NS2的整体实现
来源:互联网 发布:北京人少的景点知乎 编辑:程序博客网 时间:2024/05/01 00:41
原作者:naonaoruby
来源网址:http://naonaoruby.bokee.com/viewdiary.11857286.html
1. NS 的整体实现
固定网络的仿真是通过下面三层合作来实现的。
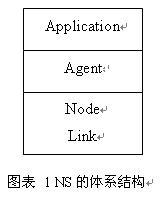
Application 这个层是实现数据流的层次。 Agent 这个层是实现所有各层协议的的层次。 Node 这个部分由多个分类器( Classifier)实现了所有接收数据包进行判断是否进行转发或接收到 Agent 的部分。 Link 实现了队列、时延、 Agent 、记录 Trace 等一系列的仿真问题。
2.
TclObject
Handler
ParentNode
Process
NsObject
Node
Application
Connector
Classifier
Delay
Queue
Agent
Trace
AddressClassifier
图表 2 NS 内部类的继承关系图
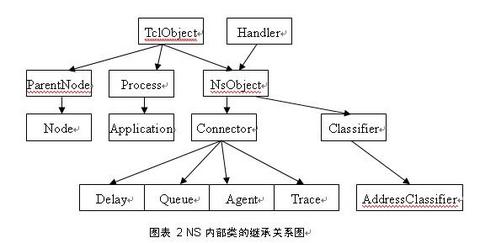
此图为 NS 内部类的继承关系,可以看出一些类是由那些类继承来的,这样相同的属性调用的函数就可以很方便的找到出处。
3. NS 中函数调用的分层
在用 gdb 跟踪 NS 发送一个 cbr 数据包的过程可以看到一下顺序:
CBR_Traffic::start
TrafficGenerator::timeout
Application::send
UdpAgent::sendmsg
Classifier::recv
Connect::recv
Connect::send
Trace::recv 写一条数据包加入队列的记录
Connector::send
Queue::recv
DropTail::enque
DequeTrace::recv 写一条数据包弹出队列的记录
Connector::send
LinkDelay::recv 插入事件到 scheduler
Scheduler::dispatch
Scheduler::run
从上面的顺序可以看出,数据包在发送以后先通过应用层( Application::send )进行发送;然后通过 Agent 层(UdpAgent::sendmsg ), UdpAgent 是在初始化 Agent 的时候确定的。 UdpAgent 还有一个作用是生成相应的数据包;然后进入 Node 部分的分类器 Classifier ( Classifier::recv ),通过 find ()函数返回下一跳地址。这个函数是通过读取 Packet 的内容得到下一跳地址的,返回给 recv 函数后调用 node->recv() 进入 connector ;经过 connector::recv 和 connector::send 后确定数据包可发,进入 Trace::recv ,记录这个数据包加入队列的记录;之后通过 connector::send ,进入 Queue::recv 函数,将数据包正式加入发送队列,再根据已经设定好的方法确定加入队列是否成功,是否要被丢弃;再调用 DequeTrace::recv 记录数据包弹出队列的记录;再通过 connector::send 进入LinkDelay::recv ,先判断目的节点是否可达,根据不同的结果将事件写入 scheduler ,等待按序执行。
上述的过程只是一个数据包从生成到发送出去的过程,因为 NS 是一个根据一个一个离散事件调度执行的,后面的过程用 gdb 跟不进去。但可以看出,数据包是发送给下一跳节点,可知数据包是通过每个中间节点的。
4. NS 中主要函数的分析
4.1. CBR 数据源
开始从下面函数进入 CBR 数据源发送:
void CBR_Traffic::start()
{
init(); // 初始化
running_ = 1;
timeout(); // 进入发送数据的循环
}
void TrafficGenerator::timeout()
{
if (! running_) // 判断是否要发送数据
return;
/* send a packet */
send(size_); // 发送一个设定好大小的数据包
/* figure out when to send the next one */
nextPkttime_ = next_interval(size_);
/* schedule it */
if (nextPkttime_ > 0)
timer_.resched(nextPkttime_);
else
running_ = 0;
}
4.2. 中间几个函数只是体现分层
void Application::send(int nbytes)
{
agent_->sendmsg(nbytes);
}
void Agent::sendmsg(int /*sz*/, AppData* /*data*/, const char* /*flags*/)
{
fprintf(stderr,
"Agent::sendmsg(int, AppData*, const char*) not implemented/n");
abort();
}
上述两个函数其实并没有什么实质的操作,只是这样可以看出其经过了应用层和 Agent 层。
4.3. Classifier 的函数
void Classifier::recv(Packet* p, Handler*h)
{
NsObject* node = find(p); // 查找目的节点
if (node == NULL) { // 只要返回了目的节点就调用节点的 recv 函数
/*
* 这个将被丢弃,不用记录在 trace 文件中
*/
Packet::free(p);
return;
}
node->recv(p,h);
}
NsObject* Classifier::find(Packet* p)
{
NsObject* node = NULL;
int cl = classify(p); // 根据发送的 packet 的记录找到 slot
if (cl < 0 || cl >= nslot_ || (node = slot_[cl]) == 0) { // 根据 slot 得到下一跳 node
if (default_target_)
return default_target_;
/*
* 不能将数据包发送出去,因为返回结果不是一个对象 .
*/
Tcl::instance().evalf("%s no-slot %ld", name(), cl);
if (cl == TWICE) {
/*
* Try again. Maybe callback patched up the table.
*/
cl = classify(p);
if (cl < 0 || cl >= nslot_ || (node = slot_[cl]) == 0)
return (NULL);
}
}
return (node); // 返回给 classifier::recv 得到的 node 的值
}
这个地址分类器就是根据数据包的内容,通过偏移查找接收的节点,然后调用接收节点的 recv 函数。而 find 函数是根据数据包的内容得到 slot 的值从而查询出谁是接收方的 node 。
4.4. Connector 的函数
void Connector::recv(Packet* p, Handler* h)
{
send(p, h);
}
inline void send(Packet* p, Handler* h) { target_->recv(p, h); }
connector 的 recv 和 send 函数是一个接口。这个函数中最重要的是 target_ 这个值,这个值的不同会不同的调用 Trace::recv 、Queue::recv 、 LinkDelay::recv 等等,但是这个值在那确定还没有看出来。
4.5. Queue 的函数
void Queue::recv(Packet* p, Handler*)
{
double now = Scheduler::instance().clock();
enque(p); // 根据规定的规则加入队列
if (!blocked_) {
/*
* 这里没有堵塞 . 将一个数据包发送出去 .
* 我们执行一个附加的检查,因为这个队列可能丢弃这个数据包
* 即使它前面是空的。 ( 例如 , RED 队列就可能发生 .)
*/
p = deque();
if (p != 0) {
utilUpdate(last_change_, now, blocked_);
last_change_ = now;
blocked_ = 1;
target_->recv(p, &qh_); // 调用 dequetrace
}
}
}
Queue::recv 这个函数调用 DropTail 规则将数据包加入队列,然后判断是否堵塞,如果没有则发送一个数据包,之前判断是认定这个包是否要被发送出去。这里也使用了 target_->recv() ,这里调用的是 DequeTrace::recv 函数,将记录一个数据包出队列的记录。
4.6. LinkDelay 的函数
void LinkDelay::recv(Packet* p, Handler* h)
{
double txt = txtime(p);
Scheduler& s = Scheduler::instance();
if (dynamic_) { // 这个是动态链路的标志,判断这个值确定链路是否为 动态链
Event* e = (Event*)p;
e->time_= txt + delay_;
itq_->enque(p); // 用一个队列来储存数据包
s.schedule(this, p, txt + delay_);
} else if (avoidReordering_) {
// 预防重新安排带宽或时延改变
double now_ = Scheduler::instance().clock();
if (txt + delay_ < latest_time_ - now_ && latest_time_ > 0) {
latest_time_+=txt;
s.schedule(target_, p, latest_time_ - now_ );// 在 schedule 里面加入事件
} else {
latest_time_ = now_ + txt + delay_;
s.schedule(target_, p, txt + delay_); // 在 schedule 里面加入事件
}
} else {
s.schedule(target_, p, txt + delay_); // 在 schedule 里面加入事件
}
s.schedule(h, &intr_, txt); // 在 schedule 里面加入事件
}
这个函数非常重要,这个是数据包最后离开这个节点的出口,由这个函数写一个事件加入 schedule ,在一定的时间后调用。
- NS2的整体实现
- NS2整体实现机制(转)
- NS2中跨层设计的实现
- ns2多协议节点的实现-nist
- ns2中广播代理的实现
- NS2中的TDMA的实现和分析
- NS2.29中Tdma的实现分析
- sparkSQL的整体实现框架
- 网页整体放大/缩小的实现
- 实现Web应用的整体安全
- 实现self.view的整体上移
- 购物车的整体实现逻辑
- 如何在ns2中实现一个简单的网络协议
- 如何在ns2中实现一个简单的网络协议
- ns2/nam与nam实现相关的文件
- ns2中app对agent的控制实现
- 如何在ns2中实现一个简单的网络协议
- 如何在ns2中实现一个简单的网络协议
- js 日期格式化
- poython正则表达式
- 设计模式(九) 组合模式
- swift流程控制
- ubuntu 各个目录的作用
- NS2的整体实现
- 用户体验要素
- Android data目录读写文件
- String和验证
- 51nod 1298 圆与三角形
- 关于 Des加密(Android与ios 与后台java服务器之间的加密解密)
- bzoj 2734(状压DP+神题)
- 导入GooGle ApiDemos
- AJAX的简介和使用


