Kylin学习入门
来源:互联网 发布:cda数据分析师怎么样 编辑:程序博客网 时间:2024/06/06 03:19
Kylin是什么?
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据。
Apache Kylin是首个完全由中国团队设计开发,并完整贡献到Apache软件基金会(ASF)的顶级项目。
主页:http://kylin.apache.org/
由于开发团队是中国人,所以该项目与别的Apache项目不一样,所有的文档都有中文版。
OLAP场景
Kylin作为一个大数据领域的OLAP的引擎,其性能和设计也主要是基于OLAP的特点来的,这里简单介绍一下OLAP。
OLAP(Online Analytical Processing)联机分析处理过程,是数据仓库系统最主要的应用,专门设计用于支持复杂的分析操作,侧重对决策人员和高层管理人员的决策支持,可以根据分析人员的要求快速、灵活地进行大数据量的复杂查询处理,并且以一种直观而易懂的形式将查询结果提供给决策人员,以便他们准确掌握企业(公司)的经营状况,了解对象的需求,制定正确的方案。
OLAP的主要操作有:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot)。如下图所示,在这里不一一细讲。

与其相对应的是OLTP(On-Line Transaction Processing)联机事务处理过程,也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。
两者的的特点如下:

针对OLAP场景的这些特点,业界对OLAP的通用解决方案如下:
预运算
- 提前运算好数据,提高查询效率
面向列存储
- OLAP中多使用大宽表,面向列的存储方式能提高查询效率。
冗余存储
- 不同的数据结构应对不同的查询场景
Kylin特点
作为大数据领域的OLAP引擎,kylin在基于传统的解决方案的基础上,使用了自己独特的实现: 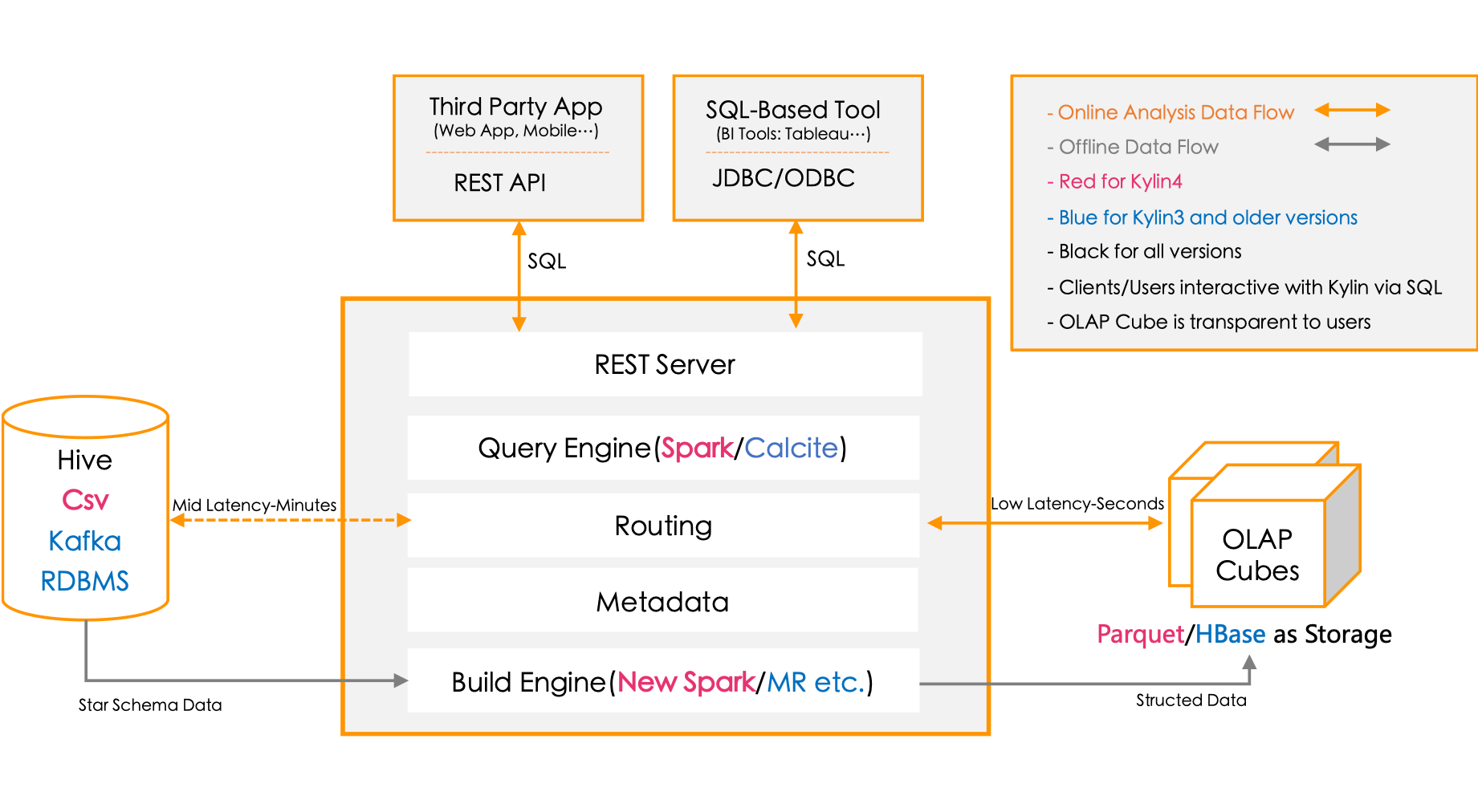
建立Cube
- 数据都是历史的,操作多为查询
- 预计算
- 冗余存储
存入Hbase
- 数据是多维的
- 面向列存储
基于Hadoop
- Batch计算
- 聚合计算
数据立方体
一个N维的完全Cube,是由:1个N维子立方体(Cuboid), N个(N-1)维Cuboid, N*(N-1)/2个(N-2)维Cuboid …, N个1维Cuboid, 1个0维Cuboid,总共2^N个子立方体组成的;在“逐层算法”中,按维度数逐渐减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。

通过预先计算好条件维度所有可能的组合,在查询时,直接查询对应的表能大大的减少查询的输入数据量,提高查询效率。
同时,kylin在cube构建的算法上做了很多优化,以提高性能。其算法主要有以下一些特点:
Mapper的预聚合
Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量,Combiner也不再需要;
一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。
数据压缩
计算过程中,使用字典表,减少数据传输。
维度聚合过程如下图所示:

从图中可以看出,当维度过多的时候,大量数据会保存在内存中。可能会导致OOM。
本文先介绍到这里,更多的内容大家可以到kylin官网了解~~其文档和介绍都挺全面的。
- Kylin学习入门
- kylin学习
- kylin入门到实战:入门
- kylin入门到实战:入门
- kylin学习(一)
- Apache kylin学习笔记
- kylin的doc学习
- kylin学习(一)
- kylin学习(二)
- Apache Kylin的入门安装
- KYLIN基于CDH入门实战(2)之kylin安装
- KYLIN基于CDH入门实战(1)之kylin简介
- Kylin
- Kylin
- kylin
- Kylin
- 《KyLin学习理解》-01-KyLin麒麟的简介及其思想
- 《KyLin学习理解》-02-KyLin的网页界面使用
- source insight 编程风格(持续更新)
- 华为OJ 挑7
- Model-View-ViewModel for iOS
- 我的Android开发之旅(二)Android布局管理
- 对bean生命周期的认识
- Kylin学习入门
- 二叉排序树
- E
- Starting namenodes on [master] hadoop@master's password:
- ALSA audio 术语
- HDU_2955_Robberies(变种的01背包)
- 简单的外边距折叠问题
- 支持向量机(SVM)二
- LCA--最近公共祖先


