使用 InfoSphere Warehouse 和 Cognos 检测偏差
来源:互联网 发布:多媒体网络教学系统 编辑:程序博客网 时间:2024/06/01 07:50
简介
在当前的很多 IT 应用中,及时发现可疑行为是一项很重要的任务。以信用卡事务为例。如果一个用户表现出异常的购买行为(例如,平常都是在廉价商店买东西,现在突然购买昂贵的珠宝),那么最好检查相应的事务,以跟踪欺诈行为。除了检测欺诈行为或恶意操纵外,偏差还可以用于其他一些场景。人力资源部门使用偏差检测来发现异常的雇员或求职者。如果仅凭固定的规则识别潜在的情况,则这些人可能被忽视。
偏离全局数据分布的数据记录称为离群值(outlier)。离群值处理通常不是一项完全自动化的任务。相反,数据挖掘用于指出有待分析师或专家进一步分析的数据记录。然后,析师或专家以此为依据决定是否采取行动。因此,一个先进的用户界面和交互模型是成功处理离群值的前提条件。Cognos 很适合完成这项任务。实际上,可以使用一个类似于本系列 的 将 InfoSphere Warehouse 数据挖掘与 IBM Cognos 报告集成,第 1 部分:InfoSphere Warehouse 与 Cognos 集成架构概述 中创建的报告来可视化离群值。但是,要想充分利用 Cognos 显示离群值的潜力,需要采用一些更高级的技巧。首先,看看如何使用 “穿透钻取(drill-through)” 来创建交互式 Cognos 报告,以及如何链接报告。这将有助于总结信息,同时允许快速访问相关的异常数据记录。其次,学习如何从数据挖掘模型中提取出附加信息,这些附加信息可帮助专家理解离群值的性质。
本文中的实例是一个应用程序,该应用程序帮助一家银行的雇员识别行为异常的客户。这个应用程序可用于避免欺诈,或检测出需要特别关注的客户。下一小节将对偏差检测作一个概述,并展示如何使用 InfoSphere Warehouse 发现大型数据集中的离群值。随后的小节则阐述从挖掘模型中穿透钻取和提取信息的基础知识,并展示如何使用这两种技巧使偏差检测结果更容易理解和利用。
使用 InfoSphere Warehouse 进行偏差检测
什么是偏差检测?
偏差检测是一项在大型数据集中发现异常数据记录的任务。这些记录称为离群值。“异常” 的确切定义还有待讨论,但它与应用偏差检测的领域有关。通常而言,偏差检测的目标是发现不符合大多数数据记录整体统计分布的数据记录。根据应用领域不同,偏差可能是:
- 不正确的数据(例如,如果一个人的年龄为 300,这很可能是数据库中一个不正确的条目)
- 异常行为(例如,不符合通常模式的信用卡事务)
相应地,偏差检测可用于不同的任务。如果您猜测数据集包含不正确的数据,那么可以应用偏差检测进行数据清洗,从而发现数据库中不正确的条目。在第二种情况下,数据是正确的,但是反映出某个过程表现出异常的行为。这可用于检测欺诈,这是偏差检测的第二个主要应用。前面已指出,异常的行为不一定是欺诈。例如,也可能表明新兴的模式,比如 “过度使用在线拍卖的老年客户”。尽早检测出新兴模式有助于公司尽早提供新的产品或服务,从而获得竞争优势。在财务部门就可以发现类似的应用。可以使用偏差检测来发现有前景的投资,这种投资不符合通常的模式,因而到目前为止还没有人意识到。在所有这些案例中,必须由分析师来检查离群值,看看是数据是否正确,是否需要采取措施避免欺诈,或者利用还没有人意识到的机遇。接下来将了解 InfoSphere Warehouse 如何检测离群值,以及如何对数据应用偏差检测。本文剩下的内容讨论如何在 Cognos 中交互式地可视化离群值。
InfoSphere Warehouse 中的偏差检测
近年来产生了很多不同的用于检测偏差的方法。InfoSphere Warehouse 使用一种特别强大的方法来进行偏差检测,这种方法基于数据集群。集群是一种数据挖掘技术,这种技术根据数据记录的属性将相近的数据记录指定到集群中。我们来看看图 1。图中每个点表示一个客户。在这个简单的案例中,客户只以年龄和平均余额来描述。InfoSphere Warehouse 使用一个统计集群算法将在这两个维上相近的客户分到集群中。可以看到,有些集群比其他集群更大,更集中(集群 1 相对于集群 3)。InfoSphere Warehouse 结合一些属性为每个集群赋予一个 “偏差” 度。这个度越高,则该集群中的记录越有可能是离群值。
图 1. 基于集群的偏差检测
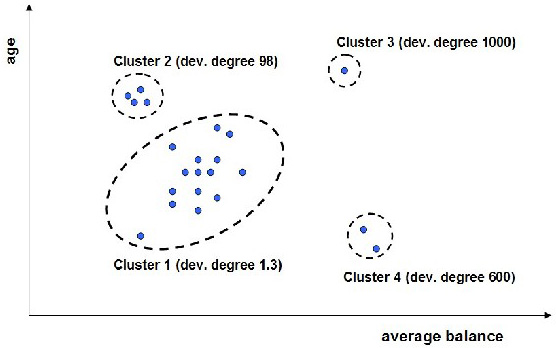
离群值与非离群值之间并没有明显的区别。实际上,用户必须指定一个阈值,以便界定离群值。偏差度高于这个阈值的所有集群被标记为离群值集群,它们的成员都是离群值。这个阈值可通过两种方式来设置。首先,如果检查离群值的专家有限,那么可以使用具有最高偏差度的集群的数据记录。如果要寻找有投资前景的公司,那么可以先从具有最高偏差度的集群开始,然后在资源允许的情况下,逐渐转向偏差度较低的集群。其次,阈值可以是固定的。一个例子就是警报场景,在此场景中,当有新的数据记录分配到具有高于给定阈值的偏差度的集群时,则需要采取行动。InfoSphere Warehouse 同时支持这两种方式,您只需为每个数据记录赋予一个集群 id 和相应的偏差度。您可以过滤记录,也可以对它们进行排序,从而获得想要查看或必须检查的离群值。接下来的小节将提供一个例子,以逐步演示如何用 InfoSphere Warehouse 发现离群值,以及如何为各个数据记录赋予偏差度。
一个实例
接下来的例子对关于银行客户的条目应用偏差检测。图 2 中显示了相应表中的示例数据。表 BANK.BANKCUSTOMERS 是 InfoSphere Warehouse 的示例中附带的。
图 2. BANK.BANKCUSTOMERS 表中的示例数据
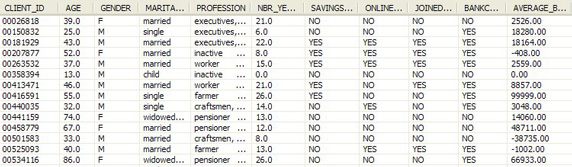
为了检测这个表中的离群值:
- 像 将 InfoSphere Warehouse 数据挖掘与 IBM Cognos 报告集成,第 1 部分:InfoSphere Warehouse 与 Cognos 集成架构概述 中描述的那样,创建一个新的挖掘流。
- 同样,像上一篇文章那样,您必须将一个 table source 操作符拖到编辑器中。
- 双击打开这个操作符,指定
BANK.BANKCUSTOMERS作为源数据库表,并单击 OK 确认。 - 现在,将一个 “Find Deviations” 操作符拖到画布上 table source 旁边的位置,并将 table source 的输出端连接到 “Find deviations” 的输入端。将 “Find Deviations” 操作符生成的集群模型的模型名称改为
IDMMX.OUTLIERMODEL。双击该操作符打开属性,在向导的第二页更改模型名称。 - 最后,从 “Find Deviations” 操作符输出端的右键菜单中选择 “Create Suitable Table...”,创建适当的目标表。在向导的第一个页面上,选择模式BANK,并输入表名
CUSTOMERS_OL。单击 Finish。一个 “Table Target” 操作符将被连接到流中。如果想要多次运行这个流,那么可以在 “Table Target” 操作符的属性中勾选复选框 “Delete Previous Content”。
这个流装载客户表,将它传递到偏差检测算法,并将结果写到一个新表中(如 图 3 所示)。在图 4 中可以看到具体的结果。
图 3. 用于检测偏差的挖掘流
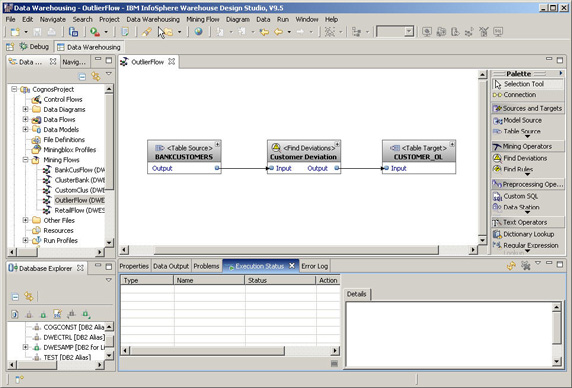
可以看到,这里有两个附加列,即 DEV_DEGREE 和 CLUSTER_ID。前一个列表明记录倾向于离群值的程度。cluster id 是记录所属的 “离群值” 集群的 id。可以通过分析 find deviation 操作符内部创建的集群模型,提取关于这些集群的更多信息。(本文还将对此进行详细讨论)。
图 4. 结果表 BANK.CUSTOMER_OL 中的示例数据
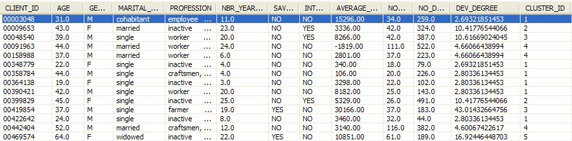
为偏差检测创建交互式 Cognos 报告
在本节中,学习如何创建允许交互式查看离群值的 Cognos 报告。开始时可以使用一个类似于本系列第一篇文章中所用的报告。但是,这次不是一个病人列表(其中有一个关于哪些病人应该进行体检的指示器),而是一个客户列表,其中有一个关于应该检查哪些客户的指示器,看是否存在欺诈或潜在机会。这种方法适用于有较少数量客户的列表,但不适用于有数千个条目的列表。而且,分析师可能还想看是什么使得一个特定的客户成为一个 “离群值”。需要更多的信息才能完成这个任务。因此,让我们从两个方面来扩展这个简单的方法:
- 将客户按职业分组,并提供关于每种职业发现多少离群值的概述。这种分组方式对于处理大量的信息是一个好方法。例如,可以让一个特定的雇员负责一个类别,使每个类别都得到检查。除了职业外,其他方面也可以用于分组(比如位置)。
- 对于每个记录,添加将其划分为离群值的信息。如前所述,每个记录被指定到一个集群,一个集群的所有成员具有相同的偏差度。因此,可以使用一个集群的属性来描述离群值。例如,如果一个集群中大部分是年轻人,而他们有较高的平均余额,那么这可以很好地解释为什么这个集群被认为是离群值集群。
接下来的小节首先展示如何用附加信息扩展离群值。然后,您将创建一个交互式报告,该报告将客户按职业分组,并且允许使用 Cognos 的 “穿透钻取” 特性交互式地选择一个特定类别中的离群值。
从挖掘模型中提取附加信息
表 CUSTOMER_OL 包含关于离群值的相关信息。如前所述,每个记录被指定到一个集群。“Find Deviations” 操作符在后台创建一个集群模型,其中存储关于这些集群的详细信息。该信息以 PMML(Predictive Model Markup Language)格式存储在数据库中。它包含关于以下方面的信息:
- 集群中值的分布
- 集群中记录的数量
- 每个集群的偏差的重要性
- 集群的同质性
- 其他
可以使用 InfoSphere Warehouse 附带的存储过程将该信息提取到结果集中,以便 Cognos 进一步处理。这样的结果集可以看作是 “视图”,它们不是显式地在数据库中创建的,而是由存储过程动态地创建的。
如果要提取关于集群的文本信息,可使用以下命令:
SELECT ID, DESCRIPTION FROM TABLE(IDMMX.DM_GETCLUSTERS((SELECT MODEL FROM IDMMX.CLUSTERMODELS WHERE MODELNAME='IDMMX.OUTLIERMODEL'))) AS CT
这样可以得到一个包含以下列的表:
- ID:集群的 id(对应于 CUSTOMER_OL 表中的 ID)
- DESCRIPTION:集群的文本描述
Cognos可以使用这些结果集作为视图或表。惟一要注意的是,DB2 中没有包括这些存储过程,它们是由 InfoSphere Warehouse 提供的。我们稍后对此进行讨论。图 5 总结了从 InfoSphere 提取信息到 Cognos 的两种方法:使用简单的数据库视图/表,或者使用存储过程从挖掘模型中提取信息。这些存储过程不仅可以用于集群模型,还可以用于其他挖掘模型。要获得所有可用的模型提取函数的列表,请参阅 InfoSphere Warehouse 文档(见 参考资料)。接下来,我们将展示如何使用 Cognos framework manager 合并这两种信息。
图 5. 在 Cognos 中访问和挖掘相关信息的两种方法
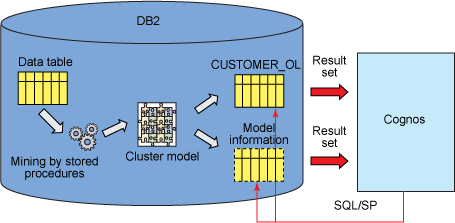
在 Cognos Framework Manager 中导入和合并挖掘结果
对于这个报告,Cognos 项目中需要两个查询主题,然后通过连接它们获得每个离群值的文本描述:
- 一个简单的访问第一节中创建的离群值表 BANK.CUSTOMER_OL 的查询主题。这个查询主题包含客户记录和偏差度以及集群 id。
- 查询主题使用存储过程访问由挖掘算法创建的集群模型的集群信息。如前所述,集群信息包括对集群的简短文本描述(在这里就是对这个集群中所有离群值记录的描述)和其他信息。
首先,需要创建一个 Cognos Framework Manager 项目,该项目连接到 InfoSphere Warehouse 的示例数据库 DWESAMP,并且有前面创建的 BANK.CUSTOMERS_OL 表。本系列的将 InfoSphere Warehouse 数据挖掘与 IBM Cognos 报告集成,第 1 部分:InfoSphere Warehouse 与 Cognos 集成架构概述 提供这个步骤的详细说明。一个很好的做法是在 PresentationView 名称空间中创建一个查询主题,这个查询主题包含必要的数据库中的信息,以便拥有从 SQL 语句创建的查询主题上的抽象层。这也使得您可以将列名改成更具描述性的文本,还可以添加更多的列。您需要一个离群值标记项,以表明一个记录是否为离群值。可以根据偏差度查询项 DEV_DEGREE 计算出这个标记项。
为了创建报告使用的离群值表查询主题:
- 在 PresentationView 名称空间中从模型(已有的查询主题和查询项)创建一个新的查询主题 “OutlierTable”。
- 添加 CUSTOMER_OL 查询主题中的所有查询项,并将它们的名称改成更具描述性的名称。
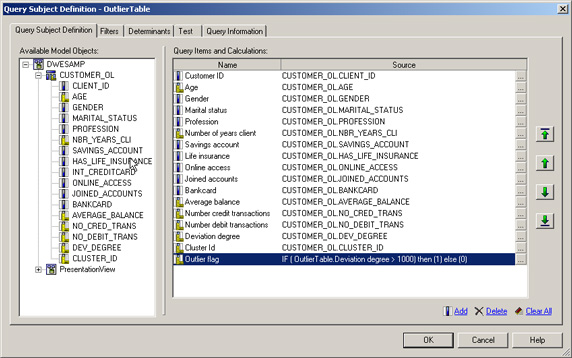
- 用以下表达式定义添加一个新的查询项:
IF ([PresentationView].[OutlierTable].[Deviation factor] > 1000) then (1) else (0)
如果偏差大于 1000,这个查询项的值将为 “1”;否则,它将为 “0”。偏差系数 1000 用作数据集的敏感分界系数。将这个偏差敏感度参数化有助于返回更多或更少的记录作为离群值。
查询主题定义看上去应该如图 6 所示:图 6. 离群值表的查询主题定义
第二个查询项是一个表,其中包含关于集群模型的集群的信息,这个集群模型是在 find deviation 运行期间创建的。可以在 InfoSphere Warehouse Data Mining 中使用用户定义函数IDMMX.DM_GETCLUSTERS 提取集群模型的列表描述。该函数返回一个表,其中包含模型中的集群,以及关于这个集群中字段分布的简短文本描述。在 IDMMX.CLUSTERMODELS 表中,集群模型被保存为 CLOBS,另外,该表中还包括一个 “MODELNAME” 列,用于选择适当的模型。用户定义函数需要打包到SELECT 语句中,以供 Gognos 使用。由于 InfoSphere Warehouse Mining 表函数不是标准的 DB2 函数,所以在创建这个查询主题之前,需要更改一些 Cognos 选项。
为了从 DB2 表函数创建集群描述查询主题,您需要:
- 在 Project Viewer 中,选择 Data Sources 文件夹中的数据库 DWESAMP,在属性视图中将 “Query Processing” 属性改为 “Limited Locale”。这样就启用了来自 SQL 的 Cognos 不能识别的查询主题。
- 在 PresentationView 名称空间中创建一个新的查询主题 “OutlierClusters”,并选择从一个数据源对该查询主题建模。如果从一个存储过程中对它进行建模,那么只支持 Cognos 能识别的存储过程。
- 在 “Select a data source” 页面上,选择 DWESAMP,并取消对选择 Run database query subject wizard 复选框。查询主题向导只适用于标准 SQL。单击Finish。
- 创建查询主题后,会出现 Query Subject Definition 向导。输入 SQL 代码,以返回模型中的集群,其中 IDMMX.OUTLIERMODEL 是 “find deviations” 运行期间生成的集群模型的名称。
SELECT * FROM TABLE(IDMMX.DM_GETCLUSTERS((SELECT MODEL FROM IDMMX.CLUSTERMODELS WHERE MODELNAME='IDMMX.OUTLIERMODEL'))) AS CT
- 由于 Cognos 不能识别这个的 SQL,因此需要将查询的 SQL 类型设为 “Native”,这告诉 Cognos 将 SQL 传递给数据库,而不是解释它。要改变这个设置,可以打开查询主题属性的 “Query Information” 选项卡。选择 “Options”,将 “SQL settings” 下的 “SQL type” 改为 “Native”。
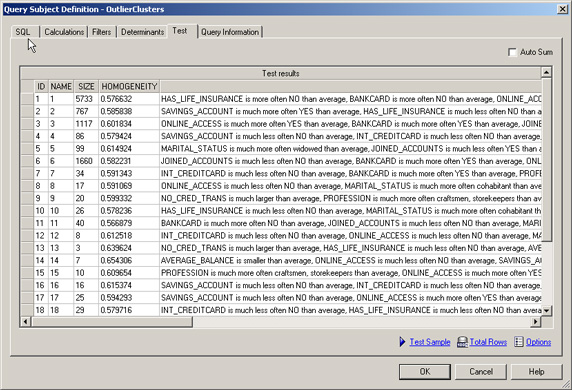
- “Test Sample” 运行后应该返回一个表,其中包含模型中的集群,如图 7 所示:
图 7. 离群值集群查询主题的测试结果
使用存储过程作为查询主题输入有一个好处,那就是不需要在数据库中创建不必要的表或视图。更重要的是,存储过程将在报告生成期间执行。这使得它可以在报告生成期间动态地执行挖掘计算。本系列后面的文章将更详细地讨论这个专题。
为了创建连接 OutlierTable 表和 OutlierClusters 查询主题的报告,需要在离群值记录中的集群 id 与集群表中的集群 id 之间建立一个关系。
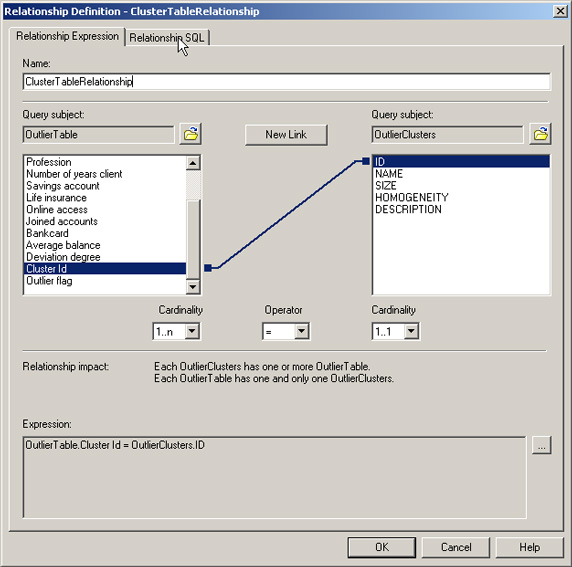
为了在 OutlierTable 与 OutlierClusters 查询主题之间建立一个关系,您需要:
- 从 OutlierTable 的上下文菜单中选择 Create Relationship。
- 对于左边的查询主题,选择 OutlierTable 的集群 id,并将基数设为 1..n,因为有多个记录属于同一个集群。
- 对于右边的查询主题,添加 OutlierClusters 查询主题,选择 ID 列,并将基数设为 1..1,因为对于每个集群有一行记录。
- 选择 OK。
图 8. OutlierTable 与 OutlierClusters 查询主题之间的关系
您已经创建了 Cognos 报告所需的查询主题,现在可以将一个包含项目的 PresentationView 的 “OutliersPackage” 部署到 Cognos Content Store。可以像本系列将 InfoSphere Warehouse 数据挖掘与 IBM Cognos 报告集成,第 1 部分:InfoSphere Warehouse 与 Cognos 集成架构概述 创建和部署这个包。
图 9. Framework Manager 中创建的资源
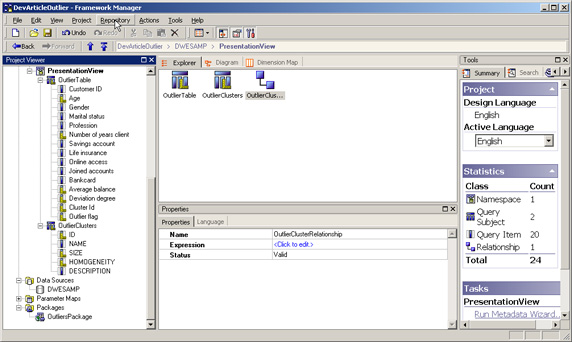
通过穿透钻取链接 Cognos 报告
“穿透钻取” 的原始概念是指从聚合值导航到单独的记录。这在 OLAP 应用中是一项常见的任务。在 Cognos 中,这个概念被延伸为将报告 “链接” 到一起。因此,穿透钻取的定义类似于 HTML 中的超级链接。链接报告本身并不是很强大的特性。参数的使用使穿透钻取成为真正强大工具。Cognos 中的每个报告可能包含一些参数,这些参数可用于创建可参数化的查询。如果还没有设置这些参数,将提示用户设置它们。在穿透钻取定义中,这些参数可被定义为超级链接的一部分(就像在HTTP GET 请求中一样)。这些参数的值可以通过链接的上下文获得。接下来的小节使用两个被链接的报告说明这一概念。
用 Cognos report studio 创建一个离群值报告
在本小节中,创建一个项目,其中包含两个基于部署的 OutliersPackage 的报告页面:
- 一个是主页面,显示按职业分组的客户记录的一个概述,其中分别列出每种职业中离群值的数量。
- 一个是报告页面,显示一种特定职业的偏差记录。
将链接这两个报告,以便从主概述页面穿透钻取到偏差记录。
由于概述页面包含详细页面的链接,所以先创建它。离群值详细界面包含被标记为离群值且属于主报告页面选定的职业的客户记录。为了创建这种交互,需要添加一个表示要报告的职业的参数,并在一个记录过滤器中使用它。另外还需要添加一个过滤条件,以便只返回 Outlier Flag 查询项为 “1” 的记录(偏差度超过阈值的所有记录)。
要创建 “Outlier Details” 报告页面,遵循以下步骤:
- 在 Cognos Report Studio 中使用 OutliersPackage 创建一个新的 Report。
- 添加一个列表对象到报告中。
- 从 “Insertable Objects” 视图中将 OutlierTable 查询主题拖放到该列表中,并将其添加到该列表中。
- 将 OutlierClusters 查询主题的 DESCRIPTION 查询项添加到该列表中。
- 通过选择该列表,并按工具栏上的 “Filters” 图标,或者从菜单中选择 Data > Filters,将一个过滤器添加到该列表中。
- 在向导中,用 “Add” 图标添加一个 “Details filter”。
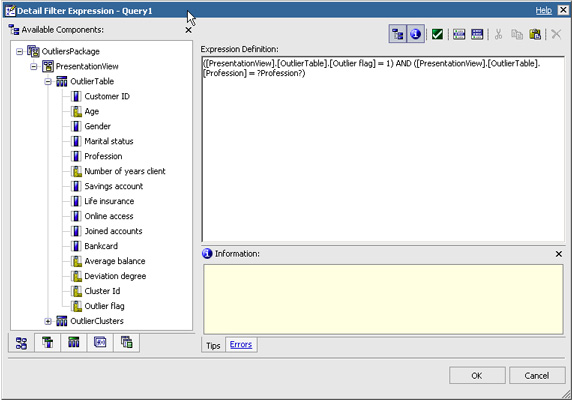
- 在 “Detail Filter Expression” 页面中,将以下代码添加到 “Expression Definition”。
([PresentationView].[OutlierTable].[Outlier flag] = 1) AND ([PresentationView].[OutlierTable].[Profession] = ?Profession?)
Cognos 将自动检测以 “?” 包围的作为参数的 “Profession” 关键词,并将它添加到报告的参数列表中。 - 按 OK 确认过滤器。
图 10. 用于 Outlier Details 页面的过滤器
- 根据自己的喜好更改报告的标题文本和列标题,并将报告保存为
OutlierDetails。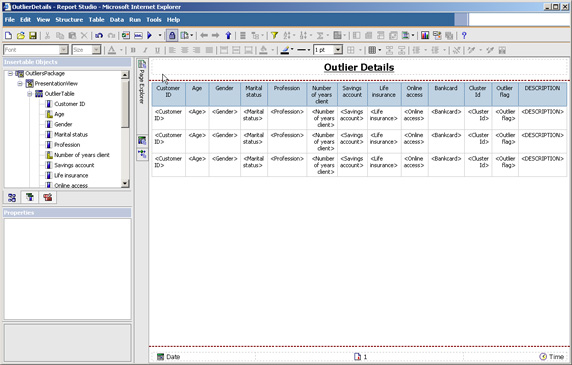
图 11. 包含 Outlier Details 报告的 Cognos Report Studio
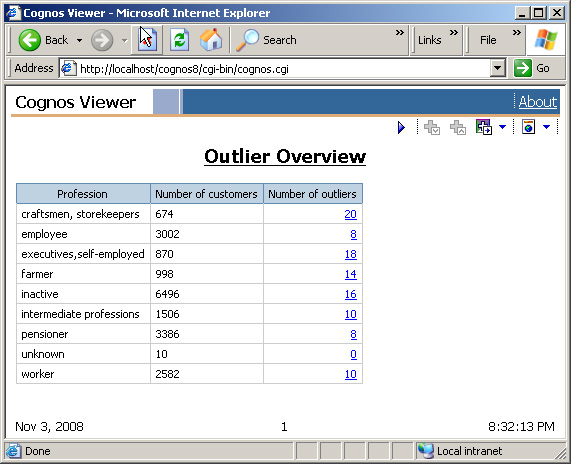
概述页面包含一个职业列表,显示每种职业的客户记录数量和离群值数量。记录数量将使用 Cognos 聚合函数计算。
为了创建 OutlierOverview 页面,您需要:
- 在 Cognos Report Studio中使用 OutliersPackage 创建一个新的报告。
- 添加一个列表对象到报告中。
- 从 “Insertable Objects” 视图中的 OutlierTable 查询主题中,将以下查询项添加到列表中:Profession/Customer ID 和Outlier flag。
- Customer ID 列用于显示每种职业客户记录的数量。为了计算这个值,需要在这个列的属性视图中将这个列的聚合函数改为 “Count”。
- OutlierFlag 列用于显示每种职业偏差记录的数量。对于每个偏差记录,这个列的值为 “1”,对于非偏差列,这个列的值为 “0”,因此,需要添加这个列的值。将这个列的聚合函数改为Total。
- 将 “Customer ID” 和 “Outlier flag” 列的 “Data Item” > “Name” 和 “Data Item” > “Label” 属性改为Number of customers 和 Number of outliers。
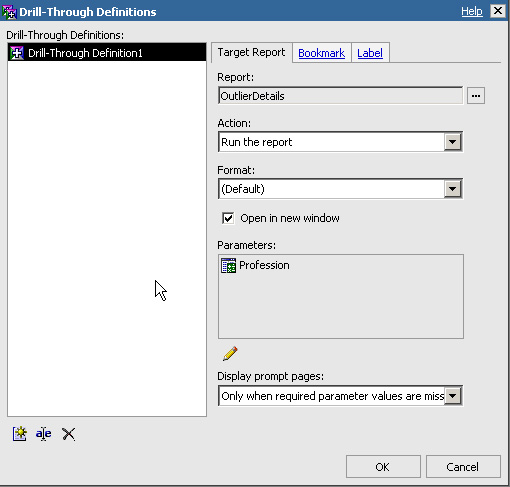
- 为了允许穿透钻取到 OutlierDetails Report,需要选择 Number of Outliers 列(不是标题,而是它下面的列),并从右键上下文菜单中选择Drill-Through Definitions。
- 添加一个新的穿透钻取定义。
- 在属性的 Target Report 选项卡中,选择 OutlierDetails 报告作为目标报告。
- 选择 Run the report 作为动作。
- 选择 Open in new window 复选框。
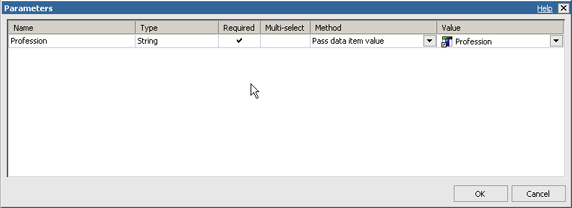
- 用参数列表下面的 Edit 按钮添加一个新的链接参数。
- 在 Parameters 对话框中,选择 Pass data item value 作为将参数链接到列表中的行中的一个值的方法。
- 选择 Profession 查询项作为数据项源,并选择 OK。
图 12. 穿透钻取定义参数
- 按 OK 保存穿透钻取定义。
图 13. 穿透钻取定义页面
- 更改标题文本,并将报告保存为
OutlierOverview。 - 现在,可以从 Run > Run HTML 菜单或者从 Cognos Connect 运行这个报告。
- 从 number of outliers 列中单击一个链接,以查看详细的记录。
图 14. 离群值概述页面
这个简单的项目由两个报告组成。通过使用 “穿透钻取” 定义(其中包含一个由链接的上下文定义的参数)避免需要为每种职业单独定义一个链接。本系列的后续文章将展示如何使用穿透钻取定义完成一些更复杂事情,比如动态调用数据挖掘。
结束语
在本文中,您学习了偏差检测,以及如何使用 InfoSphere Warehouse 执行偏差检测。偏差检测是高度交互性的任务,通常需要手动检查离群值,以查明是否存在欺诈倾向、数据错误或者潜在的机遇。Cognos 非常适合分析交互式离群值。除了本系列 的 将 InfoSphere Warehouse 数据挖掘与 IBM Cognos 报告集成,第 1 部分:InfoSphere Warehouse 与 Cognos 集成架构概述 中使用的简单技巧之外,您还学习了另外两个技巧。首先,可以使用存储过程从还没有包含在记录表中的挖掘模型提取附加信息。其次,可以使用 “穿透钻取” 特性链接 Cognos 报告,以支持交互式报告。在本系列的后续文章中,将学习如何通过从 Cognos 中动态地调用数据挖掘,以完成更加复杂的任务。
更多大数据与分析相关行业资讯、解决方案、案例、教程等请点击查看>>>
- 使用 InfoSphere Warehouse 和 Cognos 检测偏差
- InfoSphere Warehouse 数据挖掘与 Cognos 集成架构概述(一)
- 检测色卡饱和度和色彩偏差
- cognos 10安装和使用
- 使用libsvm得到训练出的权重和偏差
- 使用libsvm得到训练出的权重和偏差
- 偏差和方差
- 偏差和方差
- 偏差和方差
- 偏差和方差
- Warehouse
- 从 UML 到数据库,使用 Rational Software Modeler 和 InfoSphere Data Architect 加快数据模型的设计到实现
- [Cognos]什么企业适合使用Cognos Express
- Cognos 10和Cognos 8优缺点比较
- cognos使用流程
- cognos使用问题汇总
- 偏差和方差的区别
- 偏倚和偏差的权衡
- 学密码学一定得学程序
- 360兼容模式 IE8等 从代码中屏蔽 通知栏弹出“浏览器已经限制此文件显示可能访问您的计算机的活动内容”
- 网络基础知识
- Java GUI打包成jar包运行、注意事项、不弹出黑框、自带jre
- MySQL 5.7 深度解析: 半同步复制技术
- 使用 InfoSphere Warehouse 和 Cognos 检测偏差
- sql中update语句的几个特殊处理
- HTML学习15-color颜色
- Call 相关的知识
- HACM2009 求数列的和
- [绍棠] 保持iOS设备屏幕常亮的方法
- 有n个人围成一圈,顺序排号。从第一个人开始报数(从1到3报数)凡报到3的人退出圈子问最后留下1个人的是原来第几号的那位。
- java 反射机制的应用
- Per-CPU变量


