rcnn、fast-rcnn和faster-rcnn
来源:互联网 发布:2017非农数据公布时间 编辑:程序博客网 时间:2024/04/30 15:12
链接:https://www.zhihu.com/question/35887527/answer/99689222
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
R-CNN:针对区域提取做CNN的object detction。
<img src="https://pic1.zhimg.com/36bb2ec6663657eff23edcef578fe3b0_b.jpg" data-rawwidth="629" data-rawheight="220" class="origin_image zh-lightbox-thumb" width="629" data-original="https://pic1.zhimg.com/36bb2ec6663657eff23edcef578fe3b0_r.jpg">-----------------
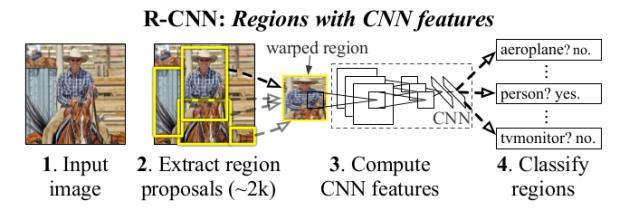 -----------------
-----------------SPPNet:针对不同尺寸输入图片,在CNN之后的Feature Map上进行相同维度的区域分割并Pooling,转化成相同尺度的向量。但是分类用的是SVM。
<img src="https://pic3.zhimg.com/ebe688fcc009229fe58cd039130505e6_b.jpg" data-rawwidth="469" data-rawheight="313" class="origin_image zh-lightbox-thumb" width="469" data-original="https://pic3.zhimg.com/ebe688fcc009229fe58cd039130505e6_r.jpg">-------------------------
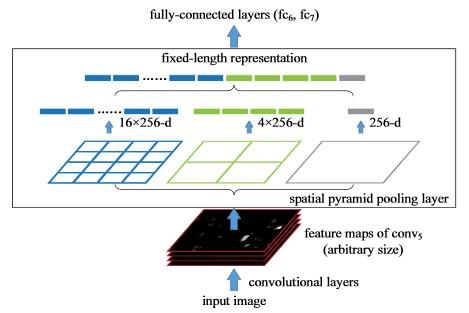 -------------------------
-------------------------Fast R-CNN:区域提取转移到Feature Map之后做,这样不用对所有的区域进行单独的CNN Forward步骤。同时最终一起回归bounding box和类别。
<img src="https://pic2.zhimg.com/1f34b695ed44113f901dbee0e7c6b425_b.jpg" data-rawwidth="361" data-rawheight="140" class="content_image" width="361">------------------------
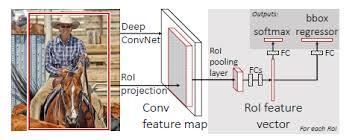 ------------------------
------------------------1.为什么做Faster-rcnn
a. SPPnet 和 Fast R-CNN 已经减少了detection步骤的执行时间,只剩下region proposal成为瓶颈
b. 因此提出了 Region Proposal Network(RPN) 用来提取检测区域,并且和整个检测网络共享卷积部分的特征。RPN同时训练区域的边界和objectness score(理解为是否可信存在oject)。
c. 最终把RPN和Fast-RCNN合并在一起,用了“attention” mechanisms(其实就是说共享这事)。在VOC数据集上可以做到每张图只提300个proposals(Fast-RCNN用selective search是2000个)。
2.继续阐述现存问题
Fast-RCNN已经做到了Region Proposal在卷积以后,这样大大减少了卷积作用的次数,全图的Feature Map提取同样只是做一次。目前最大的问题就是 Selective Search是耗时的瓶颈(CPU上大概2s一张)。尤其是这个方法没有应用在GPU上,优化比较难。RPN共享网络,可以做到每张10ms,并且一起在GPU上进行了。
3.具体网络构建
在前面全图Feature Map的基础上, RPN又增加了几个卷积层和FC层。是一种可以END-to-END训练的FullyConvNet(其实就说单独训练RPN自己的这些层)。为了统一RPN和Fast R-CNN的网络,具体实现就是在RPN和Fast-RCNN之间选择性切换,实际各训练了两次。最终结果,即使选择了VGG里最复杂的网络,仍然可以做到5fps的速度。
<img src="https://pic1.zhimg.com/455d3697e6431c4d77b1b1edf53cd1fc_b.png" data-rawwidth="220" data-rawheight="229" class="content_image" width="220">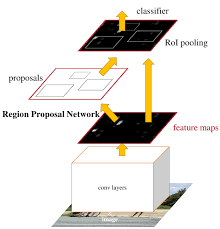
实现的时候,前面feature map之前的网络是shareable convolutional layers(VGG有13层,ZF有5层,不同的模型不一样)。RPN的具体实现就不说了,3x3尺寸的filter,卷积一层,后面几个FC,假如每个点上proposal k种不同的尺度和比例(论文里定义k=9),输出就有4*k的尺度信息(位置2维,长宽各一维)和2*k的判断信息(是否是object)。RPN的一个重大优点在于translation invariant,因为是针对各个点周围3X3进行独立卷积的,后面的 RPN整个网络的权重又是共享的。而如果MultiBox方法的话,核心k-means很难保有这种独立性,毕竟object的位置在图上都是随机的。另外现有的Region Proposal方法基本上是构建image pyramid或者是filter pyramid的基础上,这里就是真的实现了Single filter,Single scale。
4.LOSS定义和训练过程
Loss Function定义包括几个部分,RPN训练的尺度信息的边框(bounding box)部分,每个点对应的k个anchors里和ground truth IoU的overlap最大的标记为正,或者与任何IoU的overlap超过0.7也标记为正。每一个ground truth的box可能会标记给多个anchor。如果anchor与IoU的overlap小于0.3将被标记为负。本身传统方法,IoU在处理bounding的时候,就是所有RP出来的区域类似于先scale到相同尺寸进行预测,共享预测部分的网络的权重,但是在这里反而是每个feature map点周围的3X3区域各进行k个不同权重的scale和size的训练。 RPN训练用的是每个batch来自单张图的proposal。但是各个图占主要部分的negative samples会产生很大的bias。于是每次每张图选择256个随机的anchors,并且保证postive和negative的anchors比例为1:1。RPN本身的部分高斯随机初始化而来,共享部分来自ImageNet之前的训练结果。后面decay,learning rate什么的就不详细说了。训练过程就是固定一部分,训练一部分,RPN和Fast-RCNN交叉着来,定义了很多种,Caffe里实现的,也不具体说了。
----------------------------------------------------------------------------------------------------
首先膜拜RBG大神,这周以前我是不知道这个人的,之前我一直想用移动机器人带摄像头做一些实时object detection的任务,其实自动驾驶上很多人在做了,行人检测什么的。但是我对CNN的作用还一直停留在全图做image classification上。万万没想到,RBG一个人把DPM,以及后来整个object detection的所有任务链全部用CNN实现了(也不能说一个人,还有MSRA的几个华人大牛)。
同时之前我对Caffe的认识也一直停留在C++和命令行接口调用上,今天看了一下py-faster-rcnn的源代码,简直对Caffe有了全新的认识(RBG毕竟也参与了Caffe的开发)。希望早日把源代码搞透,然后试着把Faster-RCNN用在检测其他特定物体的任务上。(源代码学习,个人Blog缓慢更新中Faster R-CNN · Tai Lei Home Page,坑太大,一时半会填不满)。
- FAST-RCNN 和 Faster-RCNN
- rcnn、fast-rcnn和faster-rcnn
- RCNN,Fast-RCNN,Faster-RCNN
- RCNN, Fast RCNN, Faster RCNN
- RCNN -> Fast-RCNN -> Faster-RCNN
- rcnn,fast-rcnn,faster-rcnn
- RCNN, Fast RCNN, Faster RCNN
- RCNN, Fast-RCNN, Faster-RCNN
- RCNN, Fast-RCNN, Faster-RCNN
- RCNN+fast RCNN+faster RCNN
- rcnn, fast-rcnn, faster-rcnn, mask-rcnn
- RCNN, fast RCNN, faster RCNN, mask RCNN
- RCNN & SPP-net & Fast-RCNN & Faster-RCNN
- RCNN & SPP-net & Fast-RCNN & Faster-RCNN
- RCNN & SPP-net & Fast-RCNN & Faster-RCNN
- RCNN--Fast-rcnn--Faster RCNN(思路整理)
- RCNN & SPP-net & Fast-RCNN & Faster-RCNN
- RCNN,Fast RCNN,Faster RCNN 总结
- sift
- button点击无反应
- 益签到软件系统
- public void onItemClick(AdapterView<?> arg0, View view, int position, long arg3)参数解析
- android代码的形式让button变成圆角 透明,如图
- rcnn、fast-rcnn和faster-rcnn
- 空间FFT确定目标位置算法matlab仿真
- 如何在Mongodb中实现数据超时自动删除功能?
- opencv-3.1.0 CMake出现 Downloading opencv_ffmpeg.dll...
- Android事件分发机制完全解析,带你从源码的角度彻底理解(上)
- Android事件分发机制完全解析,带你从源码的角度彻底理解(下)
- Qt之QToolButton
- Android页面跳转器--消除跳转时Activity之间的耦合性
- c++之string类型


