Hive:环境搭建及例子
来源:互联网 发布:c语言智能五子棋游戏 编辑:程序博客网 时间:2024/06/01 22:27
Hive是由Facebook最初开发的基于Hadoop的数据仓库工具,提供了类SQL的查询语言Hive SQL(HQL)。
在内部,Hive将用户的SQL语句转化为一系列的MapReduce作业,并提交到集群中运行。
在Hive中,数据通过表来组织,提供了一种将表结构附加(attaching)到HDFS中的数据的一种方式。诸如表的Schema等元数据存放在一个称为metastore的数据库中。默认情况下,metastor存放在本地,但是可以配置在远程共享,这通常在生成环境中使用。
Hive整体架构如下;
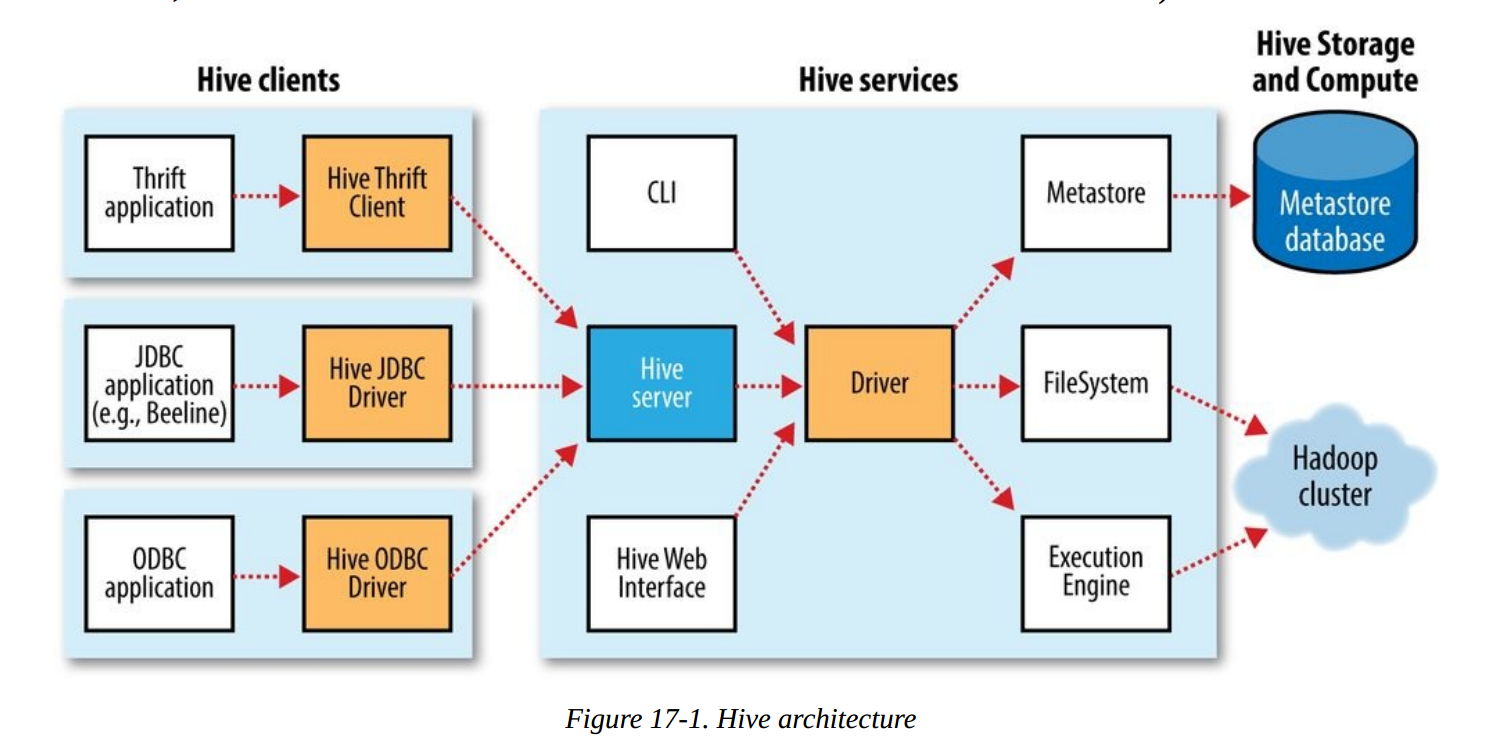
下载安装
下载稳定版本,留意与Hadoop版本的兼容:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.0.0/apache-hive-2.0.0-bin.tar.gztar -zxvf apache-hive-2.0.0-bin.tar.gz mv apache-hive-2.0.0-bin /home/hive-2.0.0vim /etc/profileexport HIVE_HOME=/home/hive-2.0.0export PATH=$PATH:$HIVE_HOME/binsource /etc/profile确保集群中配置了HADOOP_CONF_DIR环境变量,以便Hive可以找到集群配置。
配置metastore
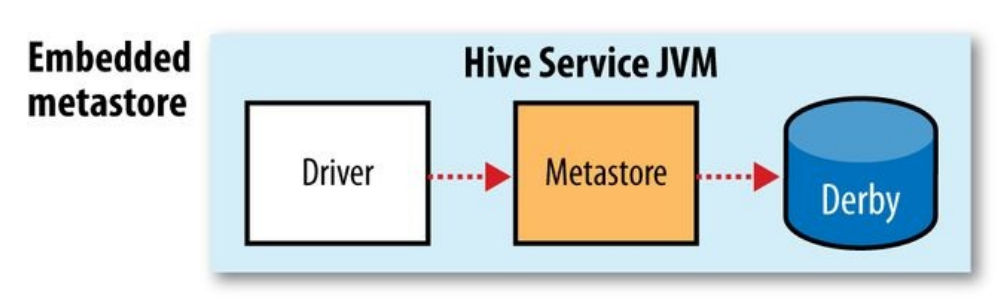
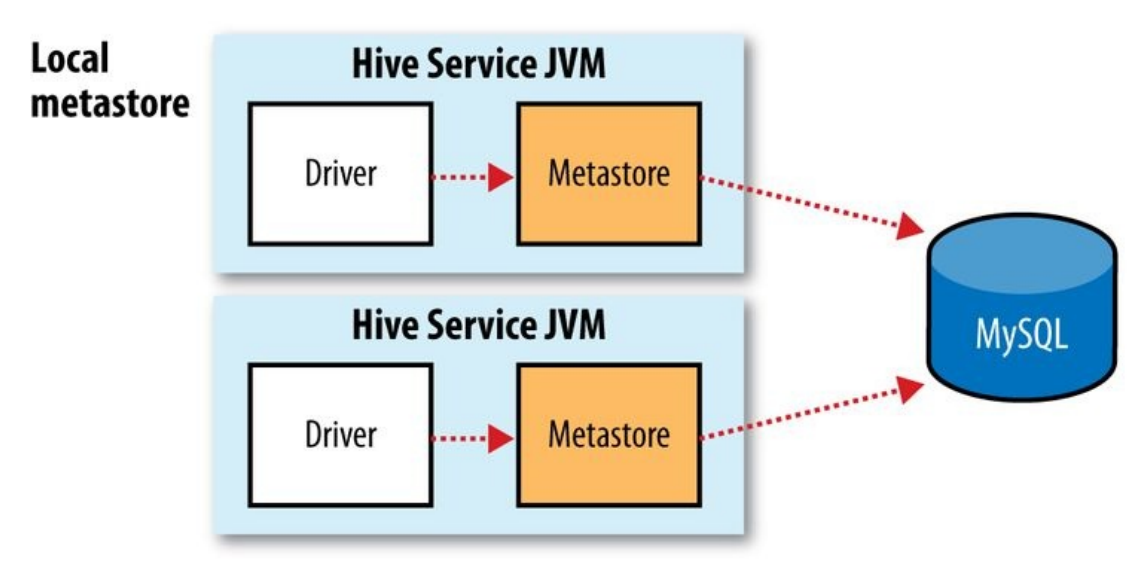
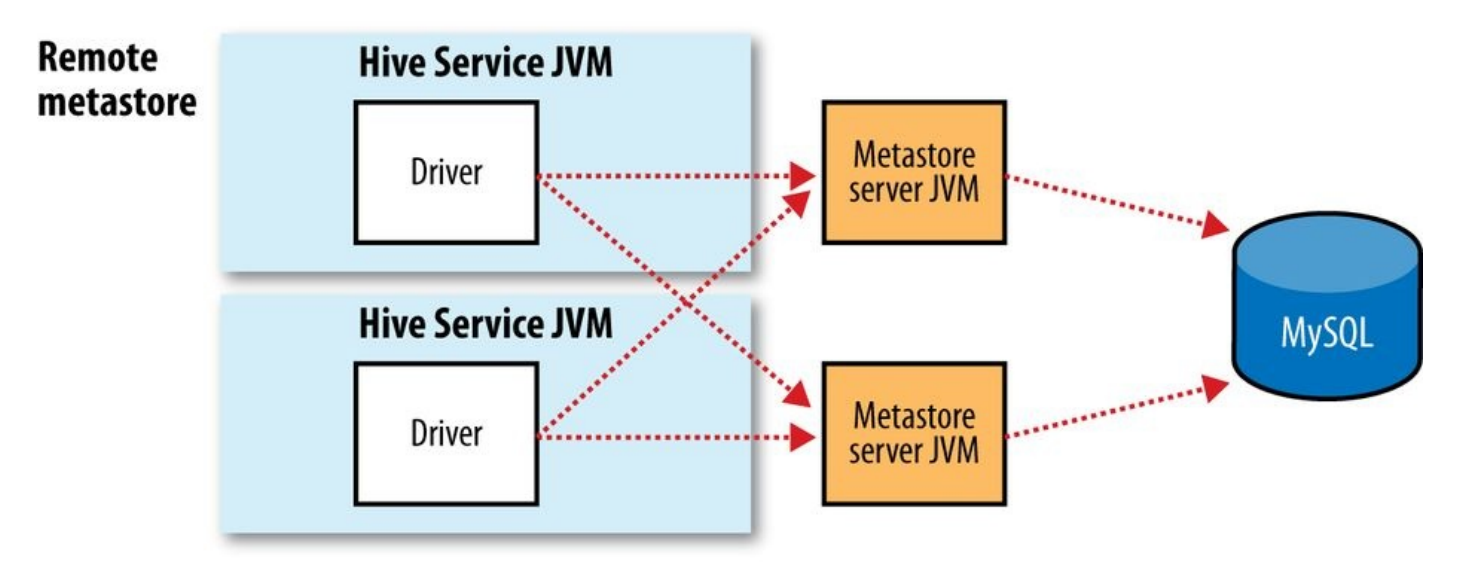
metastore的3种模式:
- Embedded metastore:
- Local metastore:
- Remote metastore
Local模式配置
创建数据库用作metastore:
create database hive;hive-site.xml
<configuration> <property> <name>hive.metastore.local</name> <value>true</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.1.132:3306/hive?characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>yourpasssword</value> </property></configuration>把MySQL JDBC驱动上传到hive的lib目录下。
初始化:
schematool -initSchema -dbType mysql
启动Hive:
% hive

简单实例
创建表
create table records(year string , temperature int ,quality int) row format delimited fields terminated by '\t'成功之后,我们可以在mysql的元数据中看到这个表的信息,在hive.TBLS表中:
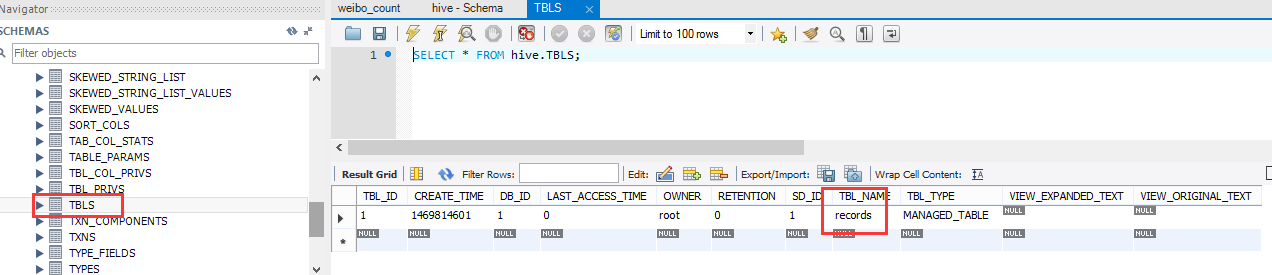
导入数据
将HDFS的文件导入Hive:
load data inpath "/input/ncdc/micro-tab/sample.txt"overwrite into table records;
在/user/hive/warehouse目录下可以看到下面的文件:

查询数据
Hive跟语法跟MySQL非常像,如下查询表中所有数据:
select * from records;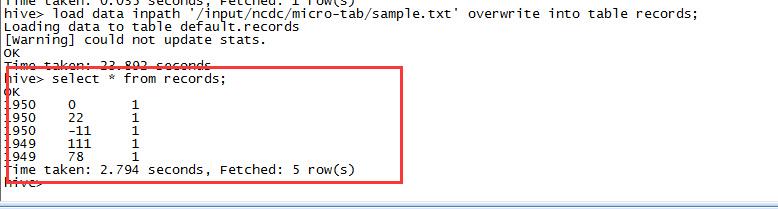
来一个分组查询:
select year , max(temperature) from records where temperature != 9999 and quality in ( 0,1,4,5,9) group by year;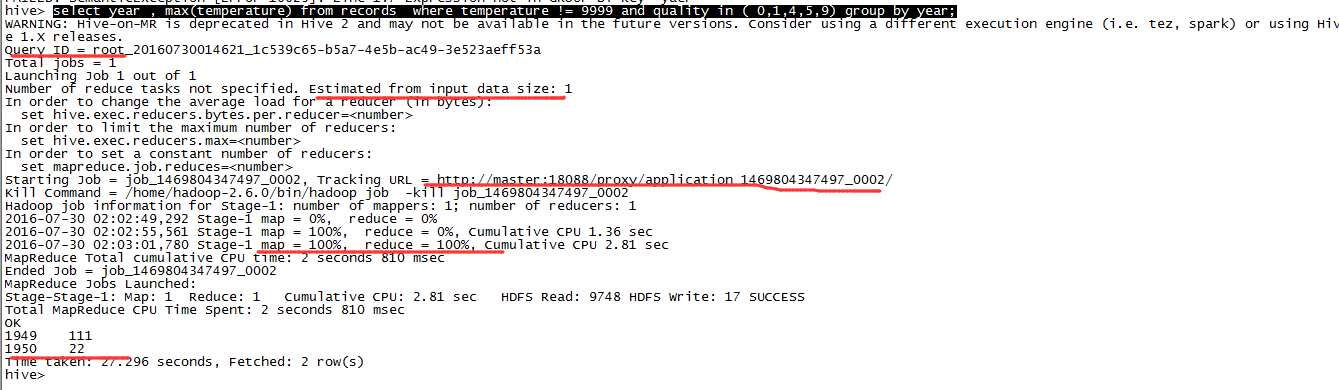
可以看到Hive启动了一个MapReduce作业,计算得到最终结果。YARN管理界面可以看到该作业:

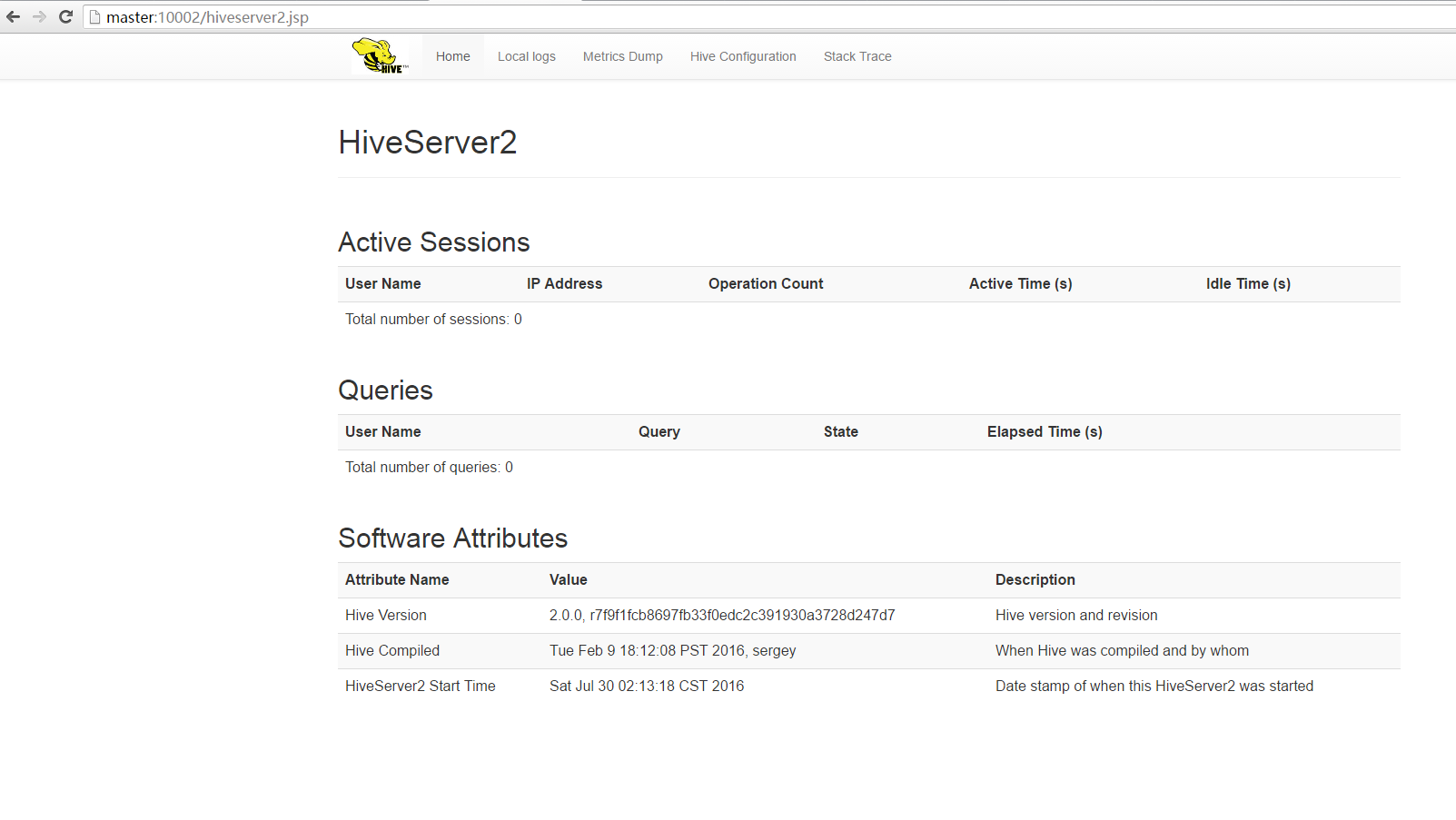
Hive Server
启动HiveServer2
hiveserver2
此时在默认的10020端口可以访问的hive界面:
(完)
0 0
- Hive:环境搭建及例子
- hive环境搭建及入门
- Hive基本原理及环境搭建
- Hive基本原理及环境搭建
- HIVE+mysql环境搭建及简单应用
- Hive 概述 体系架构及环境搭建
- Hive环境搭建
- 搭建hive调试环境
- Hive环境搭建
- hive环境搭建
- 搭建hive运行环境
- hive的环境搭建
- 关于hive环境搭建
- Hive环境搭建
- Hive环境搭建
- hive 环境搭建
- hive环境搭建
- Hadoop+Hive环境搭建
- svo简单探讨1
- HDU 4417-树状数组求区间rank查询/主席树区间rank查询
- Android Stdio安装与使用
- Linux 学习【2】
- Beego源码解析(一)——配置项初始化流程
- Hive:环境搭建及例子
- 51Nod-1459-迷宫游戏
- HDU2647:Reward(拓扑排序)
- iOS 音视频: 编译 FFmpeg-3.1.1
- Ubuntu 下安装搜狗拼音
- 10018---Linux CentOS7下 mysql-5.7.1x tar.gz包安装教程
- Android学习资源
- 数据结构~~单向链表
- 在VNC远程桌面环境Xfce4中Tab键失效的解决方法


