决策树生成c++实现(不含剪枝)
来源:互联网 发布:淘宝网谁开发的 编辑:程序博客网 时间:2024/05/20 03:04
数据挖掘课上面老师介绍了下决策树ID3算法,我抽空余时间把这个算法用C++实现了一遍。
决策树算法是非常常用的分类算法,是逼近离散目标函数的方法,学习得到的函数以决策树的形式表示。其基本思路是不断选取产生信息增益最大的属性来划分样例集和,构造决策树。信息增益定义为结点与其子结点的信息熵之差。信息熵是香农提出的,用于描述信息不纯度(不稳定性),其计算公式是
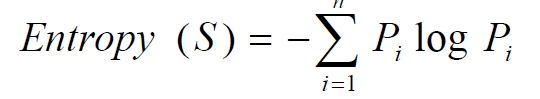
Pi为子集合中不同性(而二元分类即正样例和负样例)的样例的比例。这样信息收益可以定义为样本按照某属性划分时造成熵减少的期望,可以区分训练样本中正负样本的能力,其计算公司是

我实现该算法针对的样例集合如下
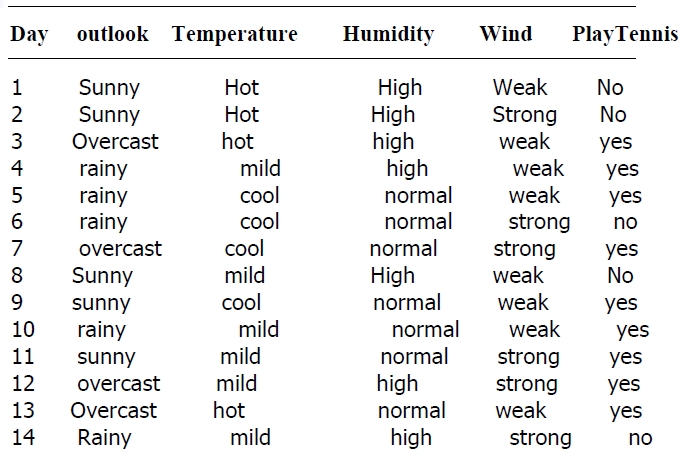
该表记录了在不同气候条件下是否去打球的情况,要求根据该表用程序输出决策树
C++代码如下,程序中有详细注释
以下是我自己分析出来的代码加上注释
#include<iostream>#include<string>#include<vector>#include<map>#include<algorithm>#include<cmath>using namespace std;#define MAXLEN 6 //输入的每行数据的个数vector<vector<string> >state; //实例集vector<string>item(MAXLEN); //对应一行的实例vector<string> attribute_row; //保存首行的属性名string end("end"); //输入结束string yes("yes"); //yesstring no("no"); //string blank(""); map<string,vector<string> >map_attribute_values; //存储属性所对应的所有的值 int tree_size=0; //树的大小struct Node{//决策树的节点 string attribute; //属性值 string arrived_value; //达到的属性值 vector<Node*>childs; //所有的孩子 Node() { attribute=blank; //初始化属性和到达的值为空 arrived_value=blank; //到达的值为为空 } }; Node *root;void Input(){ string s; while(cin>>s,s.compare(end)!=0) {//输入的值不是结束的0的情况下 item[0]=s; for(int i=1;i<MAXLEN;i++) cin>>item[i]; //填充剩下的属性 state.push_back(item); //将填充好的条目放入state表中 } for(int j=0;j<MAXLEN;j++) //最大是6 { attribute_row.push_back(state[0][j]); //填充属性数组 }}//根据数据实例计算属性和值组成的map//得到:以每一个属性为键,它的若干不重复值为值的map表 void ComputeMapFrom2DVector(){ unsigned int i,j,k; bool exited=false; //用于判断是否存在 vector<string>values; for(i=1;i<MAXLEN-1;i++) //对用中间的四个属性 { for(j=1;j<state.size();j++) //列优先遍历每一列 { for(k=0;k<values.size();k++) //遍历当前的values数组查看当前属性值是否存在 if(!values[k].compare(state[j][i])) //如果当前属性值存在 exited=true; //标注在数组中已经存在了 if(!exited) //如果要是不存在 { values.push_back(state[j][i]); //将这个属性存入数组中去 } exited=false; } map_attribute_values[state[0][i]]=values; //简历属性和属性值的映射表 values.erase(values.begin(),values.end()); //清空数据 } } //在剩余的所有数据中判断是不是都是相同的标签 bool AllTheSameLabel(vector<vector<string> >remain_state,string label){ int count=0; // for(unsigned int i=0;i<remain_state.size();i++) { //遍历所有的条目 if(!remain_state[i][MAXLEN-1].compare(label)) //统计和label标签相同的数量 count++; } if(count==remain_state.size()-1) //如果所有的数据都是相同的标签 return true; //返回true else return false; } //计算熵值------数据实例,属性,是否为父节点 double ComputeEntropy(vector<vector<string> >remain_state,string attribute,string value,bool ifparent){ vector<int>count(2,0); unsigned int i,j; bool done_flag=false; //哨兵值 for(j=1;j<MAXLEN;j++) // { if(done_flag)break; if(!attribute_row[j].compare(attribute)) {//找到这个属性 for(i=1;i<remain_state.size();i++) {//对于每一个实例 if((!ifparent&&!remain_state[i][j].compare(value))||ifparent) { if(!remain_state[i][MAXLEN-1].compare(yes)) {//统计yes和no的数量 count[0]++; //yes的数量 } else count[1]++; } } done_flag=true; //处理完每一个属性值之后退出 } } if(count[0]==0||count[1]==0) return 0;//全部都是正实例或者全部都是负实例 //开始计算熵 double sum=count[0]+count[1]; //首先计算实例的数量 double entropy=-count[0]/sum*log(count[0]/sum)/log(2.0)-count[1]/sum*log(count[1]/sum)/log(2.0); return entropy; //返回熵值 }//计算一个属性的信息增益值 double ComputeGain(vector<vector<string> >remain_state,string attribute){ unsigned int j,k,m; //计算熵值 double parent_entropy=ComputeEntropy(remain_state,attribute,blank,true); double children_entropy=0; //孩子的熵 vector<string> values=map_attribute_values[attribute]; //获取这个属性的属性值 vector<double> ratio; vector<int> count_values; int tempint; // for(m=0;m<values.size();m++) {//对于属性中的每一个值 tempint=0; for(k=1;k<MAXLEN-1;k++) {//在属性表中找这个属性 if(!attribute_row[k].compare(attribute)) {//如果找到这个属性 for(j=1;j<remain_state.size();j++) { if(!remain_state[j][k].compare(values[m])) tempint++; //统计这个属性中每一个属性值的个数 } } } count_values.push_back(tempint); //记录每一个属性值的个数 } for(j=0;j<values.size();j++) {//对于每一个属性,计算每一个属性占总实例的比例 ratio.push_back((double)count_values[j]/(double)(remain_state.size()-1)); } double temp_entropy; // for(j=0;j<values.size();j++) {//对于每一个属性值 temp_entropy=ComputeEntropy(remain_state,attribute,values[j],false); //计算每一个属性值的熵 children_entropy+=ratio[j]*temp_entropy; } return (parent_entropy-children_entropy); //返回信息增益值 }//通过属性在总表中找到这个属性的编号 int FindAttributeByName(string attri){ for(int i=0;i<MAXLEN;i++) {//遍历每一个属性 if(!state[0][i].compare(attri)) return i; } cerr<<"不能找到这个属性的编号"<<endl; return 0;} string MostCommonLabel(vector<vector<string> >remain_state){ int p=0,n=0; for(unsigned i=0;i<remain_state.size();i++) {//对于该实例表 if(!remain_state[i][MAXLEN-1].compare(yes)) p++; //找出输入yes标签的 else n++; } if(p>=n) //返回类标签数量最多的 return yes; else return no;}//根节点,原始数据,属性列表 采用递归的思想来进行构建 Node* BuildDecisionTreeDFS(Node *p,vector<vector<string> >remain_state,vector<string>remain_attribute){ if(p==NULL) p=new Node(); //如果P指针要是为空的话就新建一个节点 if(AllTheSameLabel(remain_state,yes)) //如果所有的条目都是yes标签 { p->attribute=yes; //那么属性设置为yes return p; //返回这个节点 } if(AllTheSameLabel(remain_state,no)) //如果所有的类标签都是no { p->attribute=no; //将所有的类标签置为no return p; } if(remain_attribute.size()==0) //如果剩余的属性大小为0 { string label=MostCommonLabel(remain_state); //统计出属性最多的一组 p->attribute=label; //将这组的类标签作为该类的标签 return p; //返回p } double max_gain=0,temp_gain; //最大的信息增益,和临时信息增益变量 vector<string>::iterator max_it=remain_attribute.begin(); //数据的起始迭代器 vector<string>::iterator it1; for(it1=remain_attribute.begin();it1<remain_attribute.end();it1++) {//遍历所有的属性 temp_gain=ComputeGain(remain_state,(*it1)); //计算每个属性的信息增益 if(temp_gain>max_gain) //获取最大的信息增益 { max_gain=temp_gain; //获取最大的信息增益值 max_it=it1; //获取拥有最大信息增益之的属性 } } //根据信息增益值最大的属性来进行样例的划分 //并且跟新样例集和属性集 vector<string>new_attribute; //新的属性集 vector<vector<string> >new_state; //新的样例集 for(vector<string>::iterator it2=remain_attribute.begin();it2<remain_attribute.end();it2++) {//对于原始属性集 if((*it2).compare(*max_it)) //将除了拥有最大信息增益的属性加入新的属性表中 new_attribute.push_back(*it2); } //确定了最佳划分属性 p->attribute=*max_it; //当前节点的属性值置为刚才获取的”最大“属性 vector<string>values=map_attribute_values[*max_it]; //获取这个属性的属性值 int attribute_num=FindAttributeByName(*max_it); //找到这个属性的编号 new_state.push_back(attribute_row); //构建新的数据表 for(vector<string>::iterator it3=values.begin();it3<values.end();it3++) {//遍历最大属性表中的每一个值 for(unsigned int i=1;i<remain_state.size();i++) {//对于实例表中的每一个实例 if(!remain_state[i][attribute_num].compare(*it3)) {//对于实例表中分割属性每一个值的每一个实例 new_state.push_back(remain_state[i]); } } //对于分割属性的每一个值 Node *new_node=new Node(); //新建一个节点 new_node->arrived_value=*it3; //这是将要通往的属性值 if(new_state.size()==0) {//如果当前属性值的实例表为空 new_node->attribute=MostCommonLabel(remain_state); //将类标签最多的给这个类最为类标签 } else BuildDecisionTreeDFS(new_node,new_state,new_attribute); //如果 都不是一个标签,并且大小还都不是0那么就再次划分 p->childs.push_back(new_node); //构建好之后将这个节点作为p的孩子节点 new_state.erase(new_state.begin()+1,new_state.end()); //将除了属性名之外的数据清空 } return p;}void Tdisplay(vector<vector<string> >data);int main(){ Input(); //填充数据值 vector<string>remain_attribute; //主要的属性数组 string Outlook("Outlook"); string Temperature("Temperature"); string Humidity("Humidity"); string Wind("Wind"); remain_attribute.push_back(Outlook); //将这些属性存入属性数组中去 remain_attribute.push_back(Temperature); remain_attribute.push_back(Humidity); remain_attribute.push_back(Wind); vector<vector<string> >remain_state; //剩余的数据 for(unsigned int i=0;i<state.size();i++) //遍历数据表的大小 remain_state.push_back(state[i]); //复制一份原始数据 ComputeMapFrom2DVector(); //构建属性和值的映射表 root=BuildDecisionTreeDFS(root,remain_state,remain_attribute); //构建决策树 //树根,原始数据,4个属性数组 return 0; }void Tdisplay(vector<vector<string> >data){ cout<<endl<<"测试数据"<<endl; for(int i=0;i<data.size();i++) { for(int j=0;j<data[i].size();j++) cout<<data[i][j]<<" "; cout<<endl; } cout<<endl<<"测试数据"<<endl;}原作者代码
#include <iostream>#include <string>#include <vector>#include <map>#include <algorithm>#include <cmath>using namespace std;#define MAXLEN 6//输入每行的数据个数//多叉树的实现 //1 广义表//2 父指针表示法,适于经常找父结点的应用//3 子女链表示法,适于经常找子结点的应用//4 左长子,右兄弟表示法,实现比较麻烦//5 每个结点的所有孩子用vector保存//教训:数据结构的设计很重要,本算法采用5比较合适,同时//注意维护剩余样例和剩余属性信息,建树时横向遍历考循环属性的值,//纵向遍历靠递归调用vector <vector <string> > state;//实例集vector <string> item(MAXLEN);//对应一行实例集vector <string> attribute_row;//保存首行即属性行数据string end("end");//输入结束string yes("yes");string no("no");string blank("");map<string,vector < string > > map_attribute_values;//存储属性对应的所有的值int tree_size = 0;struct Node{//决策树节点string attribute;//属性值string arrived_value;//到达的属性值vector<Node *> childs;//所有的孩子Node(){attribute = blank;arrived_value = blank;}};Node * root;//根据数据实例计算属性与值组成的mapvoid ComputeMapFrom2DVector(){unsigned int i,j,k;bool exited = false;vector<string> values;for(i = 1; i < MAXLEN-1; i++){//按照列遍历for (j = 1; j < state.size(); j++){for (k = 0; k < values.size(); k++){if(!values[k].compare(state[j][i])) exited = true;}if(!exited){values.push_back(state[j][i]);//注意Vector的插入都是从前面插入的,注意更新it,始终指向vector头}exited = false;}map_attribute_values[state[0][i]] = values;values.erase(values.begin(), values.end());}}//根据具体属性和值来计算熵double ComputeEntropy(vector <vector <string> > remain_state, string attribute, string value,bool ifparent){vector<int> count (2,0);unsigned int i,j;bool done_flag = false;//哨兵值for(j = 1; j < MAXLEN; j++){if(done_flag) break;if(!attribute_row[j].compare(attribute)){for(i = 1; i < remain_state.size(); i++){if((!ifparent&&!remain_state[i][j].compare(value)) || ifparent){//ifparent记录是否算父节点if(!remain_state[i][MAXLEN - 1].compare(yes)){count[0]++;}else count[1]++;}}done_flag = true;}}if(count[0] == 0 || count[1] == 0 ) return 0;//全部是正实例或者负实例//具体计算熵 根据[+count[0],-count[1]],log2为底通过换底公式换成自然数底数double sum = count[0] + count[1];double entropy = -count[0]/sum*log(count[0]/sum)/log(2.0) - count[1]/sum*log(count[1]/sum)/log(2.0);return entropy;}//计算按照属性attribute划分当前剩余实例的信息增益double ComputeGain(vector <vector <string> > remain_state, string attribute){unsigned int j,k,m;//首先求不做划分时的熵double parent_entropy = ComputeEntropy(remain_state, attribute, blank, true);double children_entropy = 0;//然后求做划分后各个值的熵vector<string> values = map_attribute_values[attribute];vector<double> ratio;vector<int> count_values;int tempint;for(m = 0; m < values.size(); m++){tempint = 0;for(k = 1; k < MAXLEN - 1; k++){if(!attribute_row[k].compare(attribute)){for(j = 1; j < remain_state.size(); j++){if(!remain_state[j][k].compare(values[m])){tempint++;}}}}count_values.push_back(tempint);}for(j = 0; j < values.size(); j++){ratio.push_back((double)count_values[j] / (double)(remain_state.size()-1));}double temp_entropy;for(j = 0; j < values.size(); j++){temp_entropy = ComputeEntropy(remain_state, attribute, values[j], false);children_entropy += ratio[j] * temp_entropy;}return (parent_entropy - children_entropy);}int FindAttriNumByName(string attri){for(int i = 0; i < MAXLEN; i++){if(!state[0][i].compare(attri)) return i;}cerr<<"can't find the numth of attribute"<<endl; return 0;}//找出样例中占多数的正/负性string MostCommonLabel(vector <vector <string> > remain_state){int p = 0, n = 0;for(unsigned i = 0; i < remain_state.size(); i++){if(!remain_state[i][MAXLEN-1].compare(yes)) p++;else n++;}if(p >= n) return yes;else return no;}//判断样例是否正负性都为labelbool AllTheSameLabel(vector <vector <string> > remain_state, string label){int count = 0;for(unsigned int i = 0; i < remain_state.size(); i++){if(!remain_state[i][MAXLEN-1].compare(label)) count++;}if(count == remain_state.size()-1) return true;else return false;}//计算信息增益,DFS构建决策树//current_node为当前的节点//remain_state为剩余待分类的样例//remian_attribute为剩余还没有考虑的属性//返回根结点指针Node * BulidDecisionTreeDFS(Node * p, vector <vector <string> > remain_state, vector <string> remain_attribute){//if(remain_state.size() > 0){//printv(remain_state);//}if (p == NULL)p = new Node();//先看搜索到树叶的情况if (AllTheSameLabel(remain_state, yes)){p->attribute = yes;return p;}if (AllTheSameLabel(remain_state, no)){p->attribute = no;return p;}if(remain_attribute.size() == 0){//所有的属性均已经考虑完了,还没有分尽string label = MostCommonLabel(remain_state);p->attribute = label;return p;}double max_gain = 0, temp_gain;vector <string>::iterator max_it = remain_attribute.begin();vector <string>::iterator it1;for(it1 = remain_attribute.begin(); it1 < remain_attribute.end(); it1++){temp_gain = ComputeGain(remain_state, (*it1));if(temp_gain > max_gain) {max_gain = temp_gain;max_it = it1;}}//下面根据max_it指向的属性来划分当前样例,更新样例集和属性集vector <string> new_attribute;vector <vector <string> > new_state;for(vector <string>::iterator it2 = remain_attribute.begin(); it2 < remain_attribute.end(); it2++){if((*it2).compare(*max_it)) new_attribute.push_back(*it2);}//确定了最佳划分属性,注意保存p->attribute = *max_it;vector <string> values = map_attribute_values[*max_it];int attribue_num = FindAttriNumByName(*max_it);new_state.push_back(attribute_row);for(vector <string>::iterator it3 = values.begin(); it3 < values.end(); it3++){for(unsigned int i = 1; i < remain_state.size(); i++){if(!remain_state[i][attribue_num].compare(*it3)){new_state.push_back(remain_state[i]);}}Node * new_node = new Node();new_node->arrived_value = *it3;if(new_state.size() == 0){//表示当前没有这个分支的样例,当前的new_node为叶子节点new_node->attribute = MostCommonLabel(remain_state);}else BulidDecisionTreeDFS(new_node, new_state, new_attribute);//递归函数返回时即回溯时需要1 将新结点加入父节点孩子容器 2清除new_state容器p->childs.push_back(new_node);new_state.erase(new_state.begin()+1,new_state.end());//注意先清空new_state中的前一个取值的样例,准备遍历下一个取值样例}return p;}void Input(){string s;while(cin>>s,s.compare(end) != 0){//-1为输入结束item[0] = s;for(int i = 1;i < MAXLEN; i++){cin>>item[i];}state.push_back(item);//注意首行信息也输入进去,即属性}for(int j = 0; j < MAXLEN; j++){attribute_row.push_back(state[0][j]);}}void PrintTree(Node *p, int depth){for (int i = 0; i < depth; i++) cout << '\t';//按照树的深度先输出tabif(!p->arrived_value.empty()){cout<<p->arrived_value<<endl;for (int i = 0; i < depth+1; i++) cout << '\t';//按照树的深度先输出tab}cout<<p->attribute<<endl;for (vector<Node*>::iterator it = p->childs.begin(); it != p->childs.end(); it++){PrintTree(*it, depth + 1);}}void FreeTree(Node *p){if (p == NULL)return;for (vector<Node*>::iterator it = p->childs.begin(); it != p->childs.end(); it++){FreeTree(*it);}delete p;tree_size++;}int main(){Input();vector <string> remain_attribute;string outlook("Outlook");string Temperature("Temperature");string Humidity("Humidity");string Wind("Wind");remain_attribute.push_back(outlook);remain_attribute.push_back(Temperature);remain_attribute.push_back(Humidity);remain_attribute.push_back(Wind);vector <vector <string> > remain_state;for(unsigned int i = 0; i < state.size(); i++){remain_state.push_back(state[i]); }ComputeMapFrom2DVector();root = BulidDecisionTreeDFS(root,remain_state,remain_attribute);cout<<"the decision tree is :"<<endl;PrintTree(root,0);FreeTree(root);cout<<endl;cout<<"tree_size:"<<tree_size<<endl;return 0;}训练数据如下:
Day Outlook Temperature Humidity Wind PlayTennis1 Sunny Hot High Weak no2 Sunny Hot High Strong no3 Overcast Hot High Weak yes4 Rainy Mild High Weak yes5 Rainy Cool Normal Weak yes6 Rainy Cool Normal Strong no7 Overcast Cool Normal Strong yes8 Sunny Mild High Weak no9 Sunny Cool Normal Weak yes10 Rainy Mild Normal Weak yes11 Sunny Mild Normal Strong yes12 Overcast Mild High Strong yes13 Overcast Hot Normal Weak yes14 Rainy Mild High Strong noend
程序输出决策树如下
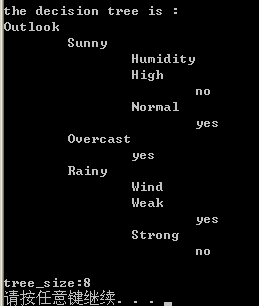
可以用图形表示为
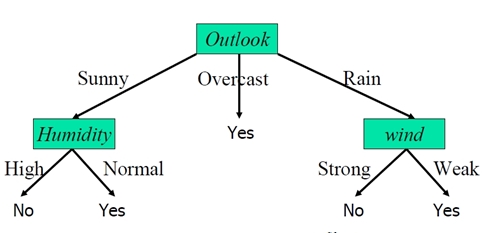
有了决策树后,就可以根据气候条件做预测了
例如如果气候数据是{Sunny,Cool,Normal,Strong} ,根据决策树到左侧的yes叶节点,可以判定会去游泳。
另外在编写这个程序时在数据结构的设计上面走了弯路,多叉树的实现有很多方法,本算法采用每个结点的所有孩子用vector保存比较合适,同时注意维护剩余样例和剩余属性信息,建树时横向遍历靠循环属性的值,纵向遍历靠递归调用 ,总体是DFS,树和图的遍历在编程时经常遇到,得熟练掌握。程序有些地方的效率还得优化,有不足的点地方还望大家拍砖。
另外这里有一份CART的实现,由于代码过多不贴出来,以下是下载地址:
http://download.csdn.net/detail/jialeheyeshu/9567888
0 0
- 决策树生成c++实现(不含剪枝)
- 决策树剪枝简单python实现
- 决策树(ID3)c++实现(未剪枝)
- 决策树算法 生成 剪枝 in Python
- 决策树-Cart生成和剪枝算法
- 决策树-剪枝算法(二)
- 决策树剪枝算法(二)
- 决策树-剪枝
- 决策树剪枝中的损失函数的实现
- 机器学习笔记(九)——决策树的生成与剪枝
- 决策树系列(二)——剪枝
- Python 实现决策树 ID3 C4.5 悲观剪枝
- 决策树的剪枝策略
- 决策树的剪枝理论
- 决策树的剪枝理论
- 决策树剪枝算法
- 决策树剪枝算法
- CART决策树剪枝
- EPROCESS 结构
- Linux 查看CPU信息的命令
- 汉诺塔问题
- 免费电子面单Api_快递鸟接口JAVA对接调用案例
- 手把手教你做安豆计算器(五)-优化资源的使用
- 决策树生成c++实现(不含剪枝)
- 混杂模式就安全了?--只谈配置混杂模式
- docker存储驱动知识汇总
- C#学习笔记之正则表达式
- 常见浏览器兼容性问题与解决方案
- javascript barcodescanner插件 可以扫描QR和PDF417码
- opensuse linux环境下telnet源码编译安装步骤
- github使用笔记
- spring boot 之 hello world !


