SparkML之分类(四)决策树
来源:互联网 发布:网络创业计划书 编辑:程序博客网 时间:2024/04/30 12:19
说起树,不得不首先提起的二个人就是Leo Breiman和John Ross Quinlan ,他俩在树這快做了很大的贡献,如果对他所做工作感兴趣的可以访问参考文献[1][5]
现在我们抛开一切,从我们最熟悉的分段函数开始,如下函数:

函数图像如下:

图1:分段函数
matlab代码如下:
x = -10:0.1:10;y = (-x-2).*(x < -1)+x.*(x >=-1&x <= 1)+(-x+2).*(x >1);plot(x,y)text(-6,4,'\leftarrow y = -x-2','FontSize',9)text(0,0,'y = x','FontSize',9)text(4,-2,'\leftarrow y =-x+2 ','FontSize',9)xlabel('x')ylabel('y')假如我们还没有并行的思想。那么我们处理這个函数的思想如下。

图2:分段函数分析流程图
其实我们在处理分段函数的时候,就已经包含了“决策树”的思想。
然而,在实际应用中,最难的一点就是 对应法则(函数)是什么?可以说整个应用数学的工作就是针对实际问题,
来寻找它的对应法则(函数)。决策树也是如此,它核心工作就是通过历史数据来训练一颗“树” ,這棵树就是 一个
对应法则(函数)。
1、决策树
如下就是一个决策树[3]:
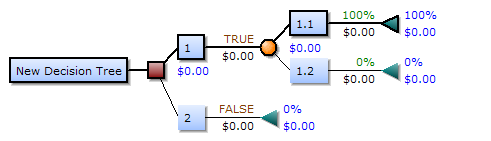
图3:决策树
一颗决策树有三种类型的节点:
(1)Decision nodes(决策点) - commonly represented by squares(矩形框来表示)
(2)Chance nodes(状态节点) - represented by circles(圆圈来表示)
(3)End nodes(结果节点) - represented by triangles(三角形来表示)
如果我们按照树节点,又可分为:根节点、中间节点和叶节点,如下图:

图4:节点说明
2、基础概念
(1)信息熵
信息熵是用来度量整个信息源X整体的不确定性。假设某个事物具有n个互相独立的可能结果(状态):
,每一种结果出现的概率分别为
。且有:
那么该事物所有的不确定性为:
其中:是
的信息量。信息熵就是這个
,它是指信息量的期望值。
如果是在某个条件下,假设是在Y下,那么信息熵的表达式为:
(2)信息增益(information gain )
信息增益是指信息前后的差值,即决策树在划分之后的一个信息差值:
gain() = infobeforeSplit() - infoafterSplit()
那么有:
其中:I(Y;X)是特征X对训练集Y的信息增益.
那么可以推理出下面定理:
1、信息是互称的

2、用概率的形式有如下表达

3、如果X和Y没有信息来往

4、如果X=Y

(3)信息增益率(Information gain ratio)
信息增益比就相当于我们函数求导一样。它展示的信息变化率。(Y是训练集,X是特征)
(4)基尼杂质(Gini impurity)
Gini公式如下:

其中是某个分区内的第i个标签的频率,m是该分区的类别总数。Gini公式计算的是类型被分错的可能性。
3、决策树学习
通过历史数据,放入训练的算法中,训练得到我们的决策树。训练决策树有很多的方法,罗列如下[4]:
(1)ID3 (Iterative Dichotomiser 3)
(2)C4.5 (successor of ID3)
(3)CART (Classification And Regression Tree)
(4)CHAID (CHi-squared Automatic Interaction Detector). Performs multi-level splits when computing classification trees.
(5)MARS: extends decision trees to handle numerical data better.
(6)Conditional Inference Trees. Statistics-based approach that uses non-parametric tests as splitting criteria, corrected for multiple testing to avoid overfitting. This approach results in unbiased predictor selection and does not require pruning.
现在分析ID3和C4.5,它们都是出自Ross Quinlan之手,可以访问他的主页在这方面的工作和进展[5]。其中C4.5是在ID3上进行改进的。现在我们结合Quinlan于1986年在Machine Learning《Induction of Decision Trees》[6]上的数据进行阐述两个算法。数据如下:

图5
数据说明:表中一共有14天,每一行中的四个参数(outlook Temperature Humidity Windy)是一天中记录的属性
最后一列是指是否可以出去玩。
3.1、ID3算法
ID3算法是一个有监督的学习算法,起于概念学习系统(Concept Learning System,CLS),下面流程图是
ID3算法流程图,参数说明:R:图5Attributes部分,C:target,图5class部分,S是R+C,图5整个训练集。

案例实现


ID3算法的缺点
(1)、ID3算法只能对描述属性为离散性的属性的数据集构造决策树
(2)、ID3算法在选择各部分分支节点的评价标准是信息增益,那么导致了会选择取值较多的属性,然后這些属性又
不会提供太多有用的信息。
3.2、C4.5算法
选择分节点的标准是把
,都是求最大的那个最为下一个节点。再次就不赘述了。
3.3 剪枝(Pruning)
当我们建立好一颗树的时候,有的时候,历史数据输入进去,我们预测的百分百,但是一遇到噪声,导致误差
很大。這就是过拟合原因。决策树也是如此。当我树叶太多了,那么稳定性就差。所以当我们考虑有一个良好的稳
定性的时候。就需要解决這种过拟合的问题。剪枝就是解决這个问题。
偷个懒,具体如何剪枝可以参考文献[7].
4、spark源码分析(大图:链接:http://pan.baidu.com/s/1c0ucDg 密码:1kt5)

5、实验
import org.apache.spark.{SparkConf, SparkContext}// $example on$import org.apache.spark.mllib.tree.DecisionTreeimport org.apache.spark.mllib.tree.model.DecisionTreeModelimport org.apache.spark.mllib.util.MLUtilsobject DecisionTreeRegressionExample { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("DecisionTreeRegressionExample").setMaster("local") val sc = new SparkContext(conf) val data = MLUtils.loadLibSVMFile(sc, "C:\\Users\\alienware\\IdeaProjects\\sparkCore\\data\\mllib\\sample_libsvm_data.txt") // Split the data into training and test sets (30% held out for testing) val splits = data.randomSplit(Array(0.7, 0.3)) val (trainingData, testData) = (splits(0), splits(1)) // Train a DecisionTree model. // Empty categoricalFeaturesInfo indicates all features are continuous. val categoricalFeaturesInfo = Map[Int, Int]() val impurity = "variance" val maxDepth = 5 val maxBins = 32 val model = DecisionTree.trainRegressor(trainingData, categoricalFeaturesInfo, impurity, maxDepth, maxBins) // Evaluate model on test instances and compute test error val labelsAndPredictions = testData.map { point => val prediction = model.predict(point.features) (point.label, prediction) } val testMSE = labelsAndPredictions.map{ case (v, p) => math.pow(v - p, 2) }.mean() println("Test Mean Squared Error = " + testMSE) println("Learned regression tree model:\n" + model.toDebugString) /** * Test Mean Squared Error = 0.0 Learned regression tree model: DecisionTreeModel regressor of depth 2 with 5 nodes If (feature 434 <= 0.0) If (feature 100 <= 165.0) Predict: 0.0 Else (feature 100 > 165.0) Predict: 1.0 Else (feature 434 > 0.0) Predict: 1.0 */ // Save and load model model.save(sc, "target/tmp/myDecisionTreeRegressionModel") val sameModel = DecisionTreeModel.load(sc, "target/tmp/myDecisionTreeRegressionModel") // $example off$ }}
1、https://www.stat.berkeley.edu/~breiman/
2、breiman L,:Random forests.Machine Learing.2001.18 45:5-3(https://www.stat.berkeley.edu/~breiman/randomforest2001.pdf)
3、https://en.wikipedia.org/wiki/Decision_tree
4、https://en.wikipedia.org/wiki/Decision_tree_learning
5、http://www.rulequest.com/Personal/
6、http://hunch.net/~coms-4771/quinlan.pdf
7、http://www.cs.waikato.ac.nz/~eibe/pubs/thesis.final.pdf
- SparkML之分类(四)决策树
- SparkML实战之四:回归
- SparkML实战之四:回归
- SparkML之分类(一)贝叶斯分类
- SparkML之分类(二)logistics回归
- SparkML之分类(三)支持向量机(SVM)
- 分类算法之决策树
- 分类算法之决策树
- sklearn之分类决策树
- 决策树分类算法之ID3
- 分类决策树原理及实现(四)
- SparkML之DistributedMatrix(一)
- SparkML之相关性分析
- sparkML之kmeans聚类
- 决策树之分类回归树(C&RT)
- 数据挖掘之决策树分类模型
- 分类算法之决策树(Decision tree)
- 文本分类算法之决策树.ID3实现
- Java中线程入门
- SparkML之分类(一)贝叶斯分类
- SparkML之分类(二)logistics回归
- SparkML之分类(三)支持向量机(SVM)
- 1510. Mispelling
- SparkML之分类(四)决策树
- SparkML之聚类(一)Kmeans聚类
- 1561. PRIME
- SparkML之聚类(二)高斯混合模型(GMMs)
- SparkML之特征提取(一)主成分分析(PCA)
- Swift编程规范之 Naming
- SparkML之特征提取(二)词项加权之DF-IDF
- 3497. 水仙花数
- SparkML之推荐算法(一)ALS


