Hadoop:MapReduce序列化
来源:互联网 发布:淘宝的自动发货机器人 编辑:程序博客网 时间:2024/05/11 16:33
hadoop高级教程:MapReduce序列化,序列化是指将结构化对象转为字节流以便于通过网络进行传输或写入持久存储的过程。反序列化指的是将字节流转为结构化对象的过程。在Hadoop MapReduce中,序列化的主要作用有两个:永久存储和进程间通信。
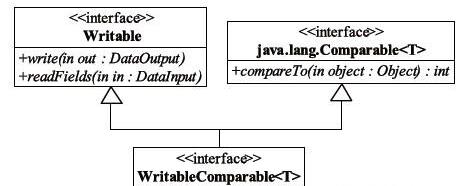
为了能够读取或者存储Java对象,MapReduce编程模型要求用户输入和输出数据中的key和value必须是可序列化的。在Hadoop MapReduce中,使一个Java对象可序列化的方法是让其对应的类实现Writable接口。但对于key而言,由于它是数据排序的关键字,因此还需要提供比较两个key对象的方法。为此,key对应类需实现WritableComparable接口,它的类如图3-3所示。来源:Oracle认证
0 0
- Hadoop:MapReduce序列化
- hadoop MapReduce序列化
- Hadoop基础之MapReduce原理、序列化和源码分析
- mapreduce序列化机制
- Hadoop详解(三)——MapReduce原理和执行过程,远程Debug,Writable序列化接口,MapReduce程序编写
- Hadoop系列-MapReduce自定义数据类型(序列化、反序列化机制)(十二)
- MapReduce API基本概念 序列化,Reporter参数,回调机制 ---《hadoop技术内幕》读书笔记
- Hadoop/MapReduce移动平均:时间序列数据平均值
- MapReduce&hadoop
- Hadoop MapReduce
- Hadoop MapReduce
- Hadoop MapReduce
- Hadoop Mapreduce
- Hadoop MapReduce
- hadoop mapreduce
- hadoop mapreduce
- hadoop mapreduce
- Hadoop mapreduce
- matlab 绘图入门与实例
- AngularJs强制操作DOM
- ReactNative 环境搭建
- App和启动图片的几种设置方法
- Android Studio调试技巧
- Hadoop:MapReduce序列化
- HDU5726 GCD【RMQ+二分】
- 20160720工作日志
- 深夜随笔
- 干货满满,绝不错过,DOM、BOM 操作超级集合
- Linux消息队列
- 图的邻接表存储 c实现
- 关于CSS需要知道的10件事
- Linux环境下修改python matplotlib显示中文乱码方格


