canal源码分析——parse模块源码分析
来源:互联网 发布:怎么开淘宝网店及货源 编辑:程序博客网 时间:2024/05/17 23:23
高层类图
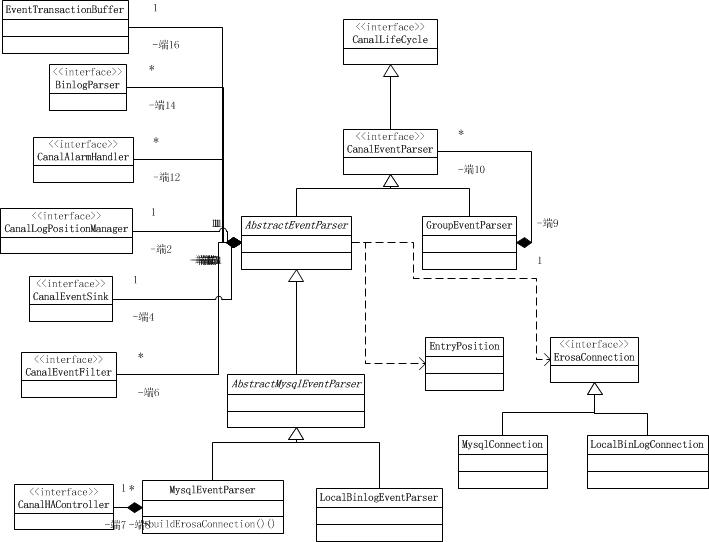
首先,我们来看看该模块下面的类图,通过类图就可以清晰地掌握整个模块的骨架结构。
EventTransactionBuffer是事件事务缓存区。它主要是在内存中开辟一个缓冲区,避免过高的flush频率导致的IO次数过度而导致的性能问题。
CanalEventParser是数据复制的控制器。该接口是核心的数据复制接口。
CanalLogPositionManager是日志的位置管理器。提供了读取和存储当前日志位置的接口。
CanalHAController是高可用的复制控制器。
图中所有接口都实现了CanalLifeCycle(生命周期接口)。
AbstractEventParser是一个模板方法的抽闲实现类,它 最大化共用mysql/oracle版本的实现类,提供了一些抽象方法交给子类实现。
AbstractMysqlEventParser是抽象的MySQL日志复制控制器的模板类。共享了MySQL的日志复制控制实现。
LocalBinlogEventParser是基于本地MySQL的binlog文件的复制控制器实现类。
MysqlEventParser是基于向mysql server复制binlog实现类。该实现类是MySQL使用最多的一种实现方式。
GroupEventParser是合多个EventParser进行合并处理,group只是做为一个delegate处理。它是一个组合模式的实现。
从上图所示可以看出,canal项目并未实现oracle数据库的日志复制器的实现,也就是不支持oracle数据库。
MysqlEventParser时序图
从类图中的介绍可以看出MysqlEventParser 是我们最核心的一个实现类,本文将重点描述该类的一个时序。

AbstractEventParser类源码解析
该类似parse模块中最核心的一个类, 它是一个事件解析的一个模板方法类,定义了事件解析的一个公共流程,几乎所有的子类都是扩展自该类的,因此阅读该类能够掌握最核心的binlog事件解析流程。
解析器对象实例化
public AbstractEventParser(){ // 初始化一下 transactionBuffer = new EventTransactionBuffer(new TransactionFlushCallback() { public void flush(List<CanalEntry.Entry> transaction) throws InterruptedException { boolean successed = consumeTheEventAndProfilingIfNecessary(transaction); if (!running) { return; } if (!successed) { throw new CanalParseException("consume failed!"); } LogPosition position = buildLastTransactionPosition(transaction); if (position != null) { // 可能position为空 logPositionManager.persistLogPosition(AbstractEventParser.this.destination, position); } } }); }首先看上述代码,它是构造方法中的代码,实例化本对象的同时,也实例化了一个EventTransactionBuffer对象。传入了一个TransactionFlushCallback的回调匿名类对象。回调类中定义了一个flush方法,该方法实现的内容是先消费事件,如果消费成功了,则存储当前的position。如果消费失败则抛出异常信息。EventTransactionBuffer写缓冲区的使用,是一种应对高并发的手段,它相当于在内存中收集一个个的事件,然后再批量的调用flush方法。这个与日志中的实现是一样的。
启动解析器方法
public void start() { super.start(); MDC.put("destination", destination); // 配置transaction buffer // 初始化缓冲队列 transactionBuffer.setBufferSize(transactionSize);// 设置buffer大小 transactionBuffer.start(); // 构造bin log parser binlogParser = buildParser();// 初始化一下BinLogParser binlogParser.start(); // 启动工作线程 parseThread = new Thread(new Runnable() { public void run() { MDC.put("destination", String.valueOf(destination)); ErosaConnection erosaConnection = null; while (running) { try { // 开始执行replication // 1. 构造Erosa连接 erosaConnection = buildErosaConnection(); // 2. 启动一个心跳线程 startHeartBeat(erosaConnection); // 3. 执行dump前的准备工作 preDump(erosaConnection); erosaConnection.connect();// 链接 // 4. 获取最后的位置信息 final EntryPosition startPosition = findStartPosition(erosaConnection); if (startPosition == null) { throw new CanalParseException("can't find start position for " + destination); } logger.info("find start position : {}", startPosition.toString()); // 重新链接,因为在找position过程中可能有状态,需要断开后重建 erosaConnection.reconnect(); final SinkFunction sinkHandler = new SinkFunction<EVENT>() { private LogPosition lastPosition; public boolean sink(EVENT event) { try { CanalEntry.Entry entry = parseAndProfilingIfNecessary(event); if (!running) { return false; } if (entry != null) { exception = null; // 有正常数据流过,清空exception transactionBuffer.add(entry); // 记录一下对应的positions this.lastPosition = buildLastPosition(entry); // 记录一下最后一次有数据的时间 lastEntryTime = System.currentTimeMillis(); } return running; } catch (TableIdNotFoundException e) { throw e; } catch (Exception e) { // 记录一下,出错的位点信息 processError(e, this.lastPosition, startPosition.getJournalName(), startPosition.getPosition()); throw new CanalParseException(e); // 继续抛出异常,让上层统一感知 } } }; // 4. 开始dump数据 if (StringUtils.isEmpty(startPosition.getJournalName()) && startPosition.getTimestamp() != null) { erosaConnection.dump(startPosition.getTimestamp(), sinkHandler); } else { erosaConnection.dump(startPosition.getJournalName(), startPosition.getPosition(), sinkHandler); } } catch (TableIdNotFoundException e) { exception = e; // 特殊处理TableIdNotFound异常,出现这样的异常,一种可能就是起始的position是一个事务当中,导致tablemap // Event时间没解析过 needTransactionPosition.compareAndSet(false, true); logger.error(String.format("dump address %s has an error, retrying. caused by ", runningInfo.getAddress().toString()), e); } catch (Throwable e) { exception = e; if (!running) { if (!(e instanceof java.nio.channels.ClosedByInterruptException || e.getCause() instanceof java.nio.channels.ClosedByInterruptException)) { throw new CanalParseException(String.format("dump address %s has an error, retrying. ", runningInfo.getAddress().toString()), e); } } else { logger.error(String.format("dump address %s has an error, retrying. caused by ", runningInfo.getAddress().toString()), e); sendAlarm(destination, ExceptionUtils.getFullStackTrace(e)); } } finally { // 重新置为中断状态 Thread.interrupted(); // 关闭一下链接 afterDump(erosaConnection); try { if (erosaConnection != null) { erosaConnection.disconnect(); } } catch (IOException e1) { if (!running) { throw new CanalParseException(String.format("disconnect address %s has an error, retrying. ", runningInfo.getAddress().toString()), e1); } else { logger.error("disconnect address {} has an error, retrying., caused by ", runningInfo.getAddress().toString(), e1); } } } // 出异常了,退出sink消费,释放一下状态 eventSink.interrupt(); transactionBuffer.reset();// 重置一下缓冲队列,重新记录数据 binlogParser.reset();// 重新置位 if (running) { // sleep一段时间再进行重试 try { Thread.sleep(10000 + RandomUtils.nextInt(10000)); } catch (InterruptedException e) { } } } MDC.remove("destination"); } }); parseThread.setUncaughtExceptionHandler(handler); parseThread.setName(String.format("destination = %s , address = %s , EventParser", destination, runningInfo == null ? null : runningInfo.getAddress().toString())); parseThread.start(); }start()方法是实现了生命周期的启动方法,是被上层的组件调用的,parser组件的start方法应该是被instance组件调用的。该方法开始启动组件,接收binlog,并且解析处理它。该方法的流程是这样的。
- 初始化并启动transactionBuffer组件。
- 构造binlogParser组件,并启动它。
- 开启新的线程并启动它。避免阻塞上级组件的启动。
- 开启循环,直到终止组件运行。判断标志是protected volatile boolean running = false。定义为volatile修饰的成员变量,让多线程可见。
- 构造erosa连接。
- 启动一个心跳线程。用Timer实现。会定期消费一个事件类型为EntryType.HEARTBEAT的事件。应该是告知下游组件,上有组件还活着。
- dump数据库复制日志前的准备处理。
- erosa连接创建连接。
- 查找日志起始位置。
- erosa连接重建连接。因为在找position过程中可能有状态,需要断开后重建
- 开始dump数据库复制日志。传入一个回调的SinkFunction匿名类对象。回调方法sink的实现就是解析dump到的日志事件,将其转化为Entry对象。并强Entry对象加入到缓冲区transactionBuffer中,并且记录当前日志位置和时间。
- 最后dump后的处理。关闭连接等事后处理。
- 若未停止运行,则再次进入第一步。
问题是:没做一次dump之后,就会进入一次循环,会再次创建和连接,这样连接就无法复用,高并发性能岂不是很差,服务器压力也非常大呢?这个问题从源码开起来是有些问题,先记录下来,后面通过查看其它部分源码和调试就能得到答案了。
经过排查dump方法内部的实现,发现该方法内部是会阻塞的,当连接的缓冲区中没有新的内容的情况下,会阻塞请求,等待数据。因此连接是可以被复用的。
- canal源码分析——parse模块源码分析
- canal源码分析——DirectLogFetcher源码分析
- canal源码分析——整体架构分析
- canal源码分析系列——ErosaConnection分析
- canal源码分析——项目组成结构
- canal的重写与parser源码分析
- Canal源码分析---模拟Slave同步binlog
- nginx源码分析——模块、初始化
- Spark源码分析——deploy模块
- nginx源码分析——event模块
- nginx源码分析——event模块
- nginx源码分析—模块及其初始化
- nginx源码分析—core模块callback
- nginx源码分析—core模块callback
- nginx源码分析—模块及其初始化
- nginx源码分析—core模块callback
- nginx源码分析—模块及其初始化 .
- nginx源码分析—模块及其初始化
- centos telnet命令
- Linux下的C语言开发(Makefile编写)
- 进程间通信(IPC)之消息队列
- Maven学习笔记
- 【POI2010】BZOJ2096 pilots
- canal源码分析——parse模块源码分析
- 论文阅读:Personalizing Human Video Pose Estimation
- 什么是IP核
- HDOJ/HDU 1372 Knight Moves(经典BFS)
- Tomcat与Java Web(一)
- asp.net CheckBox 控件
- 格子布局
- Andorid(1)
- 5-18 二分法求多项式单根 (20分)


