lr参数化取值规则总结
来源:互联网 发布:小满科技 数据怎么样 编辑:程序博客网 时间:2024/05/01 00:52
详解lr参数表中的参数分配规则
参数化中数据替换方式详解:
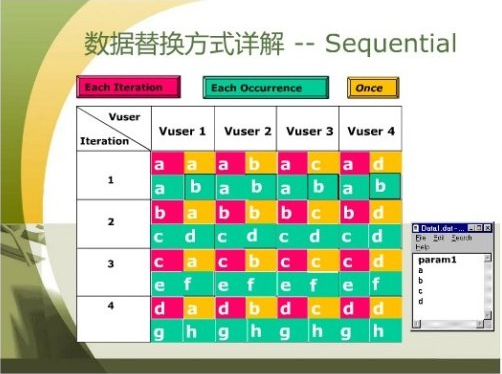
图一:顺序读取。
图二:随机替换:

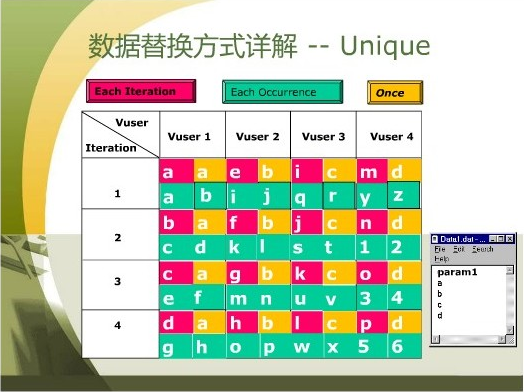
图三:唯一:
Select next row
Update value on
Sequential
Each iteration
每次执行Action时,参数值改变。
每个Vuser的参数取值都一样。
Each occurrence
每次取参数时,参数值改变。
每个Vuser的参数取值都一样。
Once
唯一
Random
自由选取参数
Unique
Each iteration
每次执行Action时,参数值改变。
在Allocate Vuser values in the Controller中
可选择“自动”和“手动”分配。
“自动”分配把参数平均分给每个Vuser。
“手动”分配时,参数不够的话,压力测试时会报错。
Each occurrence
每次取参数时,参数值改变。
只有“手动”分配。参数不够,测试时报错。
Once
唯一
When out of values
Abort Vuser
结束Vuser
Continue in a cyclic manner
使用同样的循环样式继续
Continue with last value
使用最后一个参数值继续
注释:
iteration: 在Run-time Settings中对Number of Iterations进行设置,即每次运行脚本时,Action反复执行的次数。
occurrence: 在一个Action中出现2次以上的同一个参数表。
注意:
当在脚本中使用lr_message ,lr_ouput_message输出参数值时,
例如lr_message(“result=%s”,lr_eval_string(“{NewParam}”);
参数表也会给这个语句中的{NewParam}分配一个参数值。
Parameter type: Unique Number
Number range: Start: 1
Block size per Vuser: 100 从1开始,每个并发使用100个参数.第1个并发使用1- 100,第2个使用101=200,第3个……
Number format: %d 不保留有效数字。
%01d 保留1位有效数字。
LoadRunner参数化设置详细说明
我想使用参数化输入设置10个并发用户循环1000次,第一个用户使用参数列表中的前1000个参数(第依次循环使用第一个参数、第二次循环使用第二个参数,依次类推)、第二个用户使用参数列表中的2001-3000个参数,依次类推。
LoadRunner进行参数化输入时,参数的属性有Select next row、Update value on两个项,其中Select next row属性包括三个选项: Update value on属性包括四个选项:Sequential、Random、Unique、四个选项。
首先搞清楚了几个概念:
1.Update value on
--Each Occurrence:只要发现该参数就重新取值(用于各处引用参数都不相关时)
--Each iteration:每次反复都要取新值(各个并发会共享同一个值,用于多次引用参数且相关的情况)
--Once:在所有的反复中都使用同一个值(仅在场景初始化时产生一次,在一个场景中的所有并发和所有反复的值都相同)
2.Select Next Row
方法可以是:连续的、随机的、唯一的、或者与其它
参数表的相同行。
--顺序(Sequential):该方法顺序地给虚拟用户分配参数值。如果正在
运行的虚拟用户访问数据表的时候,它会取到下一行中可用的数据。
--随机(Random):该方法在每次迭代的时候会从数据表中取随机数
--唯一(UNIQUE):Unique方法分配一个唯一的有顺序的值给每个虚拟用户的参数。
--其它参数表的相同行(Same Line As)该方法从和以前定义过的参数中的同样的一行分配数据。你必须指定包含有该数据的列。在下拉列表中会出现定义过的所有参数列表。注意:至少其中的一个参数必须是Sequential、Random或者Unique。
--使用种子取随机顺序(Use Random Sequence with Seed):如果从Loadrunner的控制器来运行scenario,你可以指定一个种子数值用于随机顺序。每一个种子数值在测试执行的时候代表了一个随机数的顺序。无论你何时使用这个种子数值,在scenario中同样的数据顺序就被分配给虚拟用户。如果在测试执行的时候发现了一个问题并且企图使用同样的随机数序列来重复测试,那么,你就可以启动这个功能(可选项)。
3.唯一参数值的分配方式
场景初始化时会根据设置为每个VUser预先分配多个参数值,已确保不会重复。
使用选项:Allocate XXX values for each vuser
按照此设置后,运行设置为并发3个Vuser,RunTimeSetting设置为Run两次。运行 LoadRunner时,总是报错:
insufficient records for param 'NewParam' in table to provide the Vuser with unique data
百思不得其解,终于在Google上看到一篇文中提到:
Do not delete script sections to avoid confusing the Controller. Instead, delete scripts you don't use from the Runtime Settings Run Logic section. However, actions not appearing in Run Logic are not available to the Controller.
Conversely, parameters in actions deleted in the Controller still increment. This may result in this error message: -84800 "insufficient records for param '...' in table to provide the Vuser with unique data" (哈哈,想起来了自己曾经删除过一些参数)
于是乎,New—〉Record—〉Replace Parameter一阵忙碌重新把脚本录制一遍,并且一次性设置好参数的属性。运行LoadRuner,那该死的错误终于看不到啦!
只进行迭代的操作,未在场景进行操作:
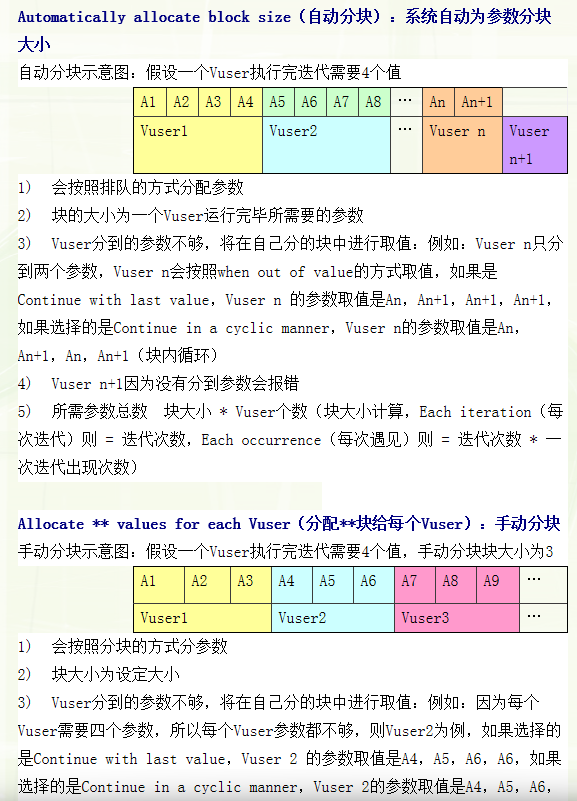
Automatically allocate block size(自动分块):系统自动为参数分块大小
自动分块示意图:假设一个Vuser执行完迭代需要4个值
A1
A2
A3
A4
A5
A6
A7
A8
…
An
An+1
Vuser1
Vuser2
…
Vuser n
Vuser n+1
1) 会按照排队的方式分配参数
2) 块的大小为一个Vuser运行完毕所需要的参数
3) Vuser分到的参数不够,将在自己分的块中进行取值:例如:Vuser n只分到两个参数,Vuser n会按照when out of value的方式取值,如果是Continue with last value,Vuser n 的参数取值是An,An+1,An+1,An+1,如果选择的是Continue in a cyclic manner,Vuser n的参数取值是An,An+1,An,An+1(块内循环)
4) Vuser n+1因为没有分到参数会报错
5) 所需参数总数 块大小 * Vuser个数(块大小计算,Each iteration(每次迭代)则 = 迭代次数,Each occurrence(每次遇见)则 = 迭代次数 * 一次迭代出现次数)
Allocate ** values for each Vuser(分配**块给每个Vuser):手动分块
手动分块示意图:假设一个Vuser执行完迭代需要4个值,手动分块块大小为3
A1
A2
A3
A4
A5
A6
A7
A8
A9
…
Vuser1
Vuser2
Vuser3
…
1) 会按照分块的方式分参数
2) 块大小为设定大小
3) Vuser分到的参数不够,将在自己分的块中进行取值:例如:因为每个Vuser需要四个参数,所以每个Vuser参数都不够,则Vuser2为例,如果选择的是Continue with last value,Vuser 2 的参数取值是A4,A5,A6,A6,如果选择的是Continue in a cyclic manner,Vuser 2的参数取值是A4,A5,A6,A4(块内循环)
4) 所需参数总数 手动分配块大小 * Vuser个数
注:在controller设置duration的情况下,自动分块的分块方式有所变化,块大小 = 我们输入的参数总数 / Vuser的个数,其他处理方式和手动分配块大小一致

参数表中select next row和update value on的设置
LR的参数的取值,和select next row和update value on的设置都有密不可分的关系。 下表给出了select next row和update value on不同的设置,对于LR的参数取值的结果将不同,给出了详细的描述。
参数表中when out of values的意义
WHEN OUT OF VALUES是指在每个用户分配到一定数量的参数后,在LR循环运行的时候, 当某个用户的参数不够的时候,LR将按照设置的WHEN OUT OF VALUES的值进行处理。
举个例子:
现有一参数,名为:emp_no, 有四个值: E01,E02,E03,E04
现有一场景,三个虚拟用户,分别为:U1,U2,U3
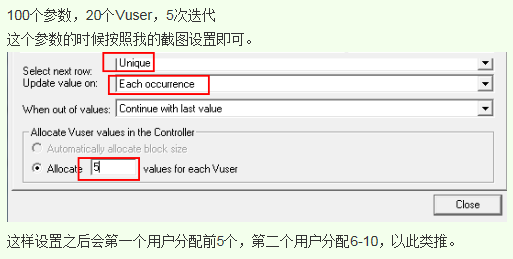
LR参数列表设置:unique + each iteration+ allocate 2 values for each vuser
在场景运行的时候:
1. LR会先做一件事情-参数分配,假设参数分配的方式是手工分配,allocate 2 values for each vuser. 分配的结果是: U1-E01,E02; U2-E03,E04; U3-无参数;
[备注:若选择了自动分配参数。那将遵循以下的原则:
Controller中edit schedule中选择了run until comletion:按照循环次数先分配第一个VU(例如设置的循环次数为3,那分配给第一个VU 3个参数值),
然后接下来的3个参数值分配给第二个VU,依次类推…... Controller中edit schedule中选择了run for:若选择自动分配,LR将按照用户数均分参数,剩余的参数不使用。]
2. 在运行开始后,U3将会FAILED. 因为没有参数分配给他。其他的两个虚拟用户正常运行,但是其他的两个用户,每个用户只有两个参数,只能保证他们循环两次而已。 当他们运行到第三个循环的时候,他们已经没有参数可以用了。 怎么办呢? 这个时候,LR将按照设置的WHEN OUT OF VALUES的值进行处理。我们拿虚拟用户U1来举例说明。
如果when out of values=abort vuser, U1在第三次循环的时候将会退出执行。
如果when out of values=continue in a cyclic manner, U1在第三次循环的时候将会开始循环利用他的参数值E01, 第四次循环使用E02…….
如果when out of values=continue with last value, U1在第三次循环的时候使用最后的一个参数即E02, 第四次继续使用E02…….
http://www.cnblogs.com/cxd4321/archive/2008/11/18/1336184.html
loadrunner参数化总结Select next row:Sequential,Rondom,Unique Update value on:Each iteration,Each occurrence,Once下面分别对这两种取值情况组合介绍 一、Sequential与Update value on各个选项的组合情况: 1.Sequential+Each iteration 说明:此组合是在每次迭代时,顺序循环取值,即迭代次数超过参数个数时,循环取值1.当此组合放在vuser_init函数中时,取Action第一次迭代的值2.当此组合放在Action函数中是,取值为顺序取值(fromFirst->toLast->fromfirst),可以从ReplayLog中,以“Starting iteration” 为标志3.当此组合放在vuser_end函数中时,取Action最后一次迭代的值 总结:vuser_int函数包含在Action的第一次迭代中,而vuser_end函数包含在Action最后一次迭代中,此组合只受迭代的影响。 2、Sequential+Each occurrence 说明:此组合是在每次发生参数取值时,就会更新参数值,同样是顺序取值。 此组合的特点是取值与迭代无关,不管是在vuser_init(),Action(),vuser_end()中,只要发生取值,就会从参数列表中顺序循环取 值。 3、Sequential+Once 说明:这种组合比较简单,对于整个脚本来说参数值只取一次,再也不会更新,且与脚本迭代无关。 二、Random与Update value on各个选项的组合情况: 1.Random+Each iteration 说明:每当一次新的迭代开始(以Starting iteration为标志),从参数列表中取一次随机值。 总结:与“Sequential+Each iteration”这中情况相同,vuser_int函数包含在Action的第一次迭代中,而vuser_end函数包含在Action最后一次迭代中,只受迭代的影响。 唯一的不同点:每次取值方式不同。 2.Random+Each occurence 说明:每当取一次参数值时,从参数列表中取一次随机值。 总结:取值情况与“Sequential+Each occurrence”类似, 唯一不同点:此组合每次取值方式是随机从参数列表中读取的,而前者每次取值是顺序循环的方式读取值。 3.Random+Once 说明:当第一次取到值时,再也不更新记录 总结:与“Sequential+Once”类似,唯一不同的是取值方式不同。 三、Unique与Update value on各个选项的组合情况: 说明:1.Unique取值是一种类似于Sequential的顺序取值方式 不同点:Unique强调的是取值的唯一性,即当取值遍历完参数列表中的数据时,默认将终止vuser 2.通过When out of values选项可以设置vugen对vuser超出参数列表边界时的处理方式:1.Abort Vuser:默认是此模式,当参数取值超出参数表记录的条数时,中止当前vuser 2.Continue in a cyclic manner:此方式与“Sequential”完全相同。3.Continue with last value:当参数取值超出参数表记录的条数时,使用参数列表中最后一个值。 1.Unique+Each Iteration 设置了run上的迭代次数后,按照纪录顺序读取,当纪录超出列表后,执行when out of values策略 2.Unique+Each occurrence 每当参数取值时,顺序读取参数纪录,当纪录超出列表后,执行when out of values策略 3.Unique+Once 第一次取值后,一直使用该记录 到这里就把Select next row与Update value on中的各选项组合介绍完毕,在实际应用中可能这些组合还是无法满足我们对参数取值,下面 介绍两个常用函数,手工将参数值下移一位,以Sequential+Each iteration为例。1.lr_advance_param()参数列表name中,顺序存储A,B,C,D四个数据,如果想参数在第一次Action迭代中,取得A值后,紧接取得B值,显然依靠之前的9种 组合无法完成,接下来以代码为例,讲解lr_advance_param()的使用。 代码:Action() { lr_eval_string("{name}"); //取值为A lr_advance_param("name"); //Next row for parameter name,将参数取值下移一位lr_eval_string("{name}"); //取值为B return 0; } 2.lr_next_row() 代码:Action() { lr_eval_string("{name}"); //取值为A lr_advance_param("name.dat"); //Next row for parameter name,将参数取值下移一位lr_eval_string("{name}"); //取值为B return 0; }总结:两个函数主要区别在于前者在函数内的参数值是参数名称,后者写的是参数文件名。
假如你有两个用户分别为用户A,用户B。假如你的参数为emp_name有20行数据("1","2',"3","4".........."20")那么按照这种设置以后,在Loadrunner的controller运行的时候,LR会分配给用户A,用户B如下的参数。用户A:emp_name参数列表中的第一行:即例子中的"1";用户B:emp_name参数列表中的第二行;即例子中的"2"不管controller中运行多少个iteration,或者持续运行多长时间。 用户A始终使用参数"1",用户B始终使用参数"2".第二种方法: 假如你有两个用户分别为用户A,用户B。假如你的参数为emp_name有20行数据("1","2',"3","4".........."20")那么按照这种设置以后,你设置了给每个用户分配2个参数值。那么在Loadrunner的controller运行的时候,LR会分配给用户A,用户B如下的参数。用户A:emp_name参数列表中的第一,二行:即例子中的"1",“2”。用户B:emp_name参数列表中的第三,四行;即例子中的"3",“4”。不管controller中运行多少个iteration,或者持续运行多长时间。 用户A始终使用参数"1""2", 用户B始终使用参数"3""4"。 当然,假如你有5个虚拟用户的话,每个用户分配的参数如下:用户A:"1","2"用户B:"3","4"用户C:"5","6"用户D:"7","8"用户E:"9,"10"
- lr参数化取值规则总结
- lr参数表中的参数分配规则
- LR 杂记--loadrunner参数化总结
- LR手动关联参数化问题总结
- LR手动关联参数化问题总结
- LR邮件附件参数化
- LR工具-参数化
- LR中的参数
- LR参数和变量
- lR关联功能总结
- lR关联功能总结
- LR检查点出错总结
- LR常用函数总结
- lR关联功能总结
- 关于LR的总结
- LR的参数和变量
- LR里的参数类型
- LR 连接数据库设置参数
- Swift 指南
- 探寻次时代渲染 - CryEngine2
- android知识小贴士之二:基于位置的服务
- 解决Genymotion模拟器不能上网的问题
- python实现微信提醒({“errcode”:41011,”errmsg”:”missing agentid”})
- lr参数化取值规则总结
- 谁都没想到,乐视超级电视涨价的真相竟然是......
- input 触发总结
- 利用FileOutputStream存储数据,实现代码中对象有存、取
- VC6.0快捷键一览表
- 108. Convert Sorted Array to Binary Search Tree
- Maven之——使用本地jar包并打包进war包里面的方法
- 老师说这是2006面谷歌应聘笔试题
- Jquery 执行顺序


