理解Hive表(Hive Table)
来源:互联网 发布:网络直销模式案例分析 编辑:程序博客网 时间:2024/05/10 08:39
Hive表逻辑上有表的数据和相关的元数据组成。元数据描述表的结构,索引等信息。数据通常存放在HDFS中,虽然任意的Hadoop文件系统都能支持,例如Amazon的S3或者而本地文件系统。元数据则存在关系型数据库中,嵌入式的默认使用Derby,MySQL是一种很常用的方案。
许多关系型数据库都提供了命名空间的概念,用于划分不同的数据库或者Schema。例如MySQL支持的Database概念,PostgreSQL支持的namespace概念。Hive同样提供了这种逻辑划分功能,相关的语句包括:
CREATE DATABASE dbname;USE dbname;DROP DATABASE dbname;表的全称可以通过dbname.tablename来访问,如果没有指定dbname,默认为default。show databases和show tables命令可用于查看数据库以及数据库中的表。
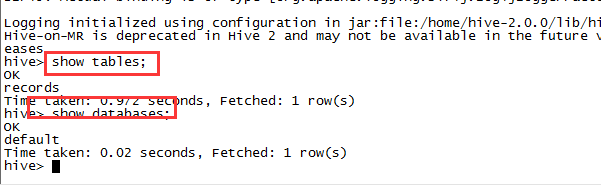
1. 内部表与外部表
在Hive中创建表的时候,默认情况下Hive将会管理表的数据,也就是将数据移动到对应的warehouse目录下。也可以创建 外部表,告诉Hive将表指向warehouse目录外的数据。
这两种类型的不同首先表现在LOAD和DROP语句的行为上。考虑下面的语句:
CREATE TABLE managed_table(dummy ,STRING);LOAD DATA INPATH '/user/root/data.txt' INTO table managed_table;上述语句会将hdfs://user/root/data.txt移动到Hive的对应目录hdfs://user/hive/warehouse/managed_table 。载入数据的速度非常快,因此Hive只是把数据移动到对应的目录,不会对数据是否符合定义的Schema做校验,这个工作通常在读取的时候进行,成为Schema On Read。
数据表使用DROP语句删除后,其数据和表的元数据都被删除,不再存在,这就是Hive Managed的意思。
DROP TABLE managed_table;外部表则不一样,数据的创建和删除完全由自己控制,Hive不管理这些数据。数据的位置在CREATE时指定:
CREATE EXTERNAL TABLE external_table (dummy,STRING) LOCATION '/user/root/external_table';LOAD DATA INPATH '/user/root/data.txt' INTO TABLE external_table;指定EXTERNAL关键字后,Hive不会把数据移动到warehouse目录中。事实上,Hive甚至不会校验外部表的目录是否存在。这使得我们可以在创建表格之后再创建数据。当删除外部表时,Hive只删除元数据,而外部数据不动。
选择内部表还是外部表?大多数情况下,这两者的区别不是很明显。如果数据的所有处理都在Hive中进行,那么更倾向于选择内部表。但是如果Hive和其他工具针对相同的数据集做处理,外部表更合适。一种常见的模式是使用外部表访问存储的HDFS(通常由其他工具创建)中的初始数据,然后使用Hive转换数据并将其结果放在内部表中。相反,外部表可以用于将Hive的处理结果导出供其他应用使用。使用外部表的另一种场景是针对一个数据集,关联多个Schema。
2. 分区与Buckets
Hive将表划分为分区,Partition根据分区字段进行。分区可以让数据的部分查询变得更快。表或者分区可以进一步被划分为buckets,bucket通常在原始数据中加入一些额外的结构,这些结构可以用于高效查询。例如,基于用户id的分桶可以使用基于用户的查询非常快。
分区
假设日志数据中,每条记录都带有时间戳。如果根据时间来分区,那么同一天的数据将被划分到同一个Partition中。针对每一天或者某几天数据的查询将会变得很高效,因为只需要扫描对应分区中的文件。分区并不会导致跨度大的查询变得低效。
分区可以通过多个维度来进行。例如通过日期划分之后,我们可以根据国家进一步划分。
分区在创建表的时候定义,使用 PARTITIONED BY从句,该从句接受一个字段列表:
CREATE TABLE logs (ts BIGINT , line STRING)PARTITIONED BY (dt STRING,country STRING);当导入数据到分区表时,分区的值被显式指定:
LOAD DATA INPATH '/user/root/path'INTO TABLE logsPARTITION (dt='2001-01-01',country='GB');在文件系统上,分区作为表目录的下一级目录存在:
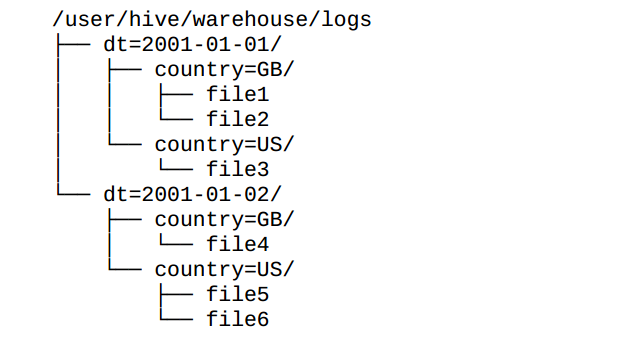
SHOW PARTITION命令可以显示表的分区:
hive> SHOW PARTITIONS logs;
虽然我们将用于分区的字段成为分区字段,但是在数据文件中,不存在这些字段的值,这些值是从目录中推断出来的。但是在SELECT语句中,我们依然可使用分区字段:
SELECT ts , dt , lineFROM logsWHERE country='GB'这个语句智慧扫描file1,file2以及file4.返回的dt字段由Hive从目录名提取,而不是数据文件。
Bucket
在表或者分区中使用Bucket通常有2个原因,一是为了高效查询。Bucket在表中加入了特殊的结果,Hive在查询的时候可以利用这些结构提高效率。例如,如果两个表根据相同的字段进行分桶,则在对这两个表进行关联的时候,可以使用map-side关联高效实现,前提是关联的字段在分桶字段中出现。 第二个原因是可以高效地进行抽样。在分析大数据集时,经常需要对部分抽样数据进行观察和分析,Bucket有利于高效实现抽样。
为了让Hive对表进行分桶,我们通过CLUSTER BY从句在创建表的时候指定:
CREATE TABLE bucketed_users(id INT, name STRING)CLUSTERED BY (id) INTO 4 BUCKETS;我们指定表根据id字段进行分桶,并且分为4个桶。分桶时Hive根据字段哈希后取余数来决定数据应该放在哪个痛,因此每个桶都是整体数据的随机抽样。
在map-side的关联中,两个表根据相同的字段进行分桶,因此处理左边表的bucket时,可以直接从外表对应的bucket中提取数据进行关联操作。map-side关联的两个表不一定需要完全相同的Bucket数量,只要是倍数即可。进一步信息请参考Map关联.
在一个Bucket内部,数据可以根据一个或者多个字段进行排序,这可以进一步提高map-side关联的效率,此时关联操作变成了一个合并排序(merge sort),下面的语句展示桶内排序:
CREATE TABLE bucketed_users(id INT,name STRING)CLUSTERED BY (id) SORTED BY (id ASC) INTO 4 BUCKETS;需要注意的是,Hive并不会对数据是否满足表定义中的分桶进行校验,只有在查询的时候,出现异常才会给出错误。因此一种更好的方式是将分桶的工作交给Hive来完成,假设我们有如下未分桶的数据:
hive> create table users(id INR , name STRING);hive> insert into users values (0,'Nat'),(2,'Joe'),(3,'Kay'),(4,'Ann');hive> SELECT * FROM users;0 Nat2 Joe3 Kay4 Ann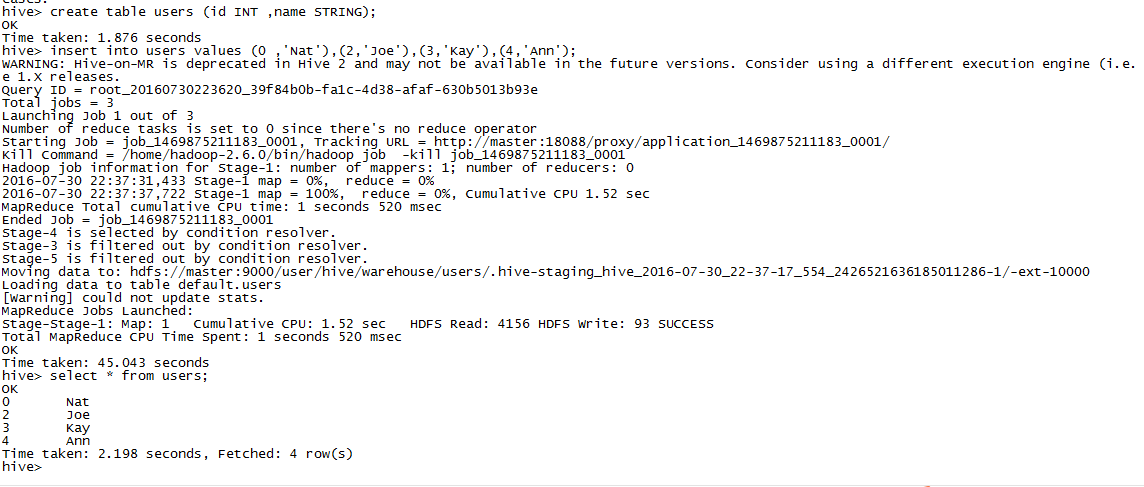
为了把这些数据填入到分桶的表中,我们需要设置hive.enforce.bucketing属性为true:
hive> set hive.enforce.bucketing = true;在Hive 2.x 版本中,无需设置这个属性。
然后使用下面的语句插入数据:
INSERT OVERWRITE TABLE bucketed_usersSELECT * FROM users;在物理存储上,每个Bucket对应表或者分区目录下的一个文件。事实上,这些文件是MapReduce的输出文件,文件的数量与Reducer数量一致。查看HDFS的文件结构我们可以证实这一点,4个文件对应我们指定的4个Bucket。

在查看一下文件的内容,可以看到id为0和4放在bucket0中,而bucket1则没有数据,id为2的数据放在bucket2中;
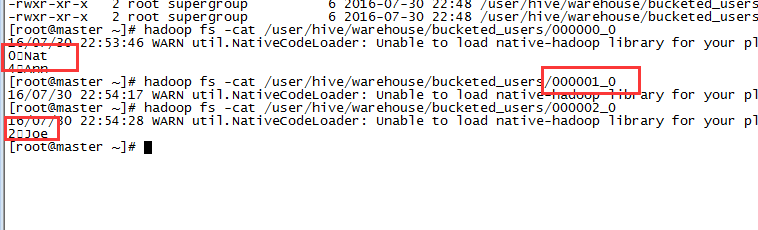
我们对表进行抽样,结果是一致的:
select * from bucketed_users tablesample(bucket 1 out of 4 on id);
注意这里的bucket数是从1开始,跟文件中的0不一样。通过指定bucket的比例,women可以抽样想要的数据,例如下面的语句返回一半bucket(即2个bucket)的数据:
select * from bucketed_userstablesample(bucket 1 out of 2 on id)
对分桶的表进行采样是很高效的,因为只需要扫描符合tablesample从句的bucket,使用随机函数抽样则不一样,需要对全表进行扫描:
select * from bucketed_userstablesample(bucket 1 out of 4 on rand());3. 存储格式
Hive中表存储的格式通常包括2个方面: 行格式(row format)和文件格式(file format)。
行格式描述行和行中的字段如果被存储。在Hive中,行格式通过SerDe来定义,SerDe代表序列化和反序列化。当查询表数据时,SerDe扮演反序列化的角色,将文件中行的字节数据反序列化为对象。当进行数据插入的时候,将数据序列化为行的字节格式,写入到文件中。在使用CREATE TABLE创建表的时候,ROW FORMAT指定的就是行的格式,例如字段分隔符、容器内部元素分隔符等。
file format则侧重于描述整个数据文件的格式,最简单的格式是纯文本文件。STORED AS从句用于指定文件格式,默认情况下,也就是没有指定STORED AS时,格式为文本格式TEXTFILE。STORED AS AVRO指定文件存储为avro数据文件。面向行和面向列的二进制格式也可用,例如Parquet,SequenceFile等。
3.1 默认存储格式:字段分隔的文本
当创建表时,如果没有指定ROW FORAMT或者STORED AS从句,Hive默认使用分隔字段的文本格式,每行对应一条记录。每一行数据中,字段的分隔符为CTRL+A。在数据或者STRUCT等数据类型中,元素之间采用CTRL+B分隔,即分隔数组元素,STRUCT的名值对或者Map的键值对。Map的键和值之间采用CTRL+C分隔。行与行之间采用换行符分隔。总结如下表:
需要注意的是,上述的分隔符只是针对通常的数据类型。在嵌套的复杂类型中,则根据嵌套结构的不同,采用不同的分隔符,具体参考Hive文档。
所以,默认情况下的CREATE语句:
CREATE TABLE ...;等同于:
CREATE TABLE ...ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' COLLECTION ITEMS TERMINATED BY '\002' MAP KEYS TERMINATED BY '\003' LINE TERMINATED BY '\n'STORED AS TEXTFILE在内部,Hive使用LazySimpleSerDe作为操作对象,与MapReduce中的文本输入输出协同工作。
文本形式的文件方便其他工具对浙西而数据进行处理,例如MapReduce和Straming。同时Hive提供了更加紧凑和高效的结构。
3.2 二进制格式:
要使用二进制格式,在创建表的时候指定STORED AS从句,不需要指定ROW FORMAT,因为行的格式完全由对应的二进制文件控制。
二进制的存储格式可以分为两类:面向行和面向列。如果查询只需要用到部分列,面向列的格式比较合适。如果需要处理的是行中的大部分数据,则面向行的格式是更好的选择。
Hive原生支持的面向行的格式有Avro数据文件和SequenceFile。这两种格式都是通用的,可切分的,可压缩的格式。Avro还支持模式解析和多种语言的绑定。下面语句使用压缩的Avro作为存储格式:
SET hive.exec.compress.output=true;SET avro.output.codec=snappy;CREATE TABLE ... STORED AS AVRO;STORED AS SEQUENCEFILE指定使用序列文件作为存储。
Hive原生支持的面向列的存储格式有Parquet,RCFile和ORCFile。下面的语句使用Parquet作为存储:
CREATE TABLE users_parquet STORED AS PARQUETASSELECT * FROM users;3.3 使用自定义的SerDe
SerDe是Hive表行数据的具体操作对象,可以在创建表的时候指定自定义的序列化机制,例如下面的语句使用基于正则表达式的SerDe来处理数据的读写:
CREATE TABLE stations ( usaf STRING, wban STRING , name STRING)ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'WITH SERDEPROPERTIES( "input.regex"="(\\d{6}) (\\d{5}) (.{29}) .*")ROW FORMAR SERDE指定使用SerDe,SERDEPROPERTIES指定相关的属性。
将下面格式的数据导入到表中:
LOAD DATA INPATH "/input/ncdc/metadata/stations-fixed-width.txt"INTO TABLE stations;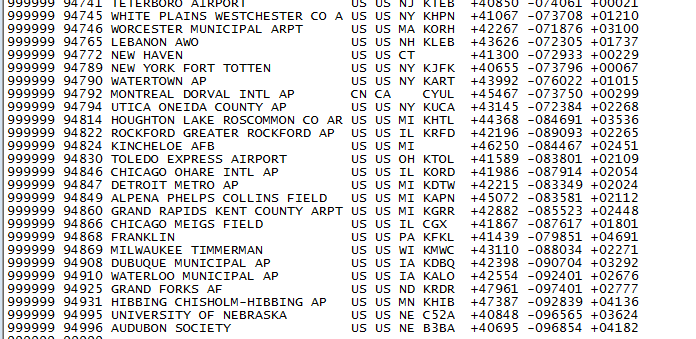
再次从表中读取数据时,将根据SerDe反序列化数据,得到如下结果:
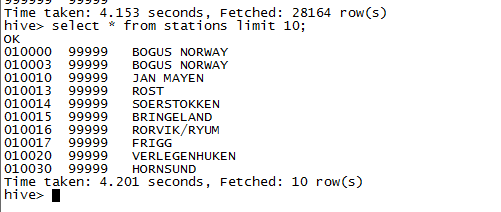
实际存储的还是相同的数据,但是解析出来是,只有我们定义的三个字段的数据。warehouse目录下的数据如下:
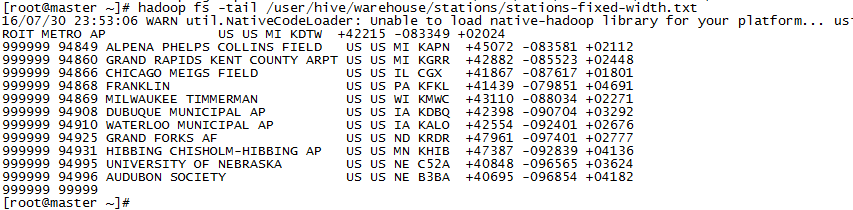
3.4 存储处理器(Storage Handler)
Storage Handler用于访问Hive无法直接访问的存储,例如HBase。通过STORED BY从句指定,而不是ROW FORMAT和STORED AS。更多Storage Handler的信息,参考Hive Wiki。
4. 导入数据
LOAD DATA通过移动或者复制文件到表对应的目录中。我们也可以从一张表中查询出数据后插入到另一张Hive表,或者使用CREATE TABLE AS SELECT创建表。如果要从关系型数据看导入数据,考虑使用Sqoop之类的工具。
4.1 INSERT
下面是一个插入的例子:
INSERT OVERWRITE TABLE targetSELECT col1 ,col2FROM source对于分区的表,插入的时候可以指定分区:
INSERT OVERWRITE TABLE targetPARTITION(dt='2010-01-01')SELECT col1 ,col2FROM source;OVERWRITE关键字表示覆盖表中或者分区中的原有数据。INSERT INTO则追加数据不覆盖。分区也可以动态指定,成为动态分区插入:
INSERT INTO TABLE targetPARTITION(dt)SELECT col1,col2,dtFROM source也可以使用VALUES插入记录:
INSERT INTO users values( 1,'name'),(2,'name');4.2 多表插入
Hive支持下面的插入语句:
FROM source INSERT OVERWRITE TABLE target SELECT col1,col2;这种语法在从一个数据源提取数据,并插入到多张表的时候很有用:
FROM recordsINSERT INTO TABLE stations_by_year SELECT year ,COUNT(DISTINCT station) GROUP BY yearINSERT INTO TABLE record_by_year SELECT year,count(1) GROUP BY yearINSERT INTO TABLE good_records_by_year SELECT year , count(1) WHERE temperature != 9999 AND quality in (0,1,4,5,9) GROUP BY year;4.3 Create Table … as Select
CTAS用于将查询结果直接插入到另外一张新建的表。新表的Schema从查询结果中推断。
CREATE TABLE targetAS SELECT col1,col2FROM source;CTAS操作是原子的,如果SELECT失败,则表不会创建。
5. 修改表
Hive的Schema On Read使得修改表结构很容易。使用ALTER TABLE修改表结构,修改表名的语句如下:
ALTER TABLE source RENAME TO target;和MySQL的语法几乎一样。如果是内部表,则相应的数据文件被重命名,外部表则只修改元数据。
下面的语句添加一列:
ALTER TABLE source ADD COLUMNS (col3 STRING);修改列的名称或类型也类似SQL的语法,只要旧的数据类型可以被解释为新的数据类型,更多语法参考Hive手册。
6. 删除表
DROP TABLE语句删除表的数据和元数据。对于外部表,只删除metastore中的元数据,而外部数据保存不动。
如果只想删除表数据,保留表结构,跟MySQL类似,使用TRUNCATE语句:
TRUNCATE TABLE my_table;这个语句只针对内部表,如果要删除外部表的数据,在Hive Shell中使用 dfs -rmr命令,该命令直接删除外部表的目录。
如果要创建一个跟现有表结构一样的空表,也跟MySQL类似使用LIKE关键字:
CREATE TABLE new_table LIKE existing_table;- 理解Hive表(Hive Table)
- Hive-table
- HIVE CREATE TABLE(一)
- HIVE理解
- Hive中的数据库(Database)和表(Table)
- SparkSQL操作Hive Table(enableHiveSupport())
- hive中的bucket table
- hive中的bucket table
- hive create extenal table
- mapreduce access hive table
- impala access hive table
- Hive table 操作
- Hive中的partition table
- Hive Alter Table
- hive中的bucket table
- Hive之Table
- Hive
- HIVE
- hdu 5777 domino(贪心)
- 冒泡排序之从小到大排序
- RecyclerView新体验(1)
- maven安装以及eclipse配置maven
- VMware Centos6.5 网络设置
- 理解Hive表(Hive Table)
- windows下PyCharm运行和调试scrapy
- thinkphp怎么修改默认提示信息
- Android小知识总结
- php学习--7GD库入门
- Spark-Hadoop、Hive、Spark 之间是什么关系?
- hdoj 1394 Minimum Inversion Number
- 淘宝APPKEY
- Monge矩阵(算法导论)


