相似性度量--Pearson相关系数
来源:互联网 发布:八一建军节军装照软件 编辑:程序博客网 时间:2024/04/30 03:07
Pearson 相关系数
Pearson 相关系数介绍
pearson是一个介于-1和1之间的值,用来描述两组线性的数据一同变化移动的趋势。
当两个变量的线性关系增强时,相关系数趋于1或-1;当一个变量增大,另一个变量也增大时,表明它们之间是正相关的,相关系数大于0;如果一个变量增大,另一个变量却减小,表明它们之间是负相关的,相关系数小于0;如果相关系数等于0,表明它们之间不存在线性相关关系。
用数学公式表示,皮尔森相关系数等于两个变量的协方差除于两个变量的标准差。

协方差(Covariance):在概率论和统计学中用于衡量两个变量的总体误差。如果两个变量的变化趋于一致,也就是说如果其中一个大于自身的期望值,另一个也大于自身的期望值,那么两个变量之间的协方差就是正值;如果两个变量的变化趋势相反,则协方差为负值。
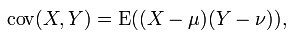
其中u表示X的期望E(X), v表示Y的期望E(Y)
由于pearson描述的是两组数据变化移动的趋势,所以在基于user-based的协同过滤系统中,经常使用。描述用户购买或评分变化的趋势,若趋势相近则pearson系数趋近于1,也就是我们认为相似的用户。
Pearson 相关系数的缺陷
直观的可以看出,pearson不适用于文本的相似性分析。
pearson存在以下3个问题: 以下图的数据作为测试用例
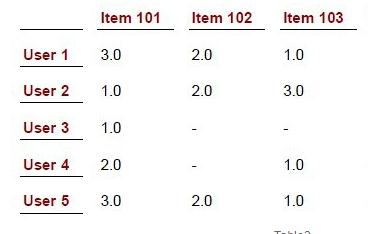
1. 未考虑重叠记录项的数量对相似度的影响
上表中,行表示用户(1~5)对项目(101~103)的一些评分值。直观来看,User1和User5用3个共同的评分项,并且给出的评分趋势相
同,User1与User4只有2个相同评分项,虽然他们的趋势也相似,但是由于102的未知,可能是User2对102未发生行为,或者对102很讨厌,所以我们更希望User1和User5更相似,但结果是User1与User4有着更高的结果。
可以看出pearson系数只会对重叠的记录进行计算。
同样的场景在现实生活中也经常发生,比如两个用户共同观看了200部电影,虽然不一定给出相同或完全相近的评分,但只要他们之间的趋势相似也应该比另一位只观看了2部相同电影的相似度高!但事实并不如此,如果对这两部电影,两个用户给出的相似度相同或很相近,通过Pearson相关性计算出的相似度会明显大于观看了相同的200部电影的用户之间的相似度。
2.如果只有一个重叠项则无法计算相关性
从数学上讲,若只有一个重叠的记录,那么至少有一组记录的标准差为0,导致分母为0
从这一点也可以看出,pearson系数不适用与小的或者非常稀疏的数据集。当然,这一特性也有它的好处,无法计算pearson系数可以认为这两组数据没有任何相关性。
3.如果一组记录的所有评分都一样则无法计算相关性
理由同2.
4.Pearson系数对绝对数值不敏感
考虑这三组数据,1:(1.0,2.0,3.0,4.0),2:(40.0,50.0,70.0,80.0),3:(50.0,60.0,70.0,80.0),我们可以直观的认为2和3更为相似,它们的重叠评分数目一致,趋势也相同,记录1虽然也满足上述的条件,但是它整体数值很低。在现实中,有人习惯于给出更高的评分,而有人则恰恰相反。
利用pearson计算它们之间的相似度为:
1&2: 0.9899494936611665
2&3: 0.9899494936611665
1&3: 0.9999999999999999
可以看出pearson系数对绝对数值并不敏感,它确实只是描述了两组数据变化的趋势。
- 相似性度量--Pearson相关系数
- 相似性度量--Pearson相关系数
- Pearson相关系数
- Pearson相关系数
- Pearson相关系数的疑问
- Pearson Correlation 皮尔逊相关系数
- 相似性度量
- 相似性度量
- 相似性度量
- 相似性度量
- 相似性度量
- 相似性度量
- 相似性度量
- 相似性度量
- 相似性度量
- 相似性度量
- 相似性度量
- 相似性度量
- 【报错】HibernateException:hibernate.cfg.xml not found
- css3 Gradient渐变效果
- 四级联动下拉菜单
- java安全框架-Shiro学习笔记(七)-自定义realm
- Jmeter 中使用Beanshell来引用第三方jar包
- 相似性度量--Pearson相关系数
- javaweb学习总结(三十七)——获得MySQL数据库自动生成的主键
- [LC347] Top K Frequent Elements
- ios各种第三方控件
- 映射关系级别注解
- 关于CLASS , SEL, IMP的说明
- cocos2dx2.2.6版本,android5.0宕机,not valid Modified UTF-8
- [342] Power of Four
- JavaScript 中的一些坑


