ZooKeeper dubbo 学习笔录
来源:互联网 发布:复杂网络画图软件 编辑:程序博客网 时间:2024/05/28 20:19
zookeeper的名字很有趣被称为动物管理员,这是因为Hadoop生态系统中很多软件的名字都是动物,hadoop本身就是小象的意思,还有hive小蜜蜂,pig。zookeeper作为一个分布式协调系统在hadhoop中被广泛的应用,其中HBase默认带有zookeeper。zookeeper主要功能有配置维护、分布式锁、选举、分布式队列等,并且zookeeper本身可以是一个集群,提供了高可用性。这一切的功能都离不开zookeeper的数据模型。
2、zookeeper数据模型
zookeeper提供的命名服务看起来和一个unix的文件系统非常相似,下面是从官网复制的一张图:

其中的每个节点称为znode,每个znode节点既可以包含数据又可以包含子节点,由于zookeeper被定位为协调程序因此znode中的数据通常存储的是非常小的数据,比如状态信息,位置信息等等。znode中有一个很重要的概念——节点类型,znode有两种类型的节点:临时节点,永久节点。其中这两种节点又分为有序和无序,重点讲一下临时节点,因为zk中很多基础的功能都是基于临时节点实现的,client在和zookeeper连接的时候两者之间会建立起session,session的状态由zookeeper服务端维护,临时节点的特点是随着session的超时服务端会将client建立的所有临时节点移除,而永久节点即使客户端退出节点也不会消失,同时临时节点不能有子节点但是可以挂载数据。结合watcher机制可以实现非常丰富和灵活的功能。
4、replaction
zookeeper中的高可用性是通过数据冗余和实现的,也就是一份数据存在多个节点中,zookeeper中要求同一份数据需要在超过一半的节点上存在,只有这样才能实现对宕机数量的容忍度更高。zk建议配置奇数个节点,是因为在flower同步数据和进行leader选举的时候都要求有超过一半完成或同意才算ok。举例来说,假如有3个节点,至少需要有2个节点正常,就是容忍度为1(允许宕掉的节点数),有4个节点,至少需要有三个节点正常,容忍度同样为1,多出来一个机器但是容忍度相同在任何时候看来都得不偿失。因此zk建议部署奇数个节点,但这不是强制。另外再看一下为什么写操作的时候要求至少有超过一半节点commit成功整体才成功,假如有2t+1个zk节点,也就是必须有t+1个节点commit成功才算成功,因为只有这种情况下才能达成至少有一个节点存有前后两次的更新操作(两次t+1节点至少会重复一个)。zookeeper使用zab算法实现数据的原子广播,并且每次write会写日志然后更新缓存,每个zk节点维护一个zxid,zxid是一个全局变量,随着znode的每一次改变而递增,当leader挂掉的时候,剩余的flower选择zxid最大的节点作为新的leader,在新leader提供服务前还需要一次数据恢复,新leader只是拥有最多的数据,但不一定拥有最新的数据,因此leader和flower的数据需要同步到最新的状态,通过合并的过程完成整个数据的恢复。

上图5个zk节点允许两个宕机,其他三个节点总是能恢复出来ABCDE。
5、Watch机制zookeeper允许客户端对znode节点或者节点中的数据设置监听器,当znode改变的时候服务器触发监听,客户端完成一个回调做自己需要处理的逻辑。zookeeper中的watch是一次性的,也就是当监听触发后,需要再次应用watcher,下次才能在收到变化的通知。exists,getData,getChildren接口都可以指定是否应用watcher,可以使用默认的watcher或者自定义watcher。触发watcher的可以为create、delete、setData、setACL。
6、配置管理
如果是单机或者几台机器,当应用的配置项变更的时候,可能通过手动的方式去修改一下,但是假如一个集群中有成百上千个应用节点,如何才能保证快速无差错的完成配置项的变更。zookeeper的出现可以轻松地解决这个问题

每个节点在zk上建立永久型znode并写入配置项,然后监听该节点下数据的变化,一旦其他客户端修改了其中的数据,所有的监听客户端都会收到变更通知。
7、Leader选举
zookeeper本身提供leader选举机制,大概的思路是所有的节点创建临时有序的znode然后监听所有节点的变化情况,获取最小序号和自己创建的序列作比较,如果自己为最小则当选为leader,当主动删除自己创建的节点或者leader宕机后,临时节点消失,该变化会被其他存活的节点获取到从而触发第二次的leader选举,依次类推。实际上zookeeper提到的很多recipes curator都提供了很好的实现(除了两阶段提交),同时基于底层的zookeeper api开发应用需要考虑的东西很多,curator对这些都提供了封装,所以如果要编写zookeeper应用推荐使用curator。
leader应用的场景很广泛,curator提供了两种不同的选举实现,一种是轮询做leader,另外一种是永久获取leader权直到退出,两种选举实现可以应用在不同的集群应用中。HBase中使用的是获取leader的永久权
上边讲了一些原理性的东西,下面我们来实际搭建一下
Zookeeper 安装与配置
本文采用 Zookeeper-3.4.0 以基础介绍它的安装步骤以及配置信息,最新的代码可以到 Zookeeper 的官网:http://zookeeper.apache.org/下载。Zookeeper功能强大,但是安装却十分简单,下面重点以伪分布式模式来介绍 Zookeeper 的安装。
1。首先你需要下载一个zookeeper ,然后创建一个文件夹zookeeper_cluster(名字任意),在zookeeper_cluster下创建三个文件夹:server001,server002,server003。
在这三个文件夹中分别创建 data,logs 两个文件夹,然后将我们下载的zookeeper 分别解压到 server001,server002,server003这三个文件夹中。
2.完成了上述操作后,在server001/data,server002/data,server003/data 中分别创建一个myid文件,文件内容分别为1,2,3,。
3.
Zookeeper 的配置文件主要在 conf 目录,包括zoo.cfg (zoo_sample.cfg)和log4j.properties,修改 zoo_sample.cfg,重命名为zoo.cgf,打开zoo.cfg,内容如下:

# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial # synchronization phase can takeinitLimit=10# The number of ticks that can pass between # sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just # example sakes.dataDir=/tmp/zookeeper# the port at which the clients will connectclientPort=2181## Be sure to read the maintenance section of the # administrator guide before turning on autopurge.## http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to "0" to disable auto purge feature#autopurge.purgeInterval=1
将内容修改为(server001节点的配置文件):
# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial # synchronization phase can takeinitLimit=10# The number of ticks that can pass between # sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just # example sakes.dataDir=/zookeeper_cluster/server001/datadataLogDir=/zookeeper_cluster/server001/logs# the port at which the clients will connectclientPort=2181## Be sure to read the maintenance section of the # administrator guide before turning on autopurge.## http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to "0" to disable auto purge feature#autopurge.purgeInterval=1server.1=127.0.0.1:8881:7771server.2=127.0.0.1:8882:7772server.3=127.0.0.1:8883:7773
- tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
- dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
- clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
- initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
- syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒
- server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
4,继续修改server002,和server003 中的zookeeper的配置文件,其他内容均相同:
clientPort=2181
dataDir=/zookeeper_cluster/server001/datadataLogDir=/zookeeper_cluster/server001/logs这三项对应修改则可,clientPort 不能重复
通过java代码使用zookeeper
Zookeeper的使用主要是通过创建其jar包下的Zookeeper实例,并且调用其接口方法进行的,主要的操作就是对znode的增删改操作,监听znode的变化以及处理。
以下为主要的API使用和解释
 //创建一个Zookeeper实例,第一个参数为目标服务器地址和端口,第二个参数为Session超时时间,第三个为节点变化时的回调方法
//创建一个Zookeeper实例,第一个参数为目标服务器地址和端口,第二个参数为Session超时时间,第三个为节点变化时的回调方法 ZooKeeper zk = new ZooKeeper("127.0.0.1:2181", 500000,new Watcher() {
ZooKeeper zk = new ZooKeeper("127.0.0.1:2181", 500000,new Watcher() { // 监控所有被触发的事件
// 监控所有被触发的事件 public void process(WatchedEvent event) { //dosomething
public void process(WatchedEvent event) { //dosomething }
} });//创建一个节点root,数据是mydata,不进行ACL权限控制,节点为永久性的(即客户端shutdown了也不会消失)zk.create("/root", "mydata".getBytes(),Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);//在root下面创建一个childone znode,数据为childone,不进行ACL权限控制,节点为永久性的zk.create("/root/childone","childone".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);//取得/root节点下的子节点名称,返回List<String>zk.getChildren("/root",true);//取得/root/childone节点下的数据,返回byte[]zk.getData("/root/childone", true, null);//修改节点/root/childone下的数据,第三个参数为版本,如果是-1,那会无视被修改的数据版本,直接改掉zk.setData("/root/childone","childonemodify".getBytes(), -1);//删除/root/childone这个节点,第二个参数为版本,-1的话直接删除,无视版本zk.delete("/root/childone", -1); //关闭sessionzk.close();
});//创建一个节点root,数据是mydata,不进行ACL权限控制,节点为永久性的(即客户端shutdown了也不会消失)zk.create("/root", "mydata".getBytes(),Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);//在root下面创建一个childone znode,数据为childone,不进行ACL权限控制,节点为永久性的zk.create("/root/childone","childone".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);//取得/root节点下的子节点名称,返回List<String>zk.getChildren("/root",true);//取得/root/childone节点下的数据,返回byte[]zk.getData("/root/childone", true, null);//修改节点/root/childone下的数据,第三个参数为版本,如果是-1,那会无视被修改的数据版本,直接改掉zk.setData("/root/childone","childonemodify".getBytes(), -1);//删除/root/childone这个节点,第二个参数为版本,-1的话直接删除,无视版本zk.delete("/root/childone", -1); //关闭sessionzk.close();
Zookeeper的主流应用场景实现思路(除去官方示例)
(1)配置管理
集中式的配置管理在应用集群中是非常常见的,一般商业公司内部都会实现一套集中的配置管理中心,应对不同的应用集群对于共享各自配置的需求,并且在配置变更时能够通知到集群中的每一个机器。
Zookeeper很容易实现这种集中式的配置管理,比如将APP1的所有配置配置到/APP1 znode下,APP1所有机器一启动就对/APP1这个节点进行监控(zk.exist("/APP1",true)),并且实现回调方法Watcher,那么在zookeeper上/APP1 znode节点下数据发生变化的时候,每个机器都会收到通知,Watcher方法将会被执行,那么应用再取下数据即可(zk.getData("/APP1",false,null));
以上这个例子只是简单的粗颗粒度配置监控,细颗粒度的数据可以进行分层级监控,这一切都是可以设计和控制的。 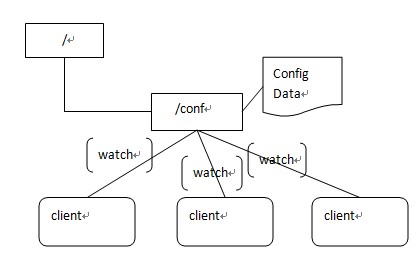
(2)集群管理
应用集群中,我们常常需要让每一个机器知道集群中(或依赖的其他某一个集群)哪些机器是活着的,并且在集群机器因为宕机,网络断链等原因能够不在人工介入的情况下迅速通知到每一个机器。
Zookeeper同样很容易实现这个功能,比如我在zookeeper服务器端有一个znode叫/APP1SERVERS,那么集群中每一个机器启动的时候都去这个节点下创建一个EPHEMERAL类型的节点,比如server1创建/APP1SERVERS/SERVER1(可以使用ip,保证不重复),server2创建/APP1SERVERS/SERVER2,然后SERVER1和SERVER2都watch /APP1SERVERS这个父节点,那么也就是这个父节点下数据或者子节点变化都会通知对该节点进行watch的客户端。因为EPHEMERAL类型节点有一个很重要的特性,就是客户端和服务器端连接断掉或者session过期就会使节点消失,那么在某一个机器挂掉或者断链的时候,其对应的节点就会消失,然后集群中所有对/APP1SERVERS进行watch的客户端都会收到通知,然后取得最新列表即可。
另外有一个应用场景就是集群选master,一旦master挂掉能够马上能从slave中选出一个master,实现步骤和前者一样,只是机器在启动的时候在APP1SERVERS创建的节点类型变为EPHEMERAL_SEQUENTIAL类型,这样每个节点会自动被编号,例如
zk.create("/testRootPath/testChildPath1","1".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL); zk.create("/testRootPath/testChildPath2","2".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL); zk.create("/testRootPath/testChildPath3","3".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL); // 创建一个子目录节点zk.create("/testRootPath/testChildPath4","4".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL);System.out.println(zk.getChildren("/testRootPath", false)); 打印结果:[testChildPath10000000000, testChildPath20000000001, testChildPath40000000003, testChildPath30000000002]
zk.create("/testRootPath", "testRootData".getBytes(),Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);// 创建一个子目录节点zk.create("/testRootPath/testChildPath1","1".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL); zk.create("/testRootPath/testChildPath2","2".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL); zk.create("/testRootPath/testChildPath3","3".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL); // 创建一个子目录节点zk.create("/testRootPath/testChildPath4","4".getBytes(), Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL);System.out.println(zk.getChildren("/testRootPath", false));打印结果:[testChildPath2, testChildPath1, testChildPath4, testChildPath3]
我们默认规定编号最小的为master,所以当我们对/APP1SERVERS节点做监控的时候,得到服务器列表,只要所有集群机器逻辑认为最小编号节点为master,那么master就被选出,而这个master宕机的时候,相应的znode会消失,然后新的服务器列表就被推送到客户端,然后每个节点逻辑认为最小编号节点为master,这样就做到动态master选举。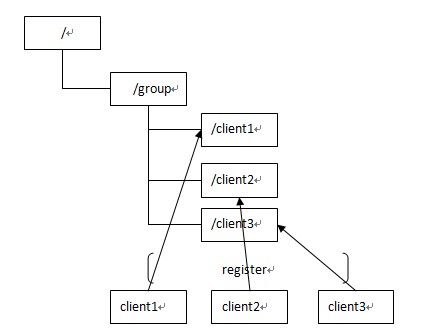
总结
我们初步使用了一下zookeeper并且尝试着描述了几种应用场景的具体实现思路,接下来的文章,我们会尝试着去探究一下zookeeper的高可用性与leaderElection算法。
参考:http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/
http://hadoop.apache.org/zookeeper/docs/current/
- ZooKeeper dubbo 学习笔录
- dubbo zookeeper 学习一
- Zookeeper,Dubbo学习
- (dubbo学习)linux 安装dubbo+zookeeper
- dubbo学习及集成zookeeper集群部署
- dubbo学习及集成zookeeper集群部署
- Zookeeper+dubbo分布式开发学习(一)
- dubbo学习笔记 第一章 zookeeper安装配置
- dubbo 使用 学习二(spring+dubbo+zookeeper单机服务)
- DUBBO研究与学习三:Dubbo+zookeeper安装
- dubbo学习总结-(2)dubbo+zookeeper注册中心
- Dubbo 学习2 Dubbo-Admin及服务注册到Zookeeper
- Dubbo+Zookeeper
- dubbo zookeeper
- dubbo zookeeper
- dubbo zookeeper
- dubbo+zookeeper
- zookeeper+dubbo
- Struts2的国际化和访问资源文件的几种方式
- Activity的生命周期
- iOS设置状态栏样式,statusBarStyle
- leetcode No238. Product of Array Except Self
- Vijos P1352 最大获利
- ZooKeeper dubbo 学习笔录
- 安装新交互英语客户端提示找不到SOAP的解决方案
- mybatis-generator有三种用法
- lsof命令:查看Liunx进程所打开的文件命令
- Android Studio Tips -- 布局预览
- js页面键盘回车事件
- Spring切面通知执行的顺序(Advice Order)
- OnCheckedChangeListener执行了二次
- Log日志工具类


