三、HDFS 与Yarn HA 架构部署与测试
来源:互联网 发布:耐克鞋淘宝网 编辑:程序博客网 时间:2024/06/06 17:35
三、HDFS 与Yarn HA 架构部署与测试
标签(空格分隔): 高级Hadoop2.x
3.HDFS HA 架构部署与测试
3.1HDFS HA(高可用性)产生背景
1)在hadoop2.x之前,hdfs集群中namenode存在单节点故障(SPOF)。因集群中只有一个namenode,故当namenode机器出现故障时,整个集群都无法使用。
2)namenode影响HDFS主要体现在两方面:
a.namenode机器发生意外,如宕机
b.namenode机器需要升级
3)基于以上缺陷,便产生HDFS HA。通过配置active namenode 与standby namenode,实现集群中的namenode备份,如此当一台机器出现故障,可以马上启动另一台机器的namenode.
3.2HDFS HA(高可用性)原理(四大要点)
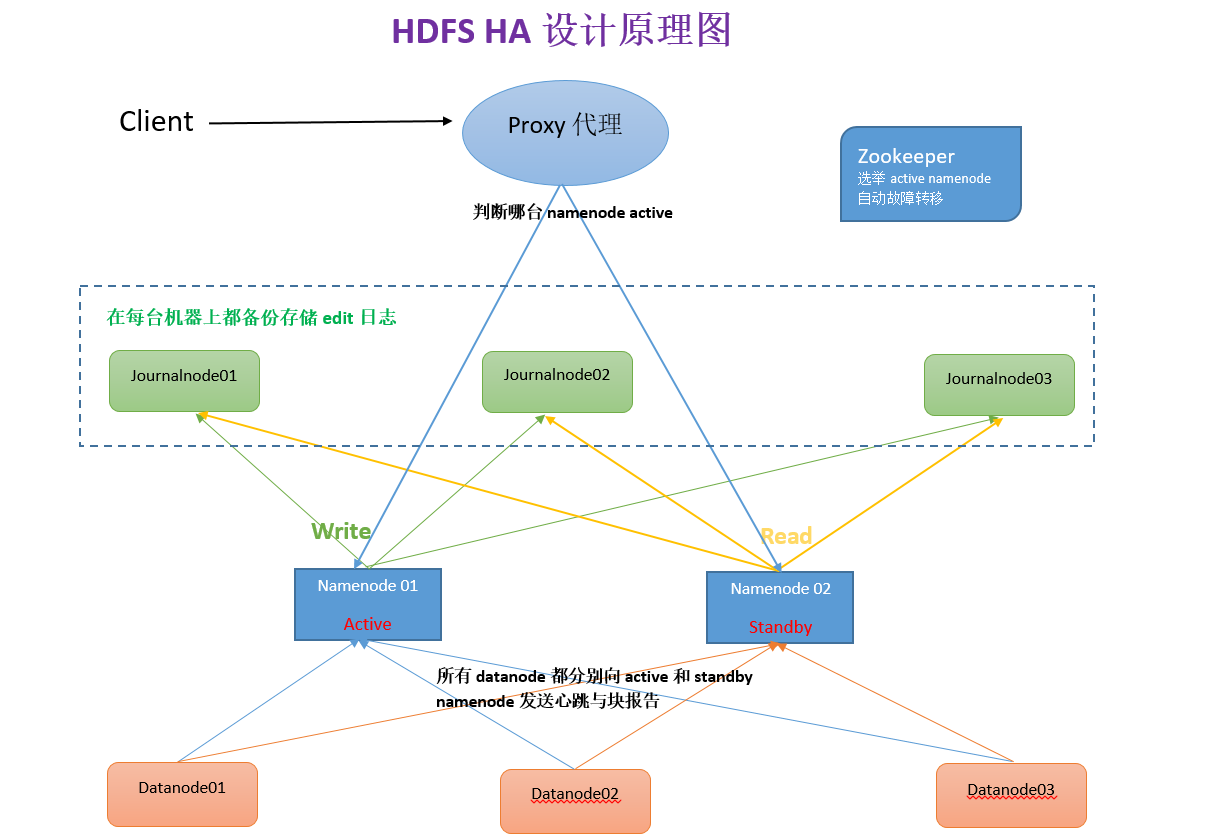
3.2.1如何保证两个namenode内存中存储的文件系统的元数据同步
文件系统元数据变化会产生新的edits记录,standby namenode会去读取new edits,当原来的active namenode 机器损坏,切换到standby namenode 机器时, 就确保了一致性,如此便需要确保edis安全性可靠性!有以下几种方式可以解决这个问题:
方式一:使用外部更好的文件系统进行存储edit, 但单价太高,违背了hadoop廉价的初衷
方式二:分布式存储日志信息–QJM
方式三:使用zookeeper进行存储
以上的方式中,第二种方式被普遍使用,原理如下:
1)首先active namenode 会在 每一台datanode的机器上备份一份edit文件,备份数量为奇数个(2n+1)–journalnode
2)standby namenode 会实时从journalnode中读取edit日志文件,做到与active namenode的同步更新。
3.2.2如何保证两个namenode同步datanode报告的信息
分布式日志存储只解决了元数据的安全性,而datanode报告的信息并没有达到同步更新。
而在HDFS HA 中设置了所有datanode都要分别向active namenode 和 standby namenode 发送心跳与块的报告,这样保证了standby 也同步接受了datanode的情况。
3.2.3如何保证client客户端访问的是active namenode
在HDFS HA中会设置一个proxy(代理), client会先去找proxy, 由proxy去判断哪台机器的namenode is active, 随后client再去找正确的namenode。
3.2.4如何保证任意时刻仅有一个namenode 对外提供服务
此时需要zookeeper ,它的功能主要有两个:
1)当两个namenode都启动时,zookeeper会选举其中一个为active, 去对外提供服务
2)当active namenode损坏时,zookeeper会监听到,并将standby namenode 变成active namenode.
注:有了两个namenode,就不需要secondary namenode了
3.3配置HDFS HA,启动并测试
3.3.1准备环境(每台机器都如下准备好):
1)将/opt/app/hadoop-2.5.0/etc/目录下的hadoop 在相同路径下复制一份,之后的配置都在hadoop中进行 (其他机器上只需把hadoop重命名为hadoop-dist, 因为一台机器配置好后会分发hadoop给其他机器)
$cp -r hadoop/ dist-hadoop/
2)将/opt/app/hadoop-2.5.0/data/目录下的tmp重命名为dist-tmp
$mv tmp/ dist-tmp同时,在相同路径下,在创建一个tmp,用于新的集群 $mkdir tmp 
3)创建一个目录存储编辑日志journalnode
到/data/目录下
$mkdir -p dfs/jn3.3.2配置(先在一台机器上配置):
1)打开hdfs-site.xml,如下配置
<configuration> //将nameservice命名为"ns1" <property> <name>dfs.nameservices</name> <value>ns1</value> </property> //命名两个namenode的id名称 <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> //nn1 namenode 节点配置在01机器 <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>hadoop-senior01.ibeifeng.com:8020</value> </property> //nn2 namenode 节点配置在02机器 <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>hadoop-senior02.ibeifeng.com:8020</value> </property> //配置第一台机器的端口号 <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>hadoop-senior01.ibeifeng.com:50070</value> </property> //配置第二台机器的端口号 <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>hadoop-senior02.ibeifeng.com:50070</value> </property> //配置共享日志的目录在三台机器上 <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop-senior01.ibeifeng.com:8485;hadoop-senior02.ibeifeng.com:8485;hadoop-senior03.ibeifeng.com:8485/ns1</value> </property> //配置journalnode的目录,(先要在命令行创建/data/dfs/jn/这个目录) <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/app/hadoop-2.5.0/data/dfs/jn</value> </property> //配置客户端 <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> //配置隔离机制(ssh隔离),确保仅有一个namenode对外提供服务 (确保已经配置了ssh无密钥登入) <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/beifeng/.ssh/id_rsa</value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property></configuration>2)打开core-site.xml,如下配置
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://ns1</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/app/hadoop-2.5.0/data/tmp</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>beifeng</value> </property></configuration>3)将一台机器上配置好的hadoop分发到其他机器上
到etc目录下
$scp -r hadoop/ hadoop-senior02.ibeifeng.com:/opt/app/hadoop-2.5.0/etc/3.3.3启动QJM HA
1)在各个journalnode节点上输入一下命令去启动journalnode
$sbin/hadoop-daemon.sh start journalnode
2)在nn1上,先格式化namnode,再启动
$bin/hdfs namenode -format$sbin/hadoop-daemon.sh start namenode3)在nn2上,同步nn1的元数据信息
$bin/hdfs namenode -bootstrapStandby4)启动nn2上的namenode
$sbin/hadoop-daemon.sh start namenode5)将nn1切换为active
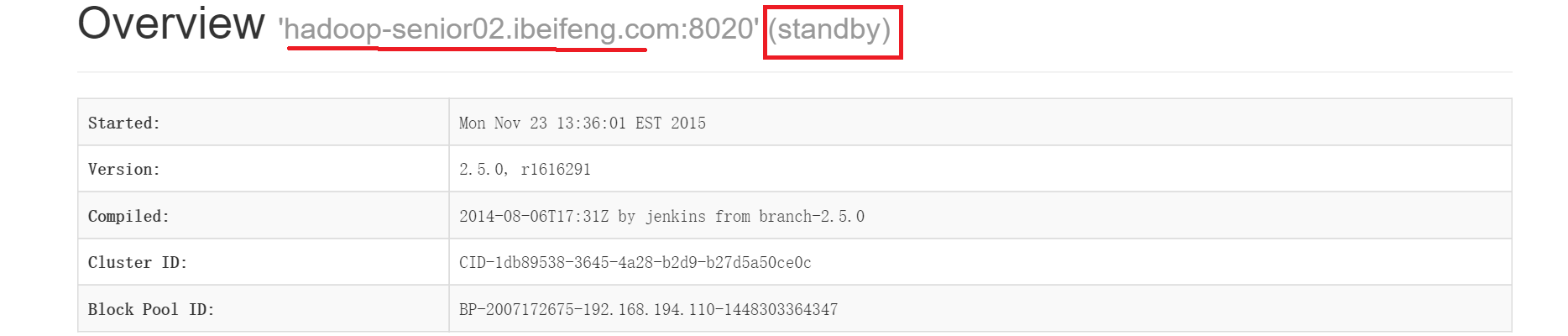
$bin/hdfs haadmin -transitionToActive nn1此时分别去两台机器的50070端口查看web,如下图所示,第一台namenode已经变成active了,否则两台都为standby 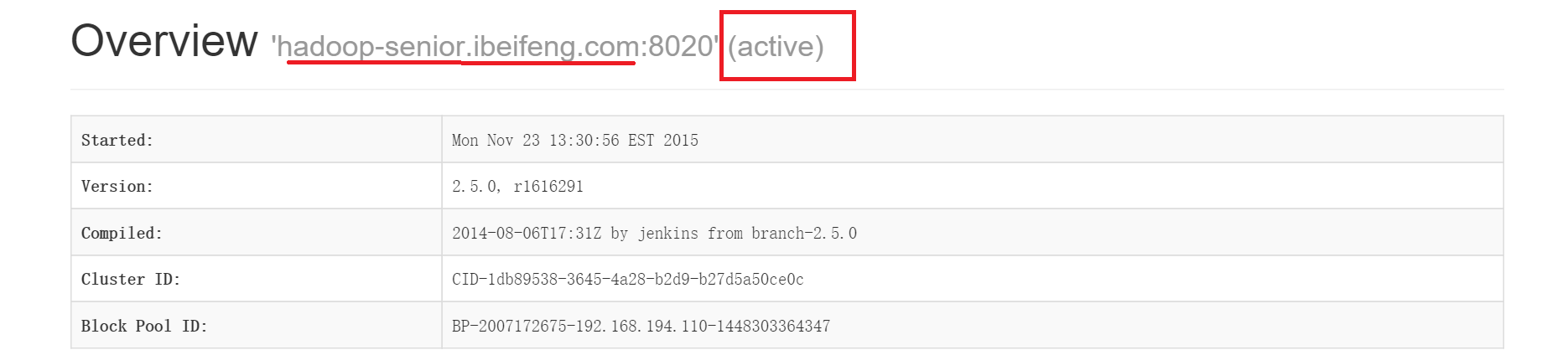
6)在nn1上,分别启动所有datanode
$sbin/hadoop-daemon.sh start datanode此时两台机器的web端都可以看到启动了两个namenode 
3.3.4 测试
1)建目录
$bin/hdfs dfs -mkdir -p tmp/conf2)上传数据
$bin/hdfs dfs -put etc/hadoop/hdfs-site.xml tmp/conf查看是否上传
$bin/hdfs dfs -ls tmp/conf3)读取数据
$bin/hdfs dfs -text tmp/conf/hdfs-site.xml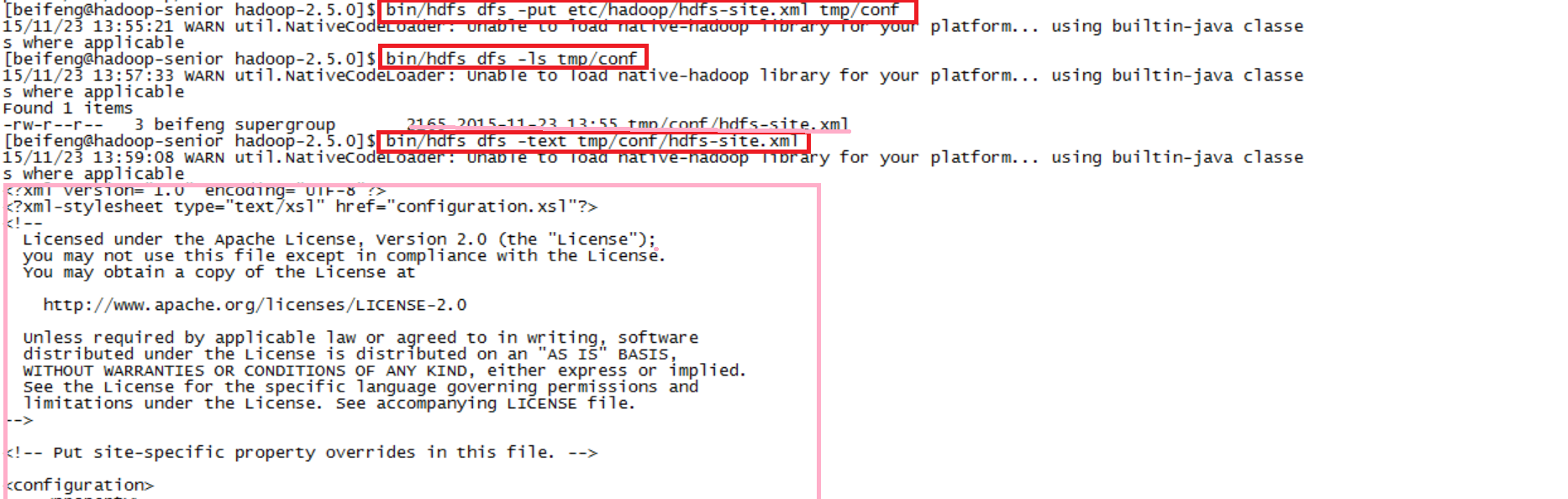
4)干掉active namenode,将standby namenode手动切换成active (自动切换需要zookeeper)
干掉nn1 
active nn2, 并读取文件,成功 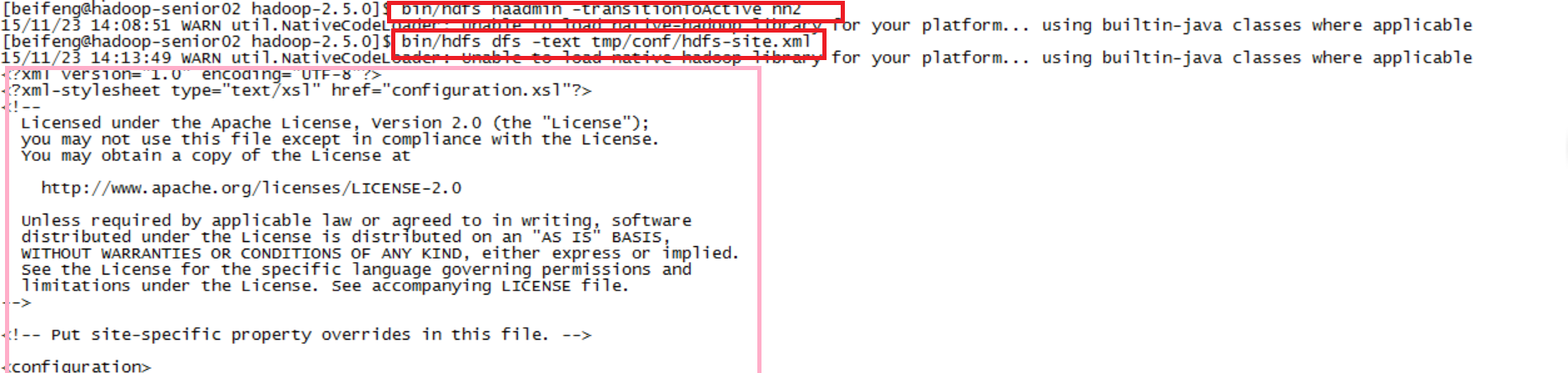
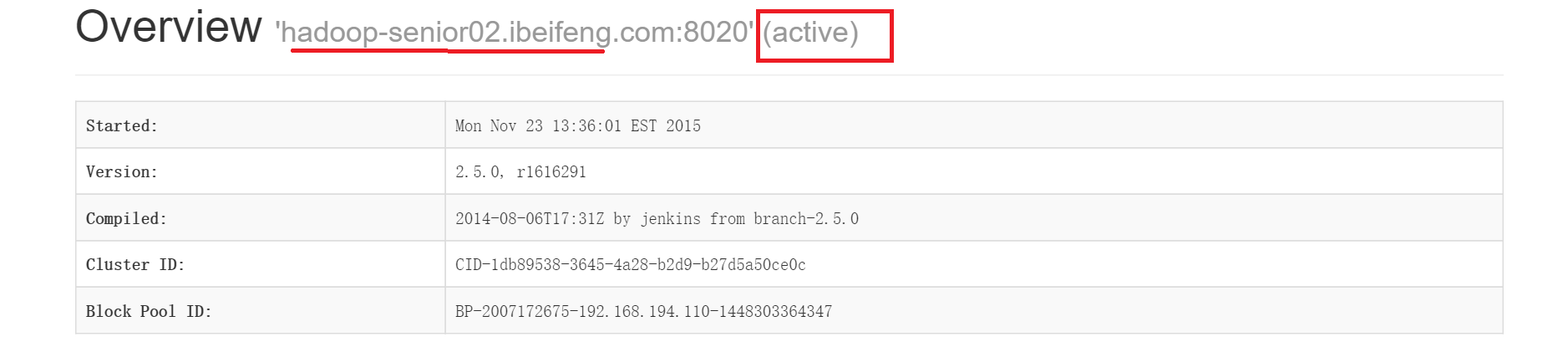
此时web端也已经显示了nn1 变成standby, 而nn2变成了active 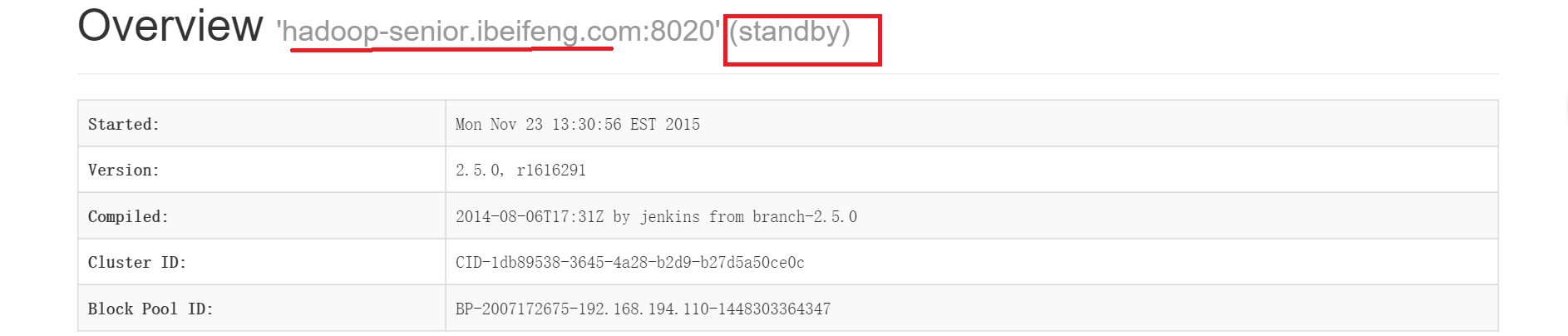
3.4配置HDFS HA(高可用性)自动故障转移与测试
FC:failcontroller
ZKFC监控namenode的情况,是zookeeper的客户端,用户选举哪个namenode为active, 或者监控namenode 是否损坏,若损坏则切换另一个namenode为active
配置自动故障转移前:将集群shut down
$sbin/stop-dfs.sh3.4.1配置文件
1)打开hdfs-site.xml,添加如下一个配置, 
2)打开core-site.xml,添加如下一个配置,表示在哪台机器上开启zookeeper(因为我集群里只有2台机器,而zookeeper个数为奇数,故,只在一台上配置) 
3.4.2 将配置好的两个文件分发给其他机器(若只有一个zookeeper是否不用做该步),并启动
1)分发
到etc目录下
$scp -r hadoop/core-site.xml hadoop/hdfs-site.xml hadoop-senior02.ibeifeng.com:/opt/app/hadoop-2.5.0/etc/hadoop/2)启动zookeeper
$bin/zkServer.sh start3)初始化HA 在zookeeper中状态
$bin/hdfs zkfc -formatZK4)在另一台机器上可以看到多了一个节点
到02机器中的目录/zookeeper-3.4.5/中进入客户端
$bin/zkCli.sh$ls /可以看到多了一个节点
5)启动HDFS服务
$sbin/start-dfs.sh6)在各个namenode节点上启动dfszk failover controller,先在哪台机器上启动,哪台就是active namenode
$sbin/hadoop-daemon.sh start zkfc
3.4.3 验证与测试
1)将active namenode进程kill
$kill -9 pid2)将active namenode机器断开网络
$service network stop4.YARN HA架构部署
4.1 yarn HA原理
zookeeper在resoucemanager HA中的功能:
1)存储resoucremanager 的状态信息,集群资源相关信息,任务相关信息
2)选举,与自动故障转移
在RM HA中,有一个active,并可以有多个standby
可以手动转移,也可以故障转移
zkfc为线程,无需单独启动
4.2YARN Resourcemanager HA 配置部署与测试
4.2.1环境准备(每台机器都需要)
将/opt/app/hadoop-2.5.0/etc/目录下原有hadoop重命名为nn-ha-zkfc-hadoop
$mv hadoop/ nn-ha-hadoop/将原有的dist-hadoop拷贝一份并重命名为hadoop(只需一台)
$cp -r dist-hadoop/ hadoop将/app/hadoop-2.5.0/data/目录下原有的tmp重命名为nn-ha-tmp
$mv tmp/ nn-ha-tmp然后再重新创建一个tmp
mkdir tmp将dfs重命名为nn-ha-dfs
$mv dfs nn-ha-dfs4.2.2配置
打开yarn-site.xml,配置如下:
<configuration> //开启resourcemanager HA <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> //设置集群的id <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-cluster</value> </property> //设置resoucemanager的名称id <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm110,rm111</value> </property> //设置rm110在第一台机器上 <property> <name>yarn.resourcemanager.hostname.rm110</name> <value>hadoop-senior.ibeifeng.com</value> </property> //设置rm111在第二台机器上 <property> <name>yarn.resourcemanager.hostname.rm111</name> <value>hadoop-senior02.ibeifeng.com</value> </property> //设置zookeeper在第一台机器上 <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop-senior.ibeifeng.com:2181</value> </property> //设置resoucemanager restart开启 <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> // <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property> </configuration>4.2.3 分发配置文件到其他机器上,启动
1)分发
$scp -r etc/hadoop/ hadoop-senior02.ibeifeng.com:/opt/app/hadoop-2.5.0/etc/2)启动zookeeper
3)根据之前的集群部署,启动hdfs 与 yarn, 其中resoucemanager 在两台机器上都启动 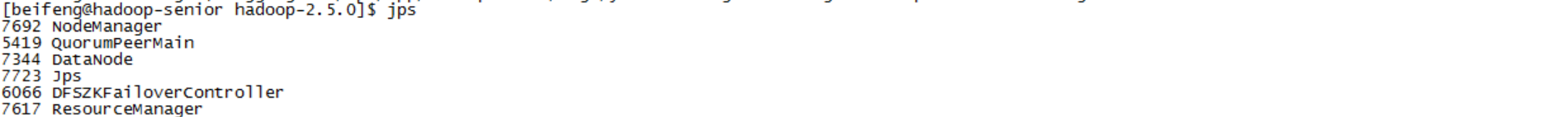

此时去8088端口,01机器如下所示,已启动,并有两个nodemanager 节点 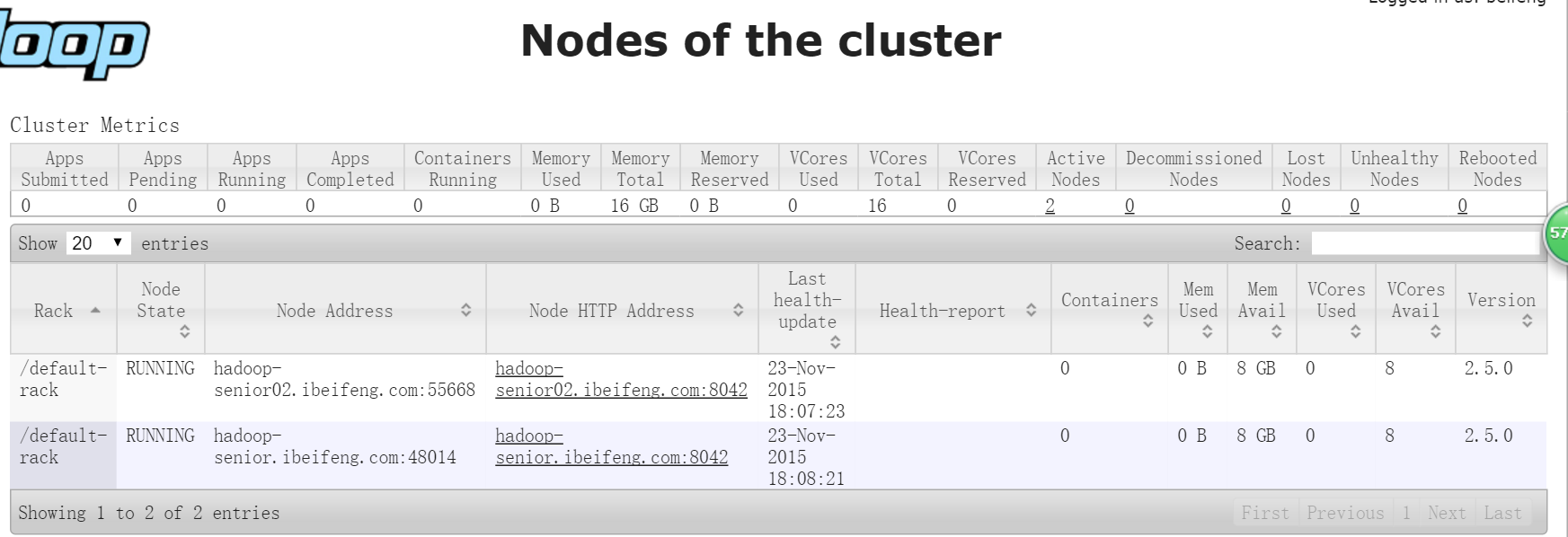
02机器出现以下提示,并会跳转到01 
4.2.4 跑mapreduce测试
1)创建目录
$bin/hdfs dfs -mkdir -p mapreduce/wordcount/input2)上传文件
$bin/hdfs dfs -put /opt/datas/wc.input mapreduce/wordcount/input3)在02机上运行mapreduce程序
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-example-2.5.0.jar wordcount mapreduce/wordcount/input/wc.input mapreduce/wordcount/output4)当开始跑mapreduce时,去01机kill它的resoucemanager
$kill -9 7449在kill 01的resourcemanager之后,运行的程序里会出现如下句子,表示自动故障转移,激活了02上的resourcemanager rm111 
5)再去读取输出,也能成功!!!!!
$sbin/hdfs dfs -text mapreduce/wordcount/output/par*

- 三、HDFS 与Yarn HA 架构部署与测试
- 集群安装:HA与Yarn(测试)
- (二)hue与HDFS、YARN集成配置与测试
- Apache Hadoop 2.2.0 HDFS HA + YARN多机部署
- Apache Hadoop 2.2.0 HDFS HA + YARN多机部署
- Apache Hadoop 2.2.0 HDFS HA + YARN多机部署
- Apache Hadoop 2.2.0 HDFS HA + YARN多机部署
- HDFS 和YARN HA 简介
- hadoop2.6.5 ha配置与yarn ha配置
- yarn安装与测试
- HDFS HA 部署安装
- YARN源码分析(三)-----ResourceManager HA之应用状态存储与恢复
- YARN源码分析(三)-----ResourceManager HA之应用状态存储与恢复
- 利用QJM实现HDFS的HA策略部署与验证工作记录分享
- 利用QJM实现HDFS的HA策略部署与验证工作记录分享
- hdfs HA架构小结
- HDFS HA 架构分析
- HDFS HA与QJM[官网整理]
- Angular+servlet java实现前后端数据交互
- 细说JavaScript中对象的属性和方法
- MySQL存储过程
- C++类模板深入理解2
- 另一种实现非阻塞网络通信的方法———使用libev
- 三、HDFS 与Yarn HA 架构部署与测试
- Duilib中各个类的简单介绍
- GPRS MG301数据传输设置
- <Android>彻底去掉导航栏方法
- Implementing Apriori Algorithm in R
- MySQL对CREATE TABLE IF NOT EXISTS SELECT的处理
- poj2418 Hardwood Species
- 几种常见的排序算法实现
- json格式转化 序列化 反序列化


