牛客 数据库
来源:互联网 发布:开不开amd优化 编辑:程序博客网 时间:2024/05/22 12:02
(1)基本概念
① 属性和域:
每个事物有很多属性,每个属性对应的取值范围叫做域,所有对域都是原子数据(第一范式)
② 相关名词
n元关系:R(D1,D2,D3...Dn)是n元关系,其中关系属性的个数称为“元数”,元组的个数称为“基 数”,也就是记录值。
候选码:若关系中某一个属性或者属性组的值可以唯一的标识一个元组,则称为候选码
主码:可以选择任意一个候选码作为主码
主属性:包含在任何候选码中的属性叫作主属性
全码:关系模型中所有属性都是这个关系模型的候选码,称为全码
外码:关系模式中的属性非该关系的码,则称为外码
③ 三种类型:
基本表:实际存在的表
查询表:查询结果对应的表
视图表:由基本表和其他视图表导出的表,不是实际存在数据库中
④ 完整性约束:
实体完整性:主属性A不能为空值
参照完整性:用实体之间的关系来描述,若F是关系R的外码,则F或者是空值,或者是某个元组的 主码值
用户定义完整性:根据具体关系数据的约束条件,比如数据范围等
(2)关系五种基本运算
① 并:
R,S具有相同的关系模式(元素相同,结构相同),记为R U S,返回由R或者S元组构成的集合组成
② 差:
R,S具有相同的关系模式(元素相同,结构相同),记为R-S,右属于R但不属于S的元组组成
③ 广义笛卡尔积:
R×S由n目和m目的关系R,S组成一个(n+m)列的元组集合,若R有K1个元组,S有K2个元组,则R×S有K1*K2个元 组
④ 投影(π) :
从关系的垂直方向开始运算,选择关系中的若干列组成新的列。
⑤ 选择(σ):
选择从关系的水平方向进行元算,选择满足给定条件的元组组成新的关系。
(3)扩展的关系代数运算
① 交:
R∩S=R-(R-S),R,S具有相同的关系模式
② 链接:
链接分为θ链接,等值链接和自然链接
θ链接:从R,S的笛卡尔积中选择满足一定条件的元组
等值链接:当θ为“=”时为等值链接
自然链接:是一种特殊的等值链接,比较的分量必须是相同的属性组,并在结果集中去掉重复列,如果没有重复列,自然链接就转换为笛卡尔积
③ 除:
同时从水平方向和垂直方向进行运算,给定关系R(X,Y)和S(Y,Z),X,Y,Z为属性组,R÷S应当满足在X上的分量值x的像集Yx包含关系S在属性组Y上的投影集合:
例如:
R是:
A
B
C
D
a
b
c
d
a
b
e
f
a
b
h
k
b
d
e
f
b
d
d
l
c
k
c
d
c
k
e
f
S是:
C
D
c
d
e
f
则R÷S:
A
B
a
b
c
k
④ 广义投影:
广义投影运算容许在投影列表中使用算法运算,实现对投影运算的扩充,投影出的列不一定是原来的列,可以是通过计算出来的列。
⑤ 外连接:
由于自然链接会丢失一些信息,而外链接可以处理由于链接运算而缺失的信息,外链接分为左外链接、右外链接、全外链接。
左外链接:取出左侧关系中所有与右侧关系中任一元素都不匹配的元组,用null来填充右侧的关系 属性。
右外链接:取出右侧关系中所有与右侧关系中任一元素都不匹配的元组,用null来填充左侧的关系属性。
全外链接:完成左外链接和右外链接的操作。
2.
牛客网的数据库有一个试卷表,希望找出试卷平均得分小于90的所有试卷。
- SELECT * FROM paper WHERE avg(score) < 90;
3.
(1) select count(*) from t1;(返回记录数,也就是行数)如果表格为空的话,会返回0,不会返回NULL。
4.
事务四大特性(简称ACID)
1、原子性(Atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行。
2、一致性(Consistency):几个并行执行的事务,其执行结果必须与按某一顺序串行执行的结果相一致。
3、隔离性(Isolation):事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
4、持久性(Durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障。
5.
在mysql中,以下哪种方式可以开启一个事务?
- BEGIN或START TRANSACTION;显示地开启一个事务;
- COMMIT;也可以使用COMMIT WORK,不过二者是等价的。COMMIT会提交事务,并使已对数据库进行的所有修改称为永久性的;
- ROLLBACK;有可以使用ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
- SAVEPOINT identifier;SAVEPOINT允许在事务中创建一个保存点,一个事务中可以有多个SAVEPOINT;
- RELEASE SAVEPOINT identifier;删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
- ROLLBACK TO identifier;把事务回滚到标记点;
- SET TRANSACTION;用来设置事务的隔离级别。InnoDB存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ和SERIALIZABLE。
6.
在MySQL中,下列关于出发机器的描述正确的是(a,c)
MySQL的触发器只支持行级出发,不支持语句级触发
触发器可以调用将数据返回客户端的存储程序
在MySQL中,使用new和old引用触发器中发生的记录内容
在触发器中可以使用显示或者隐式方式开始或结束事务的语句
A、 触发程序与表相关,当对表执行INSERT、DELETE或UPDATE语句时,将激活触发程序。可以将
触发程序设置为在执行语句之前或之后激活。例如,可以在从表中删除每一行之前,或在更新了
B、触发程序不能调用将数据返回客户端的存储程序,也不能使用采用CALL语句的动态SQL
在INSERT触发程序中,仅能使用NEW.col_name,没有旧行。在DELETE触发程序中,仅能使用
OLD.col_name,没有新行。在UPDATE触发程序中,可以使用OLD.col_name来引用更新前的某一
COMMIT或ROLLBACK。
- EXPLAIN explain命令在解决数据库性能上是第一推荐使用命令,大部分的性能问题可以通过此命令来简单的解决,Explain可以用来查看SQL语句的执行效 果,可以帮助选择更好的索引和优化查询语句,写出更好的优化语句。 explain语法:explain select … from … [where ...] 例如:explain select * from news;
- LOAD load是加载
- TOPtop是规定要返回的目录的记录的数目,长与Orderdy 合用top用法http://www.cnblogs.com/wang7/archive/2012/07/09/2582891.html
- SUM 求和
SELECT i.id_number,m.id_number FROM inventory i,manufacturer m WHEREi.manufacturer_id = m.id_number Order by inventory.description在order by的子句中使用表的别名
mysql数据库有选课表learn(student_id int,course_id int),字段分别表示学号和课程编号,现在想获取每个学生所选课程的个数信息,请问如下的sql语句正确的是
select student_id,count(course_id)from learn group by student_id
group by student_id是按学生号分组,每个编号的学生可能有多门课程,但不可能课程编号会重复,所以直接使用count(course_id),否则就要使用count(disctinct(course_id))
mysql数据库中一张user表中,其中包含字段A,B,C,字段类型如下:A:int,B:int,C:int根据字段A,B,C按照ABC顺序建立复合索引idx_A_B_C,以下查询语句中使用到索引idx_A_B_C的语句有哪些?A,B,D- select *from user where A=1 and B=1
- select *from user where 1=1 and A=1 and B=1
- select *from user where B=1 and C=1
- select *from user where A=1 and C=1
- 复合索引: Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。 例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效
下列关于关系数据模型的术语中,哪一个术语所表达的概念与二维表的"行"的概念最接近(元组)关系数据库中方,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为记录。mysql中查看SQL模式的命令是()MySQL数据库中,变量分为 系统变量(以"@@"开头)和用户自定义变量。系统变量分为全局系统变量(global)和会话系统变量(session)。@@global 仅用于访问全局系统变量的值;@@session 仅用于访问会话系统变量的值;@@ 先访问会话系统变量的值,若不存在则去访问全局系统变量的值;sql_mode 为系统变量,既是全局系统变量,又是会话系统变量。题中 A,C,D 均正确。
索引字段值不唯一,应该选择的索引类型为(普通索引)
索引类型分类:①主索引:主索引是一种只能在数据库表中建立不能在自由表中建立的索引。在指定的字段或表达式中,主索 引的关键字绝对不允许有重复值。②候选索引:和主索引类似,它的值也 不允许在指定的字段或表达式中重复。一个表中可以有多个 候选索引。③唯一索引:唯一索引允许关键字取重复的值。当有重复值 出现时,索引文件只保存重复值的第1次出现。提供唯一索引主要是为了兼容早期的 版本。④普通索引:普通索引允许关键字段有相同值。在一对 多关系的多方,可以使用普通索引select sum(score) as total,stud_name from [成绩表](nolock) group by stud_name根据stud_name对学生进行分组,分组后,同一个学生的所有成绩分为一组,用sum(score)计算出总分,最有列名为total。但是题目应该加限定条件,学生不能重名,否则会出错。有两个关系R和S如下:由关系R通过运算得到关系S,则运算可能是?
(2)关系五种基本运算
① 并:
R,S具有相同的关系模式(元素相同,结构相同),记为R U S,返回由R或者S元组构成的集合组成
② 差:
R,S具有相同的关系模式(元素相同,结构相同),记为R-S,右属于R但不属于S的元组组成
③ 广义笛卡尔积:
R×S由n目和m目的关系R,S组成一个(n+m)列的元组集合,若R有K1个元组,S有K2个元组,则R×S有K1*K2个元 组
④ 投影(π) :
从关系的垂直方向开始运算,选择关系中的若干列组成新的列。
⑤ 选择(σ):
选择从关系的水平方向进行元算,选择满足给定条件的元组组成新的关系。
一般情况下,当对关系R和S进行自然连接时,要求R和S含有一个或者多个共有的?(疑问)自然连接要求俩个关系中必须有相同的属性,等值连接要求俩个关系中有相同的值自然连接的结果会去掉重复的属性,等值连接不会去掉重复的属性自然连接一定是等值连接,等值连接不一定是自然连接。The initial insert of new data into the table will leave most of its large columns NULL, to be filled in later by subsequent updates.记录重未更新. PCTFREE 和 PCTUSED取值多少合适?
(1)PCTFREE:为一个块保留的空间百分比,表示数据块在什么情况下可以被insert。(2)PCTUSED:是指当块里的数据低于多少百分比时,又可以重新被insert。形象举例说明:假如:一个杯子一共可装10分水:PCTFREE =10,说明杯子装到9分水,就不能再装了,即:不能进行insert操作,但可以进行update操作。PCTUSED =40,说明杯子中的水喝到4分一下,就可以往里面装水,即:进行insert操作。
数据库恢复的基础是利用转储的冗余数据。这些转储的冗余数据包括(日志文件,数据库后备副本)
以下不同的数据库类型中,哪些不属于关系数据库范畴
PostgreSQL
可扩展性
响应时间
并发性
吞吐量
利用PL/SQL语句将"数据库原理"课程的学分赋值给变量的语句是(C)
select xuefen into @xuefen from course where cname='数据库原理'
select xuefen from course where cname='数据库原理' and xuefen=@xuefen
select @xuefen=xuefen from course where cname='数据库原理'
select xuefen=@xuefen from course where cname='数据库原理'
设有一个关系:DEPT(DNO,DNAME),如果要找出倒数第三个字母为W,并且至少包含4个字母的DNAME,则查询条件子句应写成WHERE DNAME LIKE__________.
‘_ % W _ _’
以下不是RDBMS的是()(关系型数据库)
RDBMS 是SQL 的基础,同样也是所有现代数据库系统的基础,比如MS SQL Server, IBM DB2, Oracle, MySQL 以及Microsoft Access。hadoop是分布式数据库
9i中的数据保护模式包括有?
这种模式能够保证在primary Database发生故障保证数据不丢失。在这种模式下,事务提交前,要保证Redo数据已经写入到Primary Database的Online Redologs,同时写入Standby Database的Standby Redologs,并确保至少在一个Standby Database中可用。如果Standby Database不可用,Primary Database将会shutdown。
最高可用性(Maximum availability)
这种模式在不影响Primary Database可用的前提下,提供最高级别的数据保护策略,这种模式也能够确保数据不丢失。事务提交之前,要保证Redo数据已经写入到Primary Database的Online Redologs,同时写入Standby Database的Standby Redologs,确保至少在一个Standby Database中可用。与最大保护模式不同的是,如果Standby Database出现故障导致不可用,Primary Database并不会被shutdown,而是自动转换为最高性能模式,等Standby Database恢复正常后,Primary Database又会自动切换到最高可用性模式。
最大性能(Maximum performance)
这是一种默认的保护模式。事务可以随时提交,当前Primary Database的Redo数据至少需要写入一个Standby Database,不过这种方式不会等待Standby Database是否写入的确认因此这种写入属于异步写入。
设关系数据库中一个表S的结构为:S(SN,CN,grade),其中SN为学生名,CN为课程名,二者均为字符型;grade为成绩,数值型,取值范围0-100。若要更正王二的化学成绩为85分,则可用()
update语法格式如下:UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值 那么,上面的需求可以通过以下语句满足:UPDATE S SET grade = 85 WHERE SN = '王二' AND CN='化学'A选项 正确B选项 grade为数值型,不能用引号将其值括起来,错误C选项 语法格式不对,缺少对哪个表操作的语句,缺少SET关键字D选项 grade为数值型,不能用引号将其值括起来,错误
电话号码表t_phonebook中含有100万条数据,其中号码字段PhoneNo上创建了唯一索引,且电话号码全部由数字组成,要统计号码头为321的电话号码的数量,下面写法执行速度最慢的是___
- select count(*) from t_phonebook where phoneno >= ‘321’ and phoneno < ‘321A’
- select count(*) from t_phonebook where phoneno like ‘321%’
- select count(*) from t_phonebook where substr(phoneno,1,3) = ‘321’
- 都一样快
说白了,索引问题就是一个查找问题。。。
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
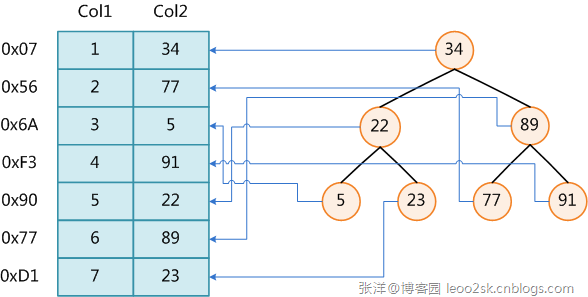
上图展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在O(log2n)的复杂度内获取到相应数据。
创建索引可以大大提高系统的性能。
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?因为,增加索引也有许多不利的方面。
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。一般来说,应该在这些列上创建索引:在经常需要搜索的列上,可以加快搜索的速度;在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。
唯一索引唯一索引是不允许其中任何两行具有相同索引值的索引。
当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。例如,如果在employee表中职员的姓(lname)上创建了唯一索引,则任何两个员工都不能同姓。主键索引数据库表经常有一列或列组合,其值唯一标识表中的每一行。该列称为表的主键。在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。聚集索引在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。
局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
B-/+Tree索引的性能分析
到这里终于可以分析B-/+Tree索引的性能了。
上文说过一般使用磁盘I/O次数评价索引结构的优劣。先从B-Tree分析,根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
综上所述,用B-Tree作为索引结构效率是非常高的。
应该花时间学习B-树和B+树数据结构
=============================================================================================================
1)B树
B树中每个节点包含了键值和键值对于的数据对象存放地址指针,所以成功搜索一个对象可以不用到达树的叶节点。
成功搜索包括节点内搜索和沿某一路径的搜索,成功搜索时间取决于关键码所在的层次以及节点内关键码的数量。
在B树中查找给定关键字的方法是:首先把根结点取来,在根结点所包含的关键字K1,…,kj查找给定的关键字(可用顺序查找或二分查找法),若找到等于给定值的关键字,则查找成功;否则,一定可以确定要查的关键字在某个Ki或Ki+1之间,于是取Pi所指的下一层索引节点块继续查找,直到找到,或指针Pi为空时查找失败。
2)B+树B+树非叶节点中存放的关键码并不指示数据对象的地址指针,非也节点只是索引部分。所有的叶节点在同一层上,包含了全部关键码和相应数据对象的存放地址指针,且叶节点按关键码从小到大顺序链接。如果实际数据对象按加入的顺序存储而不是按关键码次数存储的话,叶节点的索引必须是稠密索引,若实际数据存储按关键码次序存放的话,叶节点索引时稀疏索引。
B+树有2个头指针,一个是树的根节点,一个是最小关键码的叶节点。
所以 B+树有两种搜索方法:
一种是按叶节点自己拉起的链表顺序搜索。
一种是从根节点开始搜索,和B树类似,不过如果非叶节点的关键码等于给定值,搜索并不停止,而是继续沿右指针,一直查到叶节点上的关键码。所以无论搜索是否成功,都将走完树的所有层。
B+ 树中,数据对象的插入和删除仅在叶节点上进行。
这两种处理索引的数据结构的不同之处:
a,B树中同一键值不会出现多次,并且它有可能出现在叶结点,也有可能出现在非叶结点中。而B+树的键一定会出现在叶结点中,并且有可能在非叶结点中也有可能重复出现,以维持B+树的平衡。
b,因为B树键位置不定,且在整个树结构中只出现一次,虽然可以节省存储空间,但使得在插入、删除操作复杂度明显增加。B+树相比来说是一种较好的折中。
c,B树的查询效率与键在树中的位置有关,最大时间复杂度与B+树相同(在叶结点的时候),最小时间复杂度为1(在根结点的时候)。而B+树的时候复杂度对某建成的树是固定的。
在视图上使用INSERT语句,下列()情况可以进行插入操作.
1.若视图是由两个以上基本表导出的,则此视图不允许更新。
2.若视图的字段来自字段表达式或常数,则不允许对视图执行INSTER和UPDATE操作,但允许delete。
3.若视图的字段来自聚集函数,则此视图不允许更新。
4.若视图中含有GROUP by子句,则此视图不允许更新。
5.若视图中含有DISTINCT短语,则此视图不允许更新。.
6若视图定义中有嵌套查询,并且内层查询的FROM子句中涉及的表也是导出该视图的基本表,则此视图不允许更新。.
7.一个不允许更新的视图上定义的视图不允许更新。
关于数据完整性,以下说法正确的是?
下列有关InnoDB和MylSAM说法正确的是()
MySQL有多种存储引擎,每种存储引擎有各自的优缺点,可以择优选择使用:
MyISAM、InnoDB、MERGE、MEMORY(HEAP)、BDB(BerkeleyDB)、EXAMPLE、FEDERATED、ARCHIVE、CSV、BLACKHOLE。
MySQL支持数个存储引擎作为对不同表的类型的处理器。MySQL存储引擎包括处理事务安全表的引擎和处理非事务安全表的引擎:
· MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。MyISAM在所有MySQL配置里被支持,它是默认的存储引擎,除非你配置MySQL默认使用另外一个引擎。
· MEMORY存储引擎提供“内存中”表。MERGE存储引擎允许集合将被处理同样的MyISAM表作为一个单独的表。就像MyISAM一样,MEMORY和MERGE存储引擎处理非事务表,这两个引擎也都被默认包含在MySQL中。
注释:MEMORY存储引擎正式地被确定为HEAP引擎。
· InnoDB和BDB存储引擎提供事务安全表。BDB被包含在为支持它的操作系统发布的MySQL-Max二进制分发版里。InnoDB也默认被包括在所 有MySQL 5.1二进制分发版里,你可以按照喜好通过配置MySQL来允许或禁止任一引擎。
· EXAMPLE存储引擎是一个“存根”引擎,它不做什么。你可以用这个引擎创建表,但没有数据被存储于其中或从其中检索。这个引擎的目的是服务,在 MySQL源代码中的一个例子,它演示说明如何开始编写新存储引擎。同样,它的主要兴趣是对开发者。
· NDB Cluster是被MySQL Cluster用来实现分割到多台计算机上的表的存储引擎。它在MySQL-Max 5.1二进制分发版里提供。这个存储引擎当前只被Linux, Solaris, 和Mac OS X 支持。在未来的MySQL分发版中,我们想要添加其它平台对这个引擎的支持,包括Windows。
· ARCHIVE存储引擎被用来无索引地,非常小地覆盖存储的大量数据。
· CSV存储引擎把数据以逗号分隔的格式存储在文本文件中。
· BLACKHOLE存储引擎接受但不存储数据,并且检索总是返回一个空集。
比较常用的是MyISAM和InnoBD
MyISAM
InnoDB
构成上的区别:
每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。
.frm文件存储表定义。
数据文件的扩展名为.MYD (MYData)。
索引文件的扩展名是.MYI (MYIndex)。
基于磁盘的资源是InnoDB表空间数据文件和它的日志文件,InnoDB 表的大小只受限于操作系统文件的大小,一般为 2GB
事务处理上方面 :
MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持
InnoDB提供事务支持事务,外部键(foreign key)等高级数据库功能
SELECT UPDATE,INSERT ,Delete 操作
如果执行大量的SELECT,MyISAM是更好的选择
1.如果你的数据执行大量的INSERT 或 UPDATE,出于性能方面的考虑,应该使用InnoDB表
2.DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。
3.LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用
对AUTO_INCREMENT的操作
每表一个AUTO_INCREMEN列的内部处理。
MyISAM 为 INSERT 和 UPDATE操作自动更新这一列。这使得AUTO_INCREMENT列更快(至少10%)。在序列顶的值被删除之后就不能再利用。(当AUTO_INCREMENT列被定义为多列索引的最后一列,可以出现重使用从序列顶部删除的值的情况)。
AUTO_INCREMENT值可用ALTER TABLE或myisamch来重置
对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引
更好和更快的auto_increment处理
如果你为一个表指定AUTO_INCREMENT列,在数据词典里的InnoDB表句柄包含一个名为自动增长计数器的计数器,它被用在为该列赋新值。
自动增长计数器仅被存储在主内存中,而不是存在磁盘上
关于该计算器的算法实现,请参考
AUTO_INCREMENT 列在InnoDB 里如何工作
表的具体行数
select count(*) from table,MyISAM只要简单的读出保存好的行数,注意的是,当count(*)语句包含 where条件时,两种表的操作是一样的
InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行
锁
表锁
提供行锁(locking on row level),提供与 Oracle 类型一致的不加锁读取(non-locking read in
SELECTs),另外,InnoDB表的行锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表, 例如update table set num=1 where name like “%aaa%”
relay-log中继日志是mysql备库从主库bin-log读取的log
以下哪个不是与Mysql服务器相互作用的通讯协议()
MySQL实现了四种通信协议 与Mysql服务器相互作用的通讯协议包括TCP/IP,Socket,共享内存,命名管道
- TCP/IP协议,通常我们通过来连接MySQL,各种主要编程语言都是根据这个协议实现了连接模块
- Unix Socket协议,这个通常我们登入MySQL服务器中使用这个协议,因为要使用这个协议连接MySQL需要一个物理文件,文件的存放位置在配置文件中有定义,值得一提的是,这是所有协议中最高效的一个。
- Share Memory协议,这个协议一般人不知道,肯定也没用过,因为这个只有windows可以使用,使用这个协议需要在配置文件中在启动的时候使用–shared-memory参数,注意的是,使用此协议,一个host上只能有一个server,所以这个东西一般没啥用的,除非你怀疑其他协议不能正常工作,实际上微软的SQL Sever也支持这个协议
- Named Pipes协议,这个协议也是只有windows才可以用,同shared memory一样,使用此协议,一个host上依然只能有一个server,即使是使用不同的端口也不行,Named Pipes 是为局域网而开发的协议。内存的一部分被某个进程用来向另一个进程传递信息,因此一个进程的输出就是另一个进程的输入。第二个进程可以是本地的(与第一个进程位于同一台计算机上),也可以是远程的(位于联网的计算机上)。正因为如此,假如你的环境中没有或者禁用TCP/IP环境,而且是windows服务器,那么好歹你的数据库还能工作。使用这个协议需要在启动的时候添加–enable-named-pipe选项
网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket。 Socket的英文原义是“孔”或“插座”。作为BSD UNIX的进程通信机制,取后一种意思。通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,可以用来实现不同虚拟机或不同计算机之间的通信。在Internet上的主机一般运行了多个服务软件,同时提供几种服务。每种服务都打开一个Socket,并绑定到一个端口上,不同的端口对应于不同的服务。Socket正如其英文原意那样,像一个多孔插座。一台主机犹如布满各种插座的房间,每个插座有一个编号,有的插座提供220伏交流电, 有的提供110伏交流电,有的则提供有线电视节目。 客户软件将插头插到不同编号的插座,就可以得到不同的服务
步骤 T1 T21 读A=1002 读A=1003. A=A+10写回4. A=A-10
- 该操作不能重复读
- 该操作不存在问题
- 该操作读"脏"数据
- 该操作丢失修改
丢失修改
下面我们先来看一个例子,说明并发操作带来的数据的不一致性问题。
考虑飞机订票系统中的一个活动序列:
甲售票点(甲事务)读出某航班的机票余额A,设A=16.
乙售票点(乙事务)读出同一航班的机票余额A,也为16.
甲售票点卖出一张机票,修改余额A←A-1.所以A为15,把A写回数据库.
乙售票点也卖出一张机票,修改余额A←A-1.所以A为15,把A写回数据库.
结果明明卖出两张机票,数据库中机票余额只减少1。
归纳起来就是:两个事务T1和T2读入同一数据并修改,T2提交的结果破坏了T1提交的结果,导致T1的修改被丢失。前文(2.1.4数据删除与更新)中提到的问题及解决办法往往是针对此类并发问题的。但仍然有几类问题通过上面的方法解决不了,那就是:
不可重复读
不可重复读是指事务T1读取数据后,事务T2执行更新操作,使T1无法再现前一次读取结果。具体地讲,不可重复读包括三种情况:
事务T1读取某一数据后,事务T2对其做了修改,当事务1再次读该数据时,得到与前一次不同的值。例如,T1读取B=100进行运算,T2读取同一数据B,对其进行修改后将B=200写回数据库。T1为了对读取值校对重读B,B已为200,与第一次读取值不一致。
事务T1按一定条件从数据库中读取了某些数据记录后,事务T2删除了其中部分记录,当T1再次按相同条件读取数据时,发现某些记录神密地消失了。
事务T1按一定条件从数据库中读取某些数据记录后,事务T2插入了一些记录,当T1再次按相同条件读取数据时,发现多了一些记录。(这也叫做幻影读)
读"脏"数据
读"脏"数据是指事务T1修改某一数据,并将其写回磁盘,事务T2读取同一数据后,T1由于某种原因被撤消,这时T1已修改过的数据恢复原值,T2读到的数据就与数据库中的数据不一致,则T2读到的数据就为"脏"数据,即不正确的数据。
产生上述三类数据不一致性的主要原因是并发操作破坏了事务的隔离性。并发控制就是要用正确的方式调度并发操作,使一个用户事务的执行不受其它事务的干扰,从而避免造成数据的不一致性。

(5,68,1)
(7,45,null)
成绩表中主键是“PK=科目代码”,所以 科目代码要唯一,所以可排除AC;在数据库完整性里有说:外键必须可以找到或者为空,所以 B是可以的,而D为空,所以也满足。故选BD
定义:
主键 -- 唯一标识一条记录,不能有重复的,不允许为空
外键 -- 表的外键是另一表的主键 , 外键可以有重复的 , 可以是空值
索引 -- 该字段没有重复值,但可以有一个空值
作用:
主键 -- 用来保证数据完整性
外键 -- 用来和其他表建立联系用的
索引 -- 是提高查询排序的速度
个数:
主键 -- 主键只能有一个
外键 -- 一个表可以有多个外键
索引 -- 一个表可以有多个唯一索引
下列有关MySQL数据库中的NULL值,说法正确的是()
"空值" 和"NULL"的概念:
注:在进行 count ()统计某列的记录数的时候,如果采用的 NULL 值,会别系统自动忽略掉,但是空值是统计到其中
关于PreparedStatement与Statement描述错误的是(疑惑)
表toutiao_tb
SQL提供了四种匹配模式:1. % 表示任意0个或多个字符。如下语句:Select * FROM user Where name LIKE '%三%'; 将会把name为“张三”,“三脚猫”,“唐三藏”等等有“三”的全找出来。%三:表示左匹配。三%:表示右匹配。%三%:表示模糊查询。2. _ 表示任意单个字符。语句: Select * FROM user Where name LIKE '_三_';只找出“唐三藏”。这样name为三个字且中间一个字是“三”的; Select * FROM user Where name LIKE '三__'; 只找出“三脚猫”这样name为三个字且第一个字是“三”的;3. [ ] 表示括号内所列字符中的一个(类似与正则表达式)。语句:Select * FROM user Where name LIKE '[张李王]三'; 将找出“张三”、“李三”、“王三”(而不是“张李王三”); 如 [ ] 内有一系列字符(01234、abcde之类的)则可略写为“0-4”、“a-e“。Select * FROM user Where name LIKE '老[1-9]';将找出“老1”、“老2”、……、“老9”;如要找“-”字符请将其放在首位:'张三[-1-9]';4. [^ ] 表示不在括号所列之内的单个字符。语句:Select * FROM user Where name LIKE '[^张李王]三';将找出不姓“张”、“李”、“王”的“赵三”、“孙三”等;Select * FROM user Where name LIKE '老[^1-4]'; 将排除“老1”到“老4”寻找“老5”、“老6”、……、“老9”。5.* 表示查找的是所有信息,例如select * from tbl_user最后是重点!由于通配符的缘故,导致我们查询特殊字符“%”、“_”、“[”、“';”的语句无法正常实现,而把特殊字符用“[ ]”括起便可正常查询。据此我们写出以下函数: function sqlencode(str) str=replace(str,"';","';';") str=replace(str,"[","[[]") ';此句一定要在最先 str=replace(str,"_","[_]") str=replace(str,"%","[%]") sqlencode=str end function 在查询前将待查字符串先经该函数处理即可,并且在网页上连接数据库用到这类的查询语句时侯要注意:如Select * FROM user Where name LIKE '老[^1-4]';上面《'》老[^1-4]《'》是要有单引号的,别忘了,我经常忘!
下面有关本地管理表空间和字典管理表空间的特点的描述,错误的是?(疑问)
第一、字典管理表空间
将Oracle的区管理信息存放在表空间的字典中进行管理,所有区的分配与释放,都会使字典的记录的增减变动。也就是在字典的记录中会执行更新、插入、删 除操作,在执行上述操作时,都会生成重做日志,对字典的管理,将影响正常操作的效率,并且在区分配、回收的过程中,产生磁盘碎片,如果磁盘碎片增加到一定 的程度,会浪费空间,严重影响效率,同时,Oracle 在管理表空间的管理中,会产生递归SQL。
如果要用字典的方式管理表空间,可以在创建表空间时,使用: EXTENT MANAGEMENT DICTIONARY 选项。
第二、本地管理表空间
本地管理是以位图的方式,将区的分配信息保存在数据文件本身,所有区的分配等操作都只是位图的运算,位图中的每一位对应数据文件中的一个区或几个连续的区,这样在进行区管理时,生成的重做日志将非常少,并且运行的效率很高。并且产生磁盘碎片很少。
如果要用本地管理表空间,可以在创建表空间时,使用: EXTENT MANAGEMENT LOCAL 选项。
在表空间的管理中,Oracle8I中可以采用字典管理,也可以采用本地管理,如果不指定,将采用字典管理方式。
在 Oracle9I中,推荐采用本地管理的方式,如果不指定,将采用本地管理的方式。
从Oracle 10g开如,要求采用本地管理的方式。
声明一个名为books_cursor的游标,和名为@book_name的游标变量,以下语句正确的是()
- fetch next from books_cursor into @book_name
between and 的取值为大于等于值1 并且小于等于值2
MYSQL实现主从复制的日志是哪种?

下列哪种完整性中,将每一条记录定义为表中的惟一实体,即不能重复
设有关系模式R(A,B,C,D),其数据依赖集:F=((A,B)->C,C->D),则关系模式R的规范化程度最高达到() 疑问
对数据表进行修改的语句正确的是()
alter table employee drop column age
alter table employee drop age如需在表中添加列,请使用下列语法:ALTER TABLE table_nameADD column_name datatype要删除表中的列,请使用下列语法:
ALTER TABLE table_name DROP (COLUMN) column_name
下面名词解释错误的是: SQL(Structured Query Language)结构化查询语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。同时也是数据库脚本文件的扩展名。
TCP:Transmission Control Protocol 传输控制协议TCP是一种面向连接(连接导向)的、可靠的、基于字节流的运输层(Transport layer)通信协议. 超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。
QoS(Quality of Service)服务质量,是网络的一种安全机制, 是用来解决网络延迟和阻塞等问题的一种技术。 在正常情况下,如果网络只用于特定的无时间限制的应用系统,并不需要QoS,比如Web应用,或E-mail设置等。但是对关键应用和多媒体应用就十分必要。当网络过载或拥塞时,QoS 能确保重要业务量不受延迟或丢弃,同时保证网络的高效运行。
STL = Standard Template Library,标准模板库
XML(Extensible Markup Language)即可扩展标记语言,它与HTML一样,都是SGML(Standard Generalized Markup Language,标准通用标记语言)。Xml是Internet环境中跨平台的,依赖于内容的技术,是当前处理结构化文档信息的有力工具。扩展标记语言XML是一种简单的数据存储语言,使用一系列简单的标记描述数据,而这些标记可以用方便的方式建立,虽然XML占用的空间比二进制数据要占用更多的空间,但XML极其简单易于掌握和使用。(查询优化)就是能从这许多查询策略中找出最有效的查询执行计划的一种处理过程。
SQL中关于视图操作,错误的说法是?
视图是实际数据库实体
虚表
SQL中,下列涉及空值的操作,不正确的是?(name= NULL)
Null值使用 is not 或者 is 比较,不能使用=比较
1. 判断是为空的时候,用 name IS NULL ;判断不为空用name IS NoT NULL或者 NoT(name IS NULL)
下列哪个不是存储过程的好处()
数据库中存在学生表S、课程表C和学生选课表SC三个表,它们的结构如下:S(S#,SN,SEX,AGE,DEPT)C(C#,CN)SC(S#,C#,GRADE)其中:S#为学号,SN为姓名,SEX为性别,AGE为年龄,DEPT为系别,C#为课程号,CN为课程名,GRADE为成绩。请检索选修课程号为C2的学生中成绩最高的学号。( )
一、 SQL 基本语句
SQL 分类:
DDL —数据定义语言 (Create , Alter , Drop , DECLARE)
DML —数据操纵语言 (Select , Delete , Update , Insert)
DCL —数据控制语言 (GRANT , REVOKE , COMMIT , ROLLBACK)
首先 , 简要介绍基础语句:
1 、说明:创建数据库
Create DATABASE database-name
2 、说明:删除数据库
drop database dbname
3 、说明:备份 sql server
--- 创建 备份数据的 device
USE master
EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat'
--- 开始 备份
BACKUP DATABASE pubs TO testBack
4 、说明:创建新表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)
根据已有的表创建新表:
A : create table tab_new like tab_old ( 使用旧表创建新表 )
B : create table tab_new as select col1,col2 … from tab_old definition only
5 、说明:删除新表 drop table tabname
6 、说明:增加一个列
Alter table tabname add column col type
注:列增加后将不能删除。 DB2 中列加上后数据类型也不能改变,唯一能改变的是增加 varchar 类型的长度。
7 、说明:添加主键: Alter table tabname add primary key(col)
说明:删除主键: Alter table tabname drop primary key(col)
8 、说明:创建索引: create [unique] index idxname on tabname(col … .)
删除索引: drop index idxname
注:索引是不可更改的,想更改必须删除重新建。
9 、说明:创建视图: create view viewname as select statement
删除视图: drop view viewname
10 、说明:几个简单的基本的 sql 语句
选择: select * from table1 where 范围
插入: insert into table1(field1,field2) values(value1,value2)
删除: delete from table1 where 范围
更新: update table1 set field1=value1 where 范围
查找: select * from table1 where field1 like ’ %value1% ’ ---like 的语法很精妙,查资料 !
排序: select * from table1 order by field1,field2 [desc]
总数: select count * as totalcount from table1
求和: select sum(field1) as sumvalue from table1
平均: select avg(field1) as avgvalue from table1
最大: select max(field1) as maxvalue from table1
最小: select min(field1) as minvalue from table1
11 、说明:几个高级查询运算词
A : UNION 运算符
UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2 )并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL ),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2 。
B : EXCEPT 运算符
EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当 ALL 随 EXCEPT 一起使用时 (EXCEPT ALL) ,不消除重复行。
C : INTERSECT 运算符
INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL) ,不消除重复行。
注:使用运算词的几个查询结果行必须是一致的。
12 、说明:使用外连接
A 、 left outer join :
左外连接(左连接):结果集几包括连接表的匹配行,也包括左连接表的所有行。
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
B : right outer join:
右外连接 ( 右连接 ) :结果集既包括连接表的匹配连接行,也包括右连接表的所有行。
C : full outer join :
全外连接:不仅包括符号连接表的匹配行,还包括两个连接表中的所有记录。
1 、单行子查询
select ename,deptno,sal
from emp
where deptno=(select deptno from dept where loc='NEW YORK') ;
2 、多行子查询
SELECT ename,job,sal
FROM EMP
WHERE deptno in ( SELECT deptno FROM dept WHERE dname LIKE 'A%') ;
3 、多列子查询
SELECT deptno,ename,job,sal
FROM EMP
WHERE (deptno,sal) IN (SELECT deptno,MAX(sal) FROM EMP GROUP BY deptno) ;
4 、内联视图子查询
(1)SELECT ename,job,sal,rownum
FROM (SELECT ename,job,sal FROM EMP ORDER BY sal) ;
(2)SELECT ename,job,sal,rownum
FROM ( SELECT ename,job,sal FROM EMP ORDER BY sal)
WHERE rownum<=5 ;
5 、在 HAVING 子句中使用子查询
SELECT deptno,job,AVG(sal) FROM EMP GROUP BY deptno,job HAVING AVG(sal)>(SELECT sal FROM EMP WHERE ename='MARTIN') ;
6 、内连接 左连接 右连接举例;
select sys_user.user_id ,sys_user.user_code from sys_user inner join XZFW_BANJIE onsys_user.user_id=XZFW_BANJIE.userid
小例子:
select top 10 * from sys_user where user_code not in (select user_code from sys_user where user_code like '%yzj%')
select top 2 * from (select top 2 * from td.users order by us_username desc) users order by us_username desc
7 、删除约束语句:
alter table dbo.XZFW_SYS_USER drop CONSTRAINT FK1772E1891324F678
8 、记录数查询
select count(user_pass) from sys_user
select count(*) from sys_user where user_code!='admin'
9 、在范围之间取值 ( between ... and .. 用法 )
select sys_user.user_id,sys_user.user_name,xzfw_shoujian.caseid from sys_user inner join xzfw_shoujian on sys_user.user_id=xzfw_shoujian.userid where user_id between 5 and 100
或 select * from sys_user where user_id<10 and user_id>1
10 、 三表查询实例:(三张表为: USER_DETAILS , Subject , Score )
select USER_DETAILS.USER_NAME,Subject.SubjectName,Score.Score from USER_DETAILS inner join Scoreon USER_DETAILS.USER_ID=Score.USER_ID inner join Subject on Score.SubjectID=Subject.SubjectIDwhere USER_DETAILS.USER_ID=1
常用查询举例:
select * from dbo.USER_DETAILS where USER_NAME='Cheers Li' and USER_POSITION='SQE'
select * from dbo.USER_DEPT
select * from dbo.USER_DETAILS
select top 3* from dbo.USER_DETAILS inner join dbo.USER_DEPT onUSER_DETAILS.USER_DEPT_ID=dbo.USER_DEPT.USER_DEPT_ID
insert into dbo.USER_DEPT (USER_DEPT_ID,USER_DEPT_NAME)values('QE_01','Software quality engineer')
update USER_DEPT set USER_DEPT_ID='QE_02' where USER_DEPT_NAME='Quality Control'
delete from dbo.USER_DEPT where USER_DEPT_ID='QE_01'
select dbo.USER_DETAILS.USER_NAME,dbo.USER_DETAILS.USER_AGE,dbo.USER_DEPT.USER_DEPT_NAME,USER_DEPT.USER_DEPT_ID fromdbo.USER_DETAILS right join dbo.USER_DEPT onUSER_DETAILS.USER_DEPT_ID=dbo.USER_DEPT.USER_DEPT_ID
select count(USER_NAME)from dbo.USER_DETAILS where USER_NAME='Cheers Li'
alter table USER_DEPT add Testcolumn char
alter table USER_DEPT drop column Testcolumn
select top 3* from(select top 3* from dbo.USER_DETAILS where USER_DEPT_ID='DEV_01' order byUSER_AGE desc)aa order by USER_ID desc
select * from dbo.USER_DETAILS where USER_NAME=(select max(USER_NAME) fromdbo.USER_DETAILS)
1. select employees.employee_id,employees.first_name,employees.last_name,salary*(1+0.1) new_salary from hr.employees;
2. select employee_id,first_name from hr.employees where first_name like 'B%';
3. select count(*) from hr.employees where first_name like 'B%';
4. select job_id,avg(salary),sum(salary),max(salary),count(*) from hr.employees group by job_id;
其次,大家来看一些不错的 sql 语句
1 、说明:复制表 ( 只复制结构 , 源表名: a 新表名: b) (Access 可用 )
法一: select * into b from a where 1<>1
法二: select top 0 * into b from a
2 、说明:拷贝表 ( 拷贝数据 , 源表名: a 目标表名: b) (Access 可用 )
insert into b(a, b, c) select d,e,f from b;
3 、说明:跨数据库之间表的拷贝 ( 具体数据使用绝对路径 ) (Access 可用 )
insert into b(a, b, c) select d,e,f from b in ‘具体数据库’ where 条件
例子: ..from b in '"&Server.MapPath(".")&"\data.mdb" &"' where..
4 、说明:子查询 ( 表名 1 : a 表名 2 : b)
select a,b,c from a where a IN (select d from b ) 或者 : select a,b,c from a where a IN (1,2,3)
5 、说明:显示文章、提交人和最后回复时间
select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
6 、说明:外连接查询 ( 表名 1 : a 表名 2 : b)
select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
7 、说明:在线视图查询 ( 表名 1 : a )
select * from (Select a,b,c FROM a) T where t.a > 1;
8 、说明: between 的用法 ,between 限制查询数据范围时包括了边界值 ,not between 不包括
select * from table1 where time between time1 and time2
select a,b,c, from table1 where a not between 数值 1 and 数值 2
9 、说明: in 的使用方法
select * from table1 where a [not] in ( ‘值 1 ’ , ’值 2 ’ , ’值 4 ’ , ’值 6 ’ )
10 、说明:两张关联表,删除主表中已经在副表中没有的信息
delete from table1 where not exists ( select * from table2 where table1.field1=table2.field1 )
11 、说明:四表联查问题:
select * from a left inner join b on a.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where .....
12 、说明:日程安排提前五分钟提醒
SQL: select * from 日程安排 where datediff('minute',f 开始时间 ,getdate())>5
13 、说明:一条 sql 语句搞定数据库分页
select top 10 b.* from (select top 20 主键字段 , 排序字段 from 表名 order by 排序字段 desc) a, 表名 b where b. 主键字段 = a. 主键字段order by a. 排序字段
14 、说明:前 10 条记录
select top 10 * form table1 where 范围
15 、说明:选择在每一组 b 值相同的数据中对应的 a 最大的记录的所有信息 ( 类似这样的用法可以用于论坛每月排行榜 , 每月热销产品分析 , 按科目成绩排名 , 等等 .)
select a,b,c from tablename ta where a=(select max(a) from tablename tb where tb.b=ta.b)
16 、说明:包括所有在 TableA 中但不在 TableB 和 TableC 中的行并消除所有重复行而派生出一个结果表
(select a from tableA ) except (select a from tableB) except (select a from tableC)
17 、说明:随机取出 10 条数据
select top 10 * from tablename order by newid()
18 、说明:随机选择记录
select newid()
19 、说明:删除重复记录
Delete from tablename where id not in (select max(id) from tablename group by col1,col2,...)
20 、说明:列出数据库里所有的表名
select name from sysobjects where type='U'
21 、说明:列出表里的所有的
select name from syscolumns where id=object_id('TableName')
22 、说明:列示 type 、 vender 、 pcs 字段,以 type 字段排列, case 可以方便地实现多重选择,类似 select 中的 case 。
select type,sum(case vender when 'A' then pcs else 0 end),sum(case vender when 'C' then pcs else 0 end),sum(case vender when 'B' then pcs else 0 end) FROM tablename group by type
显示结果:
type vender pcs
电脑 A 1
电脑 A 1
光盘 B 2
光盘 A 2
手机 B 3
手机 C 3
23 、说明:初始化表 table1
TRUNCATE TABLE table1
24 、说明:选择从 10 到 15 的记录
select top 5 * from (select top 15 * from table order by id asc) table_ 别名 order by id desc
数据库基本理论整理:
通俗地理解三个范式
通俗地理解三个范式,对于数据库设计大有好处。在数据库设计中,为了更好地应用三个范式,就必须通俗地理解三个范式 ( 通俗地理解是够用的理解,并不是最科学最准确的理解 ) :
第一范式: 1NF 是对属性的原子性约束,要求属性具有原子性,不可再分解;
第二范式: 2NF 是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性;
第三范式: 3NF 是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。
没有冗余的数据库设计可以做到。但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。
基本表及其字段之间的关系 , 应尽量满足第三范式。但是,满足第三范式的数据库设计,往往不是最好的设计。为了提高数据库的运行效率,常常需要降低范式标准:适当增加冗余,达到以空间换时间的目的。
〖例 2 〗:有一张存放商品的基本表,如表 1 所示。“金额”这个字段的存在,表明该表的设计不满足第三范式,因为“金额”可以由“单价”乘以“数量”得到,说明“金额”是冗余字段。但是,增加“金额”这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法。
在 Rose 中,规定列有两种类型:数据列和计算列。“金额”这样的列被称为“计算列”,而“单价”和“数量”这样的列被称为“数据列”。
表 1 商品表的表结构
商品名称 商品型号 单价 数量 金额
电视机 29 吋 2500 40 100,000
In which case(s) would you use an outer join?
create table T{k int unsigned not null auto_increment,a date,b varchar(24),c int,d varchar(24),primary key(k),unique key a_index (a DESC,b DESC),key k1(b),key k2(c),key k3(d));
select b from WHERE b like 'aaa%';
select a,b,c from T WHERE a='2015-10-25' ORDER BY a,b;
愚认为:题目中的索引b是降序,而B,C两个选项都是升序,故会导致效率降低。而A,D两个选项没有指定升序降序,故会按照其定义的索引a desc,b desc 来进行操作,故而效率较高。所以选A,D。这是我的想法。。。如有不对,可指正ISAM文件系统中采用多级索引的目的是()分题呀,请记住:加索引的唯一目的就是为了提高查询检索性能,但一定程度上肯定会对其他操作的性能有影响,如果没有影响,那全部加索引就ok了,但是这显然不现实滴下面关于存储过程的描述不正确的是?存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象,任何一个设计良好的数据库应用程序都应该用到存储过程。对于满足SQL92标准的SQL语句:(顺序)疑问select foo,count(foo)from pokes where foo>10group by foo having count (*)>5 order by fooSQL 不同于与其他编程语言的最明显特征是处理代码的顺序。在大数编程语言中,代码按编码顺序被处理,但是在SQL语言中,第一个被处理的子句是FROM子句,尽管SELECT语句第一个出现,但是几乎总是最后被处理。每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只是最后一步生成的表才会返回 给调用者。如果没有在查询中指定某一子句,将跳过相应的步骤。下面是对应用于SQL server 2000和SQL Server 2005的各个逻辑步骤的简单描述。
( 8 ) SELECT ( 9 ) DISTINCT ( 11 ) < Top Num > < select list > ( 1 ) FROM [ left_table ] ( 3 ) < join_type > JOIN < right_table > ( 2 ) ON < join_condition > ( 4 ) WHERE < where_condition > ( 5 ) GROUP BY < group_by_list > ( 6 ) WITH < CUBE | RollUP > ( 7 ) HAVING < having_condition > ( 10 ) ORDER BY < order_by_list >逻辑查询处理阶段简介
- FROM:对FROM子句中的前两个表执行笛卡尔积(Cartesian product)(交叉联接),生成虚拟表VT1
- ON:对VT1应用ON筛选器。只有那些使<join_condition>为真的行才被插入VT2。
- OUTER(JOIN):如 果指定了OUTER JOIN(相对于CROSS JOIN 或(INNER JOIN),保留表(preserved table:左外部联接把左表标记为保留表,右外部联接把右表标记为保留表,完全外部联接把两个表都标记为保留表)中未找到匹配的行将作为外部行添加到 VT2,生成VT3.如果FROM子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤1到步骤3,直到处理完所有的表为止。
- WHERE:对VT3应用WHERE筛选器。只有使<where_condition>为true的行才被插入VT4.
- GROUP BY:按GROUP BY子句中的列列表对VT4中的行分组,生成VT5.
- CUBE|ROLLUP:把超组(Suppergroups)插入VT5,生成VT6.
- HAVING:对VT6应用HAVING筛选器。只有使<having_condition>为true的组才会被插入VT7.
- SELECT:处理SELECT列表,产生VT8.
- DISTINCT:将重复的行从VT8中移除,产生VT9.
- ORDER BY:将VT9中的行按ORDER BY 子句中的列列表排序,生成游标(VC10).
- TOP:从VC10的开始处选择指定数量或比例的行,生成表VT11,并返回调用者。
注:步骤10,按ORDER BY子句中的列列表排序上步返回的行,返回游标VC10.这一步是第一步也是唯一一步可以使用SELECT列表中的列别名的步骤。这一步不同于其它步骤的 是,它不返回有效的表,而是返回一个游标。SQL是基于集合理论的。集合不会预先对它的行排序,它只是成员的逻辑集合,成员的顺序无关紧要。对表进行排序 的查询可以返回一个对象,包含按特定物理顺序组织的行。ANSI把这种对象称为游标。理解这一步是正确理解SQL的基础。

绑定变量是相对文本变量来讲的,所谓文本变量是指在SQL直接书写查询条件,这样的SQL在不同条件下需要反复解析,绑定变量是指使用变量来代替直接书写条件,查询bind value在运行时传递,然后绑定执行。优点是减少硬解析,降低CPU的争用,节省shared_pool ;缺点是不能使用histogram,sql优化比较困难左外连接的结果集包括 LEFT OUTER 子句中指定的左表的所有行,而不仅仅是连接列所匹配的行
右外连接是左向外连接的反向连接。将返回右表的所有行。
全外连接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
内连接使用比较运算符根据每个表共有的列的值匹配两个表中的行。
下面有关sql绑定变量的描述,说法错误的是?
Mysql查询时,只有满足联接条件的记录才包含在查询结果,这种联接是()。疑惑
联接可分为以下几类:
在 FROM 子句中指定外联接时,可以由下列几组关键字中的一组指定:LEFT JOIN 或 LEFT OUTER JOIN。
左向外联接的结果集包括 LEFT OUTER 子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。 RIGHT JOIN 或 RIGHT OUTER JOIN。
右向外联接是左向外联接的反向联接。将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。FULL JOIN 或 FULL OUTER JOIN。
完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
交叉联接。 交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
SELECT AVG(score) FROM test WHERE class<3 GROUP BY ALL class
1班 72
2班 75
3班 NULL
则最有可能的查询语句是以下:
A. 在关系模型中数据的逻辑结构是一张二维表(A正确) B. SQL语句是介于关系代数和关系演算之间的(结构化查询)语言(B错 ) C. 关系模型的完整性 包括实体完整性 域完整性 参照完整性和用户定义完整性。 域完整性,实体完整性和参照完整性,是关系模型必须满足的完整性约束条件。(C错 不完整) D. 关系是一张表,表中的每行(即数据库中的每条记录)是一个元组,每列是一个属性。(D错 说反了)
声明一个名为books_cursor的游标,和名为@book_name的游标变量,以下语句正确的是() 疑问
fetch next from books_cursor into @book_name
declare cur cursor dynamic//声明游标forselect * from stuopen curdeclare @id int,@name nvarchar(12),@age int,@sex nvarchar(5),@a int//声明游标变量fetch next from cur into @id,@name,@age,@sex,@awhile @@fetch_status = 0beginprint cast(@id as nvarchar)+@name+cast(@age as nvarchar)+@sex+cast(@a as nvarchar)fetch next from cur into @id,@name,@age,@sex,@aendclose curdeallocate curgo
下面哪些方法可以用来诊断oracle IO、CPU、性能状况。AV$SQLAREA本视图持续跟踪所有shared pool中的共享cursor,在shared pool中的每一条SQL语句都对应一列。本视图在分析SQL语句资源使用方面非常重要。B通过Statspack我们可以很容易的确定Oracle数据库的瓶颈所有,记录数据库性能状态,也可以使远程技术人员迅速了解的的数据库运行状况。Csql_trace是oracle提供的一个非常好的跟踪工具,主要用来检查数据库的异常情况,通过跟踪数据库的活动,找到有问题的语句。D它提供了任何情况下session在数据库中当前正在等待什么(如果session当前什么也没在做,则显示它最后的等待事件)。当系统存在性能问题时,本视图可以做为一个起点指明探寻问题的方向。
事务日志用于保存()事务日志用以保存数据库数据的变动,包括增删改等操作。下列关于视图与基本表的对比正确的是(视图的定义功能强于基本表)
视图可以定义在多张表上,因此定义功能比表强。视图中数据更新受到诸多限制,例如不能有聚集函数,不能是定义在多张表上等,因此操作功能弱于表。视图的数据控制功能和表的数据控制功能相当,都有GRANT、REVOKE。现有表user,字段:userid,username, salary, deptid,email; 表department,字段:deptid, deptname;下面应采用检查约束来实现?选C:用检查约束(check)来检查输入数值的合法性alter table useradd constraint CK_SALARY check(salary > 1000)A:外键约束Foreign Key,选项中说明了department与user两张表的数据具有相关约束性alter table useradd constraint CK_DEPID foreign key(depid) references department (depid)B:唯一性约束Unique,确保userid字段不重复add constraint CK_USERID unique(userid)D:没用到约束以下选项中哪些是SQL的DML语句?DML(data manipulation language)是数据操纵语言:它们是UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言,增删查改。DDL(data definition language)是数据定义语言:DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用。DCL(DataControlLanguage)是数据库控制语言:是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。
ANSI SQL语句分成以下六类(按使用频率排列):
数据查询语言(DQL):其语句,也称为“数据检索语句”,用以从表中获得数据,确定数据怎样在应用程序给出。保留字SELECT是DQL(也是所有SQL)用得最多的动词,其他DQL常用的保留字有WHERE,ORDER BY,GROUP BY和HAVING。这些DQL保留字常与其他类型的SQL语句一起使用。
数据操作语言(DML):其语句包括动词INSERT,UPDATE和DELETE。它们分别用于添加,修改和删除表中的行。也称为动作查询语言。
事务处理语言(TPL):它的语句能确保被DML语句影响的表的所有行及时得以更新。TPL语句包括BEGIN TRANSACTION,COMMIT和ROLLBACK。
数据控制语言(DCL):它的语句通过GRANT或REVOKE获得许可,确定单个用户和用户组对数据库对象的访问。某些RDBMS可用GRANT或REVOKE控制对表单个列的访问。
数据定义语言(DDL):其语句可在数据库中创建新表(CREAT TABLE);为表加入索引等。DDL包括许多与人数据库目录中获得数据有关的保留字。它也是动作查询的一部分。
指针控制语言(CCL):它的语句,像DECLARE CURSOR,FETCH INTO和UPDATE WHERE CURRENT用于对一个或多个表单独行的操作。根据关系数据库规范范理论,关系数据库中的关系要满足第一范式,在部门关系中,因哪个属性而使它不满足第一范式?()1、第一范式(1NF) 在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。 所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。例如,对于图3-2 中的员工信息表,不能将员工信息都放在一列中显示,也不能将其中的两列或多列在一列中显示;员工信息表的每一行只表示一个员工的信息,一个员工的信息在表中只出现一次。简而言之,第一范式就是无重复的列。2、第二范式(2NF) 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。如图3-2 员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是唯一的,因此每个员工可以被唯一区分。这个唯一属性列被称为主关键字或主键、主码。 第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。简而言之,第二范式就是非主属性非部分依赖于主关键字。3、第三范式(3NF) 满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在图3-2的员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性。
表的主键特点中,说法不正确的是(主键可以定义在表级或列级)
主键可以有多个属性,这样就是复合主键,其中单个属性不能称之为主键。假设表A的复合主键是A1、A2,则“主键的一列”的含义应该是A1和A2的值,而不仅仅只是A1或A2的值一个表只能定义一个主键
如下SQL语句中,____可能返回null值。(1) select count(*) from t1;
(2) select max(col1) from t1;(3) select concat('max=',max(col1)) from t1;(1)返回的是表的行数,如果没有记录,应该返回0,不会出现NULL,(2) 和(3) 正常情况下不会出现NULL,但是如果表里面没有记录,则会出现NULL(疑问)9i中的数据保护模式包括有?数据库Oracle 9i :最大保护(Maximum protection )这种模式能够保证在primary Database发生故障保证数据不丢失。在这种模式下,事务提交前,要保证Redo数据已经写入到Primary Database的Online Redologs,同时写入Standby Database的Standby Redologs,并确保至少在一个Standby Database中可用。如果Standby Database不可用,Primary Database将会shutdown。
最高可用性(Maximum availability)
这种模式在不影响Primary Database可用的前提下,提供最高级别的数据保护策略,这种模式也能够确保数据不丢失。事务提交之前,要保证Redo数据已经写入到Primary Database的Online Redologs,同时写入Standby Database的Standby Redologs,确保至少在一个Standby Database中可用。与最大保护模式不同的是,如果Standby Database出现故障导致不可用,Primary Database并不会被shutdown,而是自动转换为最高性能模式,等Standby Database恢复正常后,Primary Database又会自动切换到最高可用性模式。
最大性能(Maximum performance)
这是一种默认的保护模式。事务可以随时提交,当前Primary Database的Redo数据至少需要写入一个Standby Database,不过这种方式不会等待Standby Database是否写入的确认因此这种写入属于异步写入。
对于工资表结构如下(员工编号,姓名,部门,工资),如果要对查询的结果按照部门升序与工资降序进行排序,则下列排序正确的是()desc降序,asc升序,默认是asc(升序),所以就是B C了
在视图上使用INSERT语句,下列()情况可以进行插入操作.视图除了进行查询记录外,也可以利用视图进行插入、更新、删除记录的操作,减少对基表中信息的直接操作,提高了数据的安全性。
在视图上使用INSERT语句添加数据时,要符合以下规则。
(1)使用INSERT语句向数据表中插入数据时,用户必须有插入数据的权利。
(2)由于视图只引用表中的部分字段,所以通过视图插入数据时只能明确指定视图中引用的字段的取值。而那些表中并未引用的字段,必须知道在没有指定取值的情况下如何填充数据,因此视图中未引用的字段必须具备下列条件之一。
该字段允许空值。
该字段设有默认值。
该字段是标识字段,可根据标识种子和标识增量自动填充数据。
该字段的数据类型为timestamp或uniqueidentifier。
(3)视图中不能包含多个字段值的组合,或者包含使用统计函数的结果。
(4)视图中不能包含DISTINCT或GROUP BY子句。
(5)如果视图中使用了WITH CHECK OPTION,那么该子句将检查插入的数据是否符合视图定义中SELECT语句所设置的条件。如果插入的数据不符合该条件,SQL Server会拒绝插入数据。
(6)不能在一个语句中对多个基础表使用数据修改语句。因此,如果要向一个引用了多个数据表的视图添加数据时,必须使用多个INSERT语句进行添加。
下面哪些方法可以用来诊断oracle IO、CPU、性能状况。select foo,count(foo)from pokes where foo>10group by foo having count (*)>5 order by foo 1、from子句组装来自不同数据源的数据;2、where子句基于指定的条件对记录行进行筛选;
3、group by子句将数据划分为多个分组;
4、使用聚集函数进行计算; sum,avg
5、使用having子句筛选分组;
6、select计算所有的表达式;
7、使用order by对结果集进行排序。
有关数据冗余说法错误的是在数据库设计阶段,一定要尽最大可能避免数据冗余,最好做到无数据冗余。有一些必需的数据冗余是用来建立表之间的联系
关系模式R(a,b,c,d,)中关系代数表达式σ3<'4'(R)等价于SQL语句?
五个基本操作:
并(∪)、差(-)、笛卡尔积(×)、选择(σ)、投影(π)
四个组合操作:
2、数据量超过300的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的主列字段,一般是选择性较好的字段;
B、复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
C、如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
D、如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
E、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
8、频繁进行数据操作的表,不要建立太多的索引;
9、删除无用的索引,避免对执行计划造成负面影响;
1.#是把传入的数据当作字符串,如#user_id_list#传入的是1,2,则sql语句生成是这样,in ('1,2') ,
2.$传入的数据直接生成在sql里,如$user_id_list$传入的是1,2,则sql语句生成是这样,in(1,2).
3.#方式能够很大程度防止sql注入.
4.$方式无法方式sql注入.
5.$方式一般用于传入数据库对象.例如传入表名.
$str$ 出来的效果是 str
2、 占用存储空间少的字段更适合选作索引的关键字。例如,与字符串相比,整数字段占用的存储空间较少,因此,较为适合选作索引关键字。
3、 存储空间固定的字段更适合选作索引的关键字。与 text 类型的字段相比, char 类型的字段较为适合选作索引关键字。
4、 Where 子句中经常使用的字段应该创建索引,分组字段或者排序字段应该创建索引,两个表的连接字段应该创建索引。
5、 更新频繁的字段不适合创建索引,不会出现在 where 子句中的字段不应该创建索引。
6、 最左前缀原则。
7、 尽量使用前缀索引。
SELECT S# FORM SC WHERE C#=“C2” AND GRADE>=ALL (SELECT GRADE FORM SC WHERE C#=“C2”
一、 SQL 基本语句
SQL 分类:
DDL —数据定义语言 (Create , Alter , Drop , DECLARE)
DML —数据操纵语言 (Select , Delete , Update , Insert)
DCL —数据控制语言 (GRANT , REVOKE , COMMIT , ROLLBACK)
首先 , 简要介绍基础语句:
1 、说明:创建数据库
Create DATABASE database-name
2 、说明:删除数据库
drop database dbname
3 、说明:备份 sql server
--- 创建 备份数据的 device
USE master
EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat'
--- 开始 备份
BACKUP DATABASE pubs TO testBack
4 、说明:创建新表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)
根据已有的表创建新表:
A : create table tab_new like tab_old ( 使用旧表创建新表 )
B : create table tab_new as select col1,col2 … from tab_old definition only
5 、说明:删除新表 drop table tabname
6 、说明:增加一个列
Alter table tabname add column col type
注:列增加后将不能删除。 DB2 中列加上后数据类型也不能改变,唯一能改变的是增加 varchar 类型的长度。
7 、说明:添加主键: Alter table tabname add primary key(col)
说明:删除主键: Alter table tabname drop primary key(col)
8 、说明:创建索引: create [unique] index idxname on tabname(col … .)
删除索引: drop index idxname
注:索引是不可更改的,想更改必须删除重新建。
9 、说明:创建视图: create view viewname as select statement
删除视图: drop view viewname
10 、说明:几个简单的基本的 sql 语句
选择: select * from table1 where 范围
插入: insert into table1(field1,field2) values(value1,value2)
删除: delete from table1 where 范围
更新: update table1 set field1=value1 where 范围
查找: select * from table1 where field1 like ’ %value1% ’ ---like 的语法很精妙,查资料 !
排序: select * from table1 order by field1,field2 [desc]
总数: select count * as totalcount from table1
求和: select sum(field1) as sumvalue from table1
平均: select avg(field1) as avgvalue from table1
最大: select max(field1) as maxvalue from table1
最小: select min(field1) as minvalue from table1
11 、说明:几个高级查询运算词
A : UNION 运算符
UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2 )并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL ),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2 。
B : EXCEPT 运算符
EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当 ALL 随 EXCEPT 一起使用时 (EXCEPT ALL) ,不消除重复行。
C : INTERSECT 运算符
INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL) ,不消除重复行。
注:使用运算词的几个查询结果行必须是一致的。
12 、说明:使用外连接
A 、 left outer join :
左外连接(左连接):结果集几包括连接表的匹配行,也包括左连接表的所有行。
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
B : right outer join:
右外连接 ( 右连接 ) :结果集既包括连接表的匹配连接行,也包括右连接表的所有行。
C : full outer join :
全外连接:不仅包括符号连接表的匹配行,还包括两个连接表中的所有记录。
1 、单行子查询
select ename,deptno,sal
from emp
where deptno=(select deptno from dept where loc='NEW YORK') ;
2 、多行子查询
SELECT ename,job,sal
FROM EMP
WHERE deptno in ( SELECT deptno FROM dept WHERE dname LIKE 'A%') ;
3 、多列子查询
SELECT deptno,ename,job,sal
FROM EMP
WHERE (deptno,sal) IN (SELECT deptno,MAX(sal) FROM EMP GROUP BY deptno) ;
4 、内联视图子查询
(1)SELECT ename,job,sal,rownum
FROM (SELECT ename,job,sal FROM EMP ORDER BY sal) ;
(2)SELECT ename,job,sal,rownum
FROM ( SELECT ename,job,sal FROM EMP ORDER BY sal)
WHERE rownum<=5 ;
5 、在 HAVING 子句中使用子查询
SELECT deptno,job,AVG(sal) FROM EMP GROUP BY deptno,job HAVING AVG(sal)>(SELECT sal FROM EMP WHERE ename='MARTIN') ;
6 、内连接 左连接 右连接举例;
select sys_user.user_id ,sys_user.user_code from sys_user inner join XZFW_BANJIE onsys_user.user_id=XZFW_BANJIE.userid
小例子:
select top 10 * from sys_user where user_code not in (select user_code from sys_user where user_code like '%yzj%')
select top 2 * from (select top 2 * from td.users order by us_username desc) users order by us_username desc
7 、删除约束语句:
alter table dbo.XZFW_SYS_USER drop CONSTRAINT FK1772E1891324F678
8 、记录数查询
select count(user_pass) from sys_user
select count(*) from sys_user where user_code!='admin'
9 、在范围之间取值 ( between ... and .. 用法 )
select sys_user.user_id,sys_user.user_name,xzfw_shoujian.caseid from sys_user inner join xzfw_shoujian on sys_user.user_id=xzfw_shoujian.userid where user_id between 5 and 100
或 select * from sys_user where user_id<10 and user_id>1
10 、 三表查询实例:(三张表为: USER_DETAILS , Subject , Score )
select USER_DETAILS.USER_NAME,Subject.SubjectName,Score.Score from USER_DETAILS inner join Scoreon USER_DETAILS.USER_ID=Score.USER_ID inner join Subject on Score.SubjectID=Subject.SubjectIDwhere USER_DETAILS.USER_ID=1
常用查询举例:
select * from dbo.USER_DETAILS where USER_NAME='Cheers Li' and USER_POSITION='SQE'
select * from dbo.USER_DEPT
select * from dbo.USER_DETAILS
select top 3* from dbo.USER_DETAILS inner join dbo.USER_DEPT onUSER_DETAILS.USER_DEPT_ID=dbo.USER_DEPT.USER_DEPT_ID
insert into dbo.USER_DEPT (USER_DEPT_ID,USER_DEPT_NAME)values('QE_01','Software quality engineer')
update USER_DEPT set USER_DEPT_ID='QE_02' where USER_DEPT_NAME='Quality Control'
delete from dbo.USER_DEPT where USER_DEPT_ID='QE_01'
select dbo.USER_DETAILS.USER_NAME,dbo.USER_DETAILS.USER_AGE,dbo.USER_DEPT.USER_DEPT_NAME,USER_DEPT.USER_DEPT_ID fromdbo.USER_DETAILS right join dbo.USER_DEPT onUSER_DETAILS.USER_DEPT_ID=dbo.USER_DEPT.USER_DEPT_ID
select count(USER_NAME)from dbo.USER_DETAILS where USER_NAME='Cheers Li'
alter table USER_DEPT add Testcolumn char
alter table USER_DEPT drop column Testcolumn
select top 3* from(select top 3* from dbo.USER_DETAILS where USER_DEPT_ID='DEV_01' order byUSER_AGE desc)aa order by USER_ID desc
select * from dbo.USER_DETAILS where USER_NAME=(select max(USER_NAME) fromdbo.USER_DETAILS)
1. select employees.employee_id,employees.first_name,employees.last_name,salary*(1+0.1) new_salary from hr.employees;
2. select employee_id,first_name from hr.employees where first_name like 'B%';
3. select count(*) from hr.employees where first_name like 'B%';
4. select job_id,avg(salary),sum(salary),max(salary),count(*) from hr.employees group by job_id;
其次,大家来看一些不错的 sql 语句
1 、说明:复制表 ( 只复制结构 , 源表名: a 新表名: b) (Access 可用 )
法一: select * into b from a where 1<>1
法二: select top 0 * into b from a
2 、说明:拷贝表 ( 拷贝数据 , 源表名: a 目标表名: b) (Access 可用 )
insert into b(a, b, c) select d,e,f from b;
3 、说明:跨数据库之间表的拷贝 ( 具体数据使用绝对路径 ) (Access 可用 )
insert into b(a, b, c) select d,e,f from b in ‘具体数据库’ where 条件
例子: ..from b in '"&Server.MapPath(".")&"\data.mdb" &"' where..
4 、说明:子查询 ( 表名 1 : a 表名 2 : b)
select a,b,c from a where a IN (select d from b ) 或者 : select a,b,c from a where a IN (1,2,3)
5 、说明:显示文章、提交人和最后回复时间
select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
6 、说明:外连接查询 ( 表名 1 : a 表名 2 : b)
select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
7 、说明:在线视图查询 ( 表名 1 : a )
select * from (Select a,b,c FROM a) T where t.a > 1;
8 、说明: between 的用法 ,between 限制查询数据范围时包括了边界值 ,not between 不包括
select * from table1 where time between time1 and time2
select a,b,c, from table1 where a not between 数值 1 and 数值 2
9 、说明: in 的使用方法
select * from table1 where a [not] in ( ‘值 1 ’ , ’值 2 ’ , ’值 4 ’ , ’值 6 ’ )
10 、说明:两张关联表,删除主表中已经在副表中没有的信息
delete from table1 where not exists ( select * from table2 where table1.field1=table2.field1 )
11 、说明:四表联查问题:
select * from a left inner join b on a.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where .....
12 、说明:日程安排提前五分钟提醒
SQL: select * from 日程安排 where datediff('minute',f 开始时间 ,getdate())>5
13 、说明:一条 sql 语句搞定数据库分页
select top 10 b.* from (select top 20 主键字段 , 排序字段 from 表名 order by 排序字段 desc) a, 表名 b where b. 主键字段 = a. 主键字段order by a. 排序字段
14 、说明:前 10 条记录
select top 10 * form table1 where 范围
15 、说明:选择在每一组 b 值相同的数据中对应的 a 最大的记录的所有信息 ( 类似这样的用法可以用于论坛每月排行榜 , 每月热销产品分析 , 按科目成绩排名 , 等等 .)
select a,b,c from tablename ta where a=(select max(a) from tablename tb where tb.b=ta.b)
16 、说明:包括所有在 TableA 中但不在 TableB 和 TableC 中的行并消除所有重复行而派生出一个结果表
(select a from tableA ) except (select a from tableB) except (select a from tableC)
17 、说明:随机取出 10 条数据
select top 10 * from tablename order by newid()
18 、说明:随机选择记录
select newid()
19 、说明:删除重复记录
Delete from tablename where id not in (select max(id) from tablename group by col1,col2,...)
20 、说明:列出数据库里所有的表名
select name from sysobjects where type='U'
21 、说明:列出表里的所有的
select name from syscolumns where id=object_id('TableName')
22 、说明:列示 type 、 vender 、 pcs 字段,以 type 字段排列, case 可以方便地实现多重选择,类似 select 中的 case 。
select type,sum(case vender when 'A' then pcs else 0 end),sum(case vender when 'C' then pcs else 0 end),sum(case vender when 'B' then pcs else 0 end) FROM tablename group by type
显示结果:
type vender pcs
电脑 A 1
电脑 A 1
光盘 B 2
光盘 A 2
手机 B 3
手机 C 3
23 、说明:初始化表 table1
TRUNCATE TABLE table1
24 、说明:选择从 10 到 15 的记录
select top 5 * from (select top 15 * from table order by id asc) table_ 别名 order by id desc
数据库基本理论整理:
通俗地理解三个范式
通俗地理解三个范式,对于数据库设计大有好处。在数据库设计中,为了更好地应用三个范式,就必须通俗地理解三个范式 ( 通俗地理解是够用的理解,并不是最科学最准确的理解 ) :
第一范式: 1NF 是对属性的原子性约束,要求属性具有原子性,不可再分解;
第二范式: 2NF 是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性;
第三范式: 3NF 是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。
没有冗余的数据库设计可以做到。但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。
基本表及其字段之间的关系 , 应尽量满足第三范式。但是,满足第三范式的数据库设计,往往不是最好的设计。为了提高数据库的运行效率,常常需要降低范式标准:适当增加冗余,达到以空间换时间的目的。
〖例 2 〗:有一张存放商品的基本表,如表 1 所示。“金额”这个字段的存在,表明该表的设计不满足第三范式,因为“金额”可以由“单价”乘以“数量”得到,说明“金额”是冗余字段。但是,增加“金额”这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法。
在 Rose 中,规定列有两种类型:数据列和计算列。“金额”这样的列被称为“计算列”,而“单价”和“数量”这样的列被称为“数据列”。
表 1 商品表的表结构
商品名称 商品型号 单价 数量 金额
电视机 29 吋 2500 40 100,000
下列关于视图与基本表的对比正确的是()
3. 而且视图是永远不会自己消失的除非你删除它。
视图有时会对提高效率有帮助。临时表几乎是不会对性能有帮助,是资源消耗者。
视图一般随该数据库存放在一起,临时表永远都是在tempdb里的。
4.视图适合于多表连接浏览时使用!不适合增、删、改.,存储过程适合于使用较频繁的SQL语句,这样可以提高 执行效率!
视图和表的区别和联系
区别:1、视图是已经编译好的sql语句。而表不是
2、视图没有实际的物理记录。而表有。
3、表是内容,视图是窗口
4、表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,但视图只能有创建的语句来修改
5、表是内模式,视图是外模式
6、视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构。
7、表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表。
8、视图的建立和删除只影响视图本身,不影响对应的基本表。
联系: 视图(view)是在基本表之上建立的表,它的结构(即所定义的列)和内容(即所有数据行)都来自基本表,它依据基本表存在而存在。一个视图可以对应一个基本表,也可以对应多个基本表。视图是基本表的抽象和在逻辑意义上建立的新关系。
数据表建建立复合索引tab_index(“name”,”age”),下面哪些语句能用上索引?( )
复合索引的结构与电话簿类似,它首先按姓氏对雇员进行排序,然后按名字对所有姓氏相同的雇员进行排序。如果您知道姓氏,电话簿将非常有用,如果您知道名字和姓氏,电话簿则更为有用,但如果您只知道名字而不知道姓氏,电话簿将没有用处。所以复合索引,字段的先后顺序是很重要的。 列的顺序:在创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。以下不同的数据库类型中,哪些不属于关系数据库范畴
在数据库系统中,产生不一致的根本原因是( )
数据库中有可能会存在不一致的数据。
造成数据不一致的原因主要有:
- 数据冗余
如果数据库中存在冗余数据,比如两张表中都存储了用户的地址,在用户的地址发生改变时,如果只更新了一张表中的数据,那么这两张表中就有了不一致的数据。
- 并发控制不当
比如某个订票系统中,两个用户在同一时间订同一张票,如果并发控制不当,可能会导致一张票被两个用户预订的情况。当然这也与元数据的设计有关。
- 故障和错误
如果软硬件发生故障造成数据丢失等情况,也可能引起数据不一致的情况。因此我们需要提供数据库维护和数据恢复的一些措施。
下面描述中不属于数据库系统特点的是?
下面()组命令,将变量count值赋值为1
关于关系型数据库,正确且全面的描述是:
A. 在关系模型中数据的逻辑结构是一张二维表(A正确) B. SQL语句是介于关系代数和关系演算之间的(结构化查询)语言(B错 ) C. 关系模型的完整性 包括实体完整性 域完整性 参照完整性和用户定义完整性。 域完整性,实体完整性和参照完整性,是关系模型必须满足的完整性约束条件。(C错 不完整) D. 关系是一张表,表中的每行(即数据库中的每条记录)是一个元组,每列是一个属性。(D错 说反了)
要删除表A中数据,使用TRUNCATE TABLE A。运行结果是?
表A中的约束依然存在
有订单表orders,包含字段用户信息userid,字段产品信息productid,以下语句能够返回至少被订购过两会的productid?
- select productid from orders group by productid having count(productid)>1
- select productid from orders where count(productid)>1(错误)
count()为聚合函数,需要和having关键词联合使用,是对groupby之后非分组字段的计数操作。所以D
下列sql语句中哪条语句可为用户zhangsan分配数据库userdb表userinfo的查询和插入数据权限()。
grant select,insert on userdb.userinfo to'zhangsan'@'localhost'
格式应该是:grant [权限] on [table] to 'username'@'localhost';
下列选项中,不属于SQL约束的是:
NOT NULL : 用于控制字段的内容一定不能为空(NULL)。
UNIQUE : 控制字段内容不能重复,一个表允许有多个 Unique 约束。
PRIMARY KEY: 也是用于控制字段内容不能重复,但它在一个表只允许出现一个。
FOREIGN KEY: FOREIGN KEY 约束用于预防破坏表之间连接的动作,FOREIGN KEY 约束也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
CHECK: 用于控制字段的值范围。
DEFAULT: 用于设置新记录的默认值。
现有表book,主键bookid设为标识列。若执行语句:select * into book2 from book, 以下说法正确的是?
若数据库中已存在表book2, 则会提示错误
若数据库中不存在表book2, 则语句执行成功,并且表book2中的bookid自动设为标识。select into from 和 insert into select都是用来复制表,两者的主要区别为: select into from 要求目标表不存在,因为在插入时会自动创建。insert into select from 要求目标表存在
数据库中事务隔离分为4个级别,其中允许“不可重复读”的有?
数据库事务的隔离级别有4个,由低到高依次为Read uncommitted 、Read committed、Repeatable read 、Serializable ,这四个级别可以逐个解决脏读 、不可重复读 、幻读 这几类问题。
√: 可能出现 ×: 不会出现
脏读不可重复读幻读Read uncommitted√√√Read committed×√√Repeatable read××√Serializable×××
注意:我们讨论隔离级别的场景,主要是在多个事务并发 的情况下,因此,接下来的讲解都围绕事务并发。
Read uncommitted 读未提交
公司发工资了,领导把5000元打到singo的账号上,但是该事务并未提交,而singo正好去查看账户,发现工资已经到账,是5000元整,非常高 兴。可是不幸的是,领导发现发给singo的工资金额不对,是2000元,于是迅速回滚了事务,修改金额后,将事务提交,最后singo实际的工资只有 2000元,singo空欢喜一场。

出现上述情况,即我们所说的脏读 ,两个并发的事务,“事务A:领导给singo发工资”、“事务B:singo查询工资账户”,事务B读取了事务A尚未提交的数据。
当隔离级别设置为Read uncommitted 时,就可能出现脏读,如何避免脏读,请看下一个隔离级别。
Read committed 读提交
singo拿着工资卡去消费,系统读取到卡里确实有2000元,而此时她的老婆也正好在网上转账,把singo工资卡的2000元转到另一账户,并在 singo之前提交了事务,当singo扣款时,系统检查到singo的工资卡已经没有钱,扣款失败,singo十分纳闷,明明卡里有钱,为 何......
出现上述情况,即我们所说的不可重复读 ,两个并发的事务,“事务A:singo消费”、“事务B:singo的老婆网上转账”,事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
当隔离级别设置为Read committed 时,避免了脏读,但是可能会造成不可重复读。
大多数数据库的默认级别就是Read committed,比如Sql Server , Oracle。如何解决不可重复读这一问题,请看下一个隔离级别。
Repeatable read 重复读
当隔离级别设置为Repeatable read 时,可以避免不可重复读。当singo拿着工资卡去消费时,一旦系统开始读取工资卡信息(即事务开始),singo的老婆就不可能对该记录进行修改,也就是singo的老婆不能在此时转账。
虽然Repeatable read避免了不可重复读,但还有可能出现幻读 。
singo的老婆工作在银行部门,她时常通过银行内部系统查看singo的信用卡消费记录。有一天,她正在查询到singo当月信用卡的总消费金额 (select sum(amount) from transaction where month = 本月)为80元,而singo此时正好在外面胡吃海塞后在收银台买单,消费1000元,即新增了一条1000元的消费记录(insert transaction ... ),并提交了事务,随后singo的老婆将singo当月信用卡消费的明细打印到A4纸上,却发现消费总额为1080元,singo的老婆很诧异,以为出 现了幻觉,幻读就这样产生了。
注:Mysql的默认隔离级别就是Repeatable read。
Serializable 序列化
Serializable 是最高的事务隔离级别,同时代价也花费最高,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻像读。
(1)索引概念:
索引是由用户创建,能够被修改和删除的,实际存储在数据库中的物理存在,它是某一个表中一列或者若干列值的集合和相应的指向表中物理标志这些值的数据页的逻辑指针清单。
(2)索引的优点:
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能
(3)索引的缺点:
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果 要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维 护速度。
(4)索引的分类:
① 聚集索引,表数据按照索引的顺序来存储的。对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。
② 非聚集索引,表数据存储顺序与索引顺序无关。对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,该层紧邻数据页,其行数量与数据表行数据量一致。
③ 在一张表上只能创建一个聚集索引,因为真实数据的物理顺序只可能是一种。如果一张表没有聚集索引,那么它被称为“堆集”(Heap)。这样的表中的数据行没有特定的顺序,所有的新行将被添加的表的末尾位置。
(5)索引一般可以通过B树实现


