第五章、epub文件处理 -- 解压epub文件
来源:互联网 发布:ubuntu安装1080驱动 编辑:程序博客网 时间:2024/05/22 08:26
https://github.com/geometer/FBReaderJ
第五章、epub文件处理 -- 解压epub文件
本章将介绍程序是如何将epub内部被压缩过的xml文件转化为一个可以正常解析的char数组。要想将文件转换成char数组,就需要一个字符流类。而专门针对epub内部被xml文件的字符流类需要一个专门的字节流类ZLXMLParser类。获取这种字节流的工作就是由通过ZLZipEntryFile类的getInputStream方法来完成的。
在详细介绍解压流程之前,我们先简略介绍一下zip文件(epub文件与zip文件使用的是用一种压缩格式)的解压原理。
zip文件内部的文件和文件夹会有一个头信息(Header)。头信息(Header)由特定的标示符描述,文件的标示符是0x04034b50,文件夹的标示符是0x02014b50。
紧跟在头信息之后的是文件或文件夹的元信息。元信息中包括“压缩状态下大小”(Compressed size)、“解压缩状态下大小”(Uncompressed size)、和“文件名”(FileName)等信息。而我们可以通过读取epub文件的字节流得到epub文件内部每个xml文件的元信息。
有了这些元信息之后,当我们需要解析zip文件内部中某一个xml文件时,然后我们可以利用jni调用c语言写的zlib库,将epub文件内部xml文件对应的部分解压成可以正常解析的xml文件字节流。
以上就是大致的解压原理,如果大家还想再进一步了解相关信息,有两个网址可以推荐大家读下。
http://blog.sina.com.cn/s/blog_4c3591bd0100zzm6.html
http://blog.csdn.net/zhoudaxia/article/details/8034606
http://www.cnblogs.com/esingchan/p/3958962.html
本章中涉及的主要方法有:
ZLZipEntryFile类:实现了getInputStream方法
ZipFile类内部InputStreamHolder接口实现类:获得epub文件的字节流
LocalFileHeader类:这个类记录了epub文件内部的xml文件具体从epub文件字节流哪个位置开始,以及在字节流中占据多少字节。
ZipInputStream类:这个覆写了InputStream类的read方法,这个方法将调用DeflatingDecompressor类。
DeflatingDecompressor类:这个类调用语言写的zlib库,将epub文件字节流中的一部分解压还原成正常的xml文件字节流。
下面我们就开始详细介绍代码:
ZLZipEntryFile类的getInputStream方法
getInputStream方法调用了两个方法:
ZLZipEntryFile类的getZipFile方法,参数myParent是一个代表epub文件的ZLPhysicalFile类
ZipFile类的getInputStream方法,参数myName是一个代表epub内部xml文件的文件名(参考第二章“解析资源文件”)

ZLZipEntryFile类的getZipFile方法
这个方法返回了一个ZipFile类,并实现了ZipFile类内的InputStreamHolder接口的getInputStream方法(52行)
因为getZipFile方法中的file参数是一个代表epub文件的ZLPhysicalFile类,所以这个getInputStream方法会返回一个FileInputStream类(参考第二章“解析资源文件”)
这个方法最终会返回了一个ZipFile类(63行)

ZipFile类的getInputStream方法
这个方法调用了同一个类内的getHeader方法

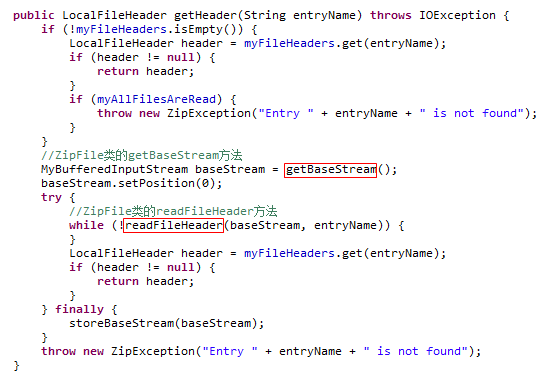
ZipFile类的getHeader方法
这个方法是要获得一个LocalFileHeader类。这个LocalFileHeader类记录了epub文件内部的xml文件具体从epub文件字节流哪个位置开始,压缩状态下占据多少字节以及解压状态下占据多少字节
LocalFileHeader类中的“DataOffset”属性记录了epub内部xml文件代表了从字节流的哪个位置开始,“CompressedSize”属性记录了这个xml文件在压缩状态下在字节流中占据了多少字节,“UncompressedSize”属性则记录了xml文件在解压状态下会占据多少字节

getHeader方法调用了两个方法,ZipFile类的getBaseStream方法与ZipFile类的readFileHeader方法
ZipFile类的getBaseStream方法
这个方法调用了MyBufferedInputStream类的构造函数,构造函数中又调用了ZipFile类内的InputStreamHolder接口实现类的getInputStream方法

InputStreamHolder接口的实现类在ZLZipEntryFile类的getZipFile方法中,我们已经介绍过了,会返回一个FileInputStream类。myFileInputStream属性就会指向这个FileInputStream类。

ZipFile类的readFileHeader方法
这个方法会调用LocalFileHeader类里面的readFrom方法

LocalFileHeader类的readFrom方法
readFrom方法调用了MyBufferedInputStream类的read4Bytes方法

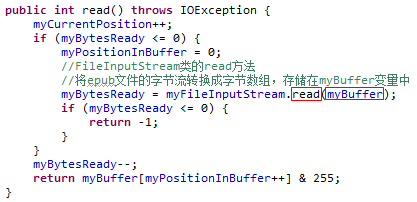
read4Bytes方法调用了四遍MyBufferedInputStream类的read方法

MyBufferedInputStream类的read方法则最终调用了MyBufferedInputStream类中myFileInputStream属性指向的FileInputStream类的read方法(myFileInputStream属性在MyBufferedInputStream类的构造函数中设置,刚才已经介绍过)

返回ZipFile类的readFileHeader方法
代码根据epub文件内部xml文件的名字取出对应的LocalFileHeader类之后,以此为参数调用ZipFile类的createZipInputStream方法。这个方法带又调用了一个ZipInputStream类的构造函数

返回ZipFile类的getHeader方法
LocalFileHeader类里面的readFrom方法创建出来的LocalFileHeader类会被加入到myFileHeaders属性指向的LinkedHashMap中。注意这里LocalFileHeader类是以epub文件内部的xml文件的文件名(header.FileName)为键名加入到LinkedHashMap里去的。

返回ZLZipEntryFile类的getInputStream方法
代码根据epub文件内部xml文件的名字取出对应的LocalFileHeader类之后,以此为参数调用ZipFile类的createZipInputStream方法。这个方法带又调用了一个ZipInputStream类的构造函数


ZipInputStream类的构造函数
MyBufferedInputStream类的setPosition方法通过LocalFileHeader类中的DataOffset属性将epub文件的字节流定位到内部xml文件开始的位置
同时DeflatingDecompressor类的init方法则调用DeflatingDecompressor类的reset方法,将LocalFileHeader类中代表内部xml文件在在压缩状态下在epub字节流中占据了多少字节,在解压状态下会占据多少字节的信息分别赋给了DeflatingDecompressor类内的属性。


现在我们已经获得了ZipInputStream类,这个类其实就是一个针对epub文件内部被压缩的xml文件的字节流类。我们在这一章的开篇曾经讲过:“要想将文件转换成char数组,就需要一个字符流类。而专门针对epub内部xml文件的字符流类需要一个专门的字节流类作为参数。”ZipInputStream就是这个专门的字节流类。现在我们只需要在以特定字节流类为参数,新建一个字符流类就完成任务了。而新建字符流类就是在ZLXMLParser类的构造函数中完成的。(ZLXMLParser类的调用流程请参见第六章)

下面,我们再来介绍下,字符流类将压缩的xml文件转换成char数组的过程。
ZipInputStream类中read方法
我们首先来复习下java中字节流类和字符流类的关系。程序在调用字符流类读取文件的时候,其实底层还是在调用字节流类在读取。字节流现将文件转换成byte数组,字符流获得这个byte数组之后再调用CharsetDecoder这个类,根据字符编码将byte数组再转换成相应的char数组。在字符流将压缩的xml文件转换成char数组的过程中,CharsetDecoder这个类会根据utf-8的编码将字节流转换成字符流。
我们需要关注的是FBReader是如何调用ZipInputStream类将压缩的xml文件转换成byte数组。这个其实就是ZipInputStream类中的read方法完成的事情。
ZipInputStream类的read方法会调用DeflatingDecompressor类的read方法填充作为参数传进来的空byte数组。

DeflatingDecompressor类的read方法中其实就是用myOutBuffer这个变量来填充传进来的空byte数组。

那么这个myOutBuffer这个变量又是在什么地方被填充的呢?就是在DeflatingDecompressor类的另一个无参read方法中。
这个无参read方法是在ZLXMLParser类的构造函数中被调用的,具体请参见第六章“epub文件处理 -- 解析 container文件与.opf文件”中关于读取xml文件的三个核心类调用顺序的介绍。

myOutBuffer属性指向的byte数组是在DeflatingDecompressor类中的fillOutBuffer方法被填充的。
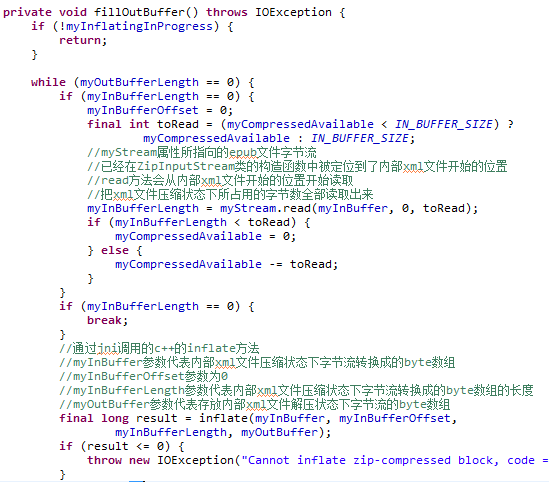
fillOutBuffer方法中的myStream属性所指向的epub文件字节流已经在ZipInputStream类的构造函数中被定位到了内部xml文件开始的位置(请看对ZipInputStream构造函数的介绍)。

在fillOutBuffer方法中,再调用MyBufferedInputStream类的read方法时,就会直接从内部xml文件开始的位置开始读取,把xml文件压缩状态下所占用的字节数全部读取出来。
调用完MyBufferedInputStream类的read方法之后,通过jni调用的c++的inflate方法的所有参数就都被设置好了:myInBuffer参数代表内部xml文件压缩状态下字节流转换成的byte数组,myInBufferOffset参数为0,myInBufferLength参数代表内部xml文件压缩状态下字节流转换成的byte数组的长度,myOutBuffer参数代表存放内部xml文件解压状态下字节流的byte数组。
在c++的inflate方法中,代码调用了zlib库的inflate方法。然后为zlib库里的inflate方法设置了参数。

c++的inflate方法调用完毕,myOutBuffer属性指向的byte数组就填充完毕了。
字节流填充完byte数组之后,字符流会根据字符编码再生成对应的char数组。整个流程就完成了。
- 第五章、epub文件处理 -- 解压epub文件
- 第四章、epub文件处理 -- epub文件内部组成
- 第十章、epub文件处理 -- 样式处理
- 使用Epublib处理epub文件
- 第七章、epub文件处理 -- 解析 .xhtml文件 (一)
- 第九章、epub文件处理 -- 显示.xhtml文件
- epub是什么文件?epub文件怎么打开?
- 第八章、epub文件处理 -- 定位指定段落
- 电子书Epub文件剖析
- 第六章、epub文件处理 -- 解析container文件与.opf文件
- 收藏的epub文件书籍
- ePub
- 电子杂志epub文件开源编程工具
- java中使用Epublib解析EPub文件
- 使用epublib自动生成epub文件
- 使用RijndaelManaged对epub文件进行加密
- 百科知识 epub文件如何打开
- Epub格式的电子书——文件组成
- HNOI 2002 (Splay入门题,无更新操作)
- Android屏幕适配全攻略(最权威的官方适配指导)
- HTTP通信
- 再谈STM32的CAN过滤器-bxCAN的过滤器的4种工作模式以及使用方法总结
- sublime Text 3实用功能和常用快捷键
- 第五章、epub文件处理 -- 解压epub文件
- 909422229__8、基数排序__程序员必须知道的8大排序和3大查找
- HIVE无法正常启动,报找不到jdbc的驱动类
- Xcode_7 iOS_9 索引栏 Objective-C (11)
- PullToRefresh的上拉加载下拉刷新
- ViewPager 实现 Galler 效果, 中间大图显示,两边小图展示
- 909422229__三种查找算法:顺序查找,二分法查找(折半查找),分块查找
- CentOS不能运行dialog的解决办法
- RadioGroip


