8-Process Control
来源:互联网 发布:微博互粉软件 编辑:程序博客网 时间:2024/06/05 17:36
Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1
8.1 Introduction
8.2 Process Identifiers
- Every process has a unique process ID(a non-negative integer). Although unique, process IDs are reused. As processes terminate, their IDs become candidates for reuse. UNIX implement algorithms to delay reuse so that newly created processes are assigned IDs different from those used by processes that terminated recently. This prevents a new process from being mistaken for the previous process to have used the same ID.
- Process ID 0 is the scheduler process and is known as the swapper. No program on disk corresponds to this process, it is part of the kernel and is known as a system process.
- Process ID 1 is the init process and is invoked by the kernel at the end of the bootstrap procedure. The program file for this process was /etc/init. init reads the system-dependent initialization files and brings the system to a certain state after the kernel has been bootstrapped. The init process is a normal user process running with superuser privileges and it never dies.
#include <sys/types.h>#include <unistd.h>pid_t getpid(void);Returns: process ID of calling processpid_t getppid(void);Returns: parent process ID of calling processuid_t getuid(void);Returns: real user ID of calling processuid_t geteuid(void);Returns: effective user ID of calling processgid_t getgid(void);Returns: real group ID of calling processgid_t getegid(void);Returns: effective group ID of calling process- None of these functions has an error return.
8.3 fork Function
#include <unistd.h>pid_t fork(void);Returns: 0 in child, process ID of child in parent, -1 on error- This function is called once but returns twice.
- The return value in the child is 0.
- The return value in the parent is the process ID of the new child.
- Both the child and the parent continue executing with the instruction that follows the call to fork. The child is a copy of the parent(data space, heap, and stack). The parent and the child share the text segment(Section 7.6).
- Modern implementations don’t perform a complete copy of the parent’s data, stack, and heap because a fork is often followed by an exec. Copy-on-write(COW) is used. These regions are shared by the parent and the child and have their protection changed by the kernel to read-only. If either process tries to modify these regions, the kernel makes a copy of that piece of memory only, typically a page in a virtual memory system.
- For POSIX threads, fork created a process containing only the calling thread.

#include <stdio.h>#include <stdlib.h>#include <sys/types.h>#include <unistd.h>int globvar = 0;char buf[] = "a write to stdout\n";void Exit(char *string){ printf("%s\n", string); exit(1);}int main(){ int var = 100; pid_t pid; if(write(STDOUT_FILENO, buf, sizeof(buf) - 1) != sizeof(buf) - 1) { Exit("write error"); } printf("Before fork\n"); if((pid = fork()) < 0) { Exit("fork error"); } else if(pid == 0) { ++globvar; ++var; } else { sleep(2); } printf("pid = %ld, global_var = %d, var = %d\n", (long)getpid(), globvar, var); exit(0);}- Figure 8.1: Changes to variables in a child process do not affect the value of the variables in the parent process.
$ ./a.out a write to stdoutBefore forkpid = 6444, global_var = 1, var = 101pid = 6443, global_var = 0, var = 100$ ./a.out > out.txt $ cat out.txt a write to stdoutBefore forkpid = 6448, global_var = 1, var = 101Before forkpid = 6447, global_var = 0, var = 100- We never know whether the child starts executing before the parent, or vice versa. The order depends on the scheduling algorithm used by the kernel. We put the parent to sleep for 2 seconds to let the child execute. There is no guarantee that the length of this delay is adequate.
- When we write to standard output, we subtract 1 from the size of buf to avoid writing the terminating null byte.
- Chapter 3: write is not buffered. Because write is called before the fork, its data is written once to standard output.
- The standard I/O library is buffered. Section 5.12: Standard output is line buffered if it’s connected to a terminal device; otherwise, it’s fully buffered.
- When we run the program interactively: we get a single copy of the first printf line, because the standard output buffer is flushed by the newline.
- When we redirect standard output to a file: we get two copies of the printf line. The printf before fork is called once, but the line remains in the buffer when fork is called. This buffer is then copied into the child when the parent’s data space is copied to the child. Both the parent and the child now have a standard I/O buffer with this line in it. The second printf, right before the exit, appends its data to the existing buffer. When each process terminates, its copy of the buffer is finally flushed.
- Change “printf(“Before fork\n”)” to “printf(“Before fork ”)”:
$ ./a.out a write to stdoutBefore fork pid = 6589, global_var = 1, var = 101Before fork pid = 6588, global_var = 0, var = 100$ ./a.out > out.txt $ cat out.txt a write to stdoutBefore fork pid = 6595, global_var = 1, var = 101Before fork pid = 6594, global_var = 0, var = 100File Sharing
- When we redirect the standard output of the parent, the child’s standard output is also redirected. All file descriptors that are open in the parent are duplicated in the child. The parent and the child share a file table entry for every open descriptor(Figure 3.9).

- Consider a process that has three different files opened for standard input, output, and error. On return from fork, we have the arrangement shown in Figure 8.2.
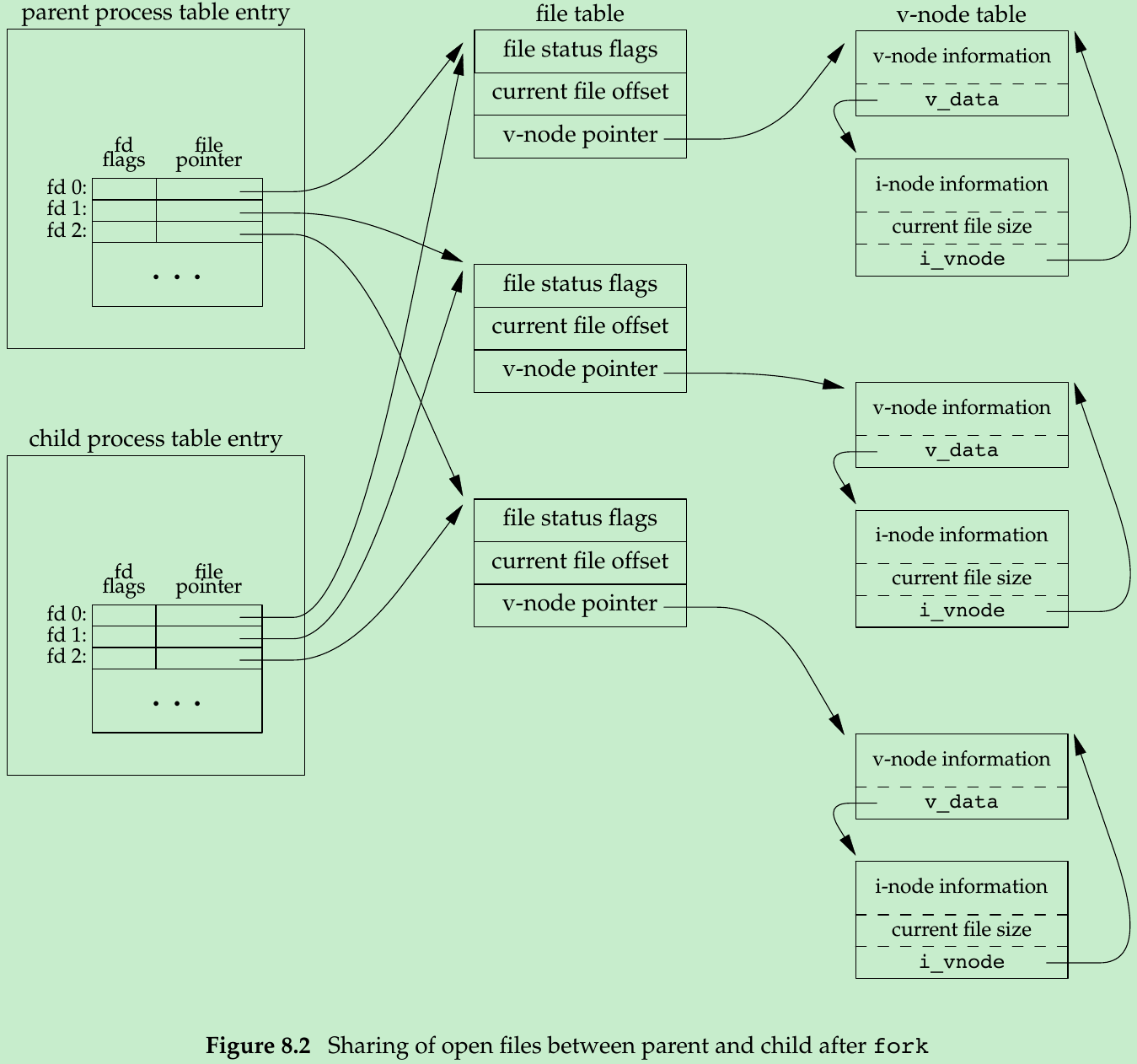
- The parent and the child share the same file offset.
Consider a process that forks a child, then waits for the child to complete. Assume that both processes write to standard output. If the parent has its standard output redirected, it is essential that the parent’s file offset be updated by the child when the child writes to standard output. In this case, the child can write to standard output while the parent is waiting for it; on completion of the child, the parent can continue writing to standard output, knowing that its output will be appended to whatever the child wrote. - If both parent and child write to the same descriptor, without any form of synchronization(such as the parent wait for the child), their output will be intermixed.
- There are two normal cases for handling the descriptors after a fork.
- The parent waits for the child to complete.
The parent does not need to do anything with its descriptors. When the child terminates, any of the shared descriptors that the child read from or wrote to will have their file offsets updated accordingly. - Both the parent and the child go their own ways.
After the fork, the parent closes the descriptors that it doesn’t need, and the child does the same thing.
- The parent waits for the child to complete.
- Besides the open files, other properties of the parent are inherited by the child:
• Real user ID, real group ID, effective user ID, and effective group ID
• Supplementary group IDs
• Process group ID
• Session ID
• Controlling terminal
• The set-user-ID and set-group-ID flags
• Current working directory
• Root directory
• File mode creation mask
• Signal mask and dispositions
• The close-on-exec flag for any open file descriptors
• Environment
• Attached shared memory segments
• Memory mappings
• Resource limits - The differences between the parent and child are
• The return values from fork are different.
• The process IDs are different.
• The two processes have different parent process IDs: the parent process ID of the child is the parent; the parent process ID of the parent doesn’t change.
• The child’s tms_utime, tms_stime, tms_cutime, and tms_cstime values are set to 0 (Section 8.17).
• File locks set by the parent are not inherited by the child.
• Pending alarms are cleared for the child.
• The set of pending signals for the child is set to the empty set. - Two main reasons for fork to fail:
(a) If too many processes are already in the system;
(b) If the total number of processes for this real user ID exceeds the system’s limit. Figure 2.11: CHILD_MAX specifies the maximum number of simultaneous processes per real user ID. - Two uses for fork:
- When a process wants to duplicate itself so that the parent and the child can each execute different sections of code at the same time. This is common for network servers: the parent waits for a service request from a client, when the request arrives, the parent calls fork and lets the child handle the request. The parent goes back to waiting for the next service request to arrive.
- When a process wants to execute a different program. This is common for shells: the child does an exec(Section 8.10) right after it returns from the fork.
8.4 vfork Function
- vfork was intended to create a new process for the purpose of executing a new program.
- vfork creates the new process without copying the address space of the parent into the child. It guarantees the child runs first, until the child calls exec or exit. When the child calls either of these functions, the parent resumes. This can lead to deadlock if the child depends on further actions of the parent before calling either of two functions.
- Since the child runs in the address space of the parent until it calls either exec or exit, it leads to undefined results if the child modifies any data(except the variable used to hold the return value from vfork), makes function calls, or returns without calling exec or exit.

#include <stdio.h>#include <stdlib.h>#include <sys/types.h>#include <unistd.h>int globvar = 0;int main(){ int var = 100; pid_t pid; printf("Before fork\n"); if((pid = vfork()) < 0) { Exit("fork error"); } else if(pid == 0) { ++globvar; ++var; printf("pid = %ld, global_var = %d, var = %d\n", (long)getpid(), globvar, var); _exit(0); } printf("pid = %ld, global_var = %d, var = %d\n", (long)getpid(), globvar, var); exit(0);}- Because the child runs in the address space of the parent, the incrementing of the variables done by the child changes the values in the parent.
- We call _exit instead of exit. Section 7.3: _exit does not perform any flushing of standard I/O buffers. If we call exit, the results are indeterminate. Depending on the implementation of the standard I/O library, we might see no difference in the output, or we might find that the output from the first printf in the parent has disappeared.
- When the child calls exit, the implementation flushes the standard I/O streams.
- If this is the only action taken, we will see no difference from the output generated if the child called _exit.
- If the implementation closes the standard I/O streams, the memory representing the FILE object for the standard output will be cleared out. Because the child is borrowing the parent’s address space, when the parent resumes and calls printf, no output will appear and printf will return -1.
- Note the parent’s STDOUT_FILENO is still valid, as the child gets a copy of the parent’s file descriptor array(Figure 8.2).
- Most implementations of exit do not close the streams. Because the process is about to exit, the kernel will close all the file descriptors open in the process.
8.5 exit Functions
Five normally terminate ways
- Executing a return from the main function.
This is equivalent to calling exit. - Calling exit.
This function includes the calling of all exit handlers that have been registered by calling atexit and closing all standard I/O streams. - Calling _exit or _Exit.
_Exit and _exit are synonymous. They terminate process without running exit handlers or signal handlers, and not flush standard I/O streams.
_exit is called by exit and handles system-specific details. exit(3) is a function in the standard C library, _exit(2) is a system call. - Executing a return from the start routine of the last thread in the process.
When the last thread returns from its start routine, the process exits with a termination status of 0 regardless of the return value of the thread. - Calling pthread_exit from the last thread in the process.
The exit status of the process is always 0 regardless of the argument passed to pthread_exit.
3 abnormal termination ways
- Calling abort.
It generates the SIGABRT signal. - When the process receives certain signals.
The signal can be generated by the process itself(e.g., call abort function), by some other process, or by the kernel(E.g.: the process reference a memory location not within its address space; try to divide by 0). - The last thread responds to a cancellation request.
By default, cancellation occurs in a deferred manner: one thread requests that another be canceled, and sometime later the target thread terminates.- Regardless of how a process terminates, the same code in the kernel is eventually executed that closes all the open descriptors for the process, releases the memory that it was using, and so on.
- We want the terminating process to be able to notify its parent how it terminated.
- For the three exit functions: pass an exit status as the argument to the function.
- For abnormal termination: kernel generates a termination status to indicate the reason for the abnormal termination.
In any case, the parent of the process can obtain the termination status from wait/waitpid function.
- Differentiate between the exit status(the argument to one of the three exit functions), the return value from main, and the termination status.
The exit status is converted into a termination status by the kernel when _exit is finally called(Figure 7.2). Figure 8.4 describes the various ways the parent can examine the termination status of a child. If the child terminated normally, the parent can obtain the exit status of the child. - When parent terminates before its child:
the kernel goes through all active processes to see whether the terminating process is the parent of any process that still exists. If so, the parent process ID of the surviving process is changed to be 1(the process ID of init). In this case, we say that the process has been inherited by init. - When child terminates before its parent:
the kernel keeps information(process ID, termination status and so on) for every terminating process, so that the information is available when the parent of the terminating process calls wait or waitpid. - A process that has terminated, but whose parent has not waited for it, is called a zombie. The ps(1) command prints the state of a zombie process as Z.
- Does a process that has been inherited by init become a zombie when terminates?
No. Whenever one of its children terminates, init calls one of the wait functions to fetch the termination status to prevent the system from being clogged by zombies.
8.6 wait and waitpid Functions
- When a process terminates, the kernel notifies the parent by sending the SIGCHLD signal to the parent. The parent can choose to ignore this signal, or provide a signal handler. The default action for this signal is to be ignored.
- A process that calls wait or waitpid can
- Block: if all of its children are still running.
- Return immediately with the termination status of a child: if a child has terminated and is waiting for its termination status to be fetched.
- Return immediately with an error: if it doesn’t have any child processes.
#include <sys/wait.h>#include <sys/types.h>pid_t wait(int *statloc);pid_t waitpid(pid_t pid, int *statloc, int options);Both return: process ID if OK, 0 (see later), or -1 on error- If a child has terminated and is a zombie, wait returns immediately with that child’s status. Otherwise, it blocks the caller until any one child terminates.
- statloc: If it is not a null pointer, the termination status of the terminated process is stored in the location pointed to by the argument. If we don’t care about the termination status, we pass a null pointer as this argument.
- The integer status that these functions return has been defined with certain bits indicating the exit status(for a normal return), other bits indicating the signal number (for abnormal return), one bit indicating whether a core file was generated, and so on.
- POSIX.1 specifies that the termination status is to be looked at using various macros that are defined in
#include <stdio.h>#include <stdlib.h>#include <sys/types.h>#include <sys/wait.h>#include <unistd.h>void Exit(char *string){ printf("%s\n", string); exit(1);}void pr_exit(int status){ if(WIFEXITED(status)) { printf("normal termination, exit status = %d\n", WEXITSTATUS(status)); } else if(WIFSIGNALED(status)) { printf("abnormal termination, signal number = %d%s\n", WTERMSIG(status),#ifdef WCOREDUMP WCOREDUMP(status) ? " (core file generated)" : "");#else "");#endif } else if(WIFSTOPPED(status)) { printf("child stopped, signal number = %d\n", WSTOPSIG(status)); }}int main(){ pid_t pid; int status; if((pid = fork()) < 0) { Exit("fork error"); } else if(pid == 0) { exit(7); } if(wait(&status) != pid) { Exit("wait error"); } pr_exit(status); if((pid = fork()) < 0) { Exit("fork error"); } else if(pid == 0) { abort(); } if(wait(&status) != pid) { Exit("wait error"); } pr_exit(status); if((pid = fork()) < 0) { Exit("fork error"); } else if(pid == 0) { status /= 0; } if(wait(&status) != pid) { Exit("wait error"); } pr_exit(status); exit(0);}/*normal termination, exit status = 7abnormal termination, signal number = 6abnormal termination, signal number = 8*/- waitpid when pid:
- = -1: Wait for any child process. Equivalent to wait.
- > 0: Wait for the child whose process ID equals pid.
- = 0: Wait for any child whose process group ID equals that of the calling process(Section 9.4).
- < -1: Wait for any child whose process group ID equals the absolute value of pid.
- waitpid returns the process ID of the child that terminated and stores the child’s termination status in the memory location pointed to by statloc.
- With wait, error occurs
- If the calling process has no children.
- The function call is interrupted by a signal.
- With waitpid, error occurs:
- if the specified process or process group does not exist.
- if pid is not a child of the calling process.
- options is 0 or is constructed from the bitwise OR of the constants in Figure 8.7.

- waitpid provides three features that aren’t provided by wait.
- waitpid lets us wait for one particular process, whereas wait returns the status of any terminated child.
- waitpid provides a nonblocking version of wait.
- waitpid provides support for job control with WUNTRACED and WCONTINUED options.
- If we want to write a process so that it forks a child but we don’t want to wait for the child to complete and we don’t want the child to become a zombie until we terminate, the trick is to call fork twice.

- We call sleep in the second child to ensure that the first child terminates before printing the parent process ID. After a fork, either the parent or the child can continue executing; we never know which will resume execution first. If we didn’t put the second child to sleep, and if it resumed execution after the fork before its parent, the parent process ID that it printed would be that of its parent, not process ID 1.
./a.out second child, parent pid = 1 - shell prints its prompt when the original process terminates, which is before the second child prints its parent process ID.
8.7 waitid Function
#include <sys/types.h>#include <sys/wait.h>int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options);Returns: 0 if OK, -1 on error- id is interpreted based on the value of idtype, summarized in Figure 8.9.

- options is a bitwise OR of the flags in Figure 8.10. These flags indicate which state changes the caller is interested in. At least one of WCONTINUED, WEXITED, or WSTOPPED must be specified.

- infop is a pointer to a siginfo structure that contains detailed information about the signal generated that caused the state change in the child process(Section 10.14).
8.8 wait3 and wait4 Functions
- The only feature provided by these two functions that isn’t provided by wait, waitid, and waitpid is an additional argument that allows the kernel to return a summary of the resources used by the terminated process and all its child processes.
#include <sys/types.h>#include <sys/wait.h>#include <sys/time.h>#include <sys/resource.h>pid_t wait3(int *statloc, int options, struct rusage *rusage);pid_t wait4(pid_t pid, int *statloc, int options, struct rusage *rusage);Both return: process ID if OK, 0, or -1 on error- The resource information includes: the amount of user CPU time, amount of system CPU time, number of page faults, number of signals received, and the like. Figure 8.11 details the various arguments supported by the wait functions.

8.9 Race Conditions
- Race condition occurs when multiple processes are trying to do something with shared data and the final outcome depends on the order in which the processes run.
- A process that wants to wait for a child to terminate must call one of the wait functions. If a process wants to wait for its parent to terminate, it can use polling but polling wastes CPU time.
while (getppid() != 1) sleep(1);- To avoid race conditions and polling, we can use signals and interprocess communication.
- For parent and child relationship: After the fork, both the parent and the child have something to do. For example, the parent could update a record in a log file with the child’s process ID, and the child might create a file for the parent. We require that each process tell the other when it has finished its initial set of operations, and that each wait for the other to complete, before heading off on its own. The following code illustrates this scenario:
TELL_WAIT(); /* set things up for TELL_xxx & WAIT_xxx */if((pid = fork()) < 0){ err_sys("fork error");}else if (pid == 0) /* child */{ /* child does whatever is necessary ... */ TELL_PARENT(getppid()); /* tell parent we’re done */ WAIT_PARENT(); /* and wait for parent */ /* and the child continues on its way ... */ exit(0);}/* parent does whatever is necessary ... */TELL_CHILD(pid); /* tell child we’re done */WAIT_CHILD(); /* and wait for child *//* and the parent continues on its way ... */exit(0);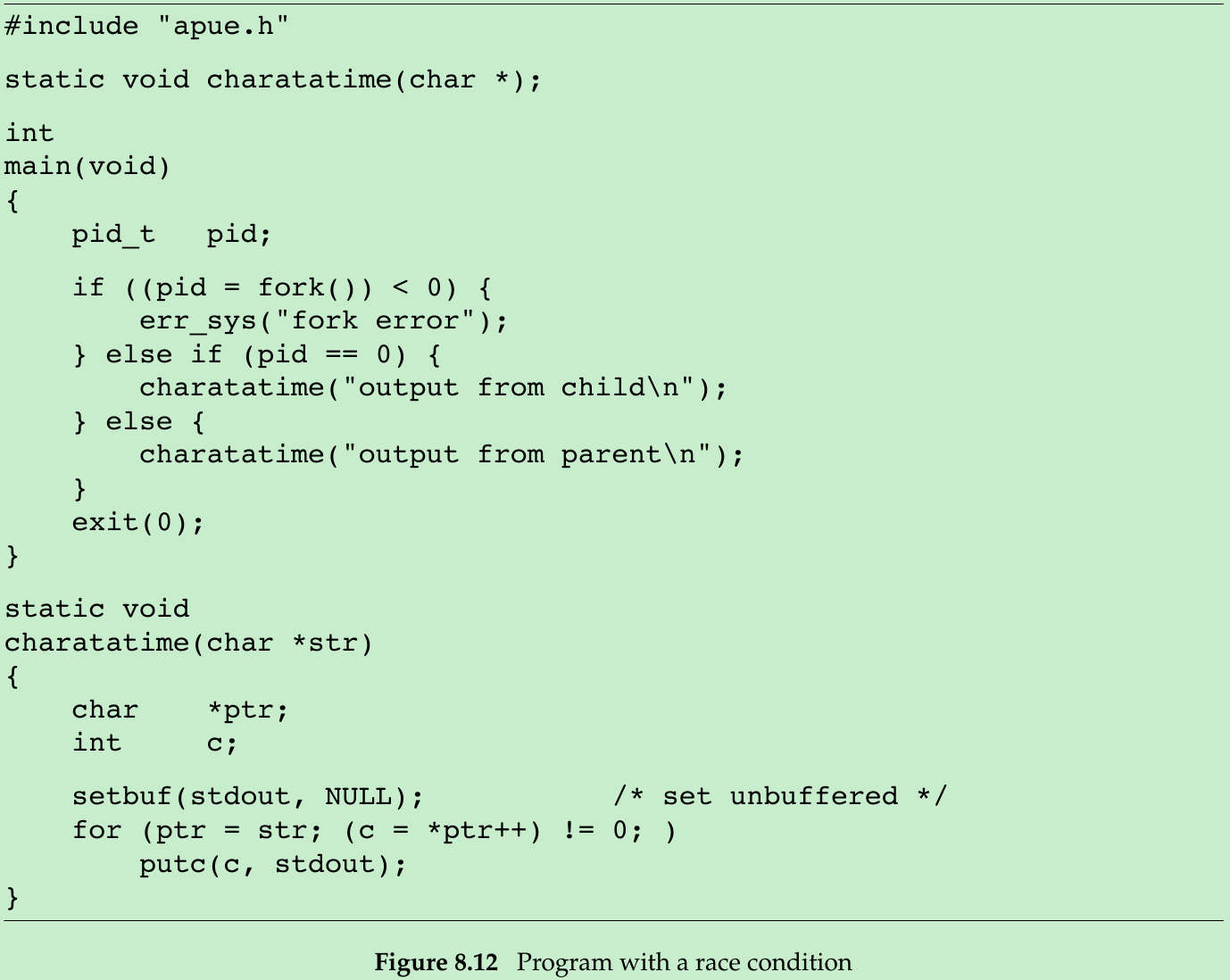
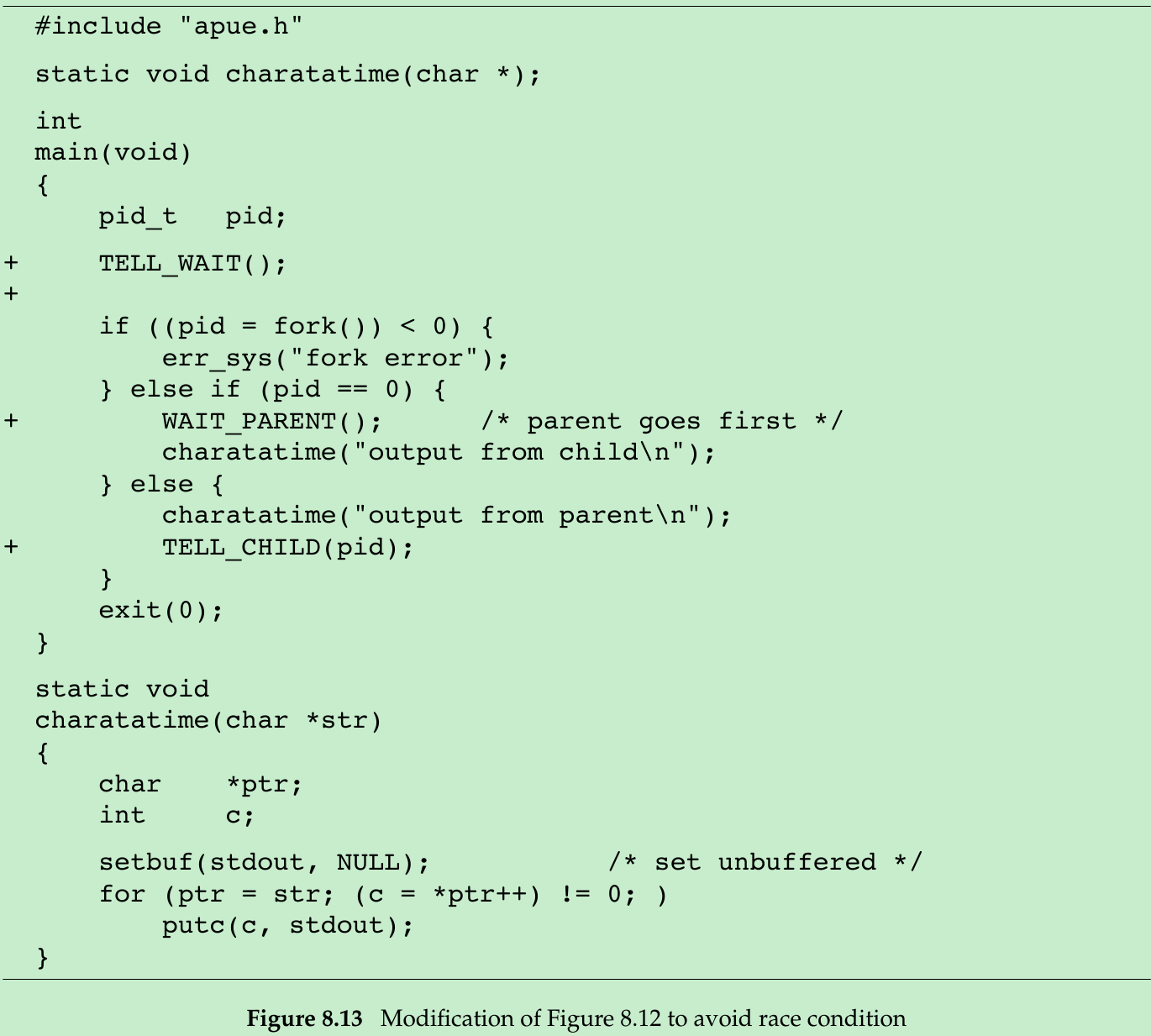
#include <stdio.h>#include <stdlib.h>#include <sys/types.h>#include <unistd.h>void Exit(char *string){ printf("%s\n", string); exit(1);}static void Print(char *str){ int c; setbuf(stdout, NULL); for(char *ptr = str; (c = *ptr++) != 0; ) { putc(c, stdout); }}int main(){ pid_t pid; if((pid = fork()) < 0) { Exit("fork error"); } else if(pid == 0) { Print("OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO\n"); } else { Print("XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX\n"); } exit(0);}/*Output:XXXXXXXXXXXXXXXXOXXOXOXOXOXOXOXOXOXOXOXOXOXOXOXOXOXOXOXOXOXOXOXOXOXOXOOOOOOOOOOOOOOOOO*/- The program in Figure 8.12 outputs two strings: one from the child and one from the parent. This program contains a race condition because the output depends on the order in which the processes are run by the kernel and the length of time for which each process runs. We set the standard output unbuffered, so every character output generates a write.
- The program in Figure 8.13 use the TELL and WAIT functions.
8.10 exec Functions
- When a process calls one of the exec functions, it is completely replaced by the new program, and the new program starts executing at its main function.
- The process ID does not change across an exec because a new process is not created; exec merely replaces the current process(its text, data, heap, and stack segments) with a new program from disk.
- fork create new processes; exec initiate new programs. exit and wait handle termination and waiting for termination.
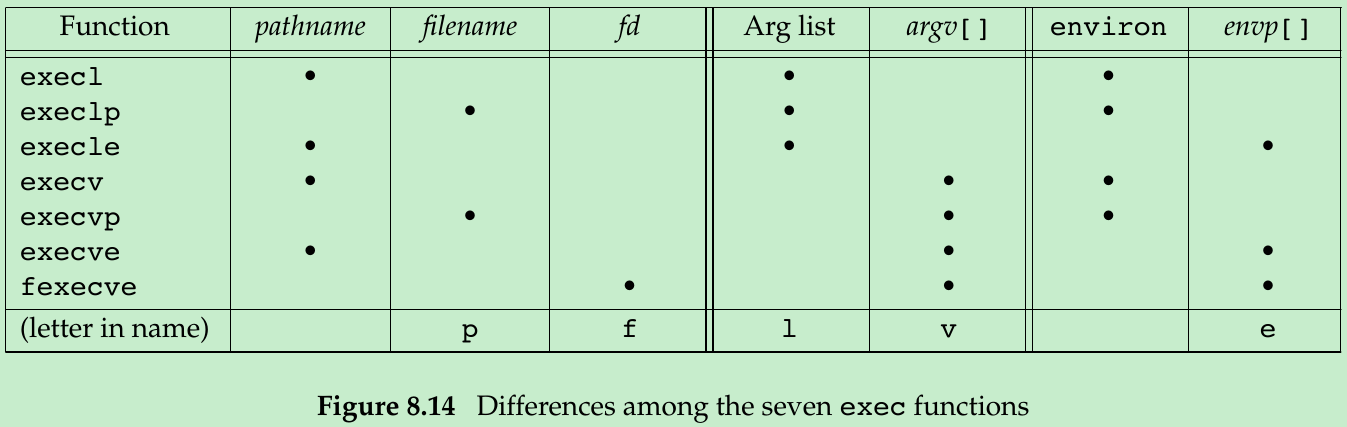
#include <unistd.h>int execl(const char *pathname, const char *arg0, ... /* (char *)0 */ );int execv(const char *pathname, char *const argv[]);int execle(const char *pathname, const char *arg0, ... /* (char *)0, char *const envp[] */ );int execve(const char *pathname, char *const argv[], char *const envp[]);int execlp(const char *filename, const char *arg0, ... /* (char *)0 */ );int execvp(const char *filename, char *const argv[]);int fexecve(int fd, char *const argv[], char *const envp[]);All seven return: -1 on error, no return on success- When a filename argument is specified:
- If filename contains a slash, it is taken as a pathname.
- Otherwise, the executable file is searched for in the directories specified by the PATH environment variable.
- The PATH variable contains a list of directories(called path prefixes) that are separated by colons. For example, the name=value environment string PATH=/bin:/usr/bin:/usr/local/bin/:.
specifies four directories to search. The last path prefix specifies the current directory. A zero-length prefix also means the current directory, it can be specified as a colon at the beginning of the value, two colons in a row, or a colon at the end of the value. - If either execlp or execvp finds an executable file using one of the path prefixes, but the file isn’t a machine executable that was generated by the link editor, the function assumes that the file is a shell script and tries to invoke /bin/sh with the filename as input to the shell.
- fexecve use a file descriptor, the caller can verify the file is in fact the intended file and execute it without a race.
- The next difference concerns the passing of the argument list(l: list; v: vector).
- execl, execlp, and execle require each of the command-line arguments to the new program to be specified as separate arguments. We mark the end of the arguments with a null pointer.
- For execv, execvp, execve, and fexecve: we have to build an array of pointers to the arguments, and the address of this array is the argument to these functions.
- The final difference is the passing of the environment list to the new program.
- The three functions whose names end in an e(execle, execve, and fexecve) allow us to pass a pointer to an array of pointers to the environment strings. The other four functions, use the environ variable in the calling process to copy the existing environment for the new program.(We could change the current environment and the environment of any subsequent child processes, but we couldn’t affect the environment of the parent process.)
- p: take a filename argument and use PATH environment variable to find the executable file.
l: take a list of arguments and is mutually exclusive with the letter v.
v: take an argv[] vector.
e: take an envp[] array.
- New program inherits properties from the calling process:
Process ID and parent process ID
Real user ID and real group ID
Supplementary group IDs
Process group ID
Session ID
Controlling terminal
Time left until alarm clock
Current working directory
Root directory
File mode creation mask
File locks
Process signal mask
Pending signals
Resource limits
Nice value (on XSI-conformant systems; see Section 8.16)
Values for tms_utime, tms_stime, tms_cutime, and tms_cstime - The handling of open files depends on the value of the close-on-exec flag for each descriptor. Figure 3.7 and the FD_CLOEXEC flag in Section 3.14: every open descriptor in a process has a close-on-exec flag. If this flag is set, the descriptor is closed across an exec. Otherwise, the descriptor is left open across the exec. The default is to leave the descriptor open unless we set the close-on-exec flag using fcntl.
- POSIX.1 requires that open directory streams(opendir function from Section 4.22) be closed across an exec. This is normally done by the opendir function calling fcntl to set the close-on-exec flag for the descriptor corresponding to the open directory stream.
- The real user ID and the real group ID remain the same across the exec, but the effective IDs can change, depending on the status of the set-user-ID and the set-group-ID bits for the program file that is executed. If the set-user-ID bit is set for the new program, the effective user ID becomes the owner ID of the program file. Otherwise, the effective user ID is not changed(it’s not set to the real user ID). The group ID is handled in the same way.
- Only execve is a system call within the kernel, other six are library functions that eventually invoke this system call.
execl (const char *pathname, const char *arg0, ... /* (char *)0 */ );execv (const char *pathname, char *const argv[]);execle (const char *pathname, const char *arg0, ... /* (char *)0, char *const envp[] */ );execve (const char *pathname, char *const argv[], char *const envp[]);execlp (const char *filename, const char *arg0, ... /* (char *)0 */ );execvp (const char *filename, char *const argv[]);fexecve (int fd, char *const argv[], char *const envp[]);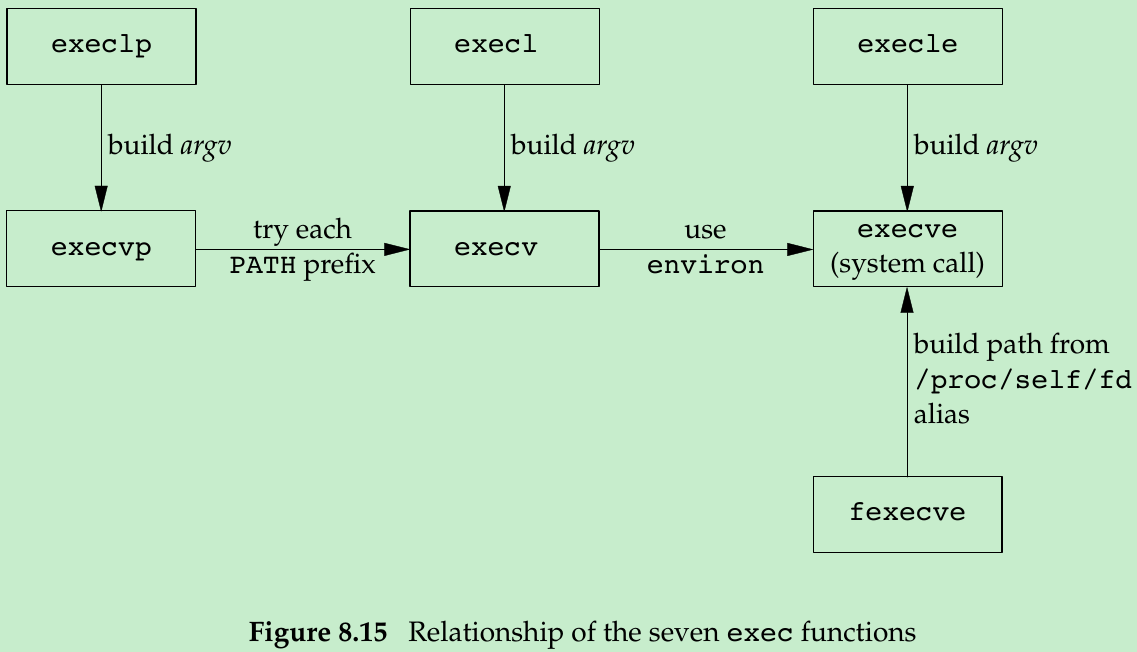

- The only reason the call to execlp works is that the directory /home/sar/bin is one of the current path prefixes. Note that we set the first argument, argv[0] in the new program, to be the filename component of the pathname. Some shells set this argument to be the complete pathname. This is a convention only; we can set argv[0] to any string we like.
- The program echoall that is executed twice in the program in Figure 8.16 is shown in Figure 8.17.

#include <stdio.h>#include <stdlib.h>#include <unistd.h>#include <sys/types.h>#include <sys/wait.h>char *env_init[] = { "USER=unknown", "PATH=/tmp", NULL };void Exit(char *string){ printf("%s\n", string); exit(1);}int main(){ pid_t pid; if((pid = fork()) < 0) { Exit("fork error"); } else if(pid == 0) { if(execle("/home/xiang/Gao/Notes/OS/APUE/Codes/echoall", "echoall", "myarg1", "MY ARG2", (char *)0, env_init) < 0) { Exit("execle error"); } } if(waitpid(pid, NULL, 0) < 0) { Exit("waitpid error"); } if((pid = fork()) < 0) { Exit("fork error"); } else if(pid == 0) { if(execlp("echoall", "echoall", "only 1 arg", (char *)0) < 0) { Exit("execlp error"); } } exit(0);}#include <stdio.h>#include <stdlib.h>int main(int argc, char *argv[]){ for(int index = 0; index < argc /* argv[index] != NULL */; ++index) { printf("argv[%d]: %s\n", index, argv[index]); } extern char **environ; int cnt = 0; for(char **ptr = environ; *ptr != 0 && cnt < 5; ++ptr, ++cnt) { printf("%s\n", *ptr); } exit(0);}- When we execute the program from Figure 8.16, we get
$ ./a.outargv[0]: echoallargv[1]: myarg1argv[2]: MY ARG2USER=unknownPATH=/tmp$ argv[0]: echoallargv[1]: only 1 argUSER=sarLOGNAME=sarSHELL=/bin/bashHOME=/home/sar#47 more lines that aren’t shown- The shell prompt appeared before the printing of argv[0] from the second exec because the parent did not wait for this child process to finish.
8.11 Changing User IDs and Group IDs(Not read)
- In UNIX, privileges and access control are based on user and group IDs. When programs need additional privileges or need to gain access to resources that they currently aren’t allowed to access, they need to change their user or group ID to an ID that has the appropriate privilege or access.
#include <sys/types.h>#include <unistd.h>int setuid(uid_t uid);int setgid(gid_t gid);Both return: 0 if OK, -1 on error- setuid: set the real user ID and effective user ID.
setgid: set the real group ID and the effective group ID. - Consider only the user ID for now.(Everything describe for user ID also applies to group ID.)
- If the process has superuser privileges, the setuid function sets the real user ID, effective user ID, and saved set-user-ID to uid.
- If the process does not have superuser privileges, but uid equals either the real user ID or the saved set-user-ID, setuid sets only the effective user ID to uid. The real user ID and the saved set-user-ID are not changed.
- If neither of these two conditions is true, errno is set to EPERM and -1 is returned.
- Statements about the three user IDs that the kernel maintains.
- Only a superuser process can change the real user ID. Normally, the real user ID is set by the login(1) program when we log in and never changes. Because login is a superuser process, it sets all three user IDs when it calls setuid.
- The effective user ID is set by the exec functions only if the set-user-ID bit is set for the program file. If the set-user-ID bit is not set, the exec functions leave the effective user ID as its current value. We can call setuid at any time to set the effective user ID to either the real user ID or the saved set-user-ID. We can’t set the effective user ID to any random value.
- The saved set-user-ID is copied from the effective user ID by exec. If the file’s set-user-ID bit is set, this copy is saved after exec stores the effective user ID from the file’s user ID.
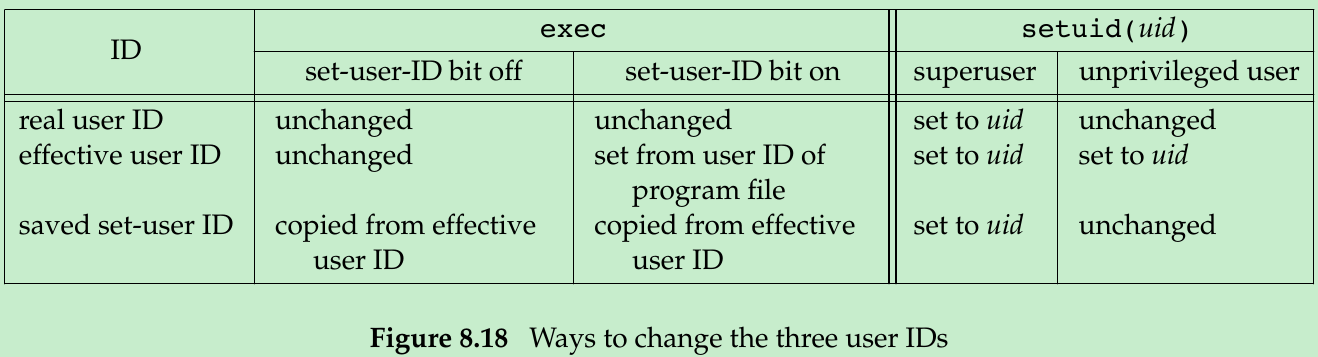
- Figure 8.18 summarizes the various ways these three user IDs can be changed. We can obtain only the current value of the real user ID and the effective user ID with the functions getuid and geteuid from Section 8.2. We have no portable way to obtain the current value of the saved set-user-ID.
- LINUX provide the getresuid and getresgid functions, which can be used to get the saved set-user-ID and saved set-group-ID, respectively.
setreuid and setregid Functions
- setreuid: swap the real user ID and the effective user ID.
#include <sys/types.h>#include <unistd.h>int setreuid(uid_t ruid, uid_t euid);int setregid(gid_t rgid, gid_t egid);Both return: 0 if OK, -1 on error- We can supply a value of -1 for any of the arguments to indicate that the corresponding ID should remain unchanged.
- An unprivileged user can always swap between the real user ID and the effective user ID. This allows a set-user-ID program to swap to the user’s normal permissions and swap back again later for set-user-ID operations. When the saved set-user-ID feature was introduced with POSIX.1, the rule was enhanced to also allow an unprivileged user to set its effective user ID to its saved set-user-ID.
- Both setreuid and setregid are included in the XSI option in POSIX.1. As such, all UNIX System implementations are expected to provide support for them.
- 4.3BSD didn’t have the saved set-user-ID feature described earlier; it used setreuid and setregid instead. This allowed an unprivileged user to swap back and forth between the two values. Be aware, however, that when programs that used this feature spawned a shell, they had to set the real user ID to the normal user ID before the exec. If they didn’t do this, the real user ID could be privileged (from the swap done by setreuid) and the shell process could call setreuid to swap the two and assume the permissions of the more privileged user.
- As a defensive programming measure to solve this problem, programs set both the real user ID and the effective user ID to the normal user ID before the call to exec in the child.
- seteuid and setegid Functions POSIX.1 includes the two functions seteuid and setegid. These functions are similar to setuid and setgid, but only the effective user ID or effective group ID is changed.
#include <unistd.h>int seteuid(uid_t uid);int setegid(gid_t gid);Both return: 0 if OK, -1 on error- An unprivileged user can set its effective user ID to either its real user ID or its saved set-user-ID. For a privileged user, only the effective user ID is set to uid. (This behavior differs from that of the setuid function, which changes all three user IDs.)
- Figure 8.19 summarizes all the functions that we’ve described here that modify the three user IDs.
Group IDs
- Everything that we’ve said so far in this section also applies in a similar fashion to group IDs. The supplementary group IDs are not affected by setgid, setregid, or setegid.
- To see the utility of the saved set-user-ID feature, let’s examine the operation of a program that uses it. We’ll look at the at(1) program, which we can use to schedule commands to be run at some time in the future.
- On Linux 3.2.0, the at program is installed set-user-ID to user daemon. On FreeBSD 8.0, Mac OS X 10.6.8, and Solaris 10, the at program is installed set-user-ID to user root. This allows the at command to write privileged files owned by the daemon that will run the commands on behalf of the user running the at command. On Linux 3.2.0, the programs are run by the atd(8) daemon. On FreeBSD 8.0 and Solaris 10, the programs are run by the cron(1M) daemon. On Mac OS X 10.6.8, the programs are run by the launchd(8) daemon.
- To prevent being tricked into running commands that we aren’t allowed to run, or reading or writing files that we aren’t allowed to access, the at command and the daemon that ultimately runs the commands on our behalf have to switch between sets of privileges: ours and those of the daemon. The following steps take place.
- Assuming that the at program file is owned by root and has its set-user-ID bit set, when we run it, we have
real user ID = our user ID (unchanged)
effective user ID = root
saved set-user-ID = root - The first thing the at command does is reduce its privileges so that it runs with our privileges. It calls the seteuid function to set the effective user ID to our real user ID. After this, we have
real user ID = our user ID (unchanged)
effective user ID = our user ID
saved set-user-ID = root (unchanged) - The at program runs with our privileges until it needs to access the configuration files that control which commands are to be run and the time at which they need to run. These files are owned by the daemon that will run the commands for us. The at command calls seteuid to set the effective user ID to root. This call is allowed because the argument to seteuid equals the saved set-user-ID. (This is why we need the saved set-user-ID.) After this, we have
real user ID = our user ID (unchanged)
effective user ID = root
saved set-user-ID = root (unchanged)
Because the effective user ID is root, file access is allowed. - After the files are modified to record the commands to be run and the time at which they are to be run, the at command lowers its privileges by calling seteuid to set its effective user ID to our user ID. This prevents any accidental misuse of privilege. At this point, we have
real user ID = our user ID (unchanged)
effective user ID = our user ID
saved set-user-ID = root (unchanged) - The daemon starts out running with root privileges. To run commands on our behalf, the daemon calls fork and the child calls setuid to change its user ID to our user ID. Because the child is running with root privileges, this changes all of the IDs. We have
real user ID = our user ID
effective user ID = our user ID
saved set-user-ID = our user ID
- Assuming that the at program file is owned by root and has its set-user-ID bit set, when we run it, we have
- Now the daemon can safely execute commands on our behalf, because it can access only the files to which we normally have access. We have no additional permissions.
- By using the saved set-user-ID in this fashion, we can use the extra privileges granted to us by the set-user-ID of the program file only when we need elevated privileges. Any other time, however, the process runs with our normal permissions. If we weren’t able to switch back to the saved set-user-ID at the end, we might be tempted to retain the extra permissions the whole time we were running (which is asking for trouble).
8.12 Interpreter Files
- Interpreter files are text files that begin with a line of the form
#! pathname [ optional-argument ] - The space between the exclamation point and the pathname is optional. The most common of these interpreter files begin with the line
#!/bin/sh - The pathname is normally an absolute pathname. The recognition of these files is done within the kernel as part of processing the exec system call. The actual file that executed by kernel is not the interpreter file, but rather the file specified by the pathname on the first line of the interpreter file. Differentiate between interpreter file(a text file that begins with #!) and interpreter(specified by the pathname on the first line of the interpreter file).
- Linux place a size limit(128 bytes) on the first line of an interpreter file which includes the #!, the pathname, the optional argument, the terminating newline, and any spaces.
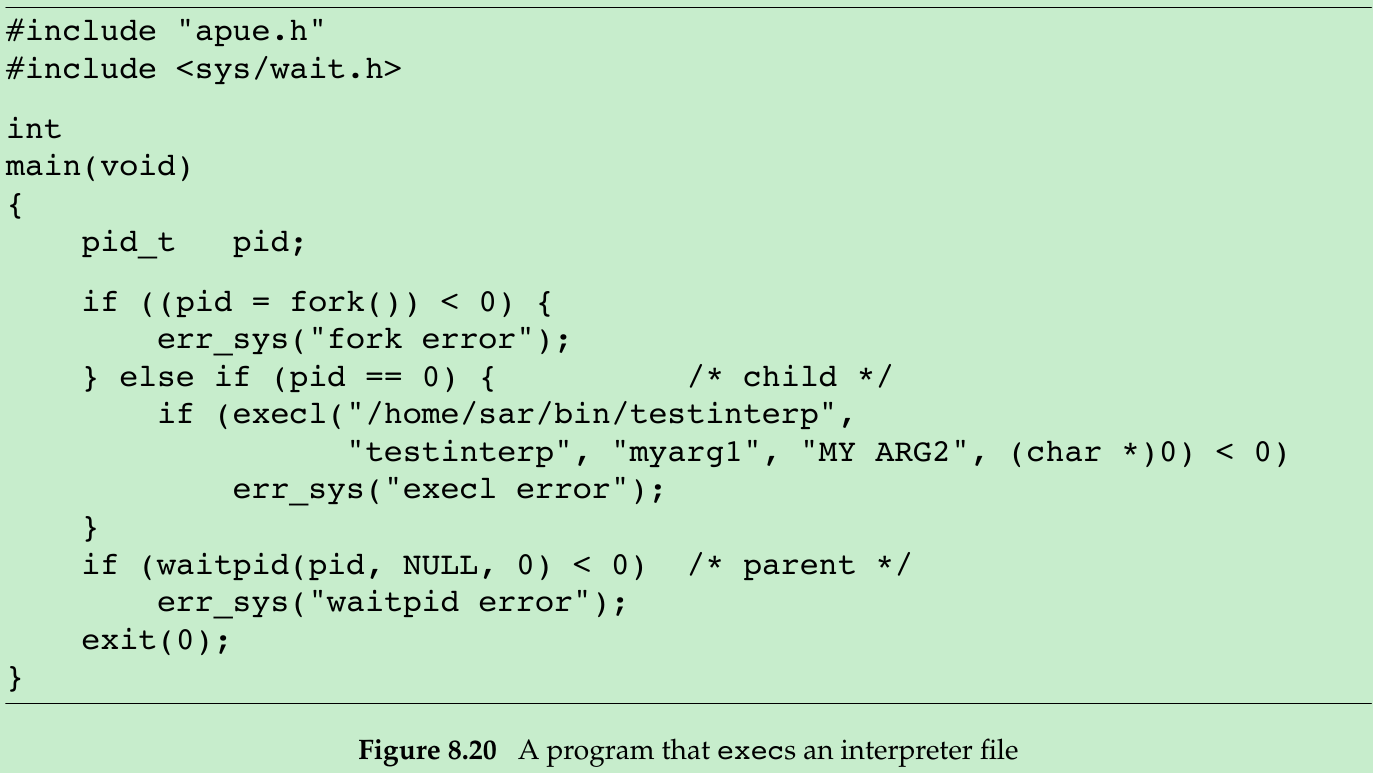
#include <stdio.h>#include <stdlib.h>#include <sys/types.h>#include <sys/wait.h>#include <unistd.h>void Exit(char *string){ printf("%s\n", string); exit(1);}int main(){ pid_t pid; if((pid = fork()) < 0) { Exit("fork error"); } else if(pid == 0) { if(execl("/home/xiang/Gao/Notes/OS/APUE/Codes/testinterp", "testinterp", "myarg1", "MY ARG2", (char *)0) < 0) { Exit("execl error"); } } if(waitpid(pid, NULL, 0) < 0) { Exit("waitpid error"); } exit(0);}$ cat testinterp#! /home/xiang/Gao/Notes/OS/APUE/Codes/echoarg foo$ gcc 8-20.c $ ./a.out execl error$ ls -l testinterp-rw-rw-r-- 1 xiang xiang 51 8月14 22:39 testinterp$ chmod 774 testinterp$ gcc 8-20.c $ ./a.out argv[0]: /home/xiang/Gao/Notes/OS/APUE/Codes/echoargargv[1]: fooargv[2]: /home/xiang/Gao/Notes/OS/APUE/Codes/testinterpargv[3]: myarg1argv[4]: MY ARG2- The program echoarg(the interpreter) echoes each of its command-line arguments. (7-4.c) When the kernel execs the interpreter(/home/sar/bin/echoarg), argv[0] is the pathname of the interpreter, argv[1] is the optional argument from the interpreter file, and the remaining arguments are the pathname(/home/sar/bin/testinterp) and the second and third arguments from the call to execl in the program shown in Figure 8.20(myarg1 and MY ARG2). Both argv[1] and argv[2] from the call to execl have been shifted right two positions.
- Common use for the optional argument following the interpreter pathname is to specify the -f option for programs that support this option. For example, an awk(1) program can be executed as
awk -f myfile
which tells awk to read the awk program from the file myfile. - Using the -f option with an interpreter file lets us write
#!/bin/awk -f(awk program follows in the interpreter file)

- Figure 8.21 shows /usr/local/bin/awkexample(an interpreter file). If one of the path prefixes is /usr/local/bin, we can execute the program in Figure 8.21(assuming that we’ve turned on the execute bit for the file) as
$ awkexample file1 FILENAME2 f3ARGV[0] = awkARGV[1] = file1ARGV[2] = FILENAME2ARGV[3] = f3When /bin/awk is executed, its command-line arguments are
/bin/awk -f /usr/local/bin/awkexample file1 FILENAME2 f3- The pathname of the interpreter file(/usr/local/bin/awkexample) is passed to the interpreter. The filename portion of this pathname(what we typed to the shell) isn’t adequate, because the interpreter(/bin/awk in this example) can’t be expected to use the PATH variable to locate files. When it reads the interpreter file, awk ignores the first line, since the pound sign is awk’s comment character.
- We can verify these command-line arguments with the following commands:

- The -f option for the interpreter is required: this tells awk where to look for the awk program. If we remove the -f option from the interpreter file, an error message usually results when we try to run it. The exact text of the message varies, depending on where the interpreter file is stored and whether the remaining arguments represent existing files. This is because the command-line arguments in this case are
/bin/awk /usr/local/bin/awkexample file1 FILENAME2 f3
and awk is trying to interpret the string /usr/local/bin/awkexample as an awk program. If we couldn’t pass at least a single optional argument to the interpreter (-f in this case), these interpreter files would be usable only with the shells. - Are interpreter files required? Not really. They provide an efficiency gain for the user at some expense in the kernel (since it’s the kernel that recognizes these files). Interpreter files are useful for the following reasons.
- They hide that certain programs are scripts in some other language. For example, to execute the program in Figure 8.21, we just say awkexample optional-arguments instead of needing to know that the program is really an awk script that we would otherwise have to execute as
awk -f awkexample optional-arguments - Interpreter scripts provide an efficiency gain. Consider the previous example again. We could still hide that the program is an awk script, by wrapping it in a shell script:
- They hide that certain programs are scripts in some other language. For example, to execute the program in Figure 8.21, we just say awkexample optional-arguments instead of needing to know that the program is really an awk script that we would otherwise have to execute as
awk ’BEGIN{ for (i = 0; i < ARGC; i++) printf "ARGV[%d] = %s\n", i, ARGV[i] exit}’ $*- The problem with this solution is that more work is required. First, the shell reads the command and tries to execlp the filename. Because the shell script is an executable file but isn’t a machine executable, an error is returned and execlp assumes that the file is a shell script(which it is). Then /bin/sh is executed with the pathname of the shell script as its argument. The shell correctly runs our script, but to run the awk program, the shell does a fork, exec, and wait. Thus there is more overhead involved in replacing an interpreter script with a shell script.
- Interpreter scripts let us write shell scripts using shells other than /bin/sh. When it finds an executable file that isn’t a machine executable, execlp has to choose a shell to invoke, and it always uses /bin/sh. Using an interpreter script, however, we can simply write
#!/bin/csh(C shell script follows in the interpreter file)- Again, we could wrap all of this in a /bin/sh script (that invokes the C shell), as we described earlier, but more overhead is required.
- None of this would work as we’ve shown here if the three shells and awk didn’t use the pound sign as their comment character.
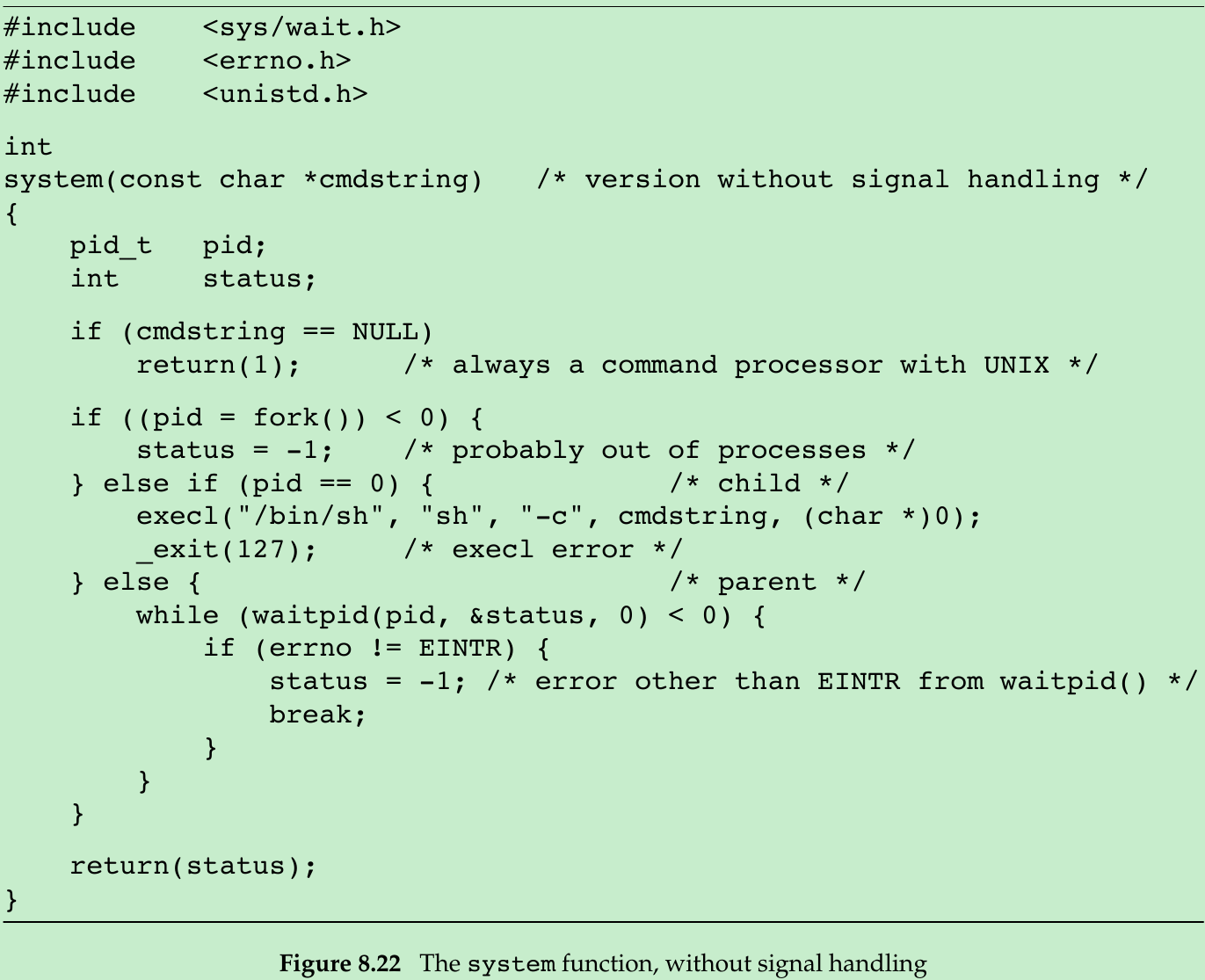
8.13 system Function
#include <stdlib.h>int system(const char *cmdstring);Returns: (see below)- If cmdstring is a null pointer, system returns nonzero only if a command processor is available. This feature determines whether the system function is supported on a given operating system.
- Because system is implemented by calling fork, exec, and waitpid, there are three types of return values.
- If either fork fails or waitpid returns an error other than EINTR: return -1 with errno set to indicate the error.
- If exec fails(i.e., the shell can’t be executed): return value is as if the shell had executed exit(127).
- All three functions succeed: return value is the termination status of the shell, in the format specified for waitpid.
- Figure 8.22 shows an implementation of system. One feature that it doesn’t handle is signals(Section 10.18).
- The shell’s -c option tells it to take the next command-line argument(cmdstring) as its command input instead of reading from standard input or from a given file. The shell parses this null-terminated C string and breaks it up into separate command-line arguments for the command. The actual command string that is passed to the shell can contain any valid shell commands.
- Note that we call _exit instead of exit to prevent any standard I/O buffers, which would have been copied from the parent to the child across the fork, from being flushed in the child.
- We can test this version of system with the program shown in Figure 8.23.(pr_exit in Figure 8.5.) Running the program in Figure 8.23 gives us

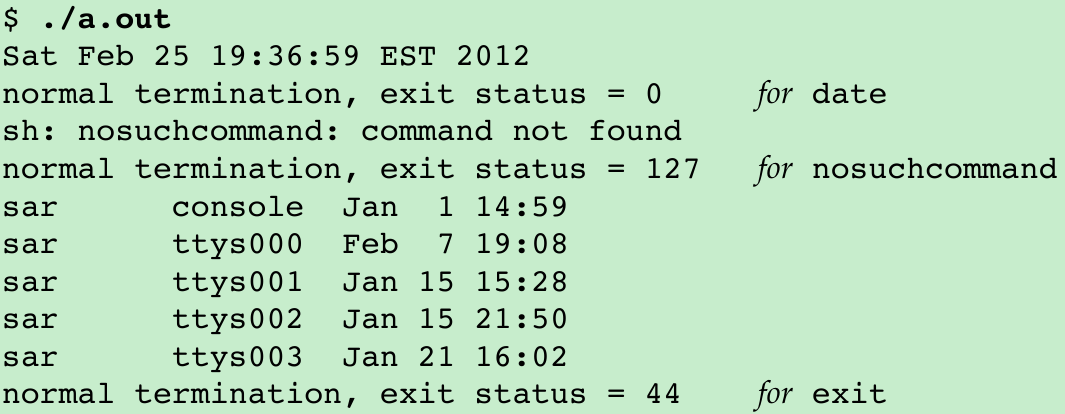
Set-User-ID Programs
- Call system from a set-user-ID program creates a security hole and should never be attempted.


- We compile 8.24 into tsys, 8.25 into printuids. Running both programs gives us the following:

- The superuser permissions that we gave the tsys program are retained across the fork and exec that are done by system.
- Some implementations closed this security hole by changing /bin/sh to reset the effective user ID to the real user ID when they don’t match. On these systems, the same effective user ID will be printed regardless of the status of the set-user-ID bit on the program calling system.
- If it is running with special permissions(either set-user-ID or set-group-ID) and wants to spawn another process, a process should use fork and exec directly, being certain to change back to normal permissions after the fork, before calling exec. The system function should never be used from a set-user-ID or a set-group-ID program.
8.14 Process Accounting
- UNIX provide an option to do process accounting. When enabled, the kernel writes an accounting record each time a process terminates. These accounting records typically contain a small amount of binary data with the name of the command, the amount of CPU time used, the user ID and group ID, the starting time, and so on. Linux doesn’t maintain I/O statistics at all.
- acct function enables and disables process accounting. The only use of this function is from the accton(8) command. A superuser executes accton with a pathname argument to enable accounting. The accounting records are written to the specified file, which is /var/log/account/pacct on Linux. Accounting is turned off by executing accton without any arguments.
- The structure of the accounting records is defined in
8.15 User Identification
- The system keeps track of the name we log in under(Section 6.8), and getlogin function provides a way to fetch that login name.
#include <unistd.h>char *getlogin(void);Returns: pointer to string giving login name if OK, NULL on error- This function can fail if the process is not attached to a terminal that a user logged in to. We call these processes daemons(Chapter 13). Given the login name, we can then use it to look up the user in the password file(e.g., to determine the login shell) using getpwnam.
8.16 Process Scheduling
- UNIX provided processes with control over their scheduling priority. The scheduling policy and priority were determined by the kernel. A process could choose to run with lower priority by adjusting its nice value. Only a privileged process was allowed to increase its scheduling priority.
- nice values range from 0 to (2*NZERO)-1, although some implementations support a range from 0 to 2*NZERO. Lower nice values have higher scheduling priority. NZERO is the default nice value of the system.
#include <unistd.h>int nice(int incr);Returns: new nice value - NZERO if OK, -1 on error- A process can retrieve and change only its own nice value; it can’t affect the nice value of any other process.
- incr is added to the nice value of the calling process. If incr is too large, the system silently reduces it to the maximum legal value. If incr is too small, the system silently increases it to the minimum legal value.
- Because -1 is a legal successful return value, we need to clear errno before calling nice and check its value if nice returns -1. If the call to nice succeeds and the return value is -1, then errno will still be zero. If errno is nonzero, it means that the call to nice failed.
- getpriority can be used to get the nice value for a process or a group of related processes.
#include <sys/time.h>#include <sys/resource.h>int getpriority(int which, id_t who);Returns: nice value between -NZERO and NZERO-1 if OK, -1 on error- which controls how the who argument is interpreted. which =
- PRIO_PROCESS: indicate a process,
- PRIO_PGRP: indicate a process group,
- PRIO_USER: indicate a user ID.
- who selects the process or processes of interest. who = 0 indicates the calling process, process group, or user(depending on the value of which). If (which = PRIO_USER & who = 0): the real user ID of the calling process is used. When which applies to more than one process, the highest priority(lowest value) of all the applicable processes is returned.
- setpriority set the priority of a process, a process group, or all the processes belonging to a particular user ID.
#include <sys/time.h>#include <sys/resource.h>int setpriority(int which, id_t who, int value);Returns: 0 if OK, -1 on error- which who are the same as in the getpriority function.
- value is added to NZERO and this becomes the new nice value.
- A child process inherits the nice value from its parent process in Linux.
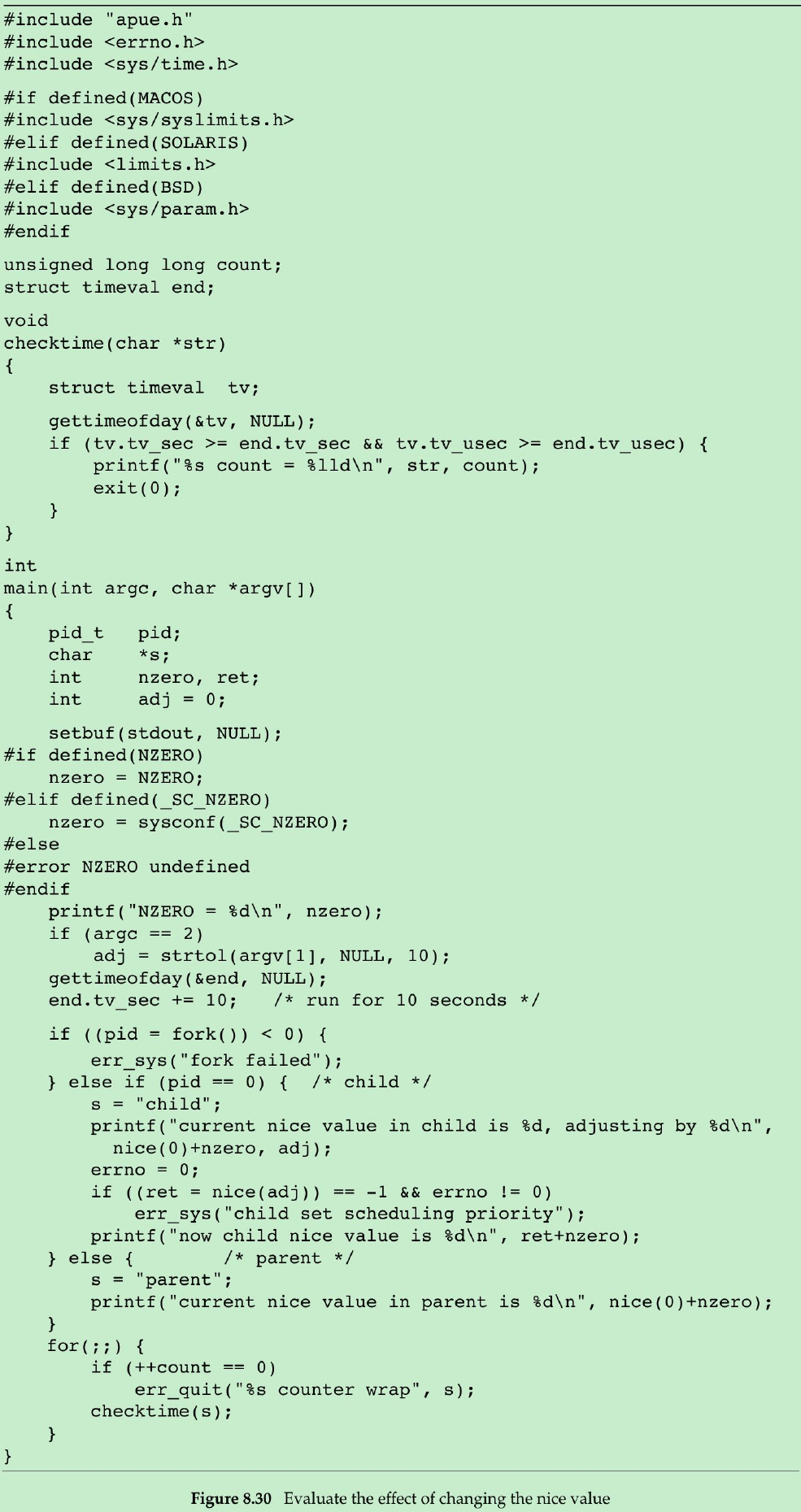
- The program in Figure 8.30 measures the effect of adjusting the nice value of a process.
- Two processes run in parallel, each incrementing its own counter. The parent runs with the default nice value, and the child runs with an adjusted nice value as specified by the optional command argument. After running for 10 seconds, both processes print the value of their counter and exit.
- We run the program twice: once with the default nice value, and once with the highest valid nice value(the lowest scheduling priority). We run this on a uniprocessor Linux to show how the scheduler shares the CPU among processes with different nice values. With an idle system, a multiprocessor system(or a multicore CPU) would allow both processes to run without the need to share a CPU, and we wouldn’t see much difference between two processes with different nice values.
$ ./a.outNZERO = 20current nice value in parent is 20current nice value in child is 20, adjusting by 0now child nice value is 20child count = 1859362parent count = 1845338$ ./a.out 20NZERO = 20current nice value in parent is 20current nice value in child is 20, adjusting by 20now child nice value is 39parent count = 3595709child count = 52111- When both processes have the same nice value: parent gets 50.2% of CPU, child gets 49.8% of CPU. The two processes are effectively treated equally. The percentages aren’t exactly equal because process scheduling isn’t exact, and because the child and parent perform different amounts of processing between the time that the end time is calculated and the time that the processing loop begins.
- When the child has the highest possible nice value(the lowest priority), parent gets 98.5% of CPU, child gets 1.5% of CPU.
8.17 Process Times
- Section 1.10. We can measure three times: wall clock time, user CPU time, and system CPU time. Any process can call times to obtain these values for itself and any terminated children.
#include <sys/times.h>clock_t times(struct tms *buf );Returns: elapsed wall clock time in clock ticks if OK, −1 on error- This function fills in the tms structure pointed to by buf :
struct tms{ clock_t tms_utime; // user CPU time clock_t tms_stime; // system CPU time clock_t tms_cutime; // user CPU time, terminated children clock_t tms_cstime; // system CPU time, terminated children};- The structure does not contain any measurement for the wall clock time. The function returns the wall clock time as the value of the function, each time it’s called. This value is measured from some arbitrary point in the past, so we can’t use its absolute value; instead, we use its relative value. For example, we call times and save the return value. At some later time, we call times again and subtract the earlier return value from the new return value. The difference is the wall clock time.
- The two structure fields for child processes contain values only for children that we have waited for with wait/waitpid.
- All the clock_t values returned by this function are converted to seconds using the number of clock ticks per second(_SC_CLK_TCK value returned by sysconf(Section 2.5.4)).
- getrusage(2): returns the CPU times and 14 other values indicating resource usage.

- The program in Figure 8.31 executes each command-line argument as a shell command string, timing the command and printing the values from the tms structure.
- If we run this program, we get
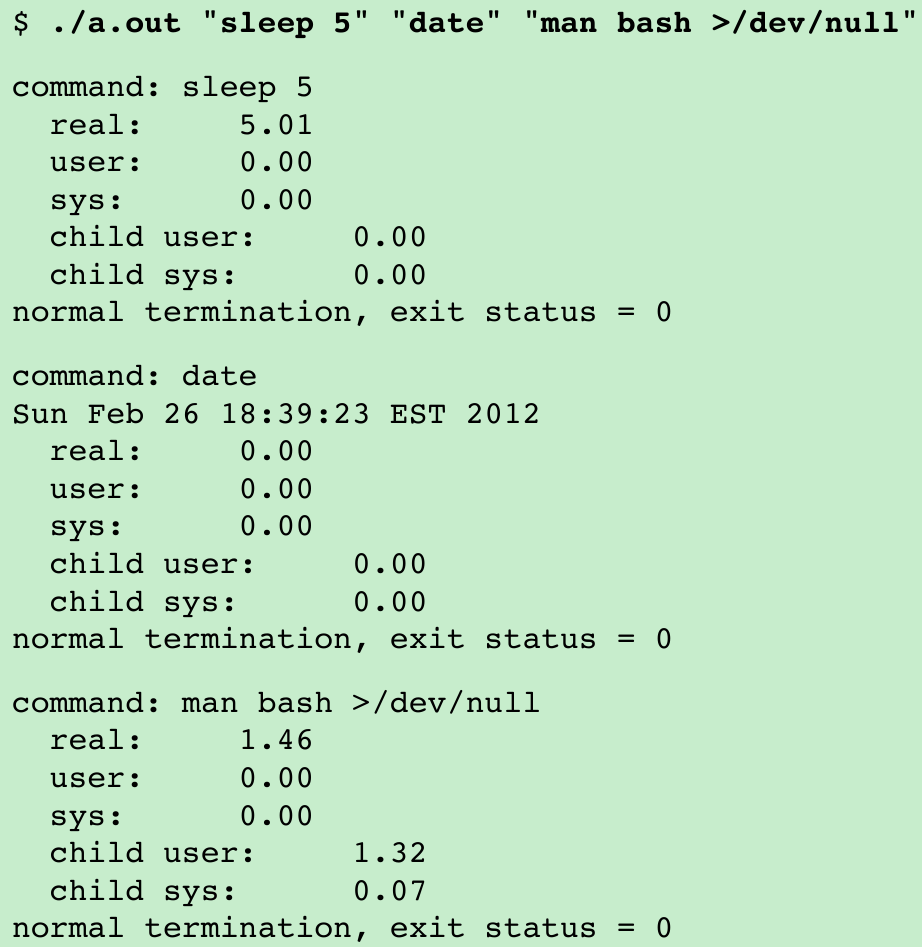
- In the first two commands, execution is fast enough to avoid registering any CPU time at the reported resolution. In the third command, we run a command that takes enough processing time to note that all the CPU time appears in the child process, which is where the shell and the command execute.
8.18 Summary
Exercises 1
In Figure 8.3, we said that replacing the call to _exit with a call to exit might cause the standard output to be closed and printf to return −1. Modify the program to check whether your implementation behaves this way. If it does not, how can you simulate this behavior?
- To simulate the behavior of the child closing the standard output when it exits, add
fclose(stdout);
before calling exit in the child. - To see the effects of doing this, replace the call to printf with the lines
char buf[MAXLINE];int i = printf("pid = %ld, glob = %d, var = %d\n", (long)getpid(), glob, var);sprintf(buf, "%d\n", i);write(STDOUT_FILENO, buf, strlen(buf));- This assumes that the standard I/O stream stdout is closed when the child calls exit, not the file descriptor STDOUT_FILENO.
- Some versions of the standard I/O library close the file descriptor associated with standard output, which would cause the write to standard output to also fail. In this case, dup standard output to another descriptor, and use this new descriptor for the write.
#include <stdio.h>#include <stdlib.h>#include <sys/types.h>#include <unistd.h>#include <string.h>int globvar = 0;void Exit(char *string){ printf("%s\n", string); exit(1);}int main(){ int var = 100; printf("Before fork\n"); printf("pid = %ld, global_var = %d, var = %d\n", (long)getpid(), globvar, var); pid_t pid; if((pid = vfork()) < 0) { Exit("fork error"); } else if(pid == 0) { ++globvar; ++var; printf("pid = %ld, global_var = %d, var = %d\n", (long)getpid(), globvar, var); fclose(stdout); exit(0); } char buf[16]; int num = printf("pid = %ld, global_var = %d, var = %d\n", (long)getpid(), globvar, var); sprintf(buf, "%d\n", num); write(STDOUT_FILENO, buf, strlen(buf)); exit(0);}/*Before forkpid = 20364, global_var = 0, var = 100pid = 20365, global_var = 1, var = 101-1*/Exercises 2
Recall the typical arrangement of memory in Figure 7.6. Because the stack frames corresponding to each function call are usually stored in the stack, and because after a vfork the child runs in the address space of the parent, what happens if the call to vfork is from a function other than main and the child does a return from this function after the vfork? Write a test program to verify this, and draw a picture of what’s happening.
- When vfork is called, the parent’s stack pointer points to the stack frame for the f1 function that calls vfork. Figure C.9 shows this.
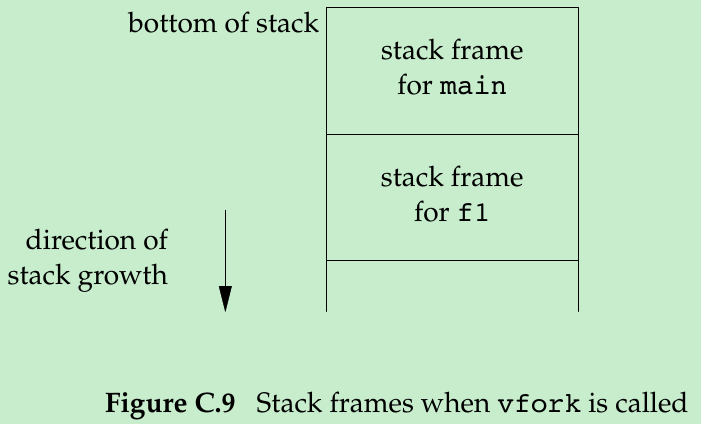
- vfork causes the child to execute first, and the child returns from f1. The child then calls f2, and its stack frame overwrites the previous stack frame for f1. The child then zeros out the automatic variable buf, setting 1,000 bytes of the stack frame to 0. The child returns from f2 and then calls _exit, but the contents of the stack beneath the stack frame for main have been changed.
- The parent then resumes after the call to vfork and does a return from f1. The return information is often stored in the stack frame, and that information has probably been modified by the child. After the parent resumes, what happens with this example depends on implementation features(where in the stack frame the return information is stored, what information in the stack frame is wiped out when the automatic variables are modified, and so on). The normal result is a core file.
#include <stdio.h>#include <stdlib.h>#include <sys/types.h>#include <unistd.h>void Exit(char *string){ printf("%s\n", string); exit(1);}static void f1(){ pid_t pid; if((pid = vfork()) < 0) { Exit("vfork error"); }}static void f2(){ char buf[1000]; for(int index = 0; index < sizeof(buf); ++index) { buf[index] = 0; }}int main(){ f1(); f2(); _exit(0);}Exercises 4
When we execute the program in Figure 8.13 one time, as in
./a.out
the output is correct. But if we execute the program multiple times, one right after the other, as in
$ ./a.out ; ./a.out ; ./a.out
output from parent
ooutput from parent
ouotuptut from child
put from parent
output from child
utput from child
the output is not correct. What’s happening? How can we correct this? Can this problem happen if we let the child write its output first?
- In Figure 8.13, we have the parent write its output first. When the parent is done, the child writes its output, but we let the parent terminate. Whether the parent terminates or whether the child finishes its output first depends on the kernel’s scheduling of the two processes(another race condition). When the parent terminates, the shell starts up the next program, and this next program can interfere with the output from the previous child.
- We can prevent this from happening by not letting the parent terminate until the child has also finished its output. Replace the code following the fork with the following:
else if (pid == 0){ WAIT_PARENT(); // parent goes first charatatime("output from child\n"); TELL_PARENT(getppid()); // tell parent we’re done}else{ charatatime("output from parent\n"); TELL_CHILD(pid); // tell child we’re done WAIT_CHILD(); // wait for child to finish}- We won’t see this happen if we let the child go first, since the shell doesn’t start the next program until the parent terminates.
Exercises 5
In the program shown in Figure 8.20, we call execl, specifying the pathname of the interpreter file. If we called execlp instead, specifying a filename of testinterp, and if the directory /home/sar/bin was a path prefix, what would be printed as argv[2] when the program is run?
- The same value (/home/sar/bin/testinterp) is printed for argv[2]. The reason is that execlp ends up calling execve with the same pathname as when we call execl directly. Recall Figure 8.15.
Exercises 6
Write a program that creates a zombie, and then call system to execute the ps(1) command to verify that the process is a zombie.
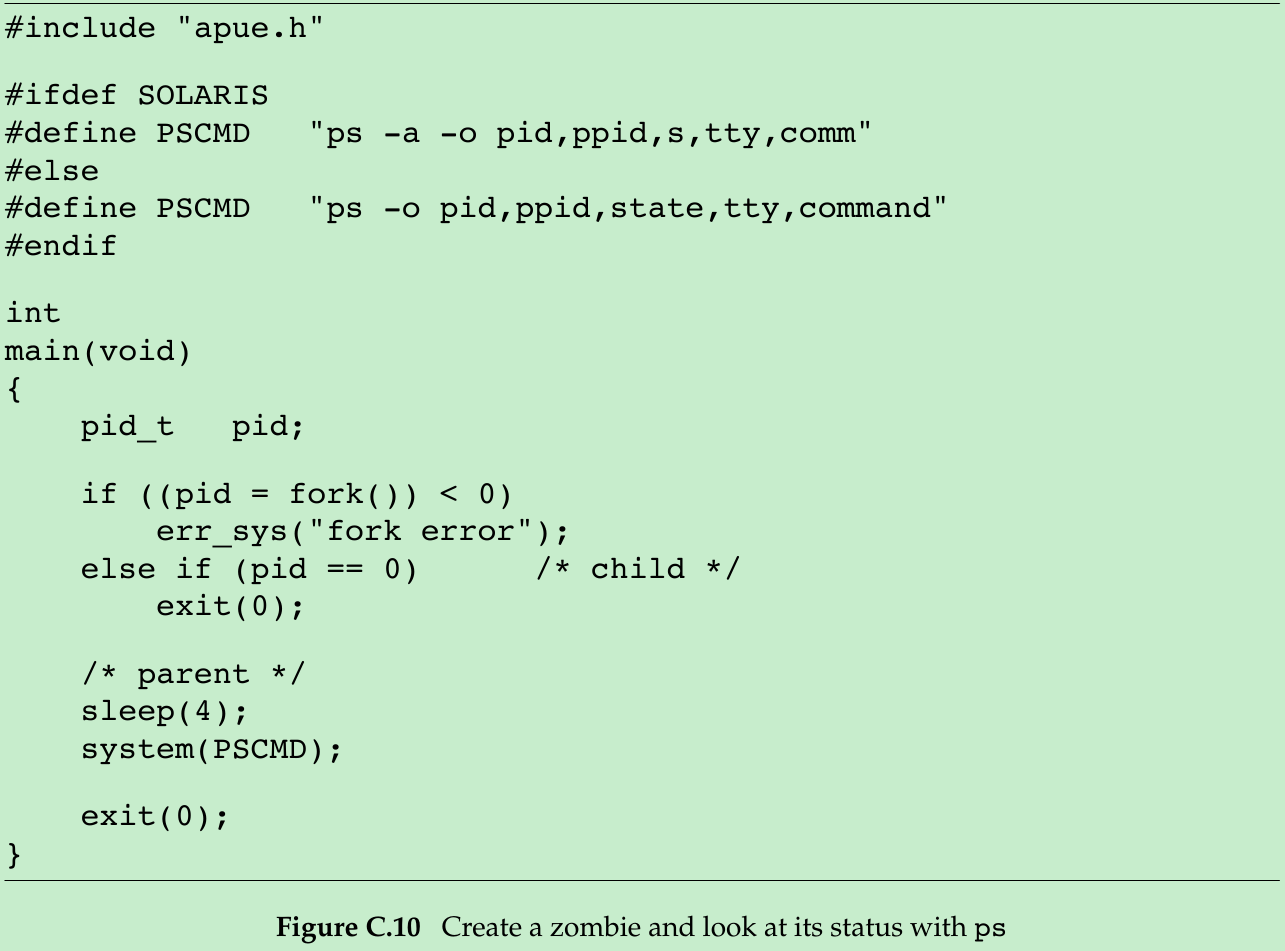
#include <stdio.h>#include <stdlib.h>#include <sys/types.h>#include <unistd.h>#define PSCMD "ps -o pid,ppid,state,tty,command"void Exit(char *string){ printf("%s\n", string); exit(1);}int main(void){ pid_t pid; if ((pid = fork()) < 0) { Exit("fork error"); } else if (pid == 0) { exit(0); } sleep(4); system(PSCMD); exit(0);}/*$ ./a.out PID PPID S TT COMMAND 9870 9864 S pts/1 bash21552 9870 S pts/1 ./a.out21553 21552 Z pts/1 [a.out] <defunct>21554 21552 S pts/1 sh -c ps -o pid,ppid,state,tty,command21555 21554 R pts/1 ps -o pid,ppid,state,tty,command*/Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1
- 8-Process Control
- unix process control
- OPC (OLE for Process Control)
- OPC (OLE for Process Control)
- 《APUE》Chapter 8 Process control(学习笔记加上自己的代码)
- OPC(ole for process control)技术论坛
- Control Study -> 用Process调用其它应用程序
- linux 学习笔记之 Process Control
- Control Study -> 用Process调用其它应用程序
- Control Study -> 用Process调用其它应用程序
- OPC (OLE for Process and Control)
- Specification of OLE for Process Control
- Advanced Run Control Techniques for Process Scheduler
- 双语阅读笔记 - 操作系统 - Process Control Block
- Institute for robotics and process control
- Operating System -- Process Description And Control
- Access Control List and Process(如何设置DACL)
- SPC统计过程控制(Statistical Process Control)
- Shell中关于if,case,for,while等的总结
- CyanogenMod 11.0模拟器goldfish的编译方法及下载地址
- WordPress 博客同步到 CSDN 插件
- win10电脑睡眠后鼠标不识别
- Linux基础知识学习:Linux下修改文件名或修改文件夹名称(有待解决问题)
- 8-Process Control
- 余额宝技术架构及演进
- 冒泡排序
- android一个布局由消失变为可见时实现动画效果
- PCB板在线模拟测试技术简介
- HDU 2376 Average distance 树形dp
- 9-Process Relationships
- session实现用户登陆功能
- JTree创建、获取和删除节点的方法


