Tez上线部署记录
来源:互联网 发布:淘宝如何设置客户权限 编辑:程序博客网 时间:2024/05/20 09:10
前言:
Tez在Hive 0.13.0版本引入,全称Hive on Tez。顾名思义就是基于Tez之上的运行Hive作业的形式。具体Tez是什么?Tez是一种运算框架,MapReduce是一种运算框架,这么说应该懂了。
更具体的讲,Tez是一种内存运算框架,类似Spark的核心——RDD。
正如刚才提到的Tez类似RDD的特性,适用于DAG运算,多路并行聚合运算,迭代运算。得益于Tez采用Map,Reduce分离的执行策略,传统意义的MapReduce作业,Map和Reduce不可分离,必须成对出现,缺一不可。这在不需要Map环节的作业中会耗费不少的内存和IO开销——这里的IO指磁盘和内存之间。同时这也拖曳了Map和Reduce之间的并行度。
然而Tez就完全不一样了,Tez通过把MapReduceWork分解成MapWork和ReduceWork,这个过程中抛弃了不必要的MapWork。
就像这样:
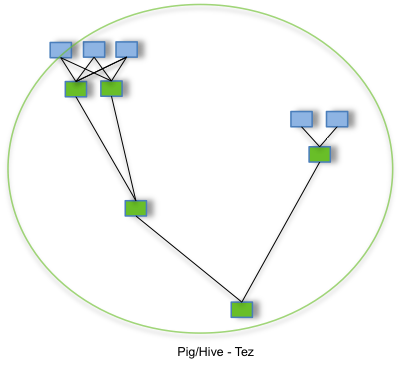
可以看到,过程中没有Map了,这样的形式,我们称为MRR。
更为重要的一点,基于内存模式,任何中间数据不再flush到磁盘,全程在内存当中,IO和CPU之间不再有瓶颈。
适用场景:
简单点说就是,任何复杂语句,任何长语句。具体一点就是下面场景:
- MRR 多阶段的Reduce操作。
- MPJ 多路Join操作。
使用方法:
在你的执行语句中加上以下参数即可:
踩坑记录:
在运行时,报错:
container初始化失败,查看contain目录下的stderr文件,有以下信息:
看似回收器冲突,拉取container的launch_container.sh文件来看:

在脚本的执行命令中看到了两个垃圾回收器设置,第二个是我们提交作业设置的,第一次是Tez默认的设置。
在代码tez-branch-0.5.2/tez-api/src/main/java/org/apache/tez/dag/api/TezConfiguration.java中:
解决方法就是上面提到的,提交前设置参数。
另一个很诡异的问题:
AMcontainer直接launch不了,没有任何日志。查看了nodemanager,resourcemanager,hive.log全都是上面这个错。
查看yarn-common包的源码:
Tez作业在分发Map,Reduce作业时,会在container launch之前,从hdfs上下载jar包等资源文件。就是我们常说的localize resource阶段。在下载之前,会校验resource文件是否被修改。
校验的方式是比较文件的时间戳是否一样。而且很奇怪的是文件一样,时间戳会不一样。(此处原由还没有搞清楚)
所以我简单做了下处理,判断如果是tez任务,如果时间戳不同,不抛出异常。程序执行正常。
遗留问题,还待研究:
1.Tez作业resource分发原理。
2.Tez session以及在Hive Cli模式下会话超时。
- Tez上线部署记录
- Tez学习笔记-UI安装部署
- Hive on Tez部署及验证测试
- linux 部署上线
- Tez在hadoop 2.2.0下的安装部署测试
- Django应用部署 - 上线指南
- Linux服务器部署上线步骤
- web项目部署服务器上线
- web项目部署与上线
- 项目上线与LOG记录
- 记录一下游戏的上线
- Apache Tez
- Tez安装
- Hello Tez
- Tez安装
- apache tez
- 上线部署遇到的各种问题
- 创业项目上线内测部署问题杂记
- 通过Unicode传递中文,防止接收端出现乱码
- skynet的运用-mmo类型
- html - style 元素
- sap pp 详细讲解 生产结算 工单结算
- openSNS 使用关闭游客访问插件后注册头像无法上传问题解决。
- Tez上线部署记录
- 数据结构——线索化二叉树
- JAVA总结
- nlogn最长单调递增
- ASP.NET Core 开发-Logging 使用NLog 写日志文件
- Java日历横向输出
- 我的奋斗
- android自定义控件之中间是斜线的占比条
- FXBlurView模糊图片处理


