推荐系统 —— 他人文章总结 -1
来源:互联网 发布:english in mind软件 编辑:程序博客网 时间:2024/04/27 19:52
华为协办的ACM RecSys国际会议圆满结束 推动推荐系统研究工作
通信世界网讯(CWW) 10月27日消息,日前,全球领先的信息与通信解决方案供应商华为在香港的诺亚方舟实验室协办的第七届推荐系统国际会议 (ACM International Conference on Recommender Systems 2013, RecSys 2013)于10月16日圆满结束。华为参与举办这次会议,成果丰硕,除了展示华为在大数据及推荐系统方面的研究成果外,也加深了华为跟各方学者及专家的交流和互动。
推荐系统是计算机研究中一个极其重要的领域,与大数据的关系密不可分。透过分析海量数据,推荐系统能够学习用户喜好跟各种物件属性的关係,以及不同情境下用户喜好或行为的变化,给出更精准、更个性化的推荐。
本次会议主席为诺亚方舟实验室主任杨强教授。杨教授在开幕上的讲话中提到,“这次Recsys大会是世界顶级的推荐系统大会,首次在亚洲举行,在大数据领域兴起的时候,举办这样一个学术界和工业界共同瞩目的会议,有着特别重要的意义。”会议也邀请了华盛顿大学的 Oren Etzioni 教授、百度公司技术副总监沈抖博士、及百合网联合创办人慕岩先生来出任主讲嘉宾。
会议上,诺亚方舟实验室副主任张宝峰在开幕礼上致辞。首席科学家李航博士于博士生研讨会上发言及为正在攻读博士课程的学生提供指导。另外,主任科学家戴文渊在工业界研讨会上发表华为在大数据及推荐系统方面的研究及未来的发展,分析推荐系统近年的演化过程,也介绍了华为正投入研发针对不同客户需求的推荐系统。新的推荐系统技术将大幅提升推荐的精度,同时减少系统需要人工调控的必要。
诺亚方舟实验室在推荐系统方面正进行多个相关项目:
1. 利用推荐技术及算法,给华为手机应用市场“智汇云”的用户推荐个性化的手机应用。
2. 透过跟银行合作,给客户推荐更合适的金融产品。
3. 开发微博机械人,分析微博上的内容,自动转发关注者可能感兴趣的微博讯息。
4. 透过分析用户喜好及行为,开发下一代的智能手机,随时随地分析用户兴趣及情境,推荐最能够帮助用户解决当前问题的选项,成为用户的最好伙伴。
这些项目都已经渐有成果,其中,手机应用推荐系统已经能够把“智汇云”应用的下载率提升超过30%,微博机械人也已经有超过400名真实用户关注(http://weibo.com/u/2867879661),并得到很多正面的反馈。这些项目所开发的技术,大大提升了华为在大数据分析及推荐系统方面的能力,使得华为在大数据时代中更具竞争力。
ACM RecSys会议是「计算机协会」举办的国际性会议。每年都会邀请推荐系统领域的杰出学者或研究员担任主讲嘉宾,吸引研究推荐系统的学者及工程师投稿。会议每年又举办名为 RecSys Challenge 的比赛,由互联网或资讯科技公司提供研究数据及出题,公开招募创新的算法。
诺亚方舟实验室专注大数据相关的研究,亦致力于推荐系统领域的发展。今后期望能继续与学术及工业界的学者及研究员交流,建立良好的合作关係,参与推动在推荐系统方面具前瞻性的研究工作。
推荐系统实验平台与案例
用Hadoop构建电影推荐系统
Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-mapreduce-recommend/

前言
Netflix电影推荐的百万美金比赛,把“推荐”变成了时下最热门的数据挖掘算法之一。也正是由于Netflix的比赛,让企业界和学科界有了更深层次的技术碰撞。引发了各种网站“推荐”热,个性时代已经到来。
目录
- 推荐系统概述
- 需求分析:推荐系统指标设计
- 算法模型:Hadoop并行算法
- 架构设计:推荐系统架构
- 程序开发:MapReduce程序实现
1. 推荐系统概述
电子商务网站是个性化推荐系统重要地应用的领域之一,亚马逊就是个性化推荐系统的积极应用者和推广者,亚马逊的推荐系统深入到网站的各类商品,为亚马逊带来了至少30%的销售额。
不光是电商类,推荐系统无处不在。QQ,人人网的好友推荐;新浪微博的你可能感觉兴趣的人;优酷,土豆的电影推荐;豆瓣的图书推荐;大从点评的餐饮推荐;世纪佳缘的相亲推荐;天际网的职业推荐等。
推荐算法分类:
按数据使用划分:
- 协同过滤算法:UserCF, ItemCF, ModelCF
- 基于内容的推荐: 用户内容属性和物品内容属性
- 社会化过滤:基于用户的社会网络关系
按模型划分:
- 最近邻模型:基于距离的协同过滤算法
- Latent Factor Mode(SVD):基于矩阵分解的模型
- Graph:图模型,社会网络图模型
基于用户的协同过滤算法UserCF
基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。
用例说明:
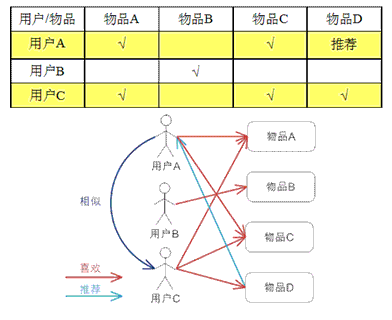
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。图 2 给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 – 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
基于物品的协同过滤算法ItemCF
基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
用例说明:
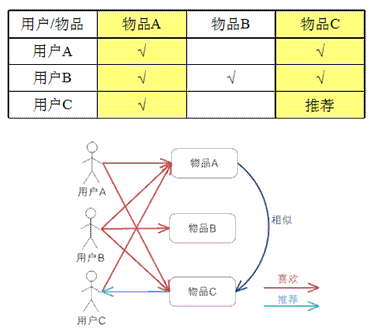
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。图 3 给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
上文中图片和对应图片解释,摘自:https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/
注:基于物品的协同过滤算法,是目前商用最广泛的推荐算法。
协同过滤算法实现,分为2个步骤
- 1. 计算物品之间的相似度
- 2. 根据物品的相似度和用户的历史行为给用户生成推荐列表
有关协同过滤的另一篇文章,请参考:RHadoop实践系列之三 R实现MapReduce的协同过滤算法
2. 需求分析:推荐系统指标设计
下面我们将从一个公司案例出发来全面的解释,如何进行推荐系统指标设计。
案例介绍
Netflix电影推荐百万奖金比赛,http://www.netflixprize.com/
Netflix官方网站:www.netflix.com
Netflix,2006年组织比赛是的时候,是一家以在线电影租赁为生的公司。他们根据网友对电影的打分来判断用户有可能喜欢什么电影,并结合会员看过的电影以及口味偏好设置做出判断,混搭出各种电影风格的需求。
收集会员的一些信息,为他们指定个性化的电影推荐后,有许多冷门电影竟然进入了候租榜单。从公司的电影资源成本方面考量,热门电影的成本一般较高,如果Netflix公司能够在电影租赁中增加冷门电影的比例,自然能够提升自身盈利能力。
Netflix公司曾宣称60%左右的会员根据推荐名单定制租赁顺序,如果推荐系统不能准确地猜测会员喜欢的电影类型,容易造成多次租借冷门电影而并不符合个人口味的会员流失。为了更高效地为会员推荐电影,Netflix一直致力于不断改进和完善个性化推荐服务,在2006年推出百万美元大奖,无论是谁能最好地优化Netflix推荐算法就可获奖励100万美元。到2009年,奖金被一个7人开发小组夺得,Netflix随后又立即推出第二个百万美金悬赏。这充分说明一套好的推荐算法系统是多么重要,同时又是多么困难。
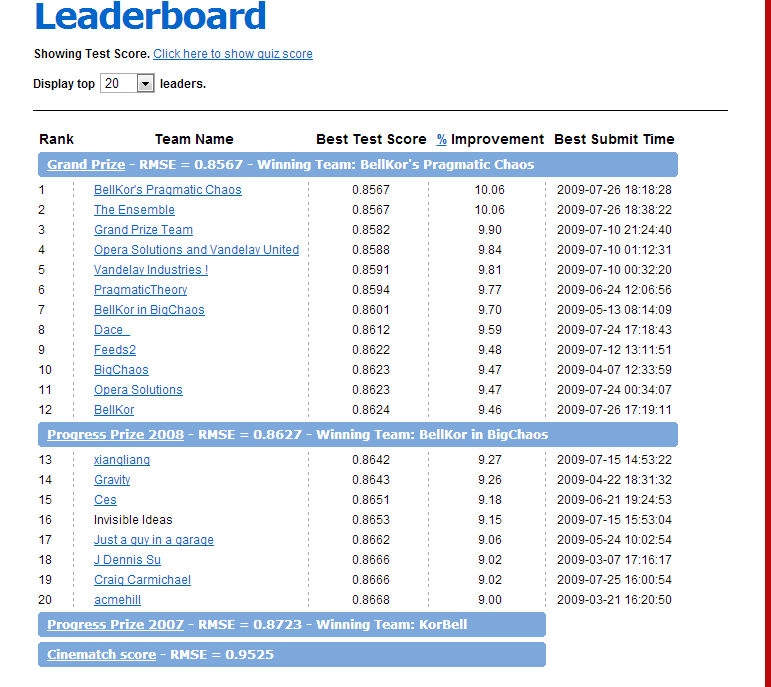
上图为比赛的各支队伍的排名!
补充说明:
- 1. Netflix的比赛是基于静态数据的,就是给定“训练级”,匹配“结果集”,“结果集”也是提前就做好的,所以这与我们每天运营的系统,其实是不一样的。
- 2. Netflix用于比赛的数据集是小量的,整个全集才666MB,而实际的推荐系统都要基于大量历史数据的,动不动就会上GB,TB等
Netflix数据下载
部分训练集:http://graphlab.org/wp-content/uploads/2013/07/smallnetflix_mm.train_.gz
部分结果集:http://graphlab.org/wp-content/uploads/2013/07/smallnetflix_mm.validate.gz
完整数据集:http://www.lifecrunch.biz/wp-content/uploads/2011/04/nf_prize_dataset.tar.gz
所以,我们在真实的环境中设计推荐的时候,要全面考量数据量,算法性能,结果准确度等的指标。
- 推荐算法选型:基于物品的协同过滤算法ItemCF,并行实现
- 数据量:基于Hadoop架构,支持GB,TB,PB级数据量
- 算法检验:可以通过 准确率,召回率,覆盖率,流行度 等指标评判。
- 结果解读:通过ItemCF的定义,合理给出结果解释
3. 算法模型:Hadoop并行算法
这里我使用”Mahout In Action”书里,第一章第六节介绍的分步式基于物品的协同过滤算法进行实现。Chapter 6: Distributing recommendation computations
测试数据集:small.csv
1,101,5.01,102,3.01,103,2.52,101,2.02,102,2.52,103,5.02,104,2.03,101,2.03,104,4.03,105,4.53,107,5.04,101,5.04,103,3.04,104,4.54,106,4.05,101,4.05,102,3.05,103,2.05,104,4.05,105,3.55,106,4.0每行3个字段,依次是用户ID,电影ID,用户对电影的评分(0-5分,每0.5为一个评分点!)
算法的思想:
- 1. 建立物品的同现矩阵
- 2. 建立用户对物品的评分矩阵
- 3. 矩阵计算推荐结果
1). 建立物品的同现矩阵
按用户分组,找到每个用户所选的物品,单独出现计数及两两一组计数。
[101] [102] [103] [104] [105] [106] [107][101] 5 3 4 4 2 2 1[102] 3 3 3 2 1 1 0[103] 4 3 4 3 1 2 0[104] 4 2 3 4 2 2 1[105] 2 1 1 2 2 1 1[106] 2 1 2 2 1 2 0[107] 1 0 0 1 1 0 12). 建立用户对物品的评分矩阵
按用户分组,找到每个用户所选的物品及评分
U3[101] 2.0[102] 0.0[103] 0.0[104] 4.0[105] 4.5[106] 0.0[107] 5.03). 矩阵计算推荐结果
同现矩阵*评分矩阵=推荐结果
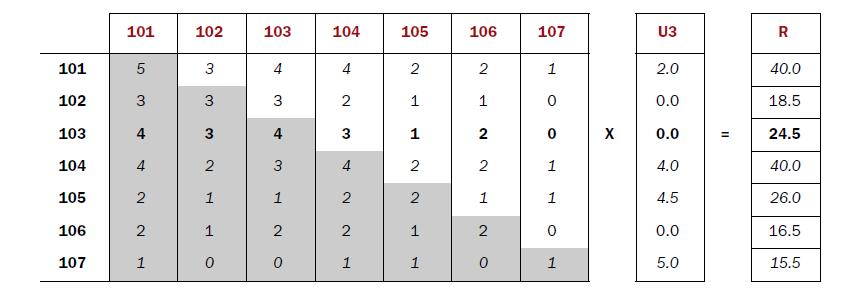
图片摘自”Mahout In Action”
MapReduce任务设计
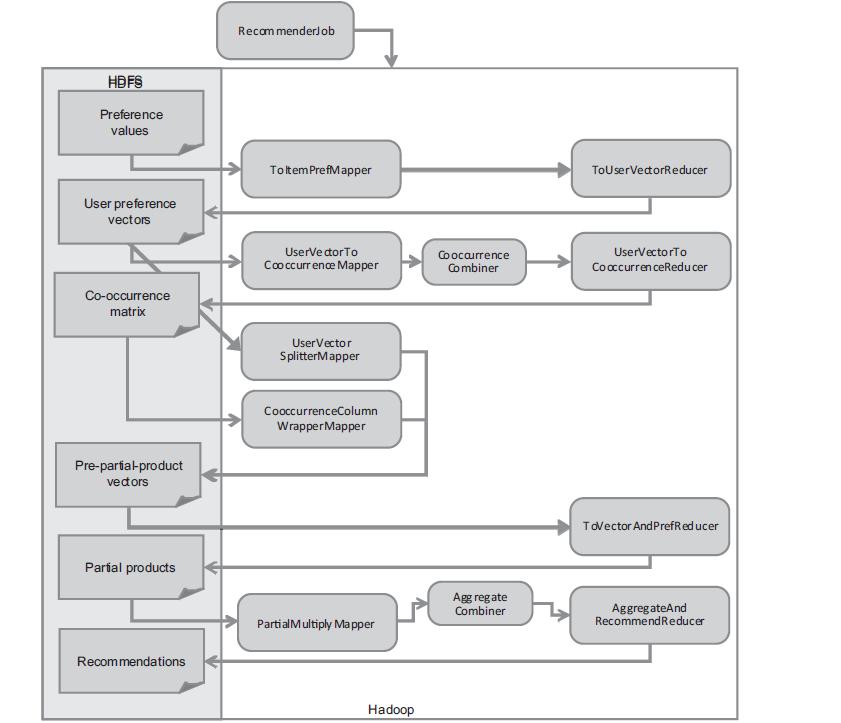
图片摘自”Mahout In Action”
解读MapRduce任务:
- 步骤1: 按用户分组,计算所有物品出现的组合列表,得到用户对物品的评分矩阵
- 步骤2: 对物品组合列表进行计数,建立物品的同现矩阵
- 步骤3: 合并同现矩阵和评分矩阵
- 步骤4: 计算推荐结果列表
4. 架构设计:推荐系统架构
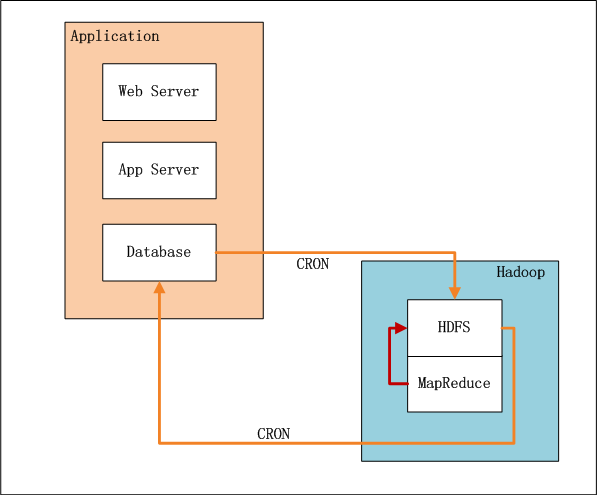
上图中,左边是Application业务系统,右边是Hadoop的HDFS, MapReduce。
- 业务系统记录了用户的行为和对物品的打分
- 设置系统定时器CRON,每xx小时,增量向HDFS导入数据(userid,itemid,value,time)。
- 完成导入后,设置系统定时器,启动MapReduce程序,运行推荐算法。
- 完成计算后,设置系统定时器,从HDFS导出推荐结果数据到数据库,方便以后的及时查询。
5. 程序开发:MapReduce程序实现
win7的开发环境 和 Hadoop的运行环境 ,请参考文章:用Maven构建Hadoop项目
新建Java类:
- Recommend.java,主任务启动程序
- Step1.java,按用户分组,计算所有物品出现的组合列表,得到用户对物品的评分矩阵
- Step2.java,对物品组合列表进行计数,建立物品的同现矩阵
- Step3.java,合并同现矩阵和评分矩阵
- Step4.java,计算推荐结果列表
- HdfsDAO.java,HDFS操作工具类
1). Recommend.java,主任务启动程序
源代码:
package org.conan.myhadoop.recommend;import java.util.HashMap;import java.util.Map;import java.util.regex.Pattern;import org.apache.hadoop.mapred.JobConf;public class Recommend { public static final String HDFS = "hdfs://192.168.1.210:9000"; public static final Pattern DELIMITER = Pattern.compile("[\t,]"); public static void main(String[] args) throws Exception { Map<String, String> path = new HashMap<String, String>(); path.put("data", "logfile/small.csv"); path.put("Step1Input", HDFS + "/user/hdfs/recommend"); path.put("Step1Output", path.get("Step1Input") + "/step1"); path.put("Step2Input", path.get("Step1Output")); path.put("Step2Output", path.get("Step1Input") + "/step2"); path.put("Step3Input1", path.get("Step1Output")); path.put("Step3Output1", path.get("Step1Input") + "/step3_1"); path.put("Step3Input2", path.get("Step2Output")); path.put("Step3Output2", path.get("Step1Input") + "/step3_2"); path.put("Step4Input1", path.get("Step3Output1")); path.put("Step4Input2", path.get("Step3Output2")); path.put("Step4Output", path.get("Step1Input") + "/step4"); Step1.run(path); Step2.run(path); Step3.run1(path); Step3.run2(path); Step4.run(path); System.exit(0); } public static JobConf config() { JobConf conf = new JobConf(Recommend.class); conf.setJobName("Recommend"); conf.addResource("classpath:/hadoop/core-site.xml"); conf.addResource("classpath:/hadoop/hdfs-site.xml"); conf.addResource("classpath:/hadoop/mapred-site.xml"); return conf; }}2). Step1.java,按用户分组,计算所有物品出现的组合列表,得到用户对物品的评分矩阵
源代码:
package org.conan.myhadoop.recommend;import java.io.IOException;import java.util.Iterator;import java.util.Map;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapred.FileInputFormat;import org.apache.hadoop.mapred.FileOutputFormat;import org.apache.hadoop.mapred.JobClient;import org.apache.hadoop.mapred.JobConf;import org.apache.hadoop.mapred.MapReduceBase;import org.apache.hadoop.mapred.Mapper;import org.apache.hadoop.mapred.OutputCollector;import org.apache.hadoop.mapred.Reducer;import org.apache.hadoop.mapred.Reporter;import org.apache.hadoop.mapred.RunningJob;import org.apache.hadoop.mapred.TextInputFormat;import org.apache.hadoop.mapred.TextOutputFormat;import org.conan.myhadoop.hdfs.HdfsDAO;public class Step1 { public static class Step1_ToItemPreMapper extends MapReduceBase implements Mapper<Object, Text, IntWritable, Text> { private final static IntWritable k = new IntWritable(); private final static Text v = new Text(); @Override public void map(Object key, Text value, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException { String[] tokens = Recommend.DELIMITER.split(value.toString()); int userID = Integer.parseInt(tokens[0]); String itemID = tokens[1]; String pref = tokens[2]; k.set(userID); v.set(itemID + ":" + pref); output.collect(k, v); } } public static class Step1_ToUserVectorReducer extends MapReduceBase implements Reducer<IntWritable, Text, IntWritable, Text> { private final static Text v = new Text(); @Override public void reduce(IntWritable key, Iterator values, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException { StringBuilder sb = new StringBuilder(); while (values.hasNext()) { sb.append("," + values.next()); } v.set(sb.toString().replaceFirst(",", "")); output.collect(key, v); } } public static void run(Map<String, String> path) throws IOException { JobConf conf = Recommend.config(); String input = path.get("Step1Input"); String output = path.get("Step1Output"); HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf); hdfs.rmr(input); hdfs.mkdirs(input); hdfs.copyFile(path.get("data"), input); conf.setMapOutputKeyClass(IntWritable.class); conf.setMapOutputValueClass(Text.class); conf.setOutputKeyClass(IntWritable.class); conf.setOutputValueClass(Text.class); conf.setMapperClass(Step1_ToItemPreMapper.class); conf.setCombinerClass(Step1_ToUserVectorReducer.class); conf.setReducerClass(Step1_ToUserVectorReducer.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(input)); FileOutputFormat.setOutputPath(conf, new Path(output)); RunningJob job = JobClient.runJob(conf); while (!job.isComplete()) { job.waitForCompletion(); } }}计算结果:
~ hadoop fs -cat /user/hdfs/recommend/step1/part-000001 102:3.0,103:2.5,101:5.02 101:2.0,102:2.5,103:5.0,104:2.03 107:5.0,101:2.0,104:4.0,105:4.54 101:5.0,103:3.0,104:4.5,106:4.05 101:4.0,102:3.0,103:2.0,104:4.0,105:3.5,106:4.03). Step2.java,对物品组合列表进行计数,建立物品的同现矩阵
源代码:
package org.conan.myhadoop.recommend;import java.io.IOException;import java.util.Iterator;import java.util.Map;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapred.FileInputFormat;import org.apache.hadoop.mapred.FileOutputFormat;import org.apache.hadoop.mapred.JobClient;import org.apache.hadoop.mapred.JobConf;import org.apache.hadoop.mapred.MapReduceBase;import org.apache.hadoop.mapred.Mapper;import org.apache.hadoop.mapred.OutputCollector;import org.apache.hadoop.mapred.Reducer;import org.apache.hadoop.mapred.Reporter;import org.apache.hadoop.mapred.RunningJob;import org.apache.hadoop.mapred.TextInputFormat;import org.apache.hadoop.mapred.TextOutputFormat;import org.conan.myhadoop.hdfs.HdfsDAO;public class Step2 { public static class Step2_UserVectorToCooccurrenceMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static Text k = new Text(); private final static IntWritable v = new IntWritable(1); @Override public void map(LongWritable key, Text values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String[] tokens = Recommend.DELIMITER.split(values.toString()); for (int i = 1; i < tokens.length; i++) { String itemID = tokens[i].split(":")[0]; for (int j = 1; j < tokens.length; j++) { String itemID2 = tokens[j].split(":")[0]; k.set(itemID + ":" + itemID2); output.collect(k, v); } } } } public static class Step2_UserVectorToConoccurrenceReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); @Override public void reduce(Text key, Iterator values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } result.set(sum); output.collect(key, result); } } public static void run(Map<String, String> path) throws IOException { JobConf conf = Recommend.config(); String input = path.get("Step2Input"); String output = path.get("Step2Output"); HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf); hdfs.rmr(output); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Step2_UserVectorToCooccurrenceMapper.class); conf.setCombinerClass(Step2_UserVectorToConoccurrenceReducer.class); conf.setReducerClass(Step2_UserVectorToConoccurrenceReducer.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(input)); FileOutputFormat.setOutputPath(conf, new Path(output)); RunningJob job = JobClient.runJob(conf); while (!job.isComplete()) { job.waitForCompletion(); } }}计算结果:
~ hadoop fs -cat /user/hdfs/recommend/step2/part-00000101:101 5101:102 3101:103 4101:104 4101:105 2101:106 2101:107 1102:101 3102:102 3102:103 3102:104 2102:105 1102:106 1103:101 4103:102 3103:103 4103:104 3103:105 1103:106 2104:101 4104:102 2104:103 3104:104 4104:105 2104:106 2104:107 1105:101 2105:102 1105:103 1105:104 2105:105 2105:106 1105:107 1106:101 2106:102 1106:103 2106:104 2106:105 1106:106 2107:101 1107:104 1107:105 1107:107 14). Step3.java,合并同现矩阵和评分矩阵
源代码:
package org.conan.myhadoop.recommend;import java.io.IOException;import java.util.Map;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapred.FileInputFormat;import org.apache.hadoop.mapred.FileOutputFormat;import org.apache.hadoop.mapred.JobClient;import org.apache.hadoop.mapred.JobConf;import org.apache.hadoop.mapred.MapReduceBase;import org.apache.hadoop.mapred.Mapper;import org.apache.hadoop.mapred.OutputCollector;import org.apache.hadoop.mapred.Reporter;import org.apache.hadoop.mapred.RunningJob;import org.apache.hadoop.mapred.TextInputFormat;import org.apache.hadoop.mapred.TextOutputFormat;import org.conan.myhadoop.hdfs.HdfsDAO;public class Step3 { public static class Step31_UserVectorSplitterMapper extends MapReduceBase implements Mapper<LongWritable, Text, IntWritable, Text> { private final static IntWritable k = new IntWritable(); private final static Text v = new Text(); @Override public void map(LongWritable key, Text values, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException { String[] tokens = Recommend.DELIMITER.split(values.toString()); for (int i = 1; i < tokens.length; i++) { String[] vector = tokens[i].split(":"); int itemID = Integer.parseInt(vector[0]); String pref = vector[1]; k.set(itemID); v.set(tokens[0] + ":" + pref); output.collect(k, v); } } } public static void run1(Map<String, String> path) throws IOException { JobConf conf = Recommend.config(); String input = path.get("Step3Input1"); String output = path.get("Step3Output1"); HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf); hdfs.rmr(output); conf.setOutputKeyClass(IntWritable.class); conf.setOutputValueClass(Text.class); conf.setMapperClass(Step31_UserVectorSplitterMapper.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(input)); FileOutputFormat.setOutputPath(conf, new Path(output)); RunningJob job = JobClient.runJob(conf); while (!job.isComplete()) { job.waitForCompletion(); } } public static class Step32_CooccurrenceColumnWrapperMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static Text k = new Text(); private final static IntWritable v = new IntWritable(); @Override public void map(LongWritable key, Text values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String[] tokens = Recommend.DELIMITER.split(values.toString()); k.set(tokens[0]); v.set(Integer.parseInt(tokens[1])); output.collect(k, v); } } public static void run2(Map<String, String> path) throws IOException { JobConf conf = Recommend.config(); String input = path.get("Step3Input2"); String output = path.get("Step3Output2"); HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf); hdfs.rmr(output); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Step32_CooccurrenceColumnWrapperMapper.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(input)); FileOutputFormat.setOutputPath(conf, new Path(output)); RunningJob job = JobClient.runJob(conf); while (!job.isComplete()) { job.waitForCompletion(); } }}计算结果:
~ hadoop fs -cat /user/hdfs/recommend/step3_1/part-00000101 5:4.0101 1:5.0101 2:2.0101 3:2.0101 4:5.0102 1:3.0102 5:3.0102 2:2.5103 2:5.0103 5:2.0103 1:2.5103 4:3.0104 2:2.0104 5:4.0104 3:4.0104 4:4.5105 3:4.5105 5:3.5106 5:4.0106 4:4.0107 3:5.0~ hadoop fs -cat /user/hdfs/recommend/step3_2/part-00000101:101 5101:102 3101:103 4101:104 4101:105 2101:106 2101:107 1102:101 3102:102 3102:103 3102:104 2102:105 1102:106 1103:101 4103:102 3103:103 4103:104 3103:105 1103:106 2104:101 4104:102 2104:103 3104:104 4104:105 2104:106 2104:107 1105:101 2105:102 1105:103 1105:104 2105:105 2105:106 1105:107 1106:101 2106:102 1106:103 2106:104 2106:105 1106:106 2107:101 1107:104 1107:105 1107:107 15). Step4.java,计算推荐结果列表
源代码:
package org.conan.myhadoop.recommend;import java.io.IOException;import java.util.ArrayList;import java.util.HashMap;import java.util.Iterator;import java.util.List;import java.util.Map;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapred.FileInputFormat;import org.apache.hadoop.mapred.FileOutputFormat;import org.apache.hadoop.mapred.JobClient;import org.apache.hadoop.mapred.JobConf;import org.apache.hadoop.mapred.MapReduceBase;import org.apache.hadoop.mapred.Mapper;import org.apache.hadoop.mapred.OutputCollector;import org.apache.hadoop.mapred.Reducer;import org.apache.hadoop.mapred.Reporter;import org.apache.hadoop.mapred.RunningJob;import org.apache.hadoop.mapred.TextInputFormat;import org.apache.hadoop.mapred.TextOutputFormat;import org.conan.myhadoop.hdfs.HdfsDAO;public class Step4 { public static class Step4_PartialMultiplyMapper extends MapReduceBase implements Mapper<LongWritable, Text, IntWritable, Text> { private final static IntWritable k = new IntWritable(); private final static Text v = new Text(); private final static Map<Integer, List> cooccurrenceMatrix = new HashMap<Integer, List>(); @Override public void map(LongWritable key, Text values, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException { String[] tokens = Recommend.DELIMITER.split(values.toString()); String[] v1 = tokens[0].split(":"); String[] v2 = tokens[1].split(":"); if (v1.length > 1) {// cooccurrence int itemID1 = Integer.parseInt(v1[0]); int itemID2 = Integer.parseInt(v1[1]); int num = Integer.parseInt(tokens[1]); List list = null; if (!cooccurrenceMatrix.containsKey(itemID1)) { list = new ArrayList(); } else { list = cooccurrenceMatrix.get(itemID1); } list.add(new Cooccurrence(itemID1, itemID2, num)); cooccurrenceMatrix.put(itemID1, list); } if (v2.length > 1) {// userVector int itemID = Integer.parseInt(tokens[0]); int userID = Integer.parseInt(v2[0]); double pref = Double.parseDouble(v2[1]); k.set(userID); for (Cooccurrence co : cooccurrenceMatrix.get(itemID)) { v.set(co.getItemID2() + "," + pref * co.getNum()); output.collect(k, v); } } } } public static class Step4_AggregateAndRecommendReducer extends MapReduceBase implements Reducer<IntWritable, Text, IntWritable, Text> { private final static Text v = new Text(); @Override public void reduce(IntWritable key, Iterator values, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException { Map<String, Double> result = new HashMap<String, Double>(); while (values.hasNext()) { String[] str = values.next().toString().split(","); if (result.containsKey(str[0])) { result.put(str[0], result.get(str[0]) + Double.parseDouble(str[1])); } else { result.put(str[0], Double.parseDouble(str[1])); } } Iterator iter = result.keySet().iterator(); while (iter.hasNext()) { String itemID = iter.next(); double score = result.get(itemID); v.set(itemID + "," + score); output.collect(key, v); } } } public static void run(Map<String, String> path) throws IOException { JobConf conf = Recommend.config(); String input1 = path.get("Step4Input1"); String input2 = path.get("Step4Input2"); String output = path.get("Step4Output"); HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf); hdfs.rmr(output); conf.setOutputKeyClass(IntWritable.class); conf.setOutputValueClass(Text.class); conf.setMapperClass(Step4_PartialMultiplyMapper.class); conf.setCombinerClass(Step4_AggregateAndRecommendReducer.class); conf.setReducerClass(Step4_AggregateAndRecommendReducer.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(input1), new Path(input2)); FileOutputFormat.setOutputPath(conf, new Path(output)); RunningJob job = JobClient.runJob(conf); while (!job.isComplete()) { job.waitForCompletion(); } }}class Cooccurrence { private int itemID1; private int itemID2; private int num; public Cooccurrence(int itemID1, int itemID2, int num) { super(); this.itemID1 = itemID1; this.itemID2 = itemID2; this.num = num; } public int getItemID1() { return itemID1; } public void setItemID1(int itemID1) { this.itemID1 = itemID1; } public int getItemID2() { return itemID2; } public void setItemID2(int itemID2) { this.itemID2 = itemID2; } public int getNum() { return num; } public void setNum(int num) { this.num = num; }}计算结果:
~ hadoop fs -cat /user/hdfs/recommend/step4/part-000001 107,5.01 106,18.01 105,15.51 104,33.51 103,39.01 102,31.51 101,44.02 107,4.02 106,20.52 105,15.52 104,36.02 103,41.52 102,32.52 101,45.53 107,15.53 106,16.53 105,26.03 104,38.03 103,24.53 102,18.53 101,40.04 107,9.54 106,33.04 105,26.04 104,55.04 103,53.54 102,37.04 101,63.05 107,11.55 106,34.55 105,32.05 104,59.05 103,56.55 102,42.55 101,68.06). HdfsDAO.java,HDFS操作工具类
详细解释,请参考文章:Hadoop编程调用HDFS
源代码:
package org.conan.myhadoop.hdfs;import java.io.IOException;import java.net.URI;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FSDataInputStream;import org.apache.hadoop.fs.FSDataOutputStream;import org.apache.hadoop.fs.FileStatus;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IOUtils;import org.apache.hadoop.mapred.JobConf;public class HdfsDAO { private static final String HDFS = "hdfs://192.168.1.210:9000/"; public HdfsDAO(Configuration conf) { this(HDFS, conf); } public HdfsDAO(String hdfs, Configuration conf) { this.hdfsPath = hdfs; this.conf = conf; } private String hdfsPath; private Configuration conf; public static void main(String[] args) throws IOException { JobConf conf = config(); HdfsDAO hdfs = new HdfsDAO(conf); hdfs.copyFile("datafile/item.csv", "/tmp/new"); hdfs.ls("/tmp/new"); } public static JobConf config(){ JobConf conf = new JobConf(HdfsDAO.class); conf.setJobName("HdfsDAO"); conf.addResource("classpath:/hadoop/core-site.xml"); conf.addResource("classpath:/hadoop/hdfs-site.xml"); conf.addResource("classpath:/hadoop/mapred-site.xml"); return conf; } public void mkdirs(String folder) throws IOException { Path path = new Path(folder); FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf); if (!fs.exists(path)) { fs.mkdirs(path); System.out.println("Create: " + folder); } fs.close(); } public void rmr(String folder) throws IOException { Path path = new Path(folder); FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf); fs.deleteOnExit(path); System.out.println("Delete: " + folder); fs.close(); } public void ls(String folder) throws IOException { Path path = new Path(folder); FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf); FileStatus[] list = fs.listStatus(path); System.out.println("ls: " + folder); System.out.println("=========================================================="); for (FileStatus f : list) { System.out.printf("name: %s, folder: %s, size: %d\n", f.getPath(), f.isDir(), f.getLen()); } System.out.println("=========================================================="); fs.close(); } public void createFile(String file, String content) throws IOException { FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf); byte[] buff = content.getBytes(); FSDataOutputStream os = null; try { os = fs.create(new Path(file)); os.write(buff, 0, buff.length); System.out.println("Create: " + file); } finally { if (os != null) os.close(); } fs.close(); } public void copyFile(String local, String remote) throws IOException { FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf); fs.copyFromLocalFile(new Path(local), new Path(remote)); System.out.println("copy from: " + local + " to " + remote); fs.close(); } public void download(String remote, String local) throws IOException { Path path = new Path(remote); FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf); fs.copyToLocalFile(path, new Path(local)); System.out.println("download: from" + remote + " to " + local); fs.close(); } public void cat(String remoteFile) throws IOException { Path path = new Path(remoteFile); FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf); FSDataInputStream fsdis = null; System.out.println("cat: " + remoteFile); try { fsdis =fs.open(path); IOUtils.copyBytes(fsdis, System.out, 4096, false); } finally { IOUtils.closeStream(fsdis); fs.close(); } }}这样我们就自己编程实现了MapReduce化基于物品的协同过滤算法。
RHadoop的实现方案,请参考文章:RHadoop实践系列之三 R实现MapReduce的协同过滤算法
Mahout的实现方案,请参考文章:Mahout分步式程序开发 基于物品的协同过滤ItemCF
我已经把整个MapReduce的实现都放到了github上面:
https://github.com/bsspirit/maven_hadoop_template/releases/tag/recommend
转载请注明出处:
http://blog.fens.me/hadoop-mapreduce-recommend/
- 推荐系统 —— 他人文章总结 -1
- 推荐系统-他人的文章
- 一篇他人推荐的职业规划文章
- 文章推荐系统(二)
- 推荐系统文章
- 总结他人文章,记录博客读书笔记之 面试知识点一
- 推荐系统(1)——推荐系统概述
- 推荐系统(1)—推荐系统评测
- 文章推荐系统(三)
- 推荐文章系统(一)
- 相关文章推荐&推荐系统排名
- 城市选择插件研究(个人研究用——转载至他人文章)
- 机器学习——推荐系统 知识点总结
- 推荐系统算法(1)<InfoQ系列翻译文章,2016>
- 推荐系统实践第1章总结
- 推荐系统算法总结
- 推荐系统算法总结
- 推荐系统算法总结
- linux的top命令参数详解
- leetcode No104. Maximum Depth of Binary Tree
- python str的函数isdigit()
- 基于Hadoop集群的HBase集群的配置
- 全国天气查询
- 推荐系统 —— 他人文章总结 -1
- Xcode 常用快捷键
- Makefile,
- 漫谈 Clustering (3): Gaussian Mixture Model
- pwm输出io EINT13
- 安装Logstash
- 号外! 大维度机器学习也有计算框架了
- csu 1759 Triangle(数学)
- 8种常见机器学习算法比较


