<<Spark Streaming Programming Guide>> - Part 2 基本概念
来源:互联网 发布:重庆邮电移通知乎 编辑:程序博客网 时间:2024/05/09 12:18
包的依赖
比较简单,有时间再翻译,先作为placeholder
初始化StreamingContext
StreamingContext通过SparkContext来创建。
from pyspark import SparkContextfrom pyspark.streaming import StreamingContextsc = SparkContext(master, appName)ssc = StreamingContext(sc, 1)其中appName指定了Spark程序的名字,在运行多个程序的Spark集群中会用来标识区分不同的程序;master参数指定Spark cluster的Master地址,根据使用不同的集群管理器 (standalone, YARN, Mesos) 会有不同的地址格式,另外还有一个特殊格式local[N]来指定本地模式(非集群模式),N用来指定线程个数,也是最多允许task的并发数目,另外可以使用特殊格式local[*]让Spark自动选择,它会探测的CPU的内核数(core)来用作N的值. 在实际的集群部署中,master参数都不会写死在代码里或者配置文件里,最方便的方式就是在通过spark-submit在提交程序到集群的时候通过--master参数运行时指定。
批处理的间隔在如上的例子里设置为1,单位为秒。具体值的设置取决于业务自身的需求,可用的集群资源,以及程序实际的处理能力。
context建立之后,需要做以下事情:
- 通过创建输入离散数据流(DStream)来定义输入流;
- 通过应用DStream的各种转换操作和最终的输出操作来定义流的计算方式;
- 启动数据流的接收和处理:
streamingContext.start(). - 等待程序运行被终止:
streamingContext.awaitTermination(). - 程序可以通过手动方式来结束终止:
streamingContext.stop().
需要记住的要点:
- 一旦StreamingContext被启动,流处理的计算方式不能被修改;
- 一旦StreamingContext被停止,则不能继续启动,只能重新启动;
- 在同一时刻,一个JVM里只能有一个被启动的StreamingContext;
- 终止 StreamingContext 同时也终止了关联的 SparkContext。如果只想终止StreamingContext 而不终止SparkContext,则在调用stop方法时指定可选参数stopSparkContext为false (默认为true,停止SparkContext)。StreamingContext.stop(stopSparkContext=True, stopGraceFully=False)
- SparkContext可以被StreamingContexts重用,只要不违反上面提到的约束3 - 在同一时刻一个JVM内只能有一个被启动的StreamingContext - 则当前一个StreamingContext停止后,就可以启动下一个StreamingContext。
离散数据流 (DStream)
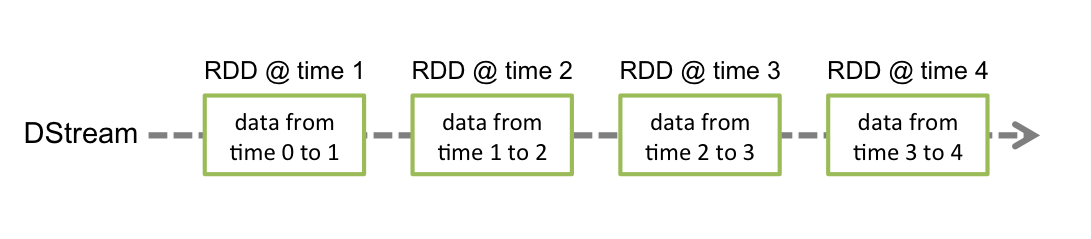
离散数据流是Spark Streaming提出的一个抽象概念,用来代表持续的数据流,数据流或者从数据源获得如kafka,或者通过其他的DStream转换而来。在内部,DStream实际是一组连续的RDD(RDD的解释具体参照Spark核心包),每一个RDD包含的是数据流在一定时间间隔的数据,如下图所示 -
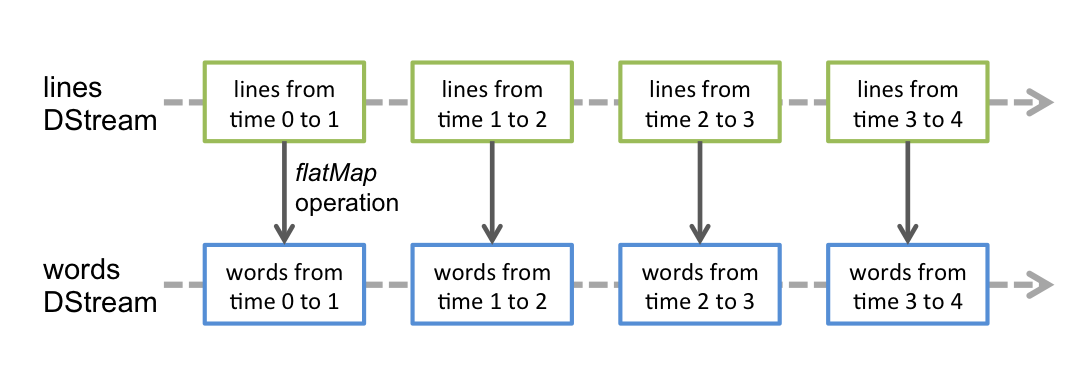
所有对DStream的操作实际是对内在的RDD的操作。例如在综述中的wordCount例子中将句子转换为单词的flatMap操作,会作用到每一个时间间隔对应的RDD上,如下如所示。
还是Spark的核心引擎对RDD进行转换操作,DStream操作只是在上面封装了一下,从而掩盖了大多数RDD操作的细节,对外暴漏出的是更高层易用的接口。具体的操作会在后面详述。
输入数据流和接收器
每一种输入数据流(除了文件流以外),都包含一个接收器(Receiver),接收器负责从数据源接收收据然后存储在Spark中。
两类数据源:
两类数据源:
- 基本数据源:直接存在在Spark Streaming的类库中,包括文件流和Socket流;
- 高级数据源:例如Kafka,Flume和Kinesis需要依赖外部的工具类。所以需要加入额外的依赖引入到工程中,例如pom中的dependency。
基本数据源
基本数据源除了从TCP Socket监听的文本数据流外,还可以把文件作为输入源。
文件数据流:
可以从任何兼容HDFS API的文件系统目录中读取数据(也就是HDFS, S3, NFS), 可以通过以下方式创建DStream -
streamingContext.textFileStream(dataDirectory)
Spark Streaming会监控目录dataDirectory,然后处理任何在此目录下创建的文件 (不支持递归的处理子目录),注意 streamingContext.textFileStream(dataDirectory)- 文件必须具有相同格式
- 文件必须一次改名或者移动到此目录下。
- 一旦文件移动到此目录后,后续对文件内容的修改不能被监听到。对于简单的文本文件,不需要创建receive接收器,所以不需要分配额外的内核。
基于定制化的接收器(Receiver):
可以自己实现接收器来创建DStream。
RDD队列作为Stream:
为了方便测试,可以基于RDD队列来创建DStream,使用streamingContext.queueStream(queueOfRDDs)。每一个加入队列的RDD被作为DSream中的一次批处理需要处理的数据。
高级数据源
Spark 2.0的Python API中可以使用了Kafka,Keneis 和 Flume的数据源。
这列数据源需要第三方的类库支持,例如kafak和Flume有着比较复杂的依赖。因此,为了减少依赖之间的版本冲突,因此把从这类数据源创建DStream的功能被移到了单独的类库中,只有当需要的时候才把它引入到工程的依赖中。
定制数据源
Python API不支持。
接收器的可靠性
根据可靠性可以分为两类数据源,一类如Kafka和Flume支持消息确认的数据源,因此当接收器接受到消息后可以向数据源进行数据的确认,这样可以保证没有数据的丢失。两类数据源 -
可靠的接收器 - 可靠的接收器能够在接收并且存储数据到Spark后,向数据源发送确认消息。要求的前提是这类数据源支持此确认机制;
不可靠的接收器 - 不可靠的接收器不会向数据源进行消息确认,一个可能是数据源本身不支持确认机制,例如Socket数据要换;一个是接收器不想这样做这么复杂,例如对数据的丢失可以容忍;
可靠的接收器 - 可靠的接收器能够在接收并且存储数据到Spark后,向数据源发送确认消息。要求的前提是这类数据源支持此确认机制;
不可靠的接收器 - 不可靠的接收器不会向数据源进行消息确认,一个可能是数据源本身不支持确认机制,例如Socket数据要换;一个是接收器不想这样做这么复杂,例如对数据的丢失可以容忍;
2 0
- <<Spark Streaming Programming Guide>> - Part 2 基本概念
- <<Spark Streaming Programming Guide>> - Part 1 综述
- Spark Streaming Programming Guide
- <<Spark Streaming Programming Guide>> - Part 3 转换操作
- Spark 2.1.0 -- Spark Streaming Programming Guide
- Spark1.1.0 Spark Streaming Programming Guide
- Spark Streaming Programming Guide(翻译)
- spark streaming programming guide 综述(一)
- spark streaming programming guide 快速开始(二)
- spark文档学习1 Spark Streaming Programming Guide
- spark streaming programming guide 基础概念之linking(三a)
- Spark Streaming基本概念
- Spark Programming Guide
- Spark programming guide
- Spark Programming Guide 中文版
- Spark Programming Guide
- Spark Programming Guide 翻译
- Spark Programming Guide
- C++宏定义详解
- 29 个你必须知道的 Linux 命令
- 《构建之法》读书笔记——第4章 两人合作
- 下载安装JDK,配置Java环境变量
- Http协议错误代码大全
- <<Spark Streaming Programming Guide>> - Part 2 基本概念
- 客都望梅归去来兮
- Linux下的静态库、动态库和动态加载库
- 字符串匹配--KMP算法
- 【C语言】C代码注释转换
- 第九天 判断二叉搜索树
- 乐观锁与悲观锁——解决并发问题
- JS 用字符串做数组下标
- 111


