) as cnt from sogou_flt group by keyword order by cnt keyworddesc limit 50;

总结:Hive是一个基于Hadoop文件系统之上的数据仓库架构,它为数据仓库的管理提供了许多功能:数据ETL(抽取,转换和加载)工具,数据存储管理和大型数据集的查询和分析能力。同时Hive定义了类SQL语言---Hive QL,Hive QL允许用户进行和SQL相似的操作,还允许开发人员方便的使用Mapper和Reducer操作。总之,Hive是一种数据仓库技术,用于查询,管理和分析存储在分布式存储系统上的海量结构化和非结构化的数据。
- Hadoop之hive学习
- Hadoop之hive学习
- Hadoop之hive学习
- hadoop学习之hive
- Hadoop之Hive学习
- Hadoop 之 hive 学习
- hadoop学习之--Hive笔记
- Hadoop学习笔记之Hive
- Hadoop之hive学习命令
- hadoop学习之-hive-数据模型
- Hadoop之hive学习_01
- Hadoop之hive学习_02
- Hadoop学习之Hive学习指南
- Hadoop之hive学习_01
- Hadoop学习之Hive简介
- Hadoop学习笔记之操作hive
- Hadoop 学习笔记之Hive安装
- hadoop学习之-hive-数据操作
- PullToRefresh刷新加载
- Android 点9图
- ViewPager轮播
- C# TabConTrol控件背景颜色
- HTTP协议三次握手过程
- Hadoop 之 hive 学习
- Sqoop教程(一) Sqoop数据迁移工具
- 每个ios开发者都应该知道Top 10 Swift三方库
- iOS长按图片保存实现方法
- 关于导入jar时出现的问题
- Linux学习总结(1)——Linux命令大全完整版
- XlistView的使用
- 往fragment传值参考代码
- iOS开发 给Label加下划线、中划线


