好未来面试题
来源:互联网 发布:程序员猝死案例 编辑:程序博客网 时间:2024/04/27 18:13
_stdcall,_cdecl区别
(1) _stdcall调用 _stdcall是Pascal程序的缺省调用方式,参数采用从右到左的压栈方式,被调函数自身在返回前清空堆栈。WIN32 Api都采用_stdcall调用方式,这样的宏定义说明了问题: #define WINAPI _stdcall 按C编译方式,_stdcall调用约定在输出函数名前面加下划线,后面加“@”符号和参数的字节数。 (2) _cdecl调用 _cdecl是C/C++的缺省调用方式,参数采用从右到左的压栈方式,传送参数的内存栈由调用者维护。_cedcl约定的函数只能被C/C++调用,每一个调用它的函数都包含清空堆栈的代码,所以产生的可执行文件大小会比调用_stdcall函数的大。由于_cdecl调用方式的参数内存栈由调用者维护,所以变长参数的函数能(也只能)使用这种调用约定。 首先,我们谈一下两者之间的区别: WINDOWS的函数调用时需要用到栈(STACK,一种先入后出的存储结构)。当函数调用完成后,栈需要清除,这里就是问题的关键,如何清除??如果我们的函数使用了_cdecl,那么栈的清除工作是由调用者,用COM的术语来讲就是客户来完成的。这样带来了一个棘手的问题,不同的编译器产生栈的方式不尽相同,那么调用者能否正常的完成清除工作呢?答案是不能。如果使用__stdcall,上面的问题就解决了,函数自己解决清除工作。所以,在跨(开发)平台的调用中,我们都使用__stdcall(虽然有时WINAPI的样子出现)。那么为什么还需要_cdecl呢?当我们遇到这样的函数如fprintf()它的参数是可变的,不定长的,被调用者事先无法知道参数的长度,事后的清除工作也无法正常的进行,因此,这种情况我们只能使用_cdecl。到这里我们有一个结论,如果你的程序中没有涉及可变参数,最好使用__stdcall关键字。float的内存布局
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit, double数据占用64bit, 无论是单精度还是双精度在存储中都分为三个部分:首先说一下原,反,补,移码. 移码其实就等于补码,只是符号相反. 对于正数而言,原,反,补码都一样, 对负数而言,反码除符号位外,在原码的基础上按位取反,补码则在反码的基础之上,在其最低位上加1,要求移码时,仍然是先求补码,再改符号. 符号位(Sign) : 0代表正,1代表为负指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储 A,阶码是用移码表示的,这里会有一个127的偏移量,它的127相当于0,小于127时为负,大于127时为正,比如:10000001表示指数为129- 127=2,表示真值为2^2,而01111110则表示2^(-1). 有移码表示阶码有是有原因的,主要是移码便于对阶操作,从而比较两个浮点数的大小. 这里要注意的是,阶码不能达到11111111的形式,IEEE规定,当编译器遇到阶码为0XFF时,即调用溢出指令. 总之,阶码化为整数时,范围是:-127~127.float:符号位1,阶码08(固定偏移7F),尾数23,固定隐含位有 double: 符号位1,阶码11(固定偏移3FF),尾数52,固定隐含位有 long double:符号位1,阶码15(固定偏移3FFF),尾数64,固定隐含位无 某些编译器中把long double作double处理 其中float的存储方式如下图所示: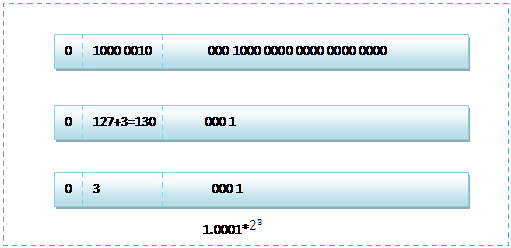什么是偏特化
说到C++模板特化与偏特化,就不得不简要的先说说C++中的模板。我们都知道,强类型的程序设计迫使我们为逻辑结构相同而具体数据类型不同的对象编写模式一致的代码,而无法抽取其中的共性,这样显然不利于程序的扩充和维护。C++模板就应运而生。C++的模板提供了对逻辑结构相同的数据对象通用行为的定义。这些模板运算对象的类型不是实际的数据类型,而是一种参数化的类型。C++中的模板分为类模板和函数模板。类模板如下:#include <iostream>using namespace std;template <class T>class TClass{public: // TClass的成员函数private: T DateMember;};函数模板如下:template <class T>T Max(const T a, const T b){ return a > b ? a : b;}有时为了需要,针对特定的类型,需要对模板进行特化,也就是所谓的特殊处理。比如有以下的一段代码:#include <iostream>using namespace std;template <class T>class TClass{public: bool Equal(const T& arg, const T& arg1);};template <class T>bool TClass<T>::Equal(const T& arg, const T& arg1){ return (arg == arg1);}int main(){ TClass<int> obj; cout<<obj.Equal(2, 2)<<endl; cout<<obj.Equal(2, 4)<<endl;}类里面就包括一个Equal方法,用来比较两个参数是否相等;上面的代码运行没有任何问题;但是,你有没有想过,在实际开发中是万万不能这样写的,对于float类型或者double的参数,绝对不能直接使用“==”符号进行判断。所以,对于float或者double类型,我们需要进行特殊处理,处理如下:#include <iostream>using namespace std;template <class T>class Compare{public: bool IsEqual(const T& arg, const T& arg1);};// 已经不具有template的意思了,已经明确为float了template <>class Compare<float>{public: bool IsEqual(const float& arg, const float& arg1);};// 已经不具有template的意思了,已经明确为double了template <>class Compare<double>{public: bool IsEqual(const double& arg, const double& arg1);};template <class T>bool Compare<T>::IsEqual(const T& arg, const T& arg1){ cout<<"Call Compare<T>::IsEqual"<<endl; return (arg == arg1);}bool Compare<float>::IsEqual(const float& arg, const float& arg1){ cout<<"Call Compare<float>::IsEqual"<<endl; return (abs(arg - arg1) < 10e-3);}bool Compare<double>::IsEqual(const double& arg, const double& arg1){ cout<<"Call Compare<double>::IsEqual"<<endl; return (abs(arg - arg1) < 10e-6);}int main(){ Compare<int> obj; Compare<float> obj1; Compare<double> obj2; cout<<obj.IsEqual(2, 2)<<endl; cout<<obj1.IsEqual(2.003, 2.002)<<endl; cout<<obj2.IsEqual(3.000002, 3.0000021)<<endl;}上面对模板的特化进行了总结。那模板的偏特化呢?所谓的偏特化是指提供另一份template定义式,而其本身仍为templatized;也就是说,针对template参数更进一步的条件限制所设计出来的一个特化版本。这种偏特化的应用在STL中是随处可见的。比如:template <class _Iterator>struct iterator_traits{ typedef typename _Iterator::iterator_category iterator_category; typedef typename _Iterator::value_type value_type; typedef typename _Iterator::difference_type difference_type; typedef typename _Iterator::pointer pointer; typedef typename _Iterator::reference reference;};// specialize for _Tp*template <class _Tp>struct iterator_traits<_Tp*> { typedef random_access_iterator_tag iterator_category; typedef _Tp value_type; typedef ptrdiff_t difference_type; typedef _Tp* pointer; typedef _Tp& reference;};// specialize for const _Tp*template <class _Tp>struct iterator_traits<const _Tp*> { typedef random_access_iterator_tag iterator_category; typedef _Tp value_type; typedef ptrdiff_t difference_type; typedef const _Tp* pointer; typedef const _Tp& reference;};设计一个文件类,使他能自动释放文件句柄
当时采用的引用计数方式来自动释放文件句柄。手写克鲁斯卡尔算法
//快速排序的条件int cmp(const void* a, const void* b) { return (*(Edge*)a).weight - (*(Edge*)b).weight;}//找到根节点int Find(int *parent, int f) { while ( parent[f] > 0) { f = parent[f]; } return f;}// 生成最小生成树void MiniSpanTree_Kruskal(MGraph G) { int i, j, n, m; int k = 0; int parent[MAXVEX]; //用于寻找根节点的数组 Edge edges[MAXEDGE]; //定义边集数组,edge的结构为begin,end,weight,均为整型 // 用来构建边集数组并排序(将邻接矩阵的对角线右边的部分存入边集数组中) for ( i = 0; i < G.numVertexes-1; i++) { for (j = i + 1; j < G.numVertexes; j++) { if (G.arc[i][j] < INFINITY) { edges[k].begin = i; //编号较小的结点为首 edges[k].end = j; //编号较大的结点为尾 edges[k].weight = G.arc[i][j]; k++; } } } //为边集数组Edge排序 qsort(edges, G.numEdges, sizeof(Edge), cmp); for (i = 0; i < G.numVertexes; i++) parent[i] = 0; printf("打印最小生成树:\n"); for (i = 0; i < G.numEdges; i++) { n = Find(parent, edges[i].begin);//寻找边edge[i]的“首节点”所在树的树根 m = Find(parent, edges[i].end);//寻找边edge[i]的“尾节点”所在树的树根 //假如n与m不等,说明两个顶点不在一棵树内,因此这条边的加入不会使已经选择的边集产生回路 if (n != m) { parent[n] = m; printf("(%d, %d) %d\n", edges[i].begin, edges[i].end, edges[i].weight); } }}栈内存和堆内存的区别
http://blog.csdn.net/hairetz/article/details/4141043以下代码有什么问题
#include<string>#include<cstdio>using namespace std;void func(char* str){ memset(str,0,sizeof(str)); printf("%s",str);}int main(){ string msg = "abc"; printf("%s",msg); char buf[1000]; func(buf); return 0;}问题1:printf("%s",msg)的%s接收的是原生的字符串指针。问题2:buf传给func时,sizeof(str)得到的值为4,因为数组作为参数传递时会退化成指针。 0 0
- 好未来面试题
- 【面试集锦】好未来前端面试题---JS实现轮播图
- 【面经笔记】好未来
- 好的面试题
- 好基础的面试题
- 一些好的面试题
- C++好的面试题和不好的面试题
- C++好的面试题和不好的面试题
- 比较好的面试题总结
- 比较好的一份面试题
- 好的数据库面试题集合
- 没回答好的面试题
- 好未来(已拿offer)+ CVTE(3面通过)
- 好未来+CVTE+美团+58+京东 Android面经
- 好未来2017春季php实习生面试题
- 好未来
- 从一些公司面试题分析理解分析未来情况
- 剑指Offer——好未来视频面知识点储备+面后总结
- java MVC架构
- iOS中的block(block编程官方文档翻译)
- React Native之Redux使用详解之Reducers(30)
- Qt用qml实现简单的粒子效果
- 编译cm12.1时 libcryptfs_hw_intermediates 报错解决方法
- 好未来面试题
- EventBus的初步接触
- Qt用qml实现简单的粒子效果
- 微服务架构下,如何实现分布式跟踪?
- u盘恢复
- Windows及Linux平台下Java环境搭建
- Javascript面向对象
- 【用Cocos Creator给暗恋的女生写一个游戏(5)】——(Run Game)场景搭建
- 图解 VS 2015 线程调试窗口解析


